Framework
- Major changes / bug-fixes / improvements: https://github.com/AliceO2Group/AliceO2/pull/14117
- GPU stream implementation
- I/O Binding -> Massive speed up improvement
- Coming up: Memory arena deallocation -> Decreases execution speed but releaves memory after each Run() function call
Physics
- Investigated loss of V0s: Just an issue with setting the right boundary values as configurable. no achieving >10% cluster reduction without loss of tracks
Current Focus
- Performance improvement of NNs -> Testing network and input size
- Reuse of memory for ONNX internal allocations
--------------------
Full 24as period (or at least the fraction where we have digits)
Selection
- cos(PA) > 0.9995
- Armenteros-Podolanski selections (shown below)
- NN cutoff reduces clusters by ~13%, Input size: 5x11x11
(Left: NN, Right: GPU CF)
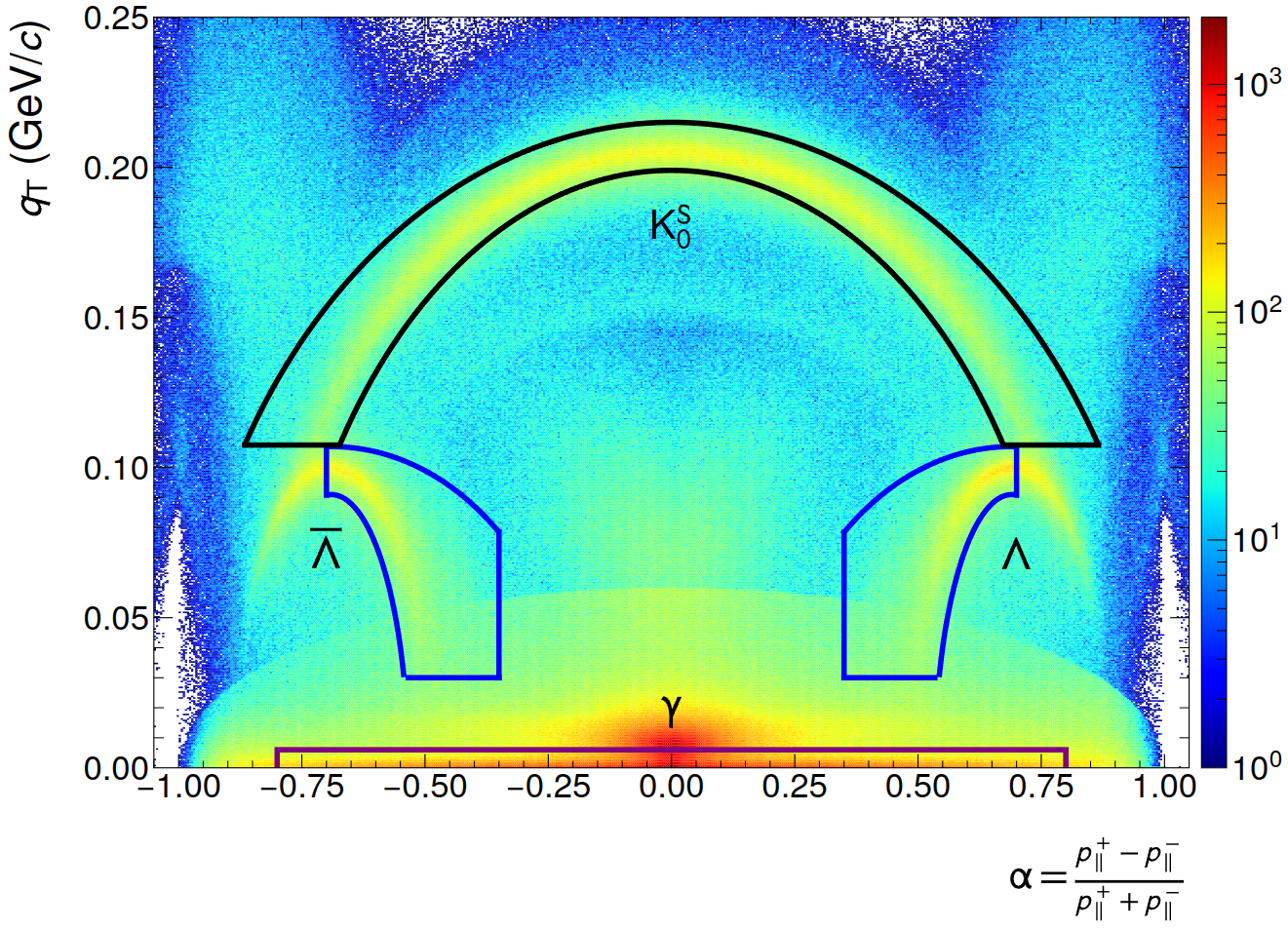
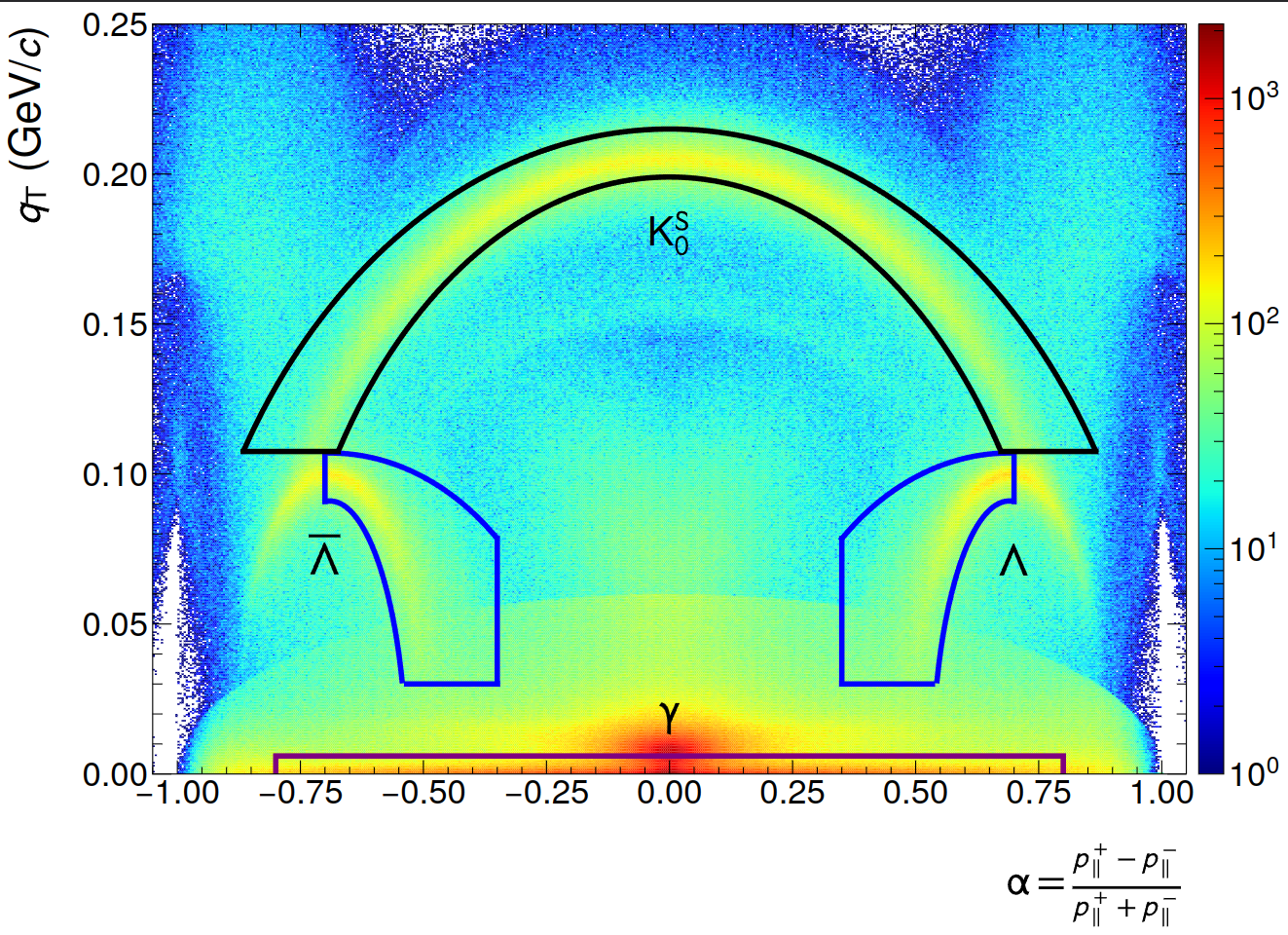
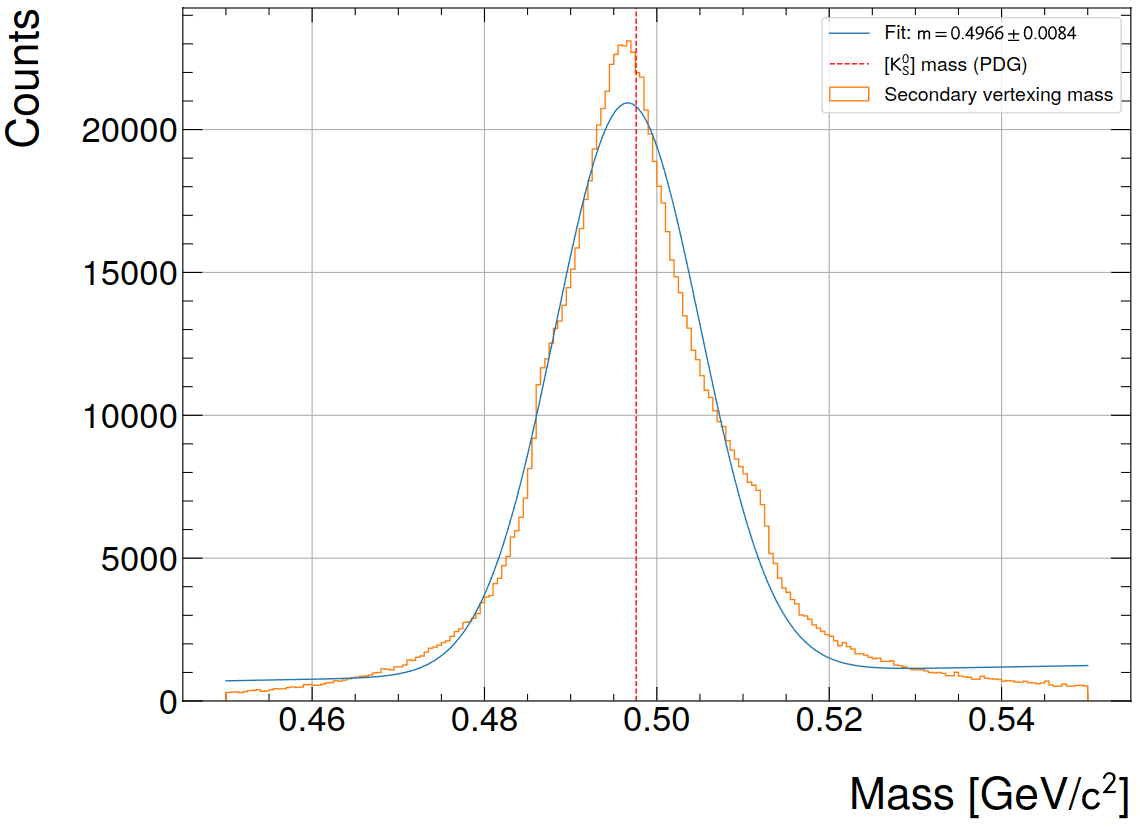



NN inference speed improvements
- Trade-off between memory consumption, compute speed and resulting quality: 3x9x9 input size, one / two layers with 128 nodes each. Achieves ~10-20 mio. clusters/s/GPU peak load (including data filling, evaluation of 2 NNs and data readout / publishing). Test on 3 lanes, 1 GPU.
- Arena memory clearing after each Run() function comes at some performance regression, but cannot be steered externally. Either clearing is done or not -> decided by the Run()-function internally with an external 0/1 option.
- Optimization: ONNX allows to set
kSameAsRequested as arena option, which avoids new allocations (https://onnxruntime.ai/docs/get-started/with-c.html)
- Tried CNNs but they are inherently "slow": PyTorch uses (N,C_out,H_out,W_out) layout. CNNs perform best when having a lot of channels. Parallelization is done over H,W dimensions, but not C dimension -> Subsequent layers with high number of channels are slow.
- ONNX with CUDA has some optimization for this after internal graph partitioning, but doesn't offer this functionality for ROCm
VRAM usage with 40k clusters per batch
- Input tensor: 40000x(3x9x9)x(3 lanes)xfloat = 116.6MB
- ONNX requests ~3% of the total GPU VRAM ~= 1GB
- Preciseness can be increased if needed

To-Do
- Use volatile memory at execution time for ONNX internal allocations (avoids GPU memory overloads while keeping the memory available for tracking)
- Potentially improve CCDB API calls
- What do we do with the momentum vector estimate? Currently not used at all.