ITS seeding vertexing news
Motivation
- Algorithm that attempts to find an approximation of vertices before tracking
- Used by ITS tracking to reduce combinatorics (thus ITS seeding vertexer --> ITS tracking)
- Basically tries to roughly find vertices without using full tracking
Current state
Algorithm uses first three layers of ITS, simplified explanation:
Compute tracklets made of two clusters on consecutive layers (0-1 and 1-2)Validates tracklets between layersExtend tracklets with a straight lineFor each line i
For each line j=i+1
If line already used, skip If Distance of Closest Approach (DCA) < cut, create a vertex, mark line as used
For each line kIf line is used, skipIf DCA < cut, add to current vertex and mark line as used
Sort all vertices by number of contributorsFor each "vertex cluster" k
For each "vertex cluster" m=k+1
if distance < cut, merge them
Sort all vertices by number of contributorsFor each cluster k
Promote the biggest one that passes some cuts as primary vertexPromote the others as vertices if they have low multiplicity and are close to the beam line
- Step 1 and 2 (tracklet creation and tracklet matching) already parallelized on CPU via TBB and ported to GPU by Felix S.
- Rest of the vertexing is purely serial (many sequential dependencies)
- Cannot directly parallelize
- Result dependent on order of evaluation of the lines
- Might miss some better associations because the lines had been already "used"
- This algorithm should be the last step for bringing all ITS tracking to GPUs
What to do
- Talked also with Matteo C.
- He tried to implement a histogram-based algorithm, he told me that it was not ideal due to too many assumptions
- There must be other ways to do this step
My idea
- Use this vertexing algorithm:
Jackson, David. (1997). A topological vertex reconstruction algorithm for hadronic jets. Nuclear Instruments and Methods in Physics Research Section A: Accelerators, Spectrometers, Detectors and Associated Equipment. 388. 247-253. 10.1016/S0168-9002(97)00341-0.
- Basically for each track, a "gaussian tube" is computed:
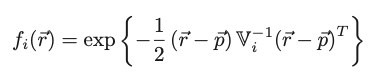
- Where r is a point in 3d space, p is the point of closest approach of track i to point r, and V is a covariance matrix to adjust the shape of the tube
