Alice Weekly Meeting: Software for Hardware Accelerators / PDP-SRC
→
Europe/Zurich
ALICE GPU Meeting
-
-
Speaker: Christian Sonnabend (CERN, Heidelberg University (DE))
Framework
- Major changes / bug-fixes / improvements: https://github.com/AliceO2Group/AliceO2/pull/14117
- GPU stream implementation
- I/O Binding -> Massive speed up improvement
- Coming up: Memory arena deallocation -> Decreases execution speed but releaves memory after each Run() function call
Physics
- Investigated loss of V0s: Just an issue with setting the right boundary values as configurable. no achieving >10% cluster reduction without loss of tracks
Current Focus
- Performance improvement of NNs -> Testing network and input size
- Reuse of memory for ONNX internal allocations
--------------------
Full 24as period (or at least the fraction where we have digits)
Selection
- cos(PA) > 0.9995
- Armenteros-Podolanski selections (shown below)
- NN cutoff reduces clusters by ~13%, Input size: 5x11x11
(Left: NN, Right: GPU CF)
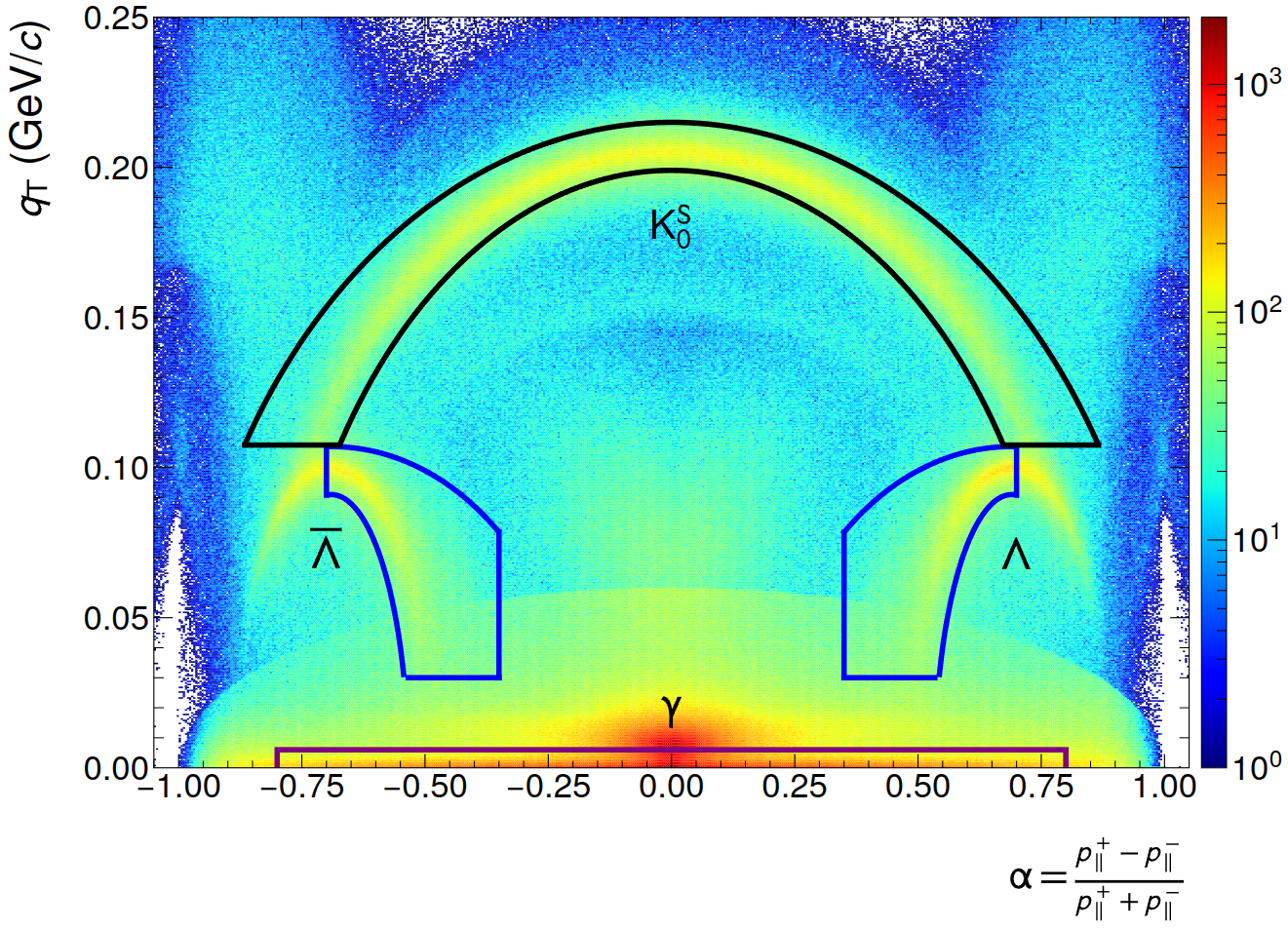
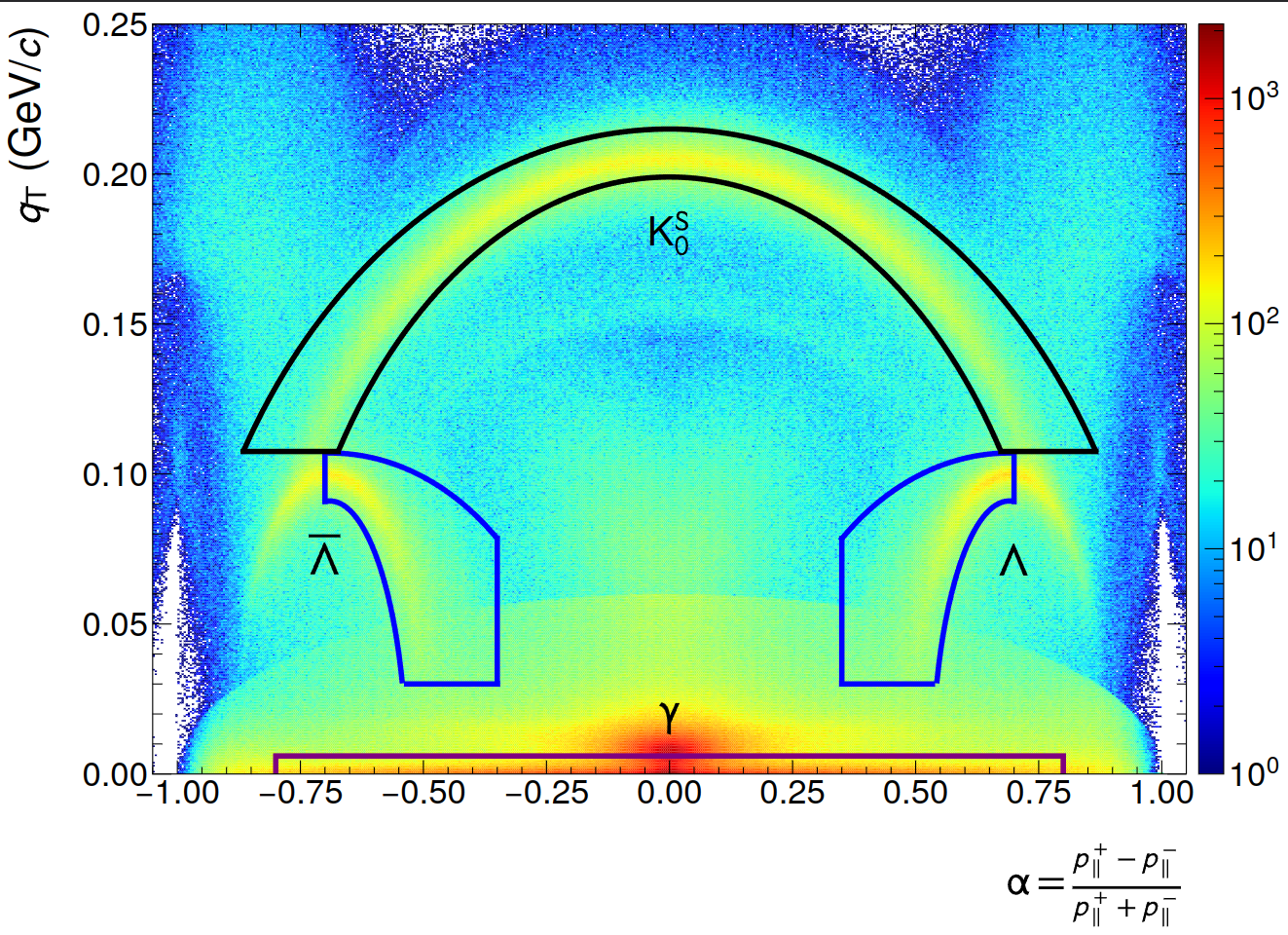
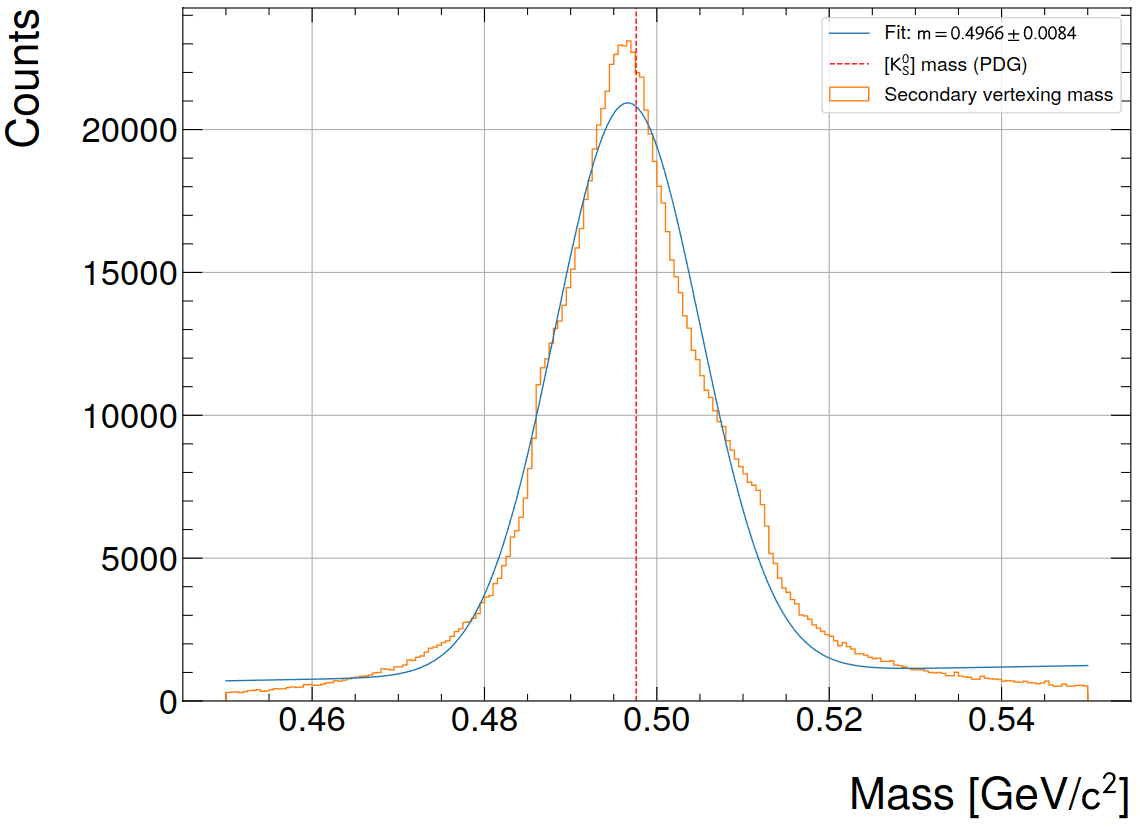



NN inference speed improvements
- Trade-off between memory consumption, compute speed and resulting quality: 3x9x9 input size, one / two layers with 128 nodes each. Achieves ~10-20 mio. clusters/s/GPU peak load (including data filling, evaluation of 2 NNs and data readout / publishing). Test on 3 lanes, 1 GPU.
- Arena memory clearing after each Run() function comes at some performance regression, but cannot be steered externally. Either clearing is done or not -> decided by the Run()-function internally with an external 0/1 option.
- Optimization: ONNX allows to set
kSameAsRequestedas arena option, which avoids new allocations (https://onnxruntime.ai/docs/get-started/with-c.html)
- Optimization: ONNX allows to set
- Tried CNNs but they are inherently "slow": PyTorch uses (N,C_out,H_out,W_out) layout. CNNs perform best when having a lot of channels. Parallelization is done over H,W dimensions, but not C dimension -> Subsequent layers with high number of channels are slow.
