Choose timezone
Your profile timezone:
Developments on real data
Thanks to David, Ruben & Jens there is a workflow which converts TF data to digits, clusters and tracks. This will be used then for the neural network training in the following time
Developments on reconstruction
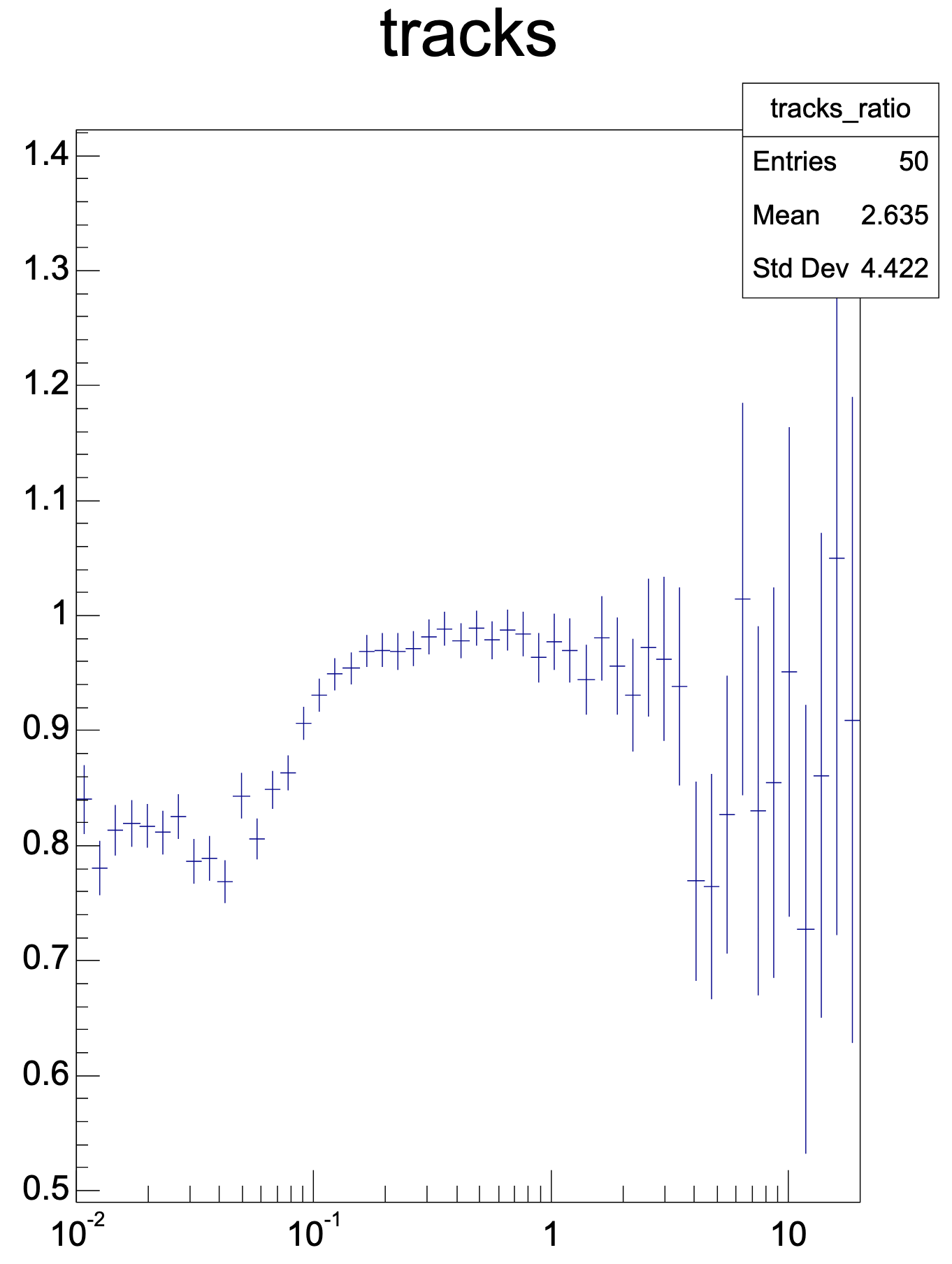
QA output works directly for NN clusterization in the tpc-reco workflow. Dumping histograms reveals strengths and weaknesses of the NN approach. Created root macro to make ratios of histograms and TGraphAsymmetricErrors to create ratio plots. Not going into full detail today.
