High Availability
for Celery
Dima Petruk, RCS-SIS-OA
Supervisor: David Caro
Celery

Is an asynchronous task queue.
message broker to send and receive messages
result backend to keep track of the tasks’ state
Problem
Both message broker and result backend are single points of failure, thus if it goes down the system goes down
Message broker
Supports:
-
RabbitMQ
-
Redis
-
Amazon SQS
-
Zookeeper
Starting from Celery v3.0+ supports multiple brokers which are switched in a round-robin fashion if one is down
[
'transport://userid:password@hostname:port//',
'transport://userid:password@hostname:port//'
]In Celery v4.0+ this functionality doesn't work properly, doesn't switch to the next node and client fails (issue #3921)
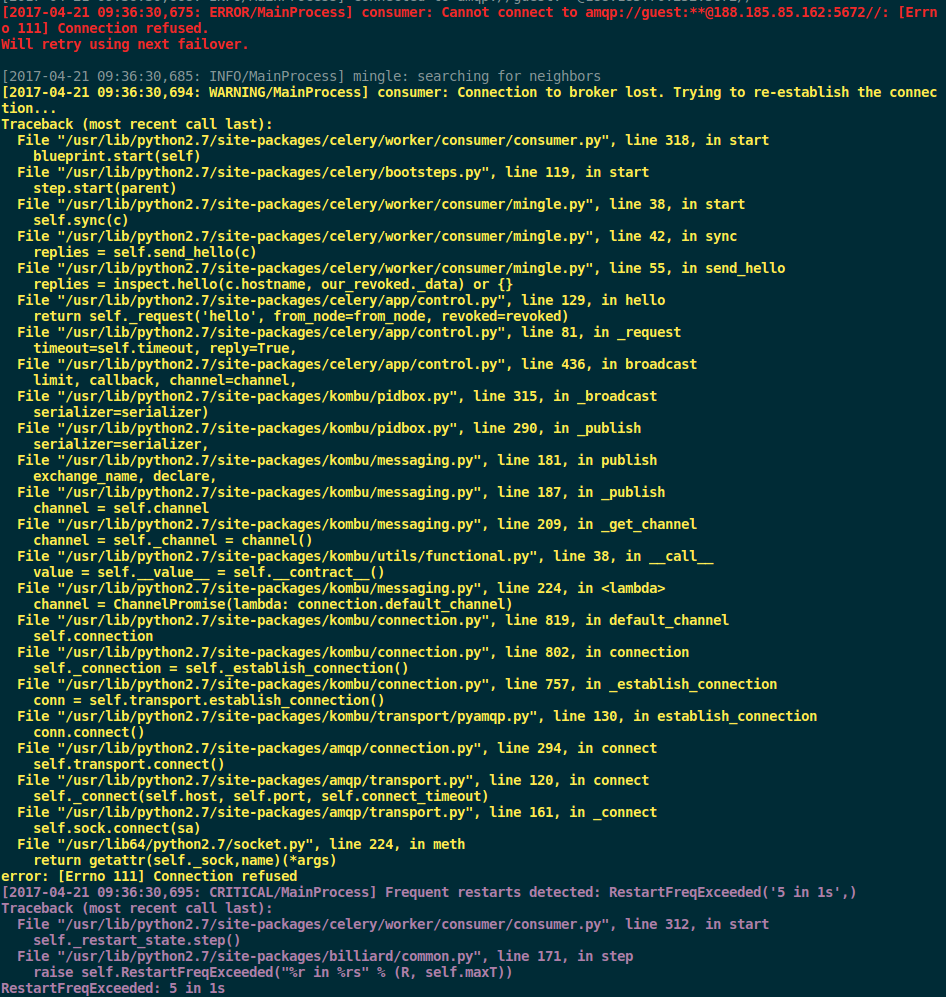
Although, there is workaround for this bug, but this is still a bug.
