Choose timezone
Your profile timezone:
Zoom information
Meeting ID: 996 1094 4232
Meeting password: 125
Invite link: https://uchicago.zoom.us/j/99610944232?pwd=ZG1BMG1FcUtvR2c2UnRRU3l3bkRhQT09
We have a request from Alessandra to fix our SRR set ups. There is a new script you can run to check a specific cloud.
For the US Cloud I did the following:
setupATLAS -3
lsetup adctools
voms-proxy-init -voms atlas
checkSRR.sh US
I will attach a the output as a separate file. The US cloud has some issues to fix here.
Next week is Supercomputing
Release (this week)
Token Transition
# ATLAS production
SCITOKENS /^https:\/\/atlas-auth.web.cern.ch\/,7dee38a3-6ab8-4fe2-9e4c-58039c21d817/ usatlas1
# ATLAS analysis
SCITOKENS /^https:\/\/atlas-auth.web.cern.ch\/,750e9609-485a-4ed4-bf16-d5cc46c71024/ usatlas3
# ATLAS SAM/ETF
SCITOKENS /^https:\/\/atlas-auth.web.cern.ch\/,5c5d2a4d-9177-3efa-912f-1b4e5c9fb660/ usatlas2dCache upgrade to latest golden release. bug in SRR - dCache had work around - to be fixed
New VP site and VP queue - to avoid injection of local xcache address that caused problems for users jobs using data from BNLLAKE_DATADISK.
Shigeki will produce a list of questions for a collaboration btwn BNL SDCC, dCache, ATLAS ADC, Rucio, FTS dev. goal to provide enough metadata to efficiently use TAPE system at Teri 1 site.
Updates on US Tier-2 centers
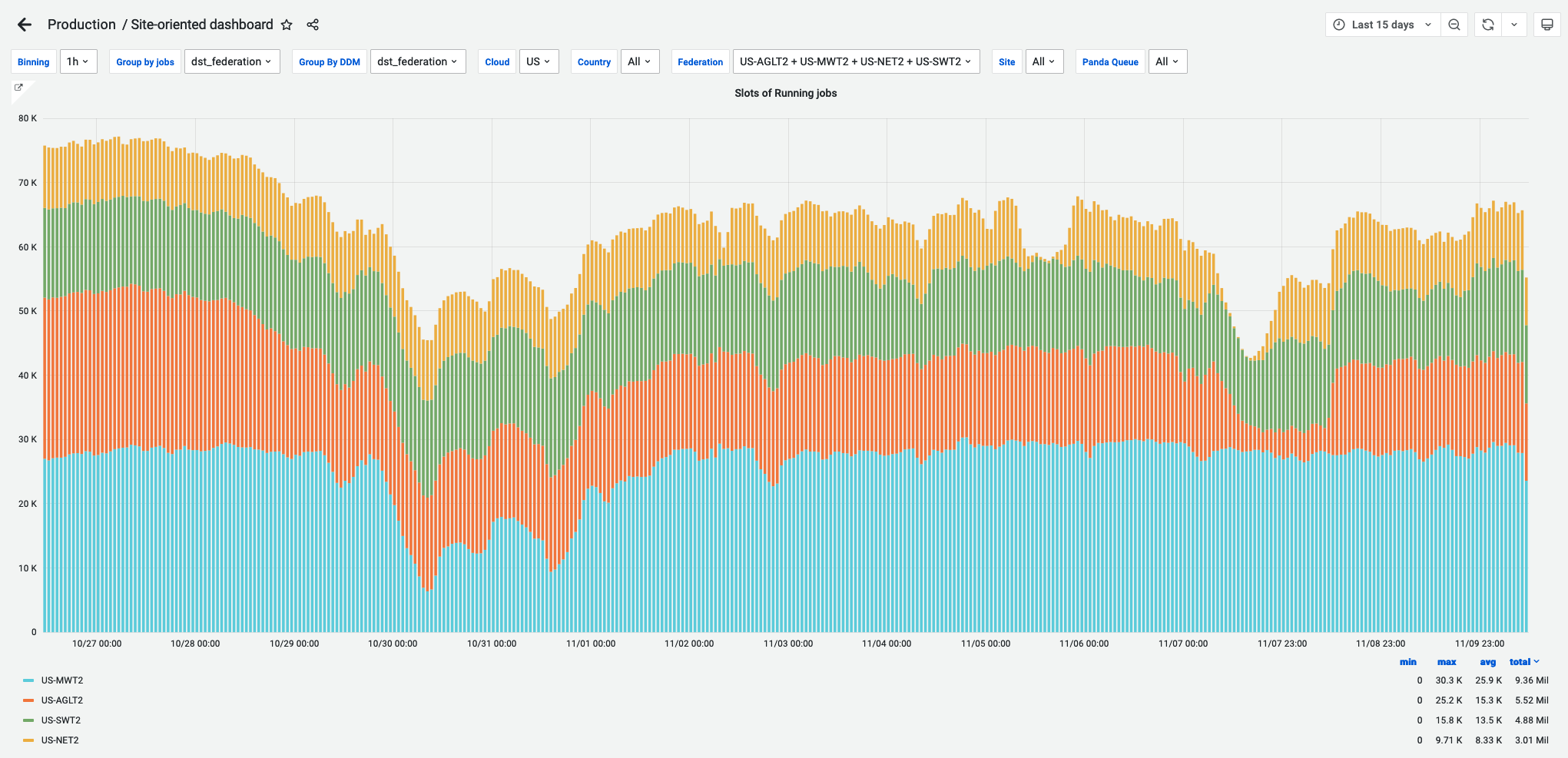

We still see problem at OU. I finally was able to repeat this issue at SLAC.
