Alice Weekly Meeting: Software for Hardware Accelerators / PDP-SRC
→
Europe/Zurich
ALICE GPU Meeting
-
-
Speaker: Christian Sonnabend (CERN, Heidelberg University (DE))
Update on cluster-overlap study
- Cluster overlap is counted like this
- Charge overlap: For cluster with MC-ID i, sum charges where pad-time-units of this cluster (with charge of MC-ID i) have contributions from other clusters with MC-ID j != i. Divide by total charge of cluster i (range between 0 and 1).
- Area overlap: Count all pad-time bins where a charge of MC-ID (i and j != i) contributed and divide by all pad-time bins where charge of MC-ID i is present
- Caveat: Probably loopers are not captured well with this technique as I count all charges (not bound by pad-time windows)
Correlation of area and charge overlap is visible, but not as strong as I had expected...

Centre-of-gravity resolution of NN, area overlap
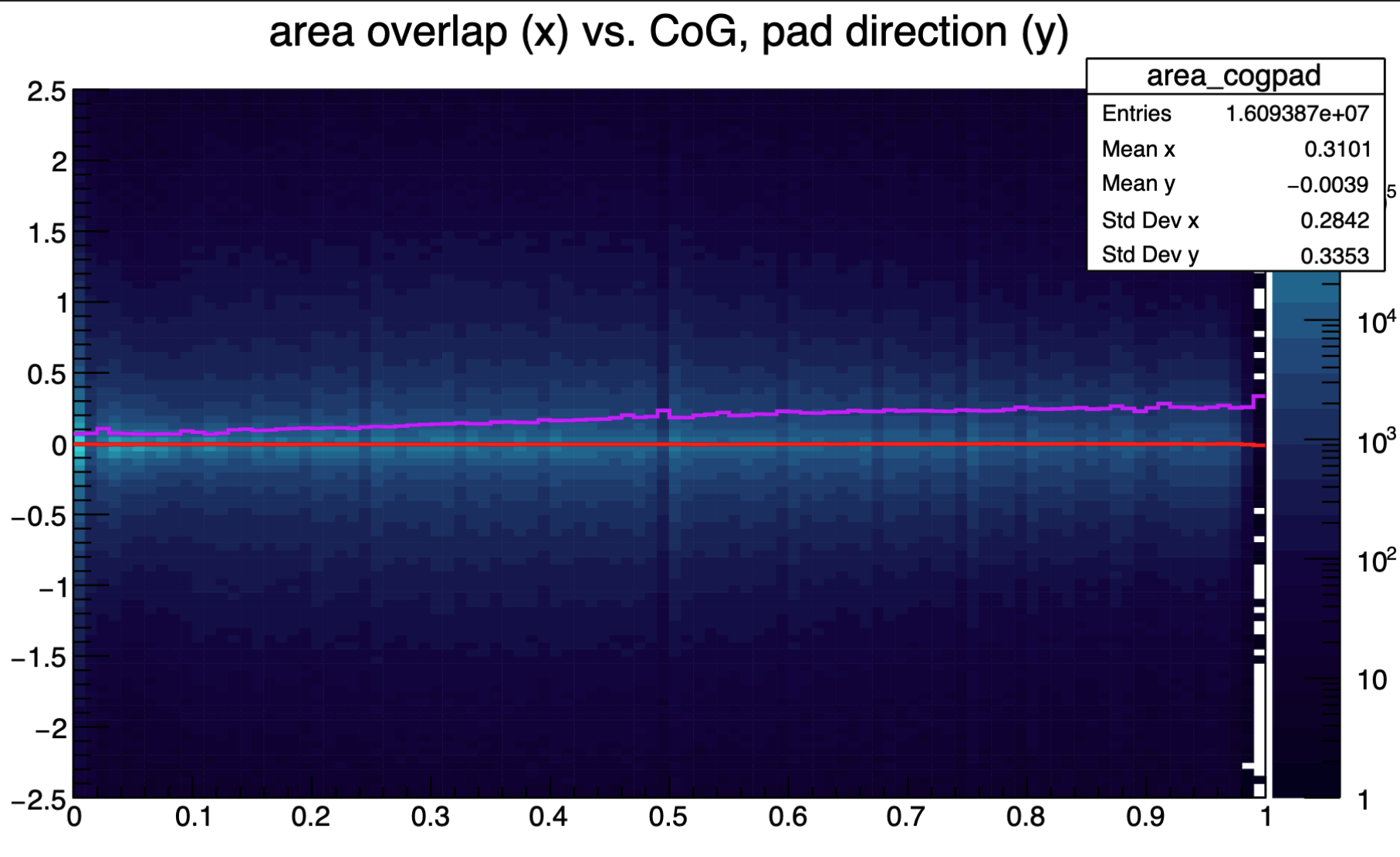
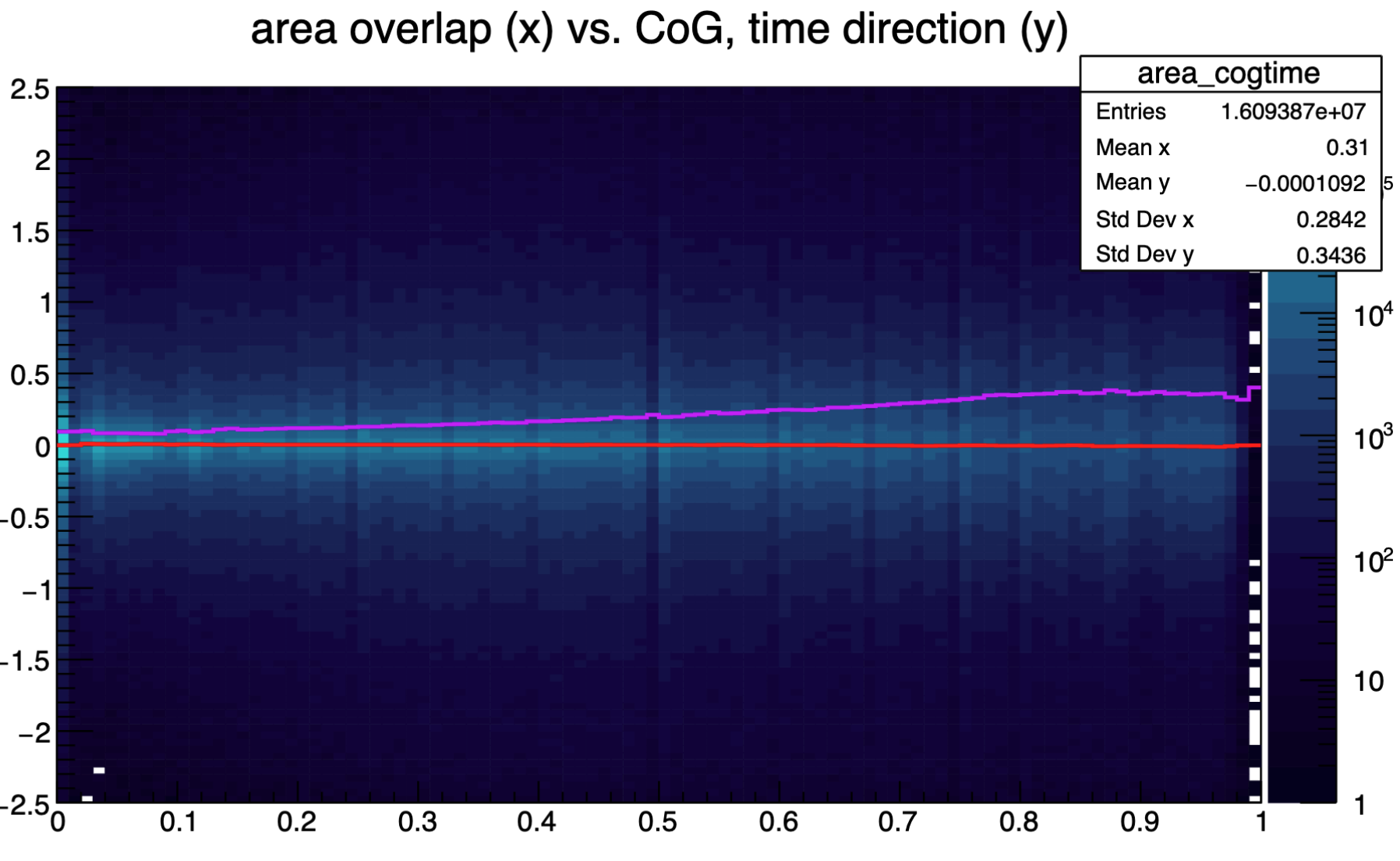
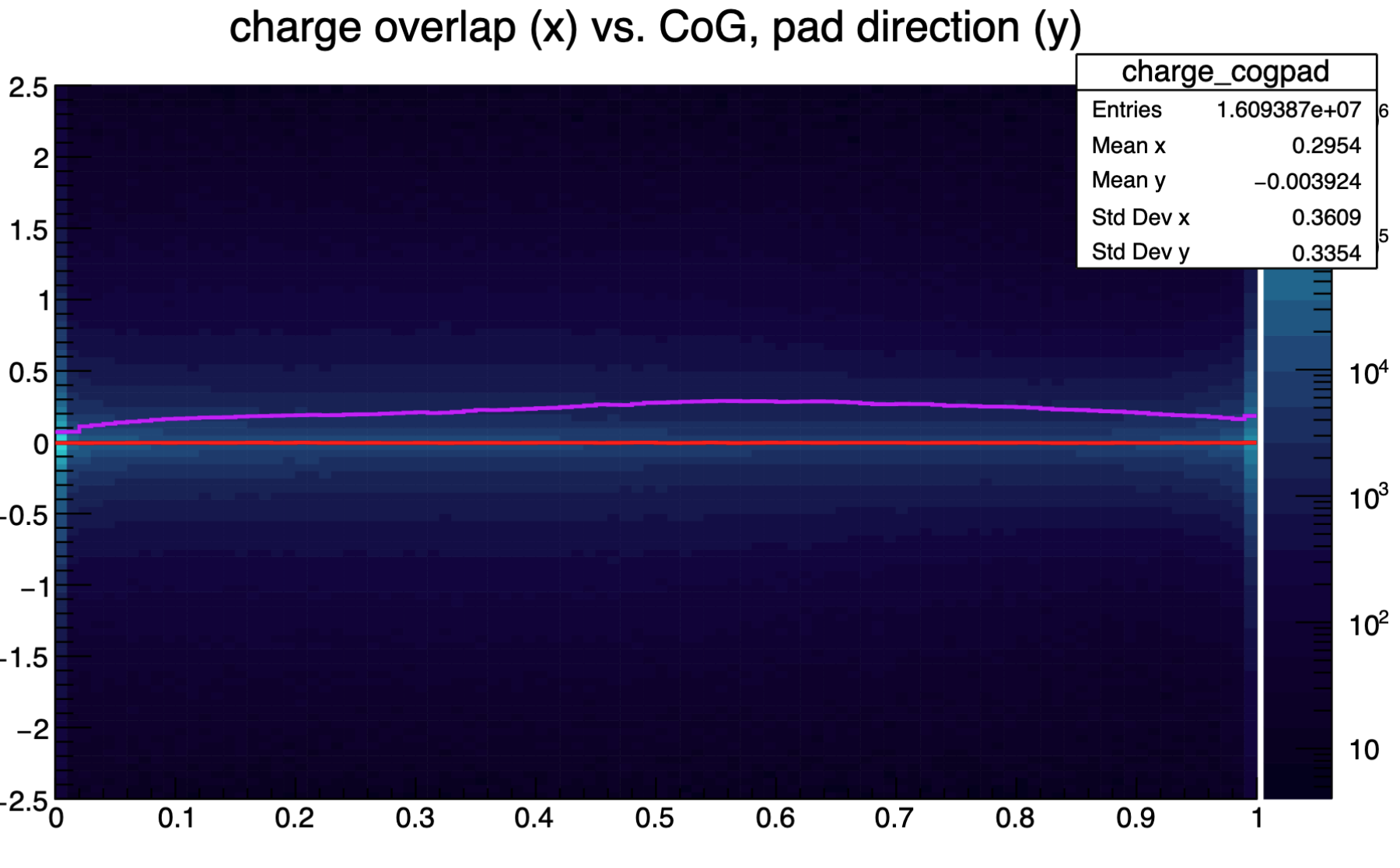
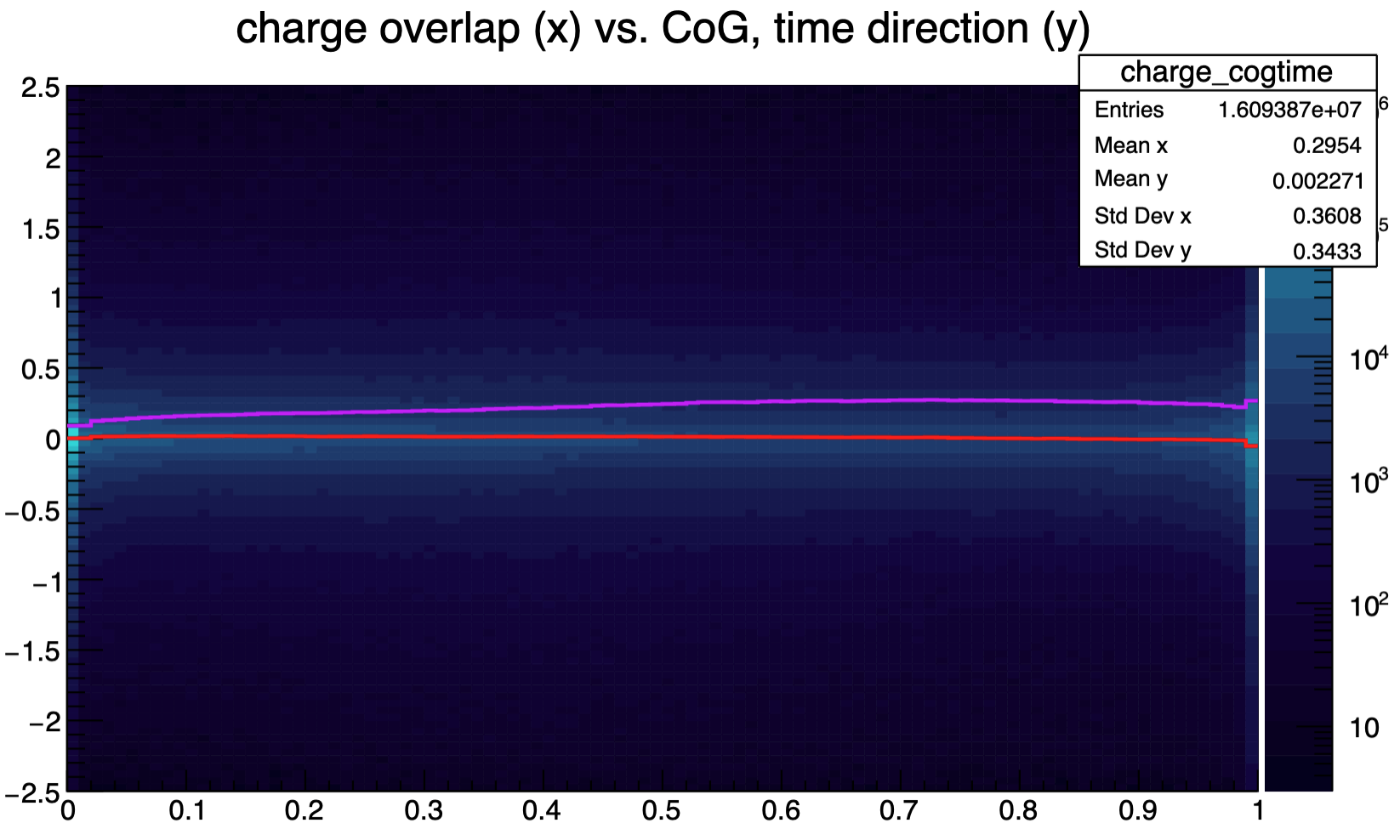
Centre-of-gravity resolution of NN, charge overlap
Booster of moral
~30 minutes ago, the clusterization project was presented in the physics forum by the ALICE ML group and outlined as the most interesting and benefical project for the entire collaboration from the ML group side 🥳
Plans & To-Do's
Title and text; High priority, medium priority, low priority; short term, mid term, long term; other
- Neural networks
- Cluster splitter network
- N-class classifier network: Probably only going until split-level 2 or 3. Higher gets really sparse in training data
- N-class regression network: Similar approach as the N-class classifier, but need to see how good performance is...
- Pass momentum vector to downstream reconstruction
- Cluster splitter network
- GPU developments
- Pull requests
- O2
- PR, ORT library integration: https://github.com/AliceO2Group/AliceO2/pull/13522
- PR, Full clusterization integration: https://github.com/AliceO2Group/AliceO2/pull/13610
- alidist
- PR, ORT GPU build: https://github.com/alisw/alidist/pull/5622
- O2
- Issues & Feature requests
- OnnxRuntime
- Coming up...
- Coming up...
- OnnxRuntime
- Pull requests
- QA task & algorithmic developments
- Include SC distortion simulation
- Use black PbPb data to evaluate performance and for training
- Redo 2D study with NN
- Cluster overlap is counted like this
-