Solution is to run celery with
--without-mingle option
Result backend
Supports:
-
RabbitMQ
-
Redis
-
Memcached
-
SQLAlchemy
-
Django ORM
-
Cassandra
-
ElasticSearch
Does not support specifying multiple backends
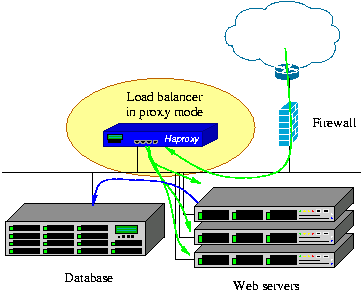
HAProxy
- free
- open source
- high availability
- load balancer
- proxy server
- fast
- efficient
- lightweight (in tests 3MB of RAM)
Redis Sentinel
Automatic failover
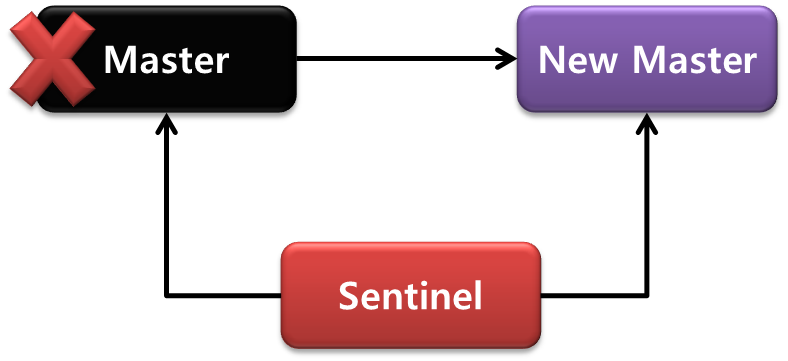
If master is not working, Sentinel promotes slave to master
HA message broker
- Setting up RabbitMQ cluster
- Adding HA policies (mirrored queues)
- Setup and configure HAProxy to have one basic node and others as backup nodes
- Define BROKER_URL as
'pyamqp://userid:password@HAProxy-IP:port//'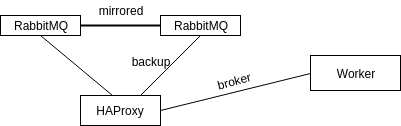
Is indeed a single point of failure, but we have a separate instance of HAProxy on each web and worker node, so if node goes down - a certain web server doesn't send tasks either.
HAProxy Cluster can be set up using keepalived.
HAProxy
Result backend
1) RabbitMQ cluster + HAProxy
Celery didn't do a good job of proper switching to another node after failover. So, for around 1 minute most of the tasks were lost and rabbitmq server is flooded with opened/closed connection requests
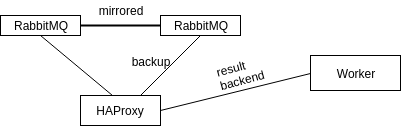
RabbitMQ cluster + HAProxy
=WARNING REPORT==== 4-Apr-2017::11:11:04 ===
closing AMQP connection <0.15366.16> (188.184.29.122:43780 -> 188.184.81.248:5672):
client unexpectedly closed TCP connection[2017-04-04 11:09:06,267: WARNING/MainProcess] consumer: Connection to broker lost. Trying to re-establish the connection...
Traceback (most recent call last):
File "/usr/lib/python2.7/site-packages/celery/worker/consumer.py", line 280, in start
blueprint.start(self)
...
File "/usr/lib/python2.7/site-packages/amqp/connection.py", line 530, in _close
(class_id, method_id), ConnectionError)
ConnectionForced: (0, 0): (320) CONNECTION_FORCED - broker forced connection closure with
reason 'shutdown'
[2017-04-04 11:09:09,292: ERROR/MainProcess] consumer: Cannot connect to
amqp://guest:**@188.184.29.122:5672//: Socket closed.
Trying again in 2.00 seconds...
[2017-04-04 11:09:14,309: ERROR/MainProcess] consumer: Cannot connect to
amqp://guest:**@188.184.29.122:5672//: Socket closed.