For a long time, SLAC ran xrootd 5.3.0 from xrootd repo, and we never saw the problem. OU runs xrootd 5.3.1 from OSG 3.5upcoming and saw the problem of accumulating TCP CLOSE_WAIT in short period of time.
Since Oct 28, SLAC switched to use the same very OU use and we saw this problem after 9 days. SLAC has since to switched to xrootd 5.3.1 in EPEL to see if we can repeat the problem
Hardware
MSU site installed 3x R740xd2, now doing benchmark on different stripe size of the RAID6.
Service:
Update dCache from 6.2.29 to 6.2.32 to address security issues. The update was smooth.
HS06 benchmark:
We run it on 2 types of CPUs (Intel(R)Xeon(R)Gold6240R and Intel(R) Xeon(R) CPU E5-2650 v2), there are 2 discoveries: 1) the new HS06 score is between 6-8% higher than the old number (with the same benchmark toolkits)but different kernel and firmware. 2) We compare HS06 score with and without BOINC jobs running in the background, and having BOINC reduces the score by 1.32-2
Incidents:
Removing DBRelease file by ADC caused BOINC jobs failing and mis-accounting.
Xcache server sl-um-es4 crashed because of one disk failing. We replaced the disk (raid 0), recreated the instance for xcache.
On 11/7/2021 , from 3am UTC, SrmManager on dcache head nodes (head01) started to fail, and it caused file transfer low efficiency (60% failure), and rucio deletion failure (datadisk was almost full), and the AGLT2 PanDA queue to be also set to test status (this drained the site to only 20% job slot usage) due to over 60% failure on the jobs. We first restarted dcache on the head node, and it fixed the rucio deletion failure issue. Later we still saw low transfer efficiency, and the problem was traced back to one xrootd door(dcdmsu01) and one pool node (msufs04), we restarted dcache on both nodes and the transfer efficiency started to improve, but we saw more errors from other pool nodes, so we ended up restarting dcache on all nodes which eventually solved all the problems.
Updated dcache from 6.2.30 to 6.2.33 for security fix.
There were a handful of 1099 errors on a few workers at UC that all seemed to be failing to download the same file/set. Manually attempting to download the file succeeded.
Found a pilot bug where pilot would tell Panda the job failed, but the job is still running happily on the compute nodes until completion. Found while troubleshooting the 1099 errors and a spur of "lost heartbeat" errors.
Swing compute, for the move, is being benchmarked. Swing storage is in production.
First physical machine move is scheduled for December 6th.
UIUC:
- finalizing infrastructure changes to support the new compute purchase (shipment ETA this week)
- ICCP (Chit) is rebuilding the OS image for the SLATE node and Lincoln has offered to configure software
SRR reporting endpoint updated => gridftp not a used protocol in CRIC
Bump from used space > total space briefly...
Issue with migration slowing GPFS down too much, resulting in staging errors.
Smooth operations otherwise
Low level of squid failovers...
We're mostly working on preparations for new workers, networking upgrade, NESE Tape preparation and preparing for adding more NESE Ceph storage.
SWT2_CPB:
- System generally running smoothly
- Continue to monitor XRootD on SE gateway for hang-ups
- Adding additional hosts to distribute the load
UTA_SWT2:
- Decommissioning of the storage essentially done
- Working with data center personnel to schedule powering off, disconnecting network, etc.
- Final step is physically moving the hardware back to campus
OU:
- Generally smooth running, except
- XrootD on SE gateway also keeps hanging up
- Continue investigating with Andy, Wei, and rucio developers
- Some dark data on OU_OSCER_ATLAS_DATADISK, investigating
- Dark data was also responsible for DATADISK being black listed for writing, which caused additional job failures, since rucio refused to stage-out jobs. rucio is supposed to still stage-out, and they found a bug which they're working on.
XCache
VP
ServiceX
Rucio