- The closest the track to a point, the greater the value (gaussian shaped function)
- To find the vertices, compute the vertex function:
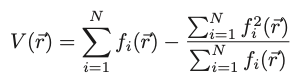
- So high peaks in the function automatically indicates vertex candidates
- Second term is to suppress contributions from only a line
- Tested this function with some pp TFs. Below projection onto the transverse plane, integrating over beam line:
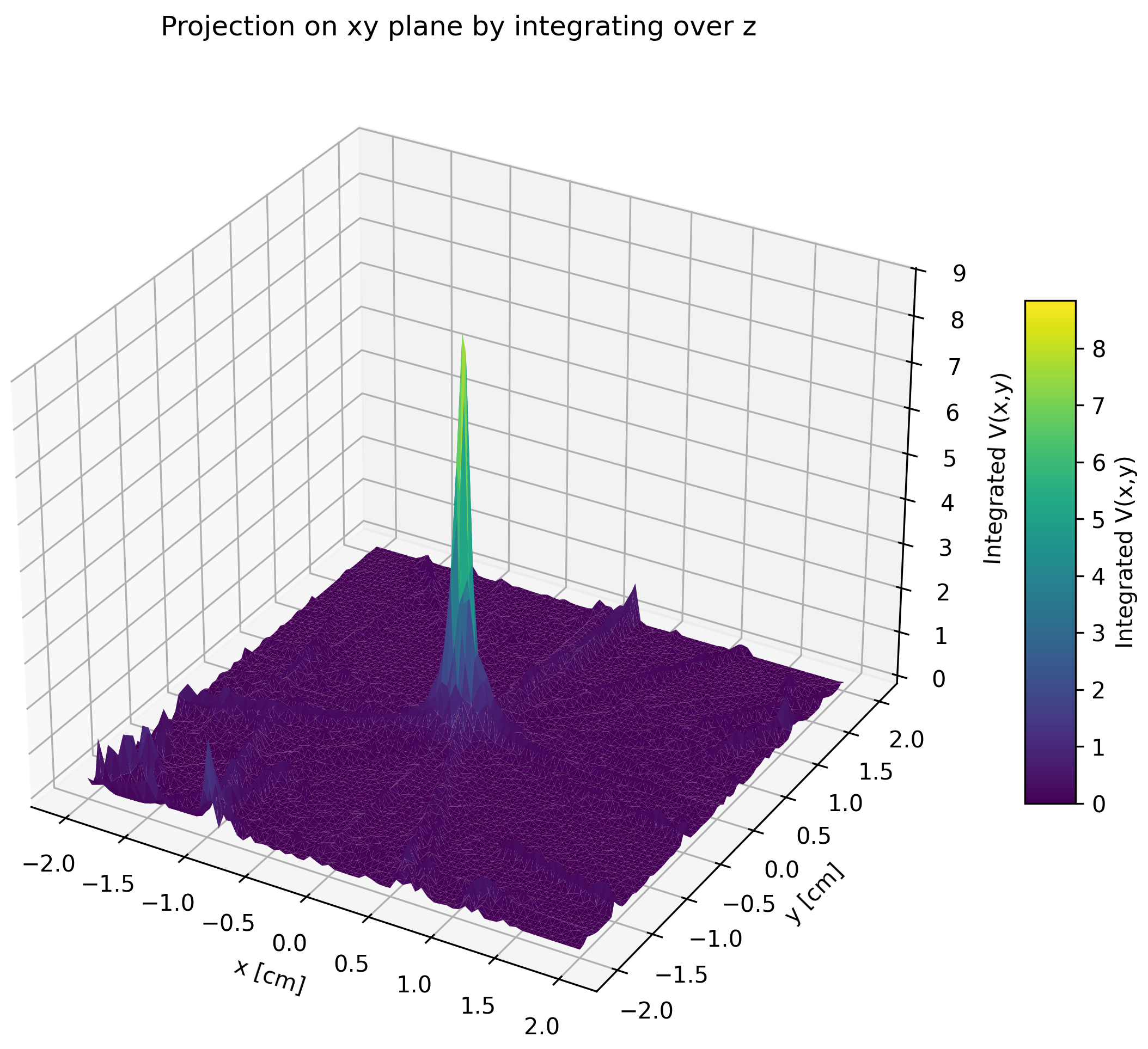
- Clearly most of the non-zero regions of the function peaks around the beam line (0,0)
- Computed the vertex function exactly at the points where the old vertexer was finding vertices, showing that indeed the function signals the presence of vertices (example for a ROF where 6 vertices where found):






- Meanwhile, it can signal also secondary vertices (different ROF than previous plots):

The algorithm in a nutshell
- With this function, it is necessary to find the peaks in the 3d space, and cluster them so to identify vertices
- High multiplicity vertices automatically signaled by high peaks
- By tuning the covariance matrix, the shape of the tube can be optimized, and thus the shape of the vertex function (more or less sensitive to noise)
- Since the function is > 0 when two or more lines passes closely, it is not necessary to scan the whole 3d volume
- Just compute the positions of each vertex made from a pair of lines and cluster the close candidates
- Algorithm parallelizable, over pair of lines
- Every thread computes the function for a pair of lines --> high compute load (good for GPU, let's see for CPU)
- Or even every block takes a candidate and all threads compute the vertex function in that candidate point
- In this way every pair gets a "chance to shine"
- Merge candidates that are close....still have to think
- Talked also with Ruben to understand how global vertexing works --> Density Based Scan for clustering
AOB
asked DPG for another test of the async prod. now with memory clearing implemented. (thanks David; hopefully this goes well :))
rewriting the tracking right now to implement the staggering (no eta on this, first have to show that it works)