Trying again in 4.00 seconds...
[2017-04-04 11:09:18,327: INFO/MainProcess] Connected to amqp://guest:**@188.184.29.122:5672//Result backend
Requires at least 6 servers (3 master + 3 slaves), which is too much for its' needs as result backend
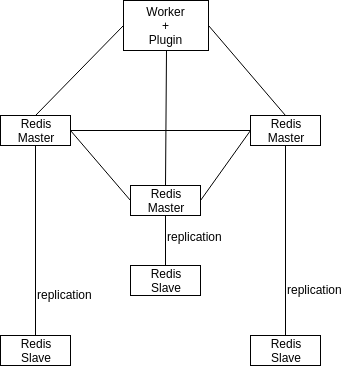
Result backend
3) Redis Sentinel + HAProxy
- Setting up Redis master/slave
- Setting up Redis Sentinel nodes (min 3, can run on the same node as Redis servers)
- Setting up HAProxy
HAProxy checks if node is master with TCP checks to Redis
- Define in celery config
CELERY_RESULT_BACKEND = 'rpc://:@HAProxy-IP:port//'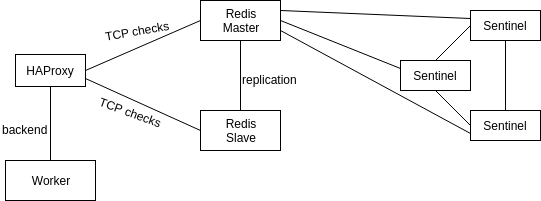
Redis Sentinel + HAProxy
backend bk_redis
option tcp-check
tcp-check connect
tcp-check send PING\r\n
tcp-check expect string +PONG
tcp-check send info\ replication\r\n
tcp-check expect string role:master
tcp-check send QUIT\r\n
tcp-check expect string +OK
server r1 188.184.94.146:7000 check inter 1s
