Updates on NN perfromance
- CF clusterizer, 21.6 mio. clusters
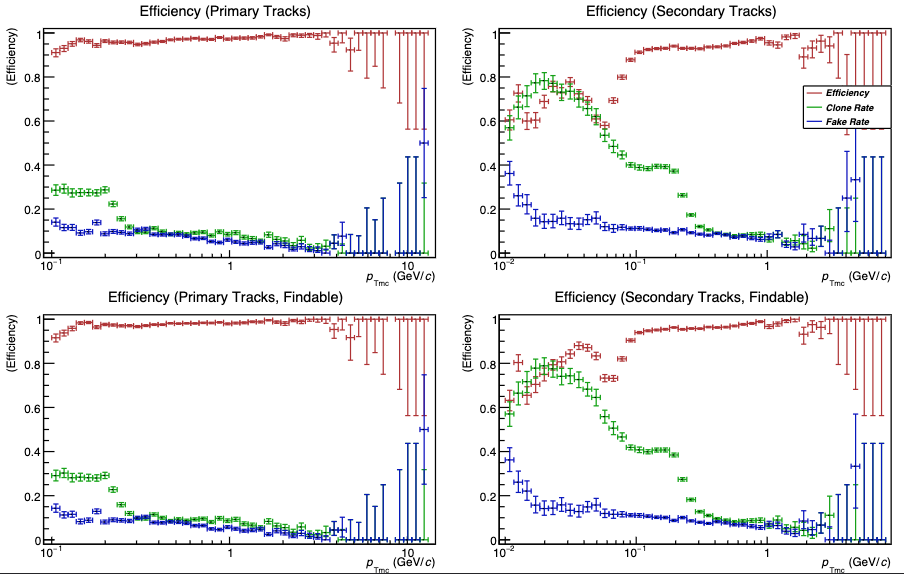
- Classification (trained on MC) + CF regression, 16 mio. clusters
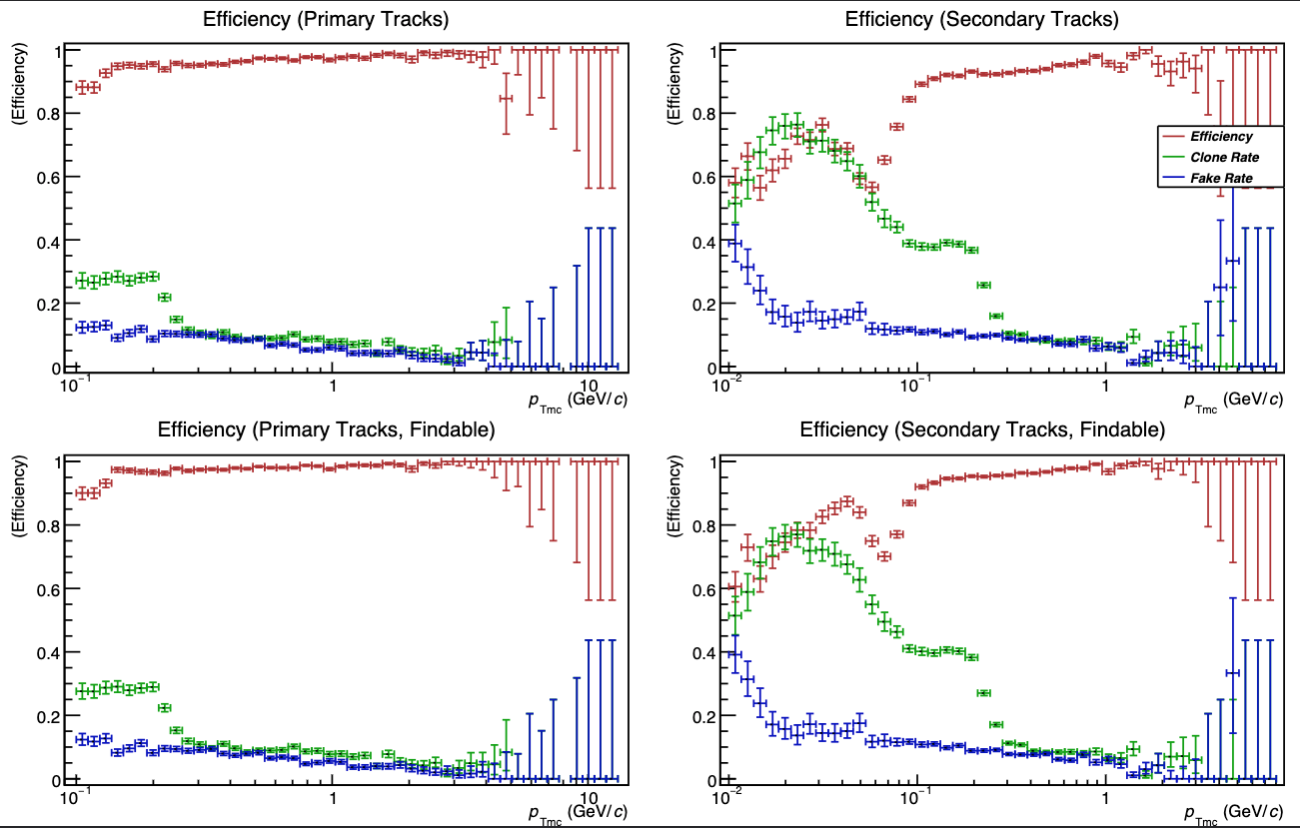