Tracks as network / native (1: All tracks vs pT; 2: Efficiency of primary tracks vs pT; 3: Clone rate of primary tracks vs pT)
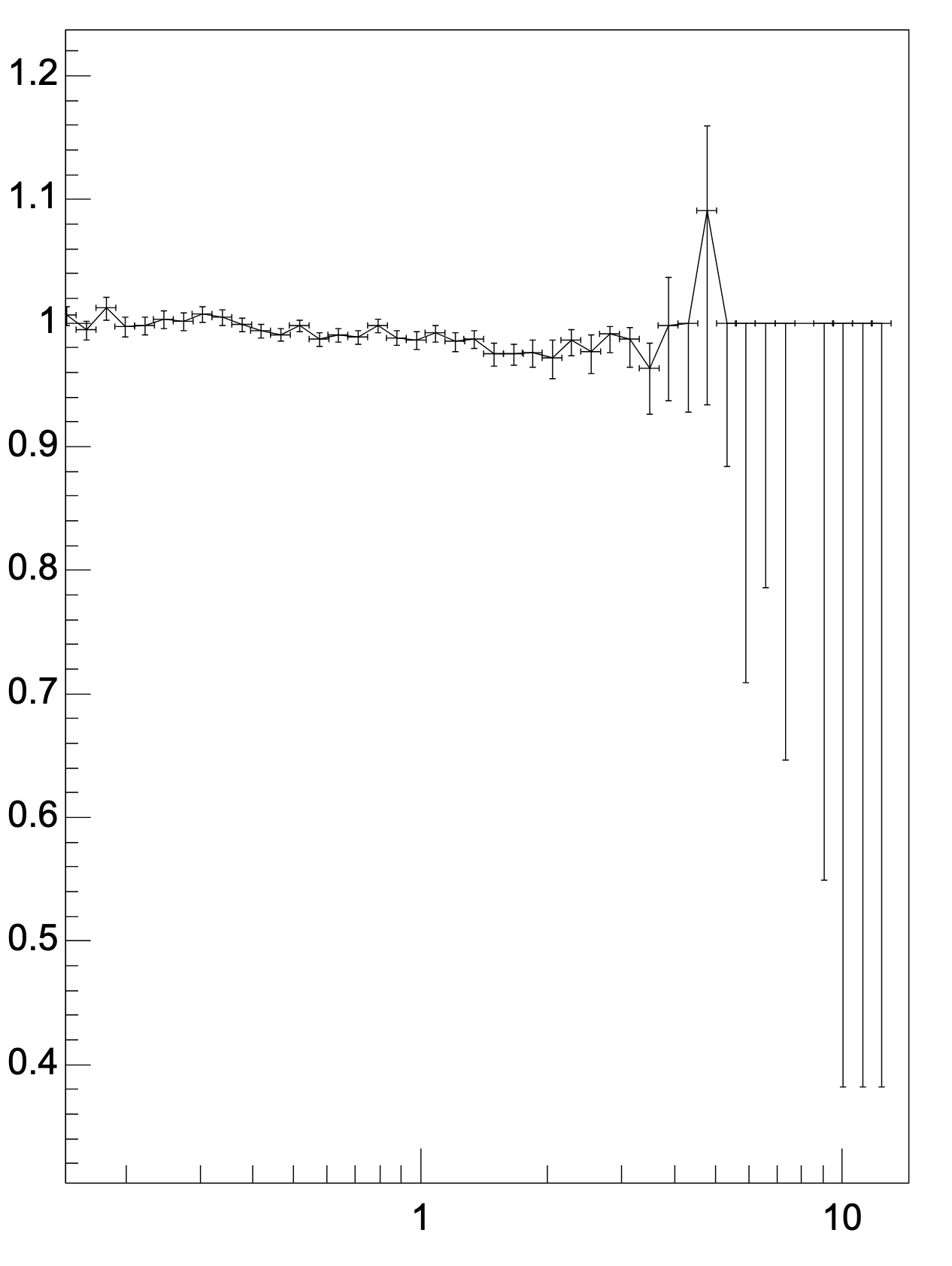
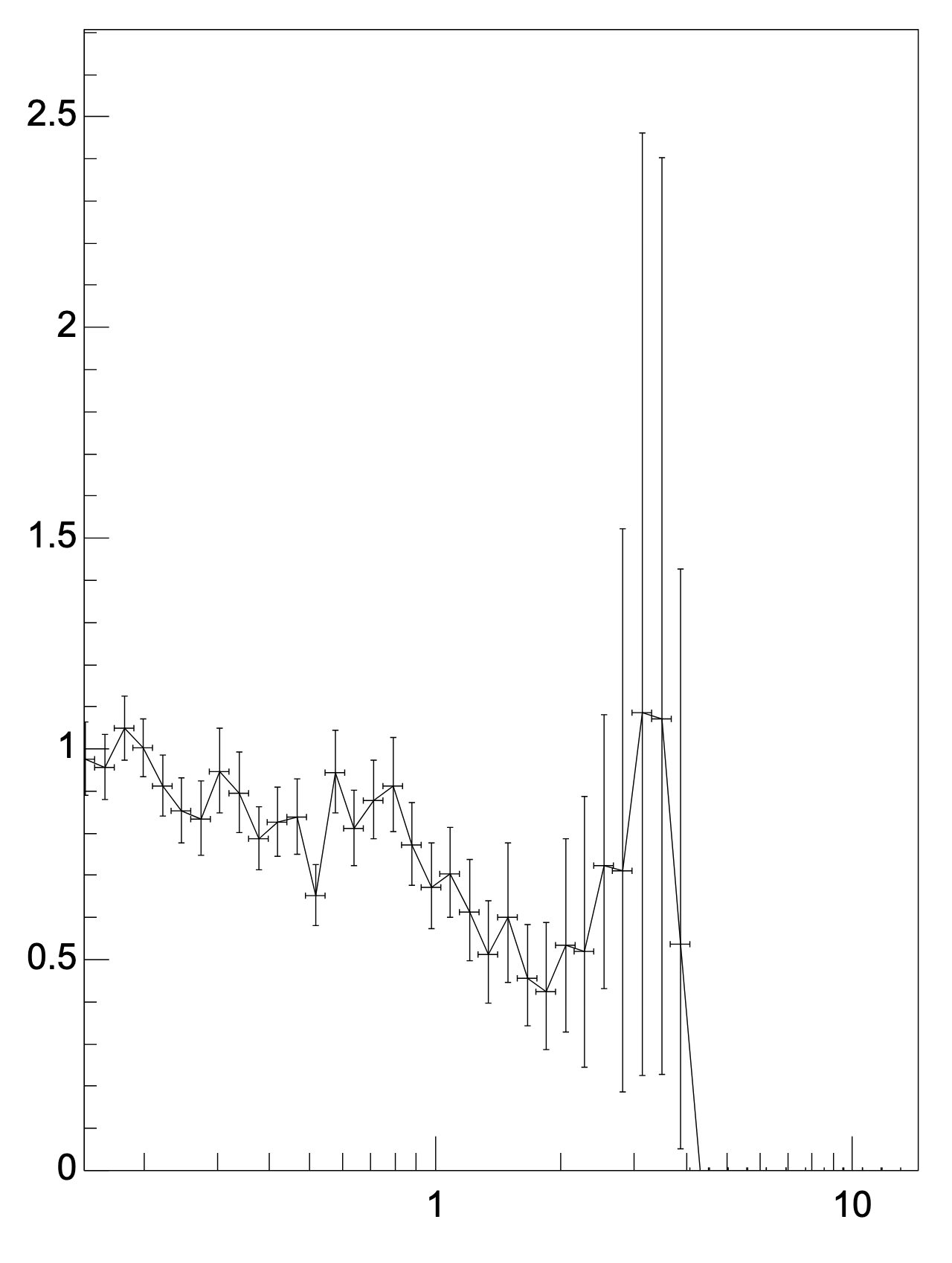