server r2 188.184.88.217:7000 check inter 1sPERFORMANCE OVERVIEW
Goal
To compare 2 setups (with single point of failure and HA) on different types of tasks
Cluster environment setup
1) 1 task queue (Celery 4.0.2)
2) 1 flask app, which sends tasks to the worker
3) RabbitMQ cluster (2 nodes, mirrored queues)
4) 2 Redis servers in master/slave configuration
5) 3 Redis Sentinel servers
6) HAProxy with 2 endpoints:
- to 2 RabbitMQ servers (1 as primary and 1 as backup)
- to 2 Redis Servers (with TCP checks to see the role)
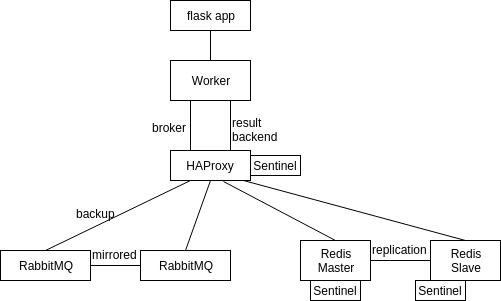
Standalone environment setup
1) 1 task queue (Celery 4.0.2)
2) 1 flask app
3) 1 RabbitMQ server
4) 1 Redis server (master)
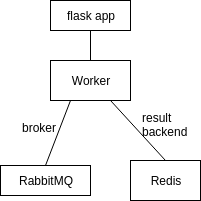
Task types
1) short task (returning constant), 10k times
2) long task (sleeping 10 seconds), 5 times
3) high I/O task (writing 1B 0's to a file), 10 times
4) high CPU task (computing factorial of 100k), 10 times
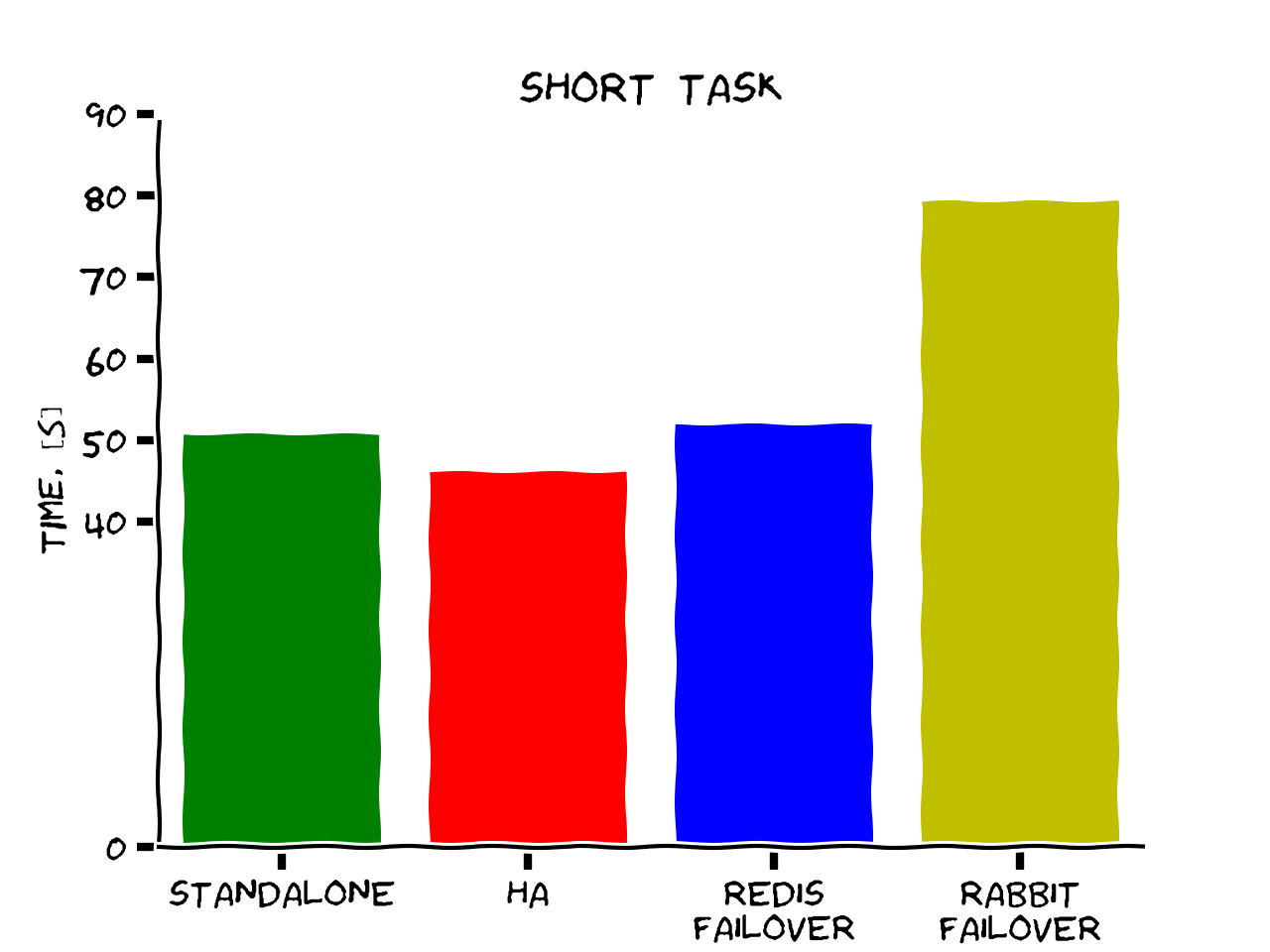