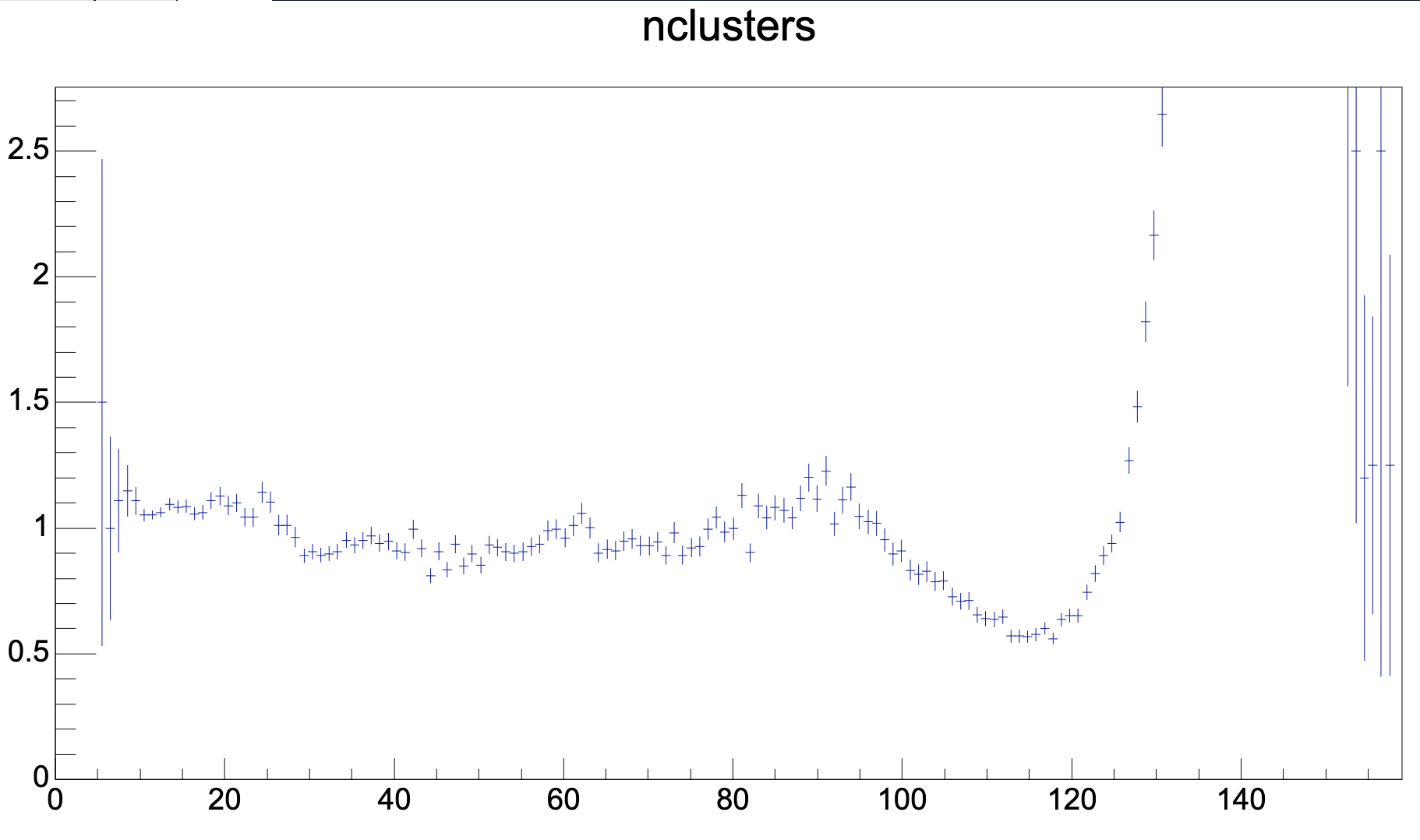
- Classification (trained on real data, native clusters) + CF regression, 18.5 mio. clusters


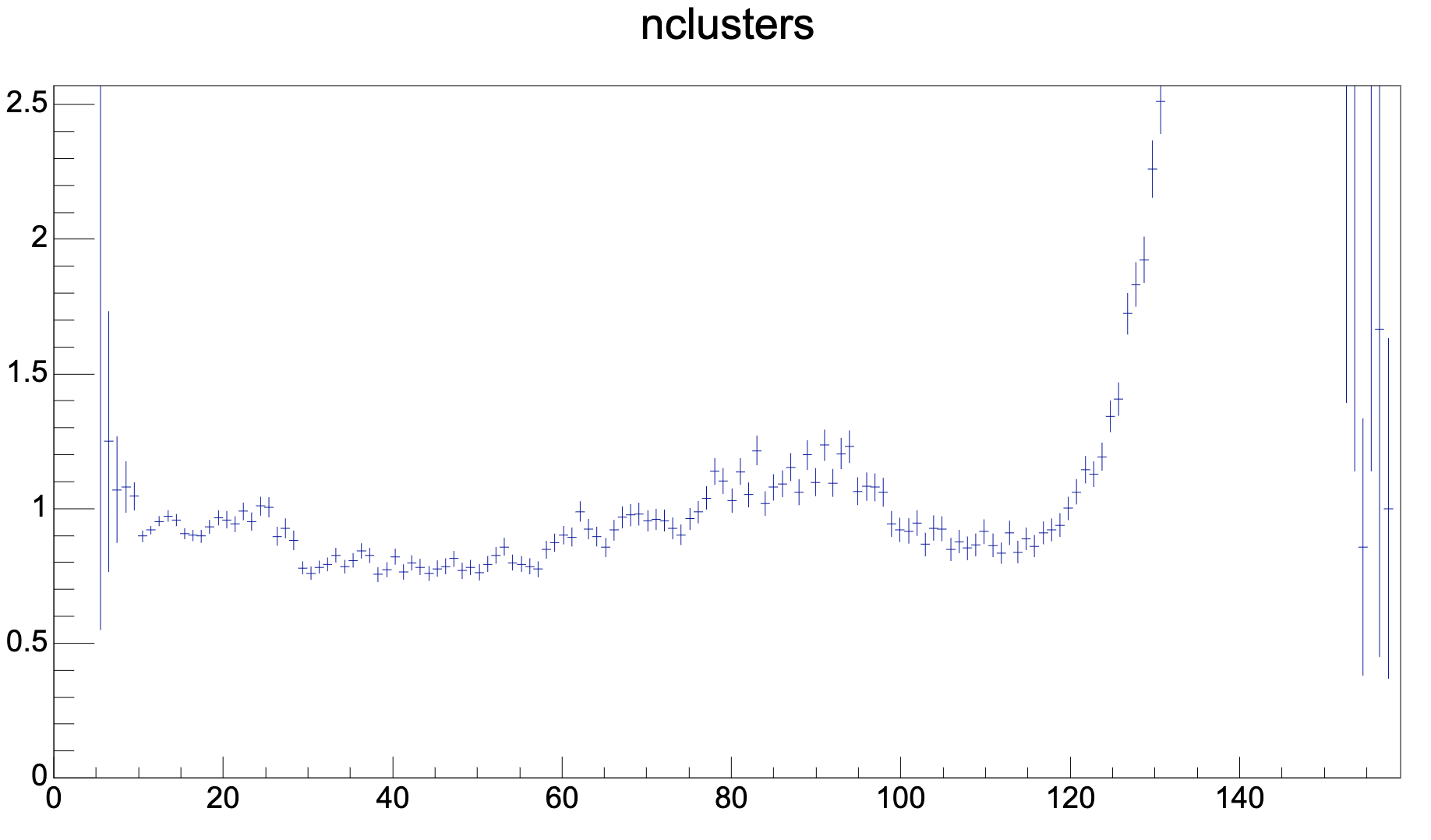
- Next subjects for study
- Improve regression network (probably connected to training data)