- ONNX with CUDA has some optimization for this after internal graph partitioning, but doesn't offer this functionality for ROCm
VRAM usage with 40k clusters per batch
- Input tensor: 40000x(3x9x9)x(3 lanes)xfloat = 116.6MB
- ONNX requests ~3% of the total GPU VRAM ~= 1GB
- Preciseness can be increased if needed

To-Do
- Use volatile memory at execution time for ONNX internal allocations (avoids GPU memory overloads while keeping the memory available for tracking)
- Potentially improve CCDB API calls
- What do we do with the momentum vector estimate? Currently not used at all.
- Major changes / bug-fixes / improvements: https://github.com/AliceO2Group/AliceO2/pull/14117
-
Speaker: Gabriele Cimador (Universita e INFN Torino (TO))
What has been done:
- Developed a unique Python interface to the standalone benchmark (https://github.com/cima22/O2GPU-autotuner)
- Easilly change kernel parameters defining dictionaries
- Method to measure mean kernel time
- Input: kernel_name, block and grid size, dataset
- Output: mean, std_dev
- Method to measure mean step time (e.g. TrackletConstructor, Clusterizer, GMMerger...)
- Input: dictionary of kernel_name, block and grid size and the dataset
- Output: mean, std_dev
- Without need to modify O2 code, only RTC used
- Developed the algorithm based on the Latin Hypercube Sampling, only for single kernels
- From first observations: minimum reached in less evaluations than grid search for a single kernel search
- Can dynamically refine the granularity of the search space
- Discovered dependency between GMMergerFollowLoopers and CompressionKernels_step0attached kernels

- Changing the parameters of GMMergerFollowLoopers alters the performance of step 0 of the compression kernels
- Looking at the profiler, it seems that write and reading operations of step 0 perform differently:
- WriteUnitStalled : The percentage of GPUTime the Write unit is stalled. Value range: 0% to 100% (bad).
Goes from 0.008% to 79% - VALUBusy : The percentage of GPUTime vector ALU instructions are processed. Value range: 0% (bad) to 100% (optimal).
Goes from 4.90% to 3.54% - R/WDATA1_SIZE : The total kilobytes fetched/written from the video memory. This is measured on EA1s.
Both metrics get reduced (i.e. less data movement)
- WriteUnitStalled : The percentage of GPUTime the Write unit is stalled. Value range: 0% to 100% (bad).
- This behaviour has not been observed for other kernels. This means that GMMergerFollowLoopers and Compression step 0 should be optimised together
- For this reason also grid search results for Compression step 0 where not around 1 when the default configuration was measured
WIP :
- Make the new algorithm work for multiple kernels (step optimisation)
- Obtain more data to effectively compare grid search with new algorithm for single kernels
To-Do:
- Test the new algorithm with the GMMergerFollowLoopers / CompressionKernels_step0 pair (4 dimension optimisation)
- If results are promising, test with a bigger step (e.g. TrackletConstructor step has 16 parameters)
- Use external optimisation framework via the new Python interface
Questions:
- If in the parameter file, a third integer is defined, e.g.:
#define GPUCA_LB_GPUTPCGMMergerFollowLoopers 256, 2, 200The kernel is executed with
grid_size = 200, instead of being a multiple of the Compute Units. - This might be interesting when refining the granularity of the grid size to be different than being a multiple of CUs, especially for kernels which run in parallel
- Developed a unique Python interface to the standalone benchmark (https://github.com/cima22/O2GPU-autotuner)
-
Speaker: Dr Oliver Gregor Rietmann (CERN)
Harbor Container Registry (plays the role of Dockerhub)
- Created a registry called ngt-wp1.7: https://registry.cern.ch/harbor/projects/3795/repositories
- Admin access for everyone in the e-group ngt-wp1-task1-7
- Images are scanned for vulnerabilites on push
- Pushing an image of the same name and tag will overwrite the image (retention policy due to 20 GB quota)
- Everyone can pull without login, e.g. docker pull registry.cern.ch/ngt-wp1.7/wp1.7-soa-wrapper:latest
- How to push: docker login registry.cern.ch
- In terminal, run: docker login registry.cern.ch
- Username is the Cern username
- Password is NOT the Cern password
- Instead go to the web interface (link above), top right corner --> User Profile --> Copy CLI secret.
- After successful login, run e.g. docker push registry.cern.ch/ngt-wp1.7/wp1.7-soa-wrapper:latest
- A robot account robot-ngt-wp1.7+github was created to push from Github actions.
