Developments since last week
- Working on realistic physics simulations with adapted FST, switiching lowneut=false for faster sim and cleaner environment
- Added QA for ITS-TPC matching
- Added post-training QA after NN training is finished (on training data)
- Tried several different network architectures. Both classification and regression could not majorly benefit from change, fully connected still seems to be the best option so far.
- Worked on fitting class2 regression -> Limited by training data availability: 5 x 50 Ev. @ 50 kHz = ~1700 training data points
- Optimizing training data selection
Post training QA
(Regression, class 1, input size (577))

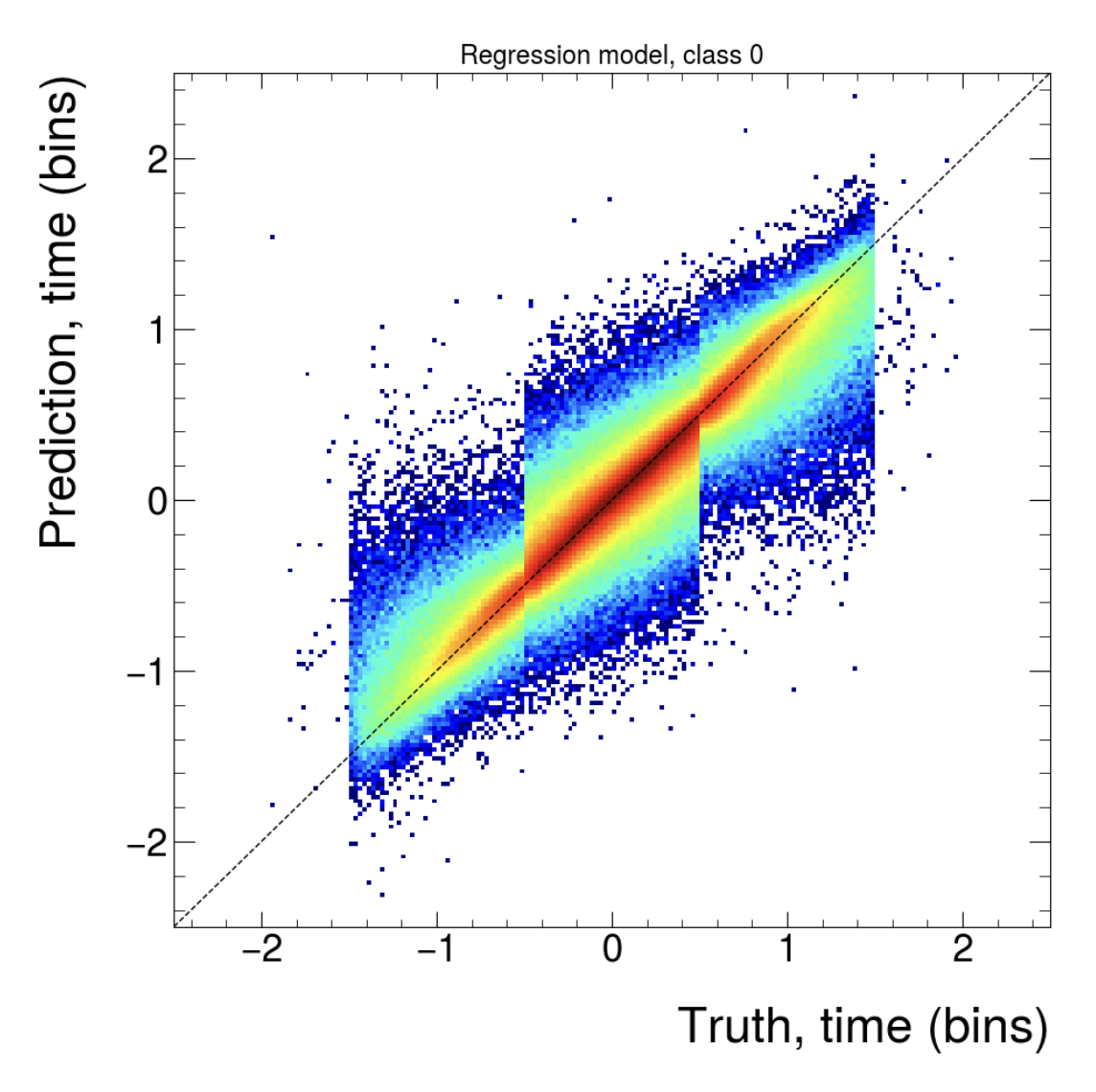

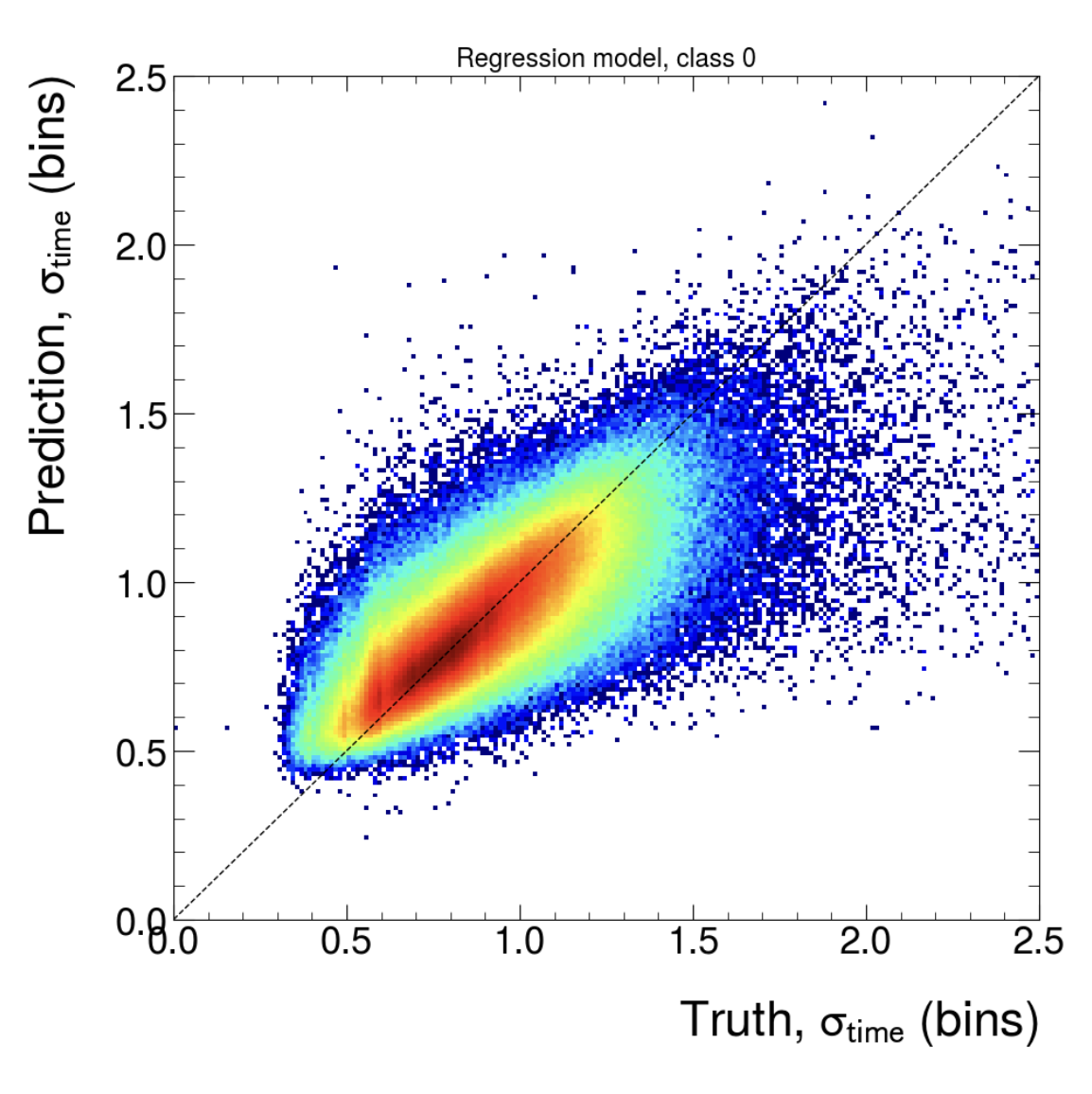

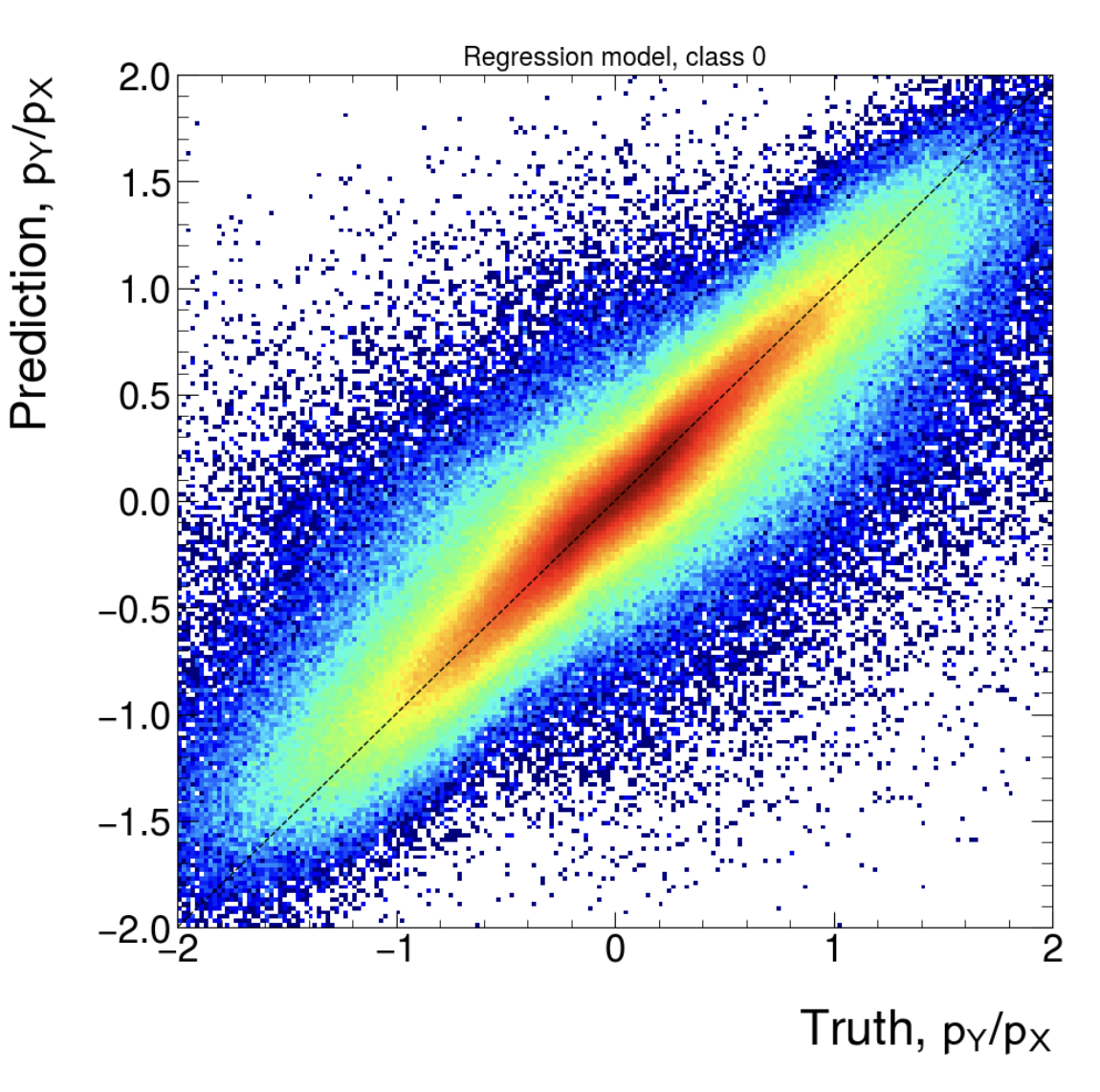

(Classification, class 1. First: Input size (177), Second: Input size (777))


ITS-TPC matching
(GPU CF: 30.4 mio. clusters, 266.4k tracks; NN: 27.0 mio. clusters, 254.4k tracks)