- Use one of the classification networks, vary cuts and observe impact on tracking efficiency
- Automatize the working point search (potentially via a hyperparameter optimization strategy)
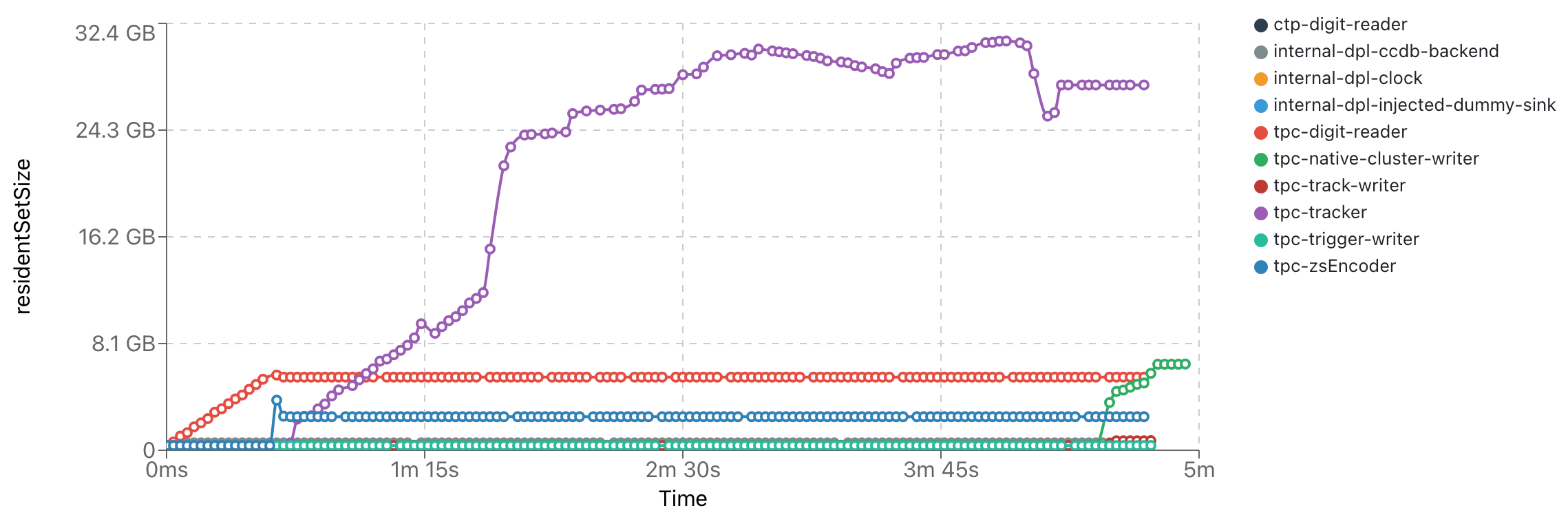