GitHub repos naming convention (only a proposal)
REPONAME is a placeholder e.g. for "soa-wrapper". For a GitHub action (e.g. for testing), we set up two repos:- wp1.7-REPONAME (contains the code)
- wp1.7-REPONAME-image (contains a Dockerfile)
One repo manages the GitHub action image of the other. More precisely:- The second repo has a GitHub action that builds a docker image called wp1.7-REPONAME:latest and pushes it to our registry on harbor.
- The first repo has a GitHub action that runs in the container wp1.7-REPONAME:latest. This container needs all the dependencies installed.
GitHub Actions
We can now run GitHub actions on our private runners. Check the following two repositories for an example.Actions run by pull requests from forked repos need approval from a repo maintainer before they are run.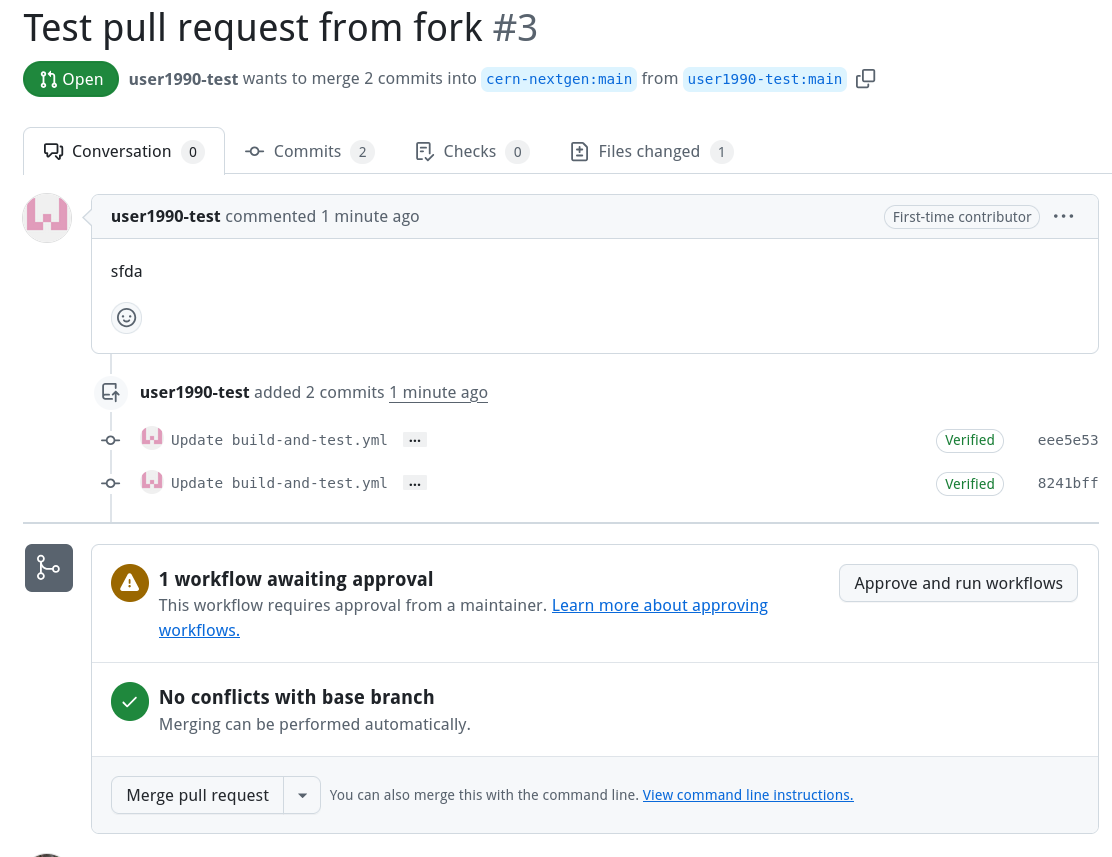
Permissions (only a proposal)
- We create a GitHub group on cern-nextgen called wp1.7.
- We give maintainer access to this group for every wp1.7-* repo.
- In this group we put every engineer that works on wp1.7 code.
Moreover, we give admin access to Ricardo Rocha on organization level. Otherwise he cannot debug the runners.
NGT Hackaton
- We compared different approaches for SoA libraries.
- People liked our approach for its simplicity. They have integrated it testwise in their code (e.g. CMSSW).
- We implemented a benchmark repo to compare the performance of these approaches:
https://github.com/cern-nextgen/wp1.7-soa-benchmark
-