Clusters as network / native (1: Cluster attachment to tracks, 2: Attached physics clusters; 3: Fake clusters)
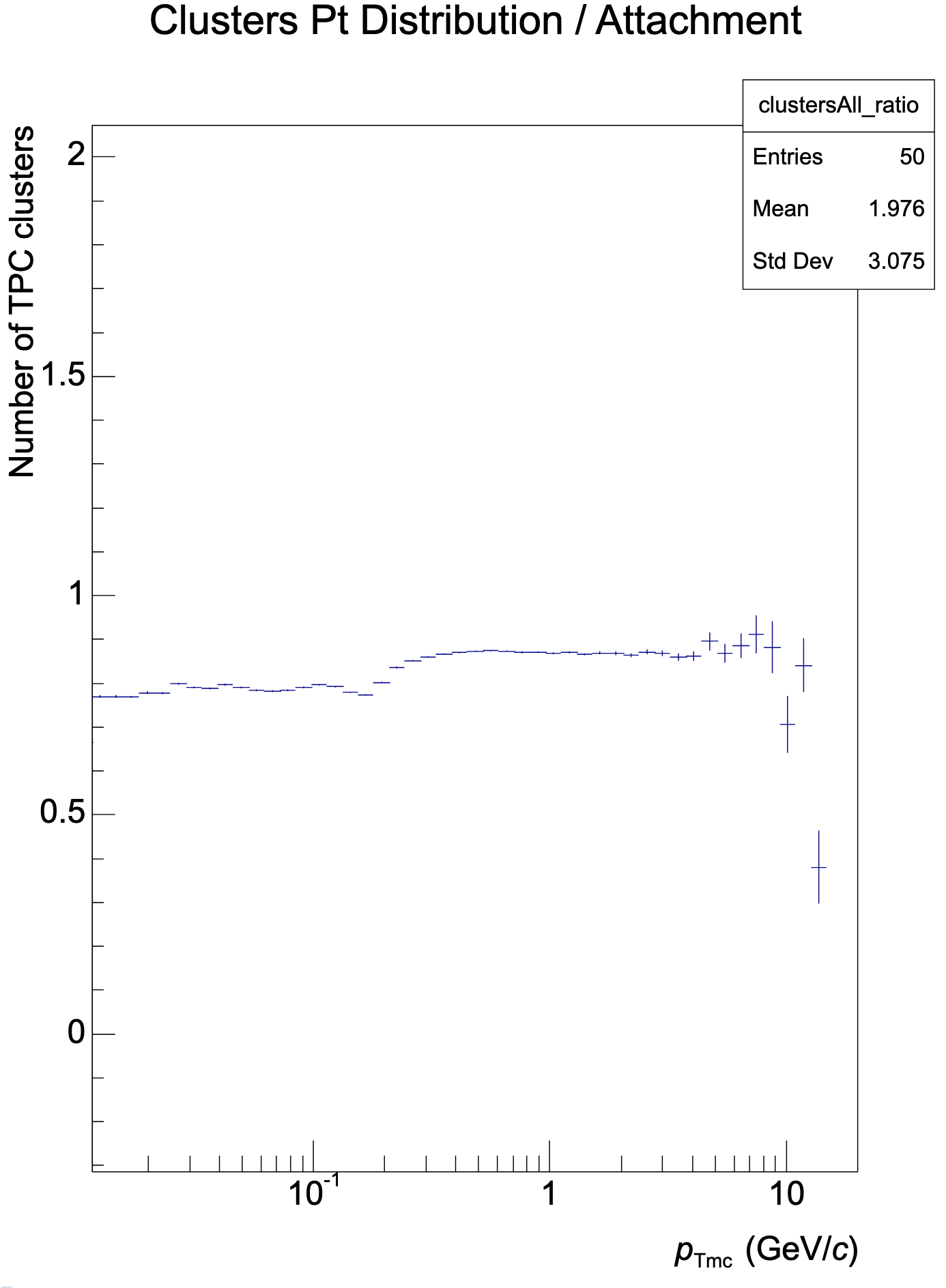
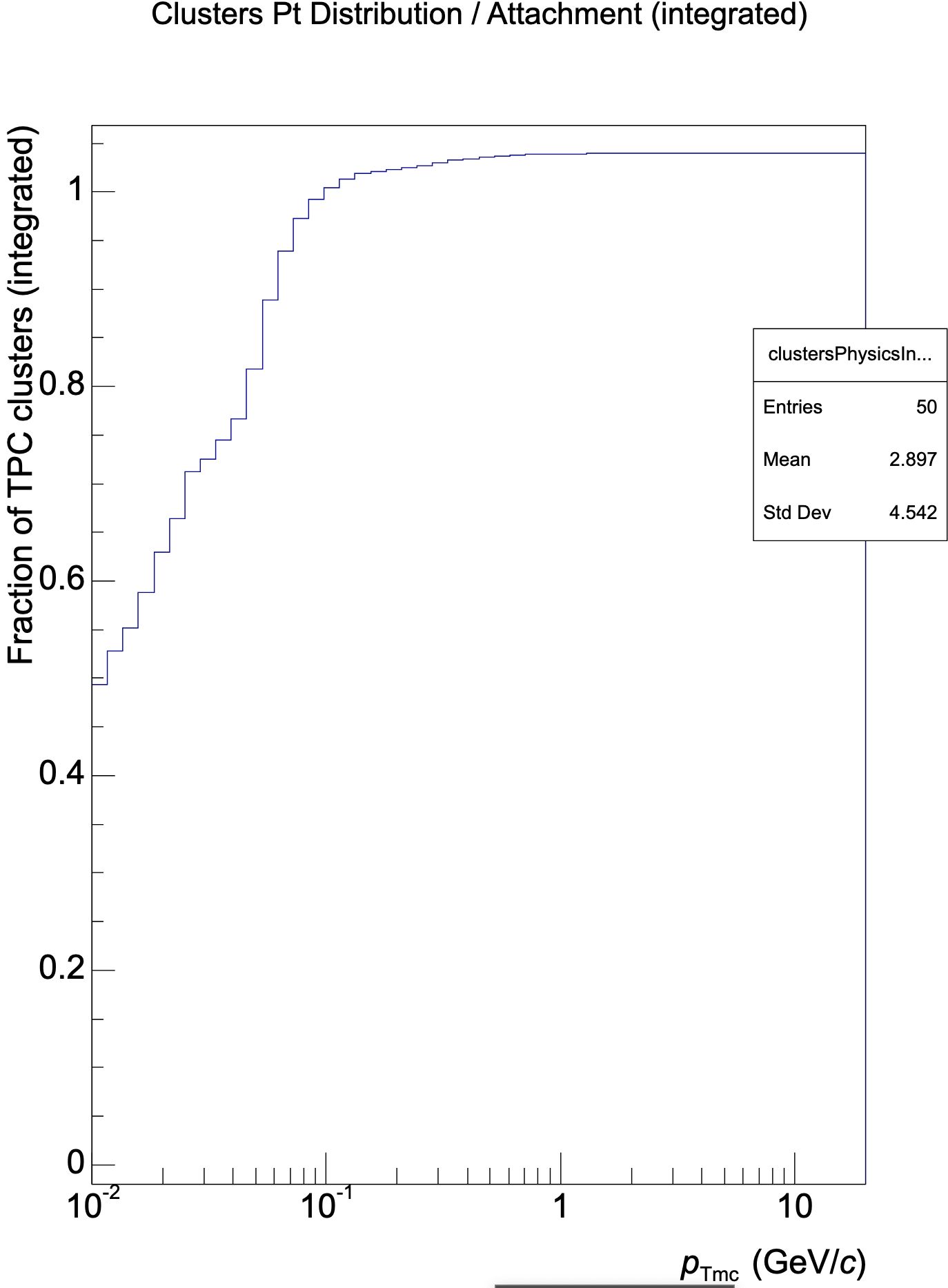