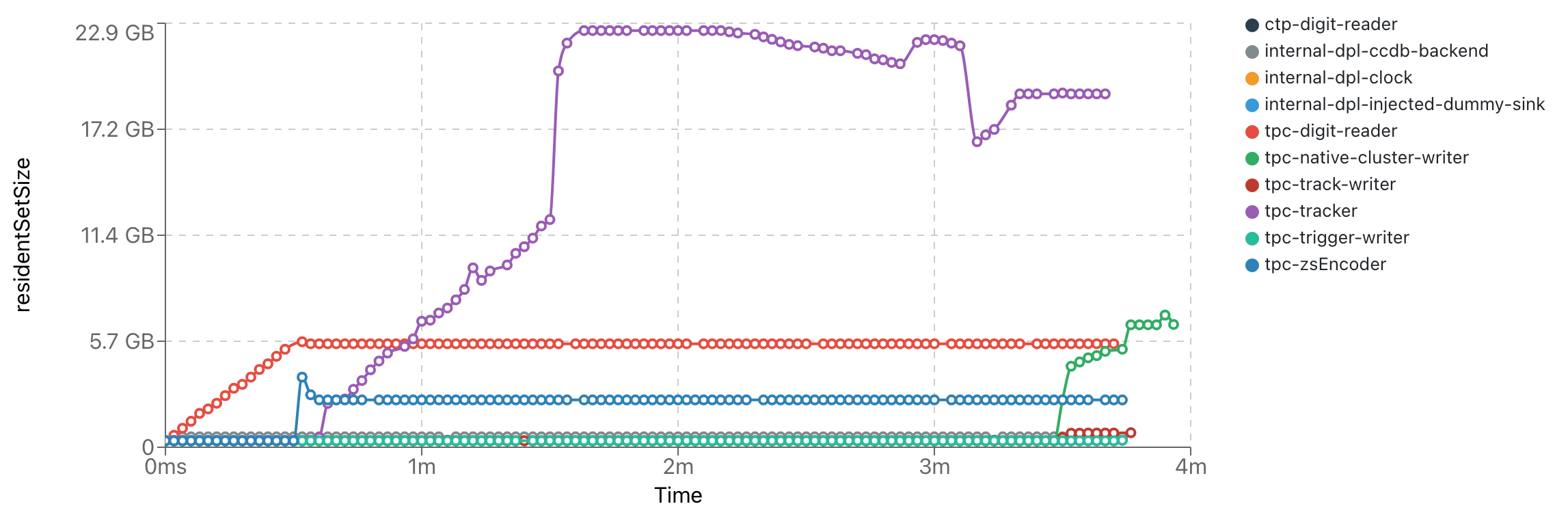
Updates on NN speed & implementation
- With ROCm 6.2, ONNXRuntime compiles now for gfx906 (MI50) & gfx908 (MI100) and also with support of float16