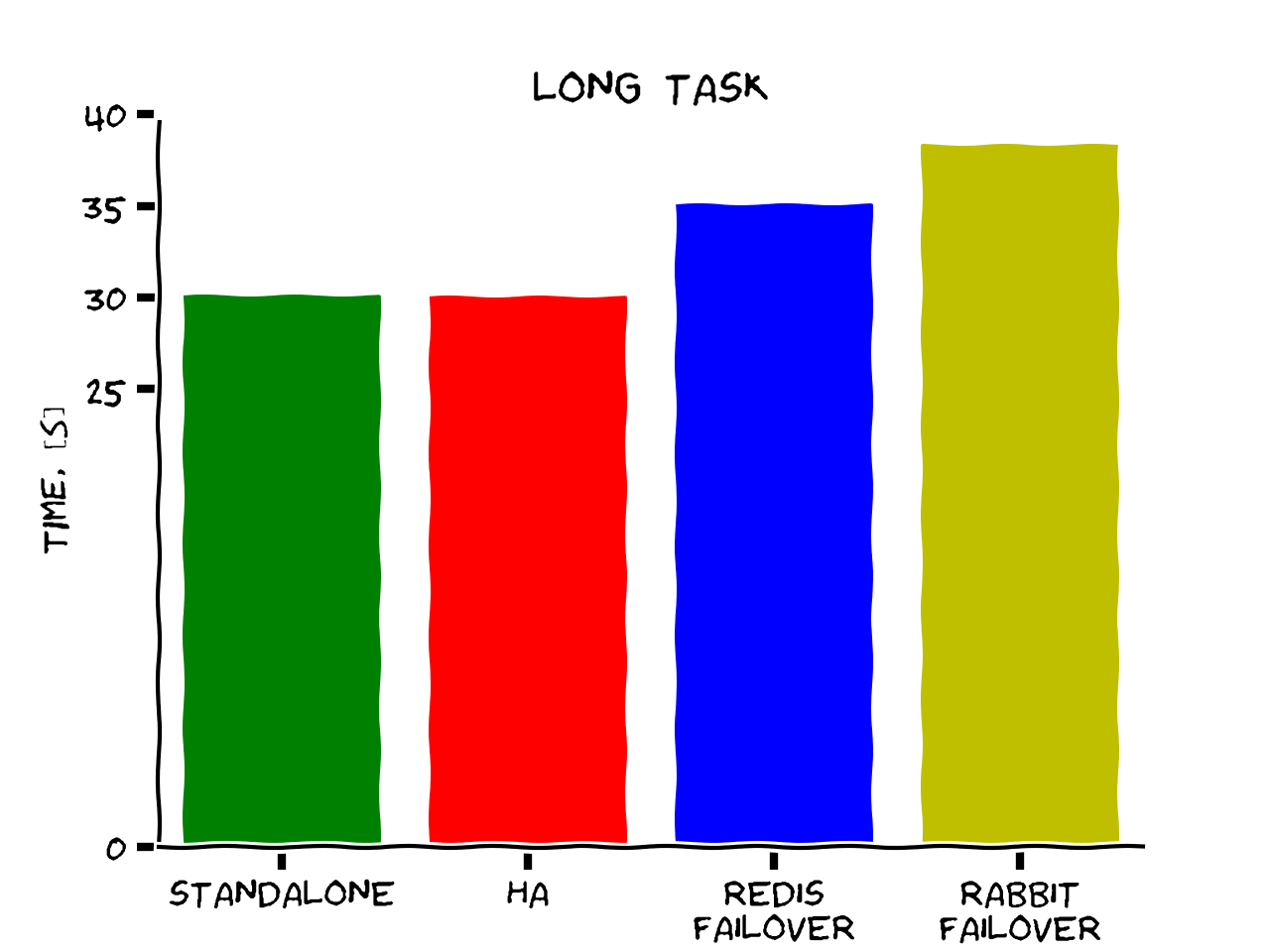
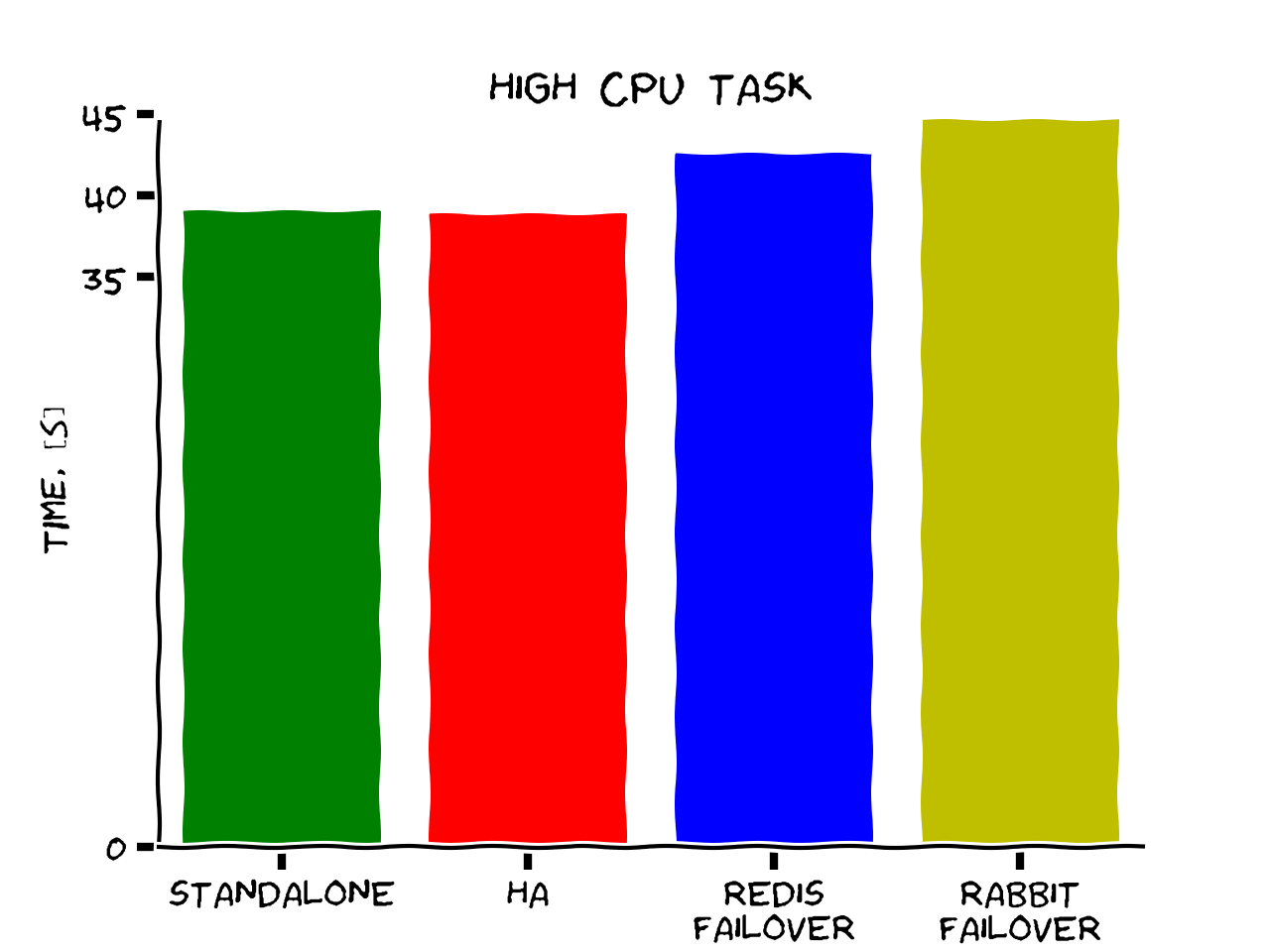
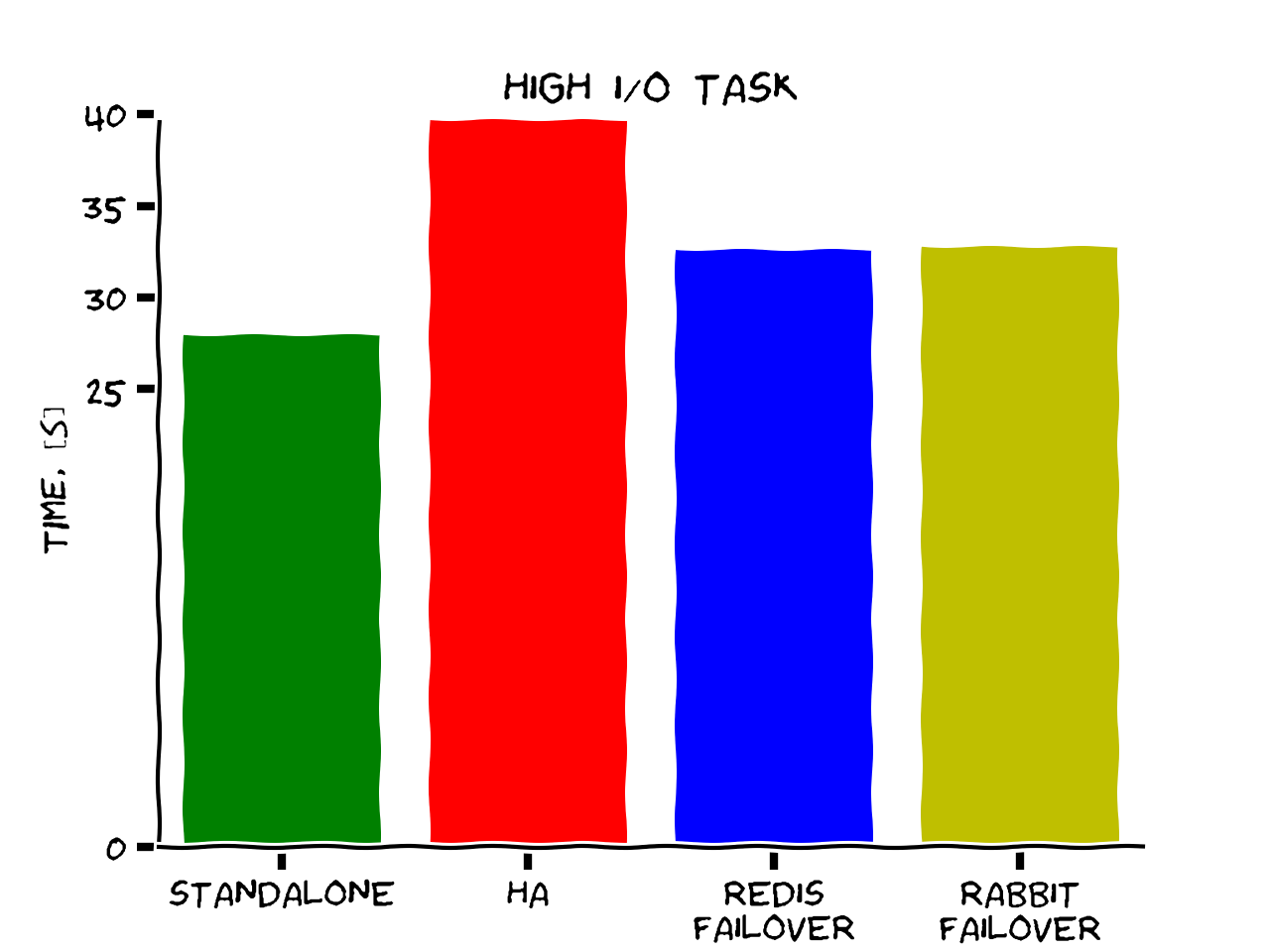
Conclusions
We were able to get a setup with:
-
HA for Celery, on both the broker and result backend
-
No lost tasks on failover
-
No significant performance penalty
-
Without need to change current code
-
With master switching times for Redis and RabbitMQ in order of 2-6 seconds
Thank You for the attention
Questions?
ha celery
By Dima Petruk