Choose timezone
Your profile timezone:
Zoom information
Meeting ID: 996 1094 4232
Meeting password: 125
Invite link: https://uchicago.zoom.us/j/99610944232?pwd=ZG1BMG1FcUtvR2c2UnRRU3l3bkRhQT09
Release (this week or next)
Large scale data deletion from life time model showed the dCache configuration changes to speed up deletion was highly successful. 11 Hz -> 61 Hz.
Seeing issues with PnfsMangers. We are using 6.2.23.
Chasing down transfer issues from BNL LAKE.
Chilled water issues caused an automated shutdown for ATLAS compute nodes. see plot for details
Updates on US Tier-2 centers
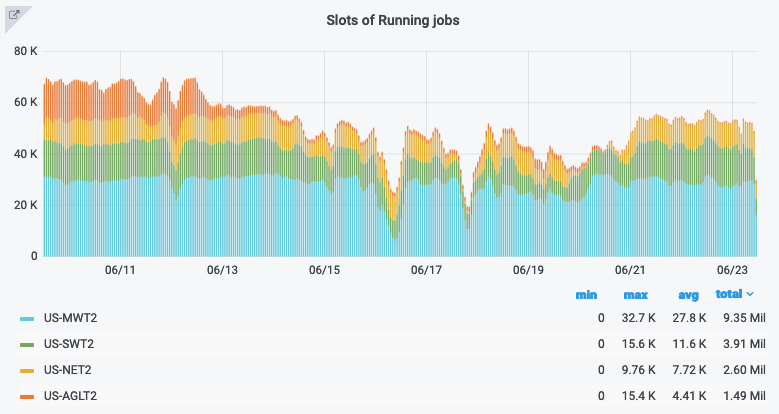
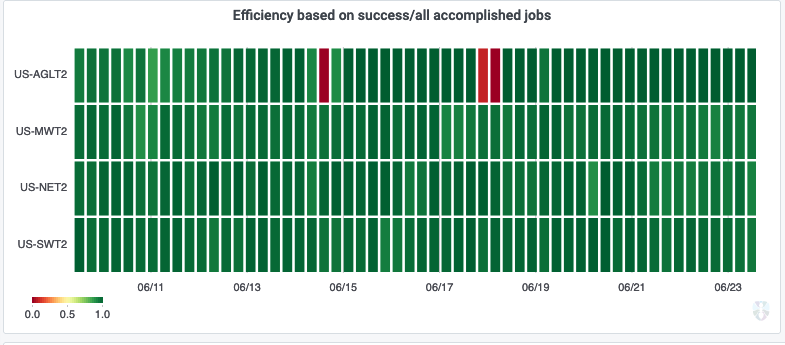
![]()
Infrastructure upgrades
- MSU moved first wave of equipment to Data Center on 14 & 15-Jun.
Included VMware and all dcache pool nodes.
Scope of first wave limited by (lack of) availibility of Juniper 10/25G switches.
Timing and choice of items was made to synchronize with UM site downtime.
Now have all switches.
Next wave will include about half of MSU T2 WNs.
Last wave(s) need to be synchronized with physics dept servers in neighbor room.
- UM replaced (almost) all rack switches (repurposing a few old ones).
Redundant uplinks at 100G.
Redundant paths to main campus and WAN.
Mix of Cisco (campus) and Dell (in room) brings some limitations.
Also replaced all network cabling, using fibers and transceivers everywhere possible.
Increased KVM coverage.
Increased switch serial port access.
- Despite extensive preparations and pre-labeling and sorting of cables,
and despite the 2 admin, 2 staff and 5 student task force
and despite UM Networking support
and despite working over the weekend
... this took much longer than anticipated.
- Status
Inter switch infrastructure was finished on Friday
Solving bugs and problems solved over the weekend.
dCache back online on Monday.
Queues in TEST mode on Tuesday.
Queues now back on AUTO on Wednesday (running mostly on MSU WNs)
- Remaining: More cabling of T2 WNs and UM T3
No GGUS tickets.
We've had a couple of power sag incidents in the past two weeks which has caused some problems. This may have caused a dip in production over the weekend, but it's unclear. Still investigating...
Xrootd 5.2.0 cluster, containerized is working. I guess we'll upgrade to 5.3.0 before going into production, re: Brian's notes.
Preparing for new worker nodes.
Preparing to upgrade networking to NESE.
UTA:
SWT2_CPB had an issue with CE due to remote spool directory. Combined with minor power work, we drained and reconfigured the spool directory to be local. So far, so good.
No issues at UTA_SWT2, but we are making progress with logistics necessary to retire cluster. Will start looking at retiring the storage first while using SWT2_CPB_DATADISK as storage location.
OU:
- xrootd proxy gateway on se1.oscer.ou.edu (OU_OSCER_ATLAS_SE) upgraded to 5.2.0, and http-tpc enabled. http transfers work, but tpc is failing because of a bug with TmpCA file creation which affects xfs file systems (which we have here). Will be fixed in 5.3.0.
- Today is OSCER cluster maintenance, so jobs are held, no jobs currently running. They will automatically start after maintenance is concluded.
1. Power cut didn't affect the Tier-3 very much (a 60% reduction in available slots for 2-3 hours) when many weren't used anyway.
2. GPFS vulnerability may require drain & reboot soon
3. Request from DOE / NPP to give large fraction of HTC resources to a short-deadline analysis until August. Tier-3 will have 40% reduction in quota through August
atlas-ml.org - all running fine
UC Analysis Facility
XCache
VP
Alarm & Alert
ServiceX