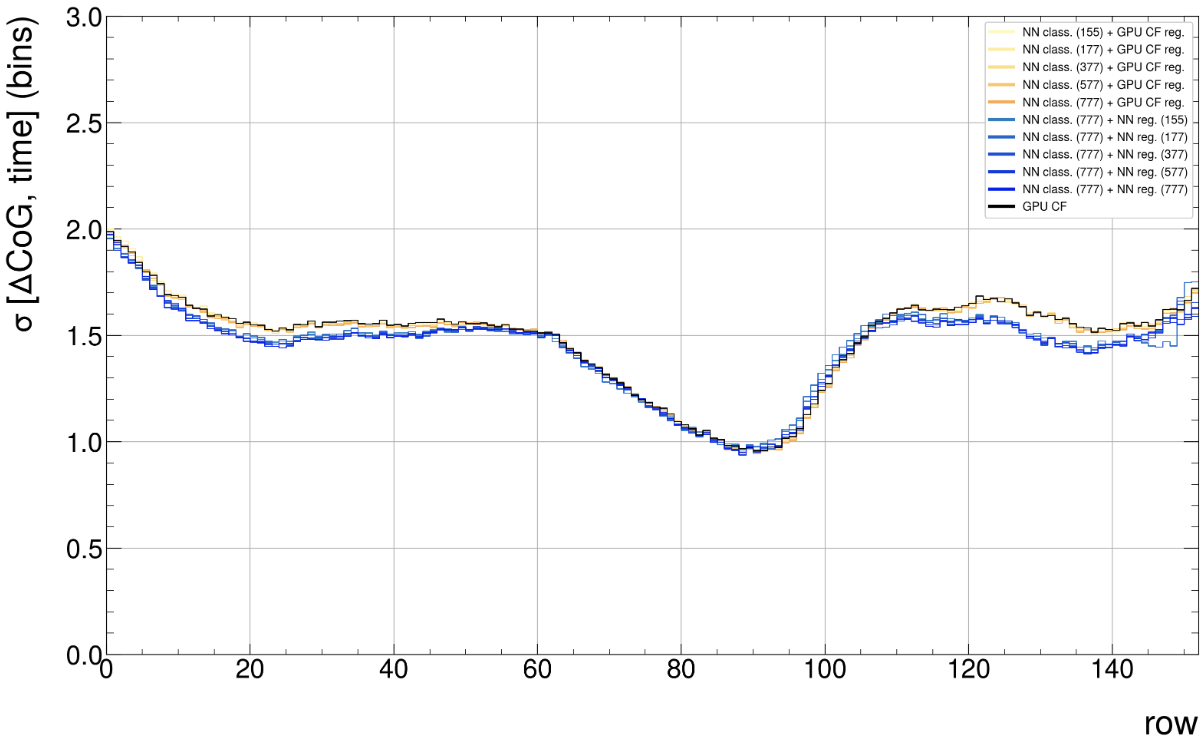
Interesting effect
We know the network learns a slightly better time-mean position of the clusters and produces a more gaussian shaped width distribution. This seems to result in smaller delta(cog time) cluster-to-track residuals, even though the network was not trained to optimize this (yet)