- Successfully imported and evaluated NN's on standalone (in O2) task with ~19 mio. clusters/s (MI50) and ~25 mio. clusters/s (MI100)
- MI100 should be ~8x faster than MI50 for FP16 -> We are "scheduling"-bound!
- session->Run() can only currently run with max. 3910 tensors of size 346 (= 7x7x7 + 3) in FP16: Potentially limited by GPU memory page-size
- Increased perfromance by spawning multiple sessions (~30) and using multithreading to load the GPU
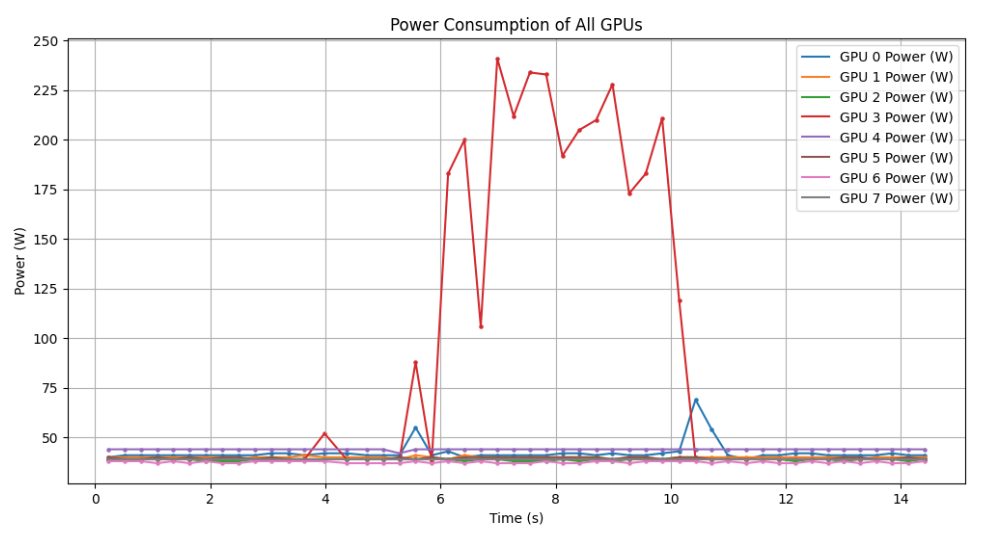
