Color code: (critical, news from this week: blue, news from last week: purple, no news: black)
CHEP Abstracts: https://indico.cern.ch/event/1471803/abstracts/ Deadline Dec. 19.
Sync reconstruction
Async reconstruction
- Need to investigate short GPU stall problem.
- Limiting factor for pp workflow is now the TPC time series, which is to slow and creates backpressure (costs ~20% performance on EPNs). Enabled multi-threading as recommended by Matthias - need to check if it works.
- New GPU architecture selection for async in O2DPG looks good, should be merged.
- Test with GPU GRID jobs at NERSC pending.
- Asked DPG to run first test with ITS tracking on GPU on EPNs.
GPU ROCm / compiler topics:
- Issues that disappeared but not yet understood: random server reboot with alma 9.4, miscompilation with ROCm 6.2, GPU getting stuck when DMA engine turned off, MI100 stalling with ROCm 5.5.
- Problem with building ONNXRuntime with MigraphX support.
- Need to find a way to build ONNXRuntime with support for CUDA and for ROCm.
- Try to find a better solution for the problem with __device__ inline functions leaking symbols in the host code.
- Miscompilation / internal compiler error fixed in new clang for ROCm 7.x, SDMA engine synchronization bug still not fixed.
- Serialization bug pending.
- Miscompilation on MI 100 leading to memory error pending.
- New miscompilation on MI 50 with ROCm 7.0 when RTC disabled.
- New miscompilation on MI 50 on ROCm 6.3 and 7.0 when RTC enabled, with latest software. Have a workaround for Pb-Pb data taking, but not compatible to latest tracking developments.
TPC / GPU Processing
- WIP: Use alignas() or find a better solution to fix alignment of monte carlo labels: https://its.cern.ch/jira/browse/O2-5314
- Waiting for TPC to fix bogus TPC transformations for good, then we can revert the workaround.
- Waiting for TPC to check PR which uses full cluster errors including average charge and occupancy map errors during seeding.
- Final solution: merging transformation maps on the fly into a single flat object:
- Sergey opened a new PR with the fixes and compatibility layer in, currently fails in the CI. Must be fixed, then Matthias can continue commissioning.
- Need to check the problem with ONNX external memory allocator.
- Next high priority topic: Improvements for cluster sharing and cluster attachment at lower TPC pad rows. PR: https://github.com/AliceO2Group/AliceO2/pull/14542
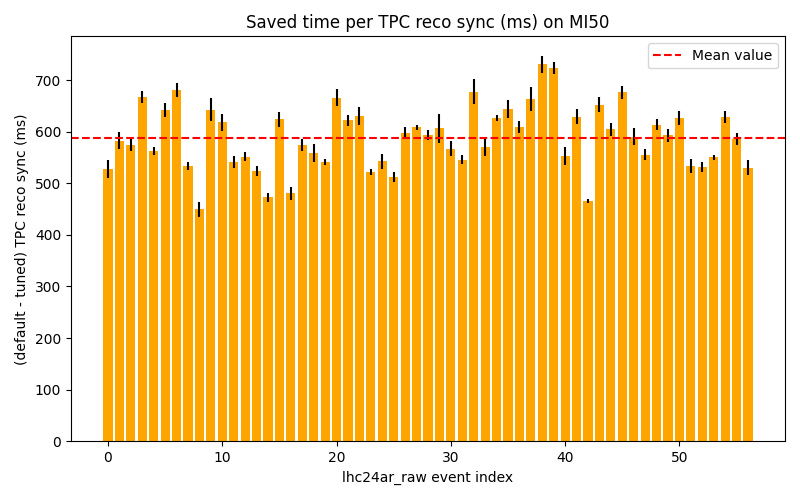
- New tracking is actually faster in the refit, but slower in the looper following. raw has more loopers than MC --> faster in MC, slower in raw overall. Can disable looper following to gain some speed for 50 kHz.
- TPC laser calib issue fixed, was a bug in tracking developments affecting only triggered data
- Large memory usage in pp on the GRID - fixed.
- Gain calib issue was due to new miscompilation.
- Next iteration of tracking improvements in draft PR: https://github.com/AliceO2Group/AliceO2/pull/14651
- Should get Gabriele's new parameters merged for Pb-Pb.
EPN GPU Topics: