- Divide each dimension of the search space in M intervals (bins)
- Sample N points s.t. each interval (bin) has only one sample point
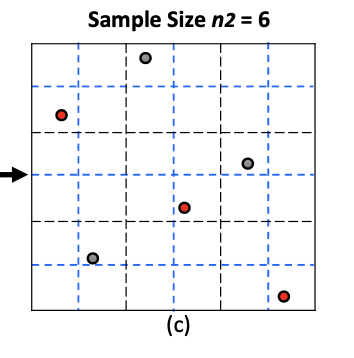
- This way the search space should be explored evenly
Should I try this type of optimisation or should I just try to apply a known external optimsation framework and somehow adapt it to this problem?
#define GPUCA_LB_GPUTPCCompressionKernels_step0attached 192, 2 where 192 is block_size and grid_size is 2 * Available Compute Unitsgrid_size which is not multiple of Compute Units?