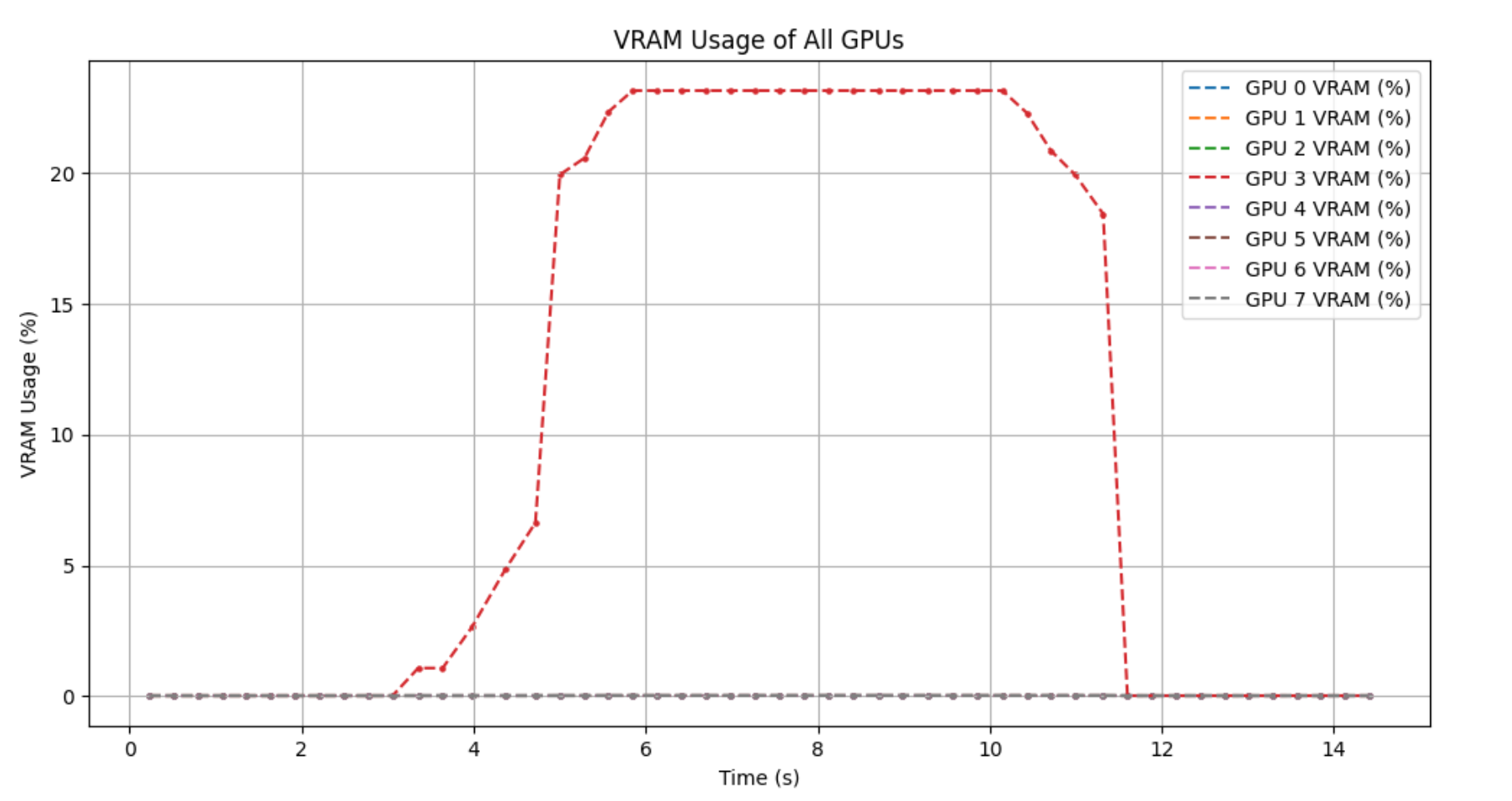
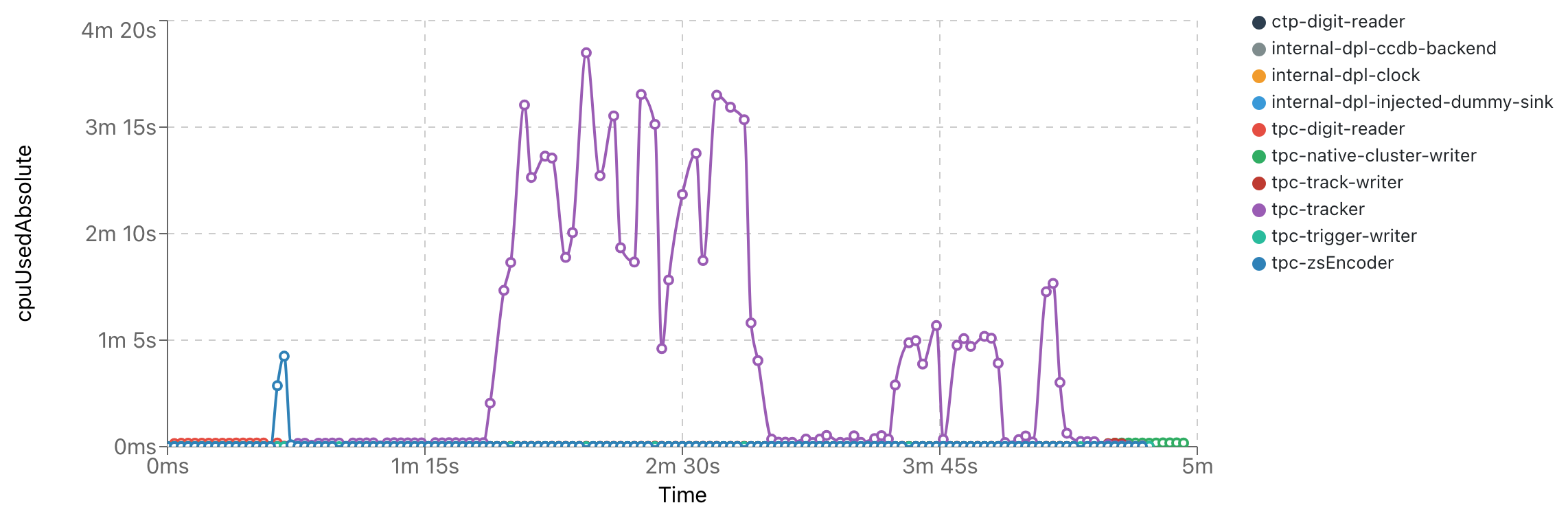
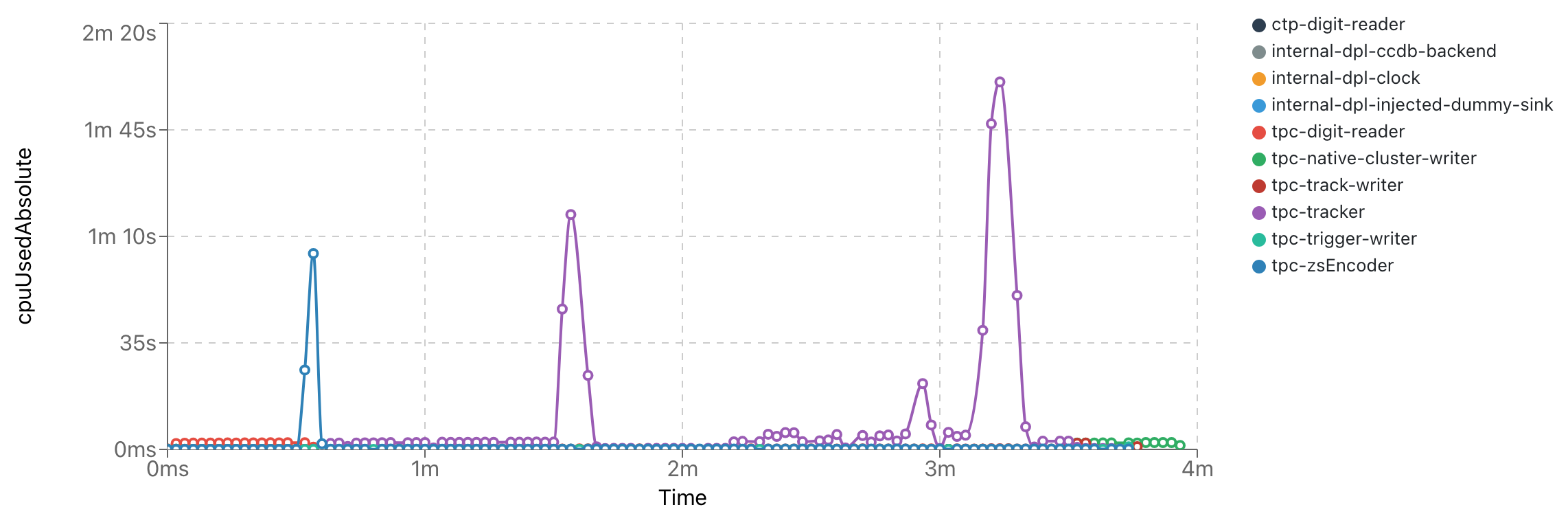
- CPU implementation (top is ONNX, bottom is standard reco)
---------------------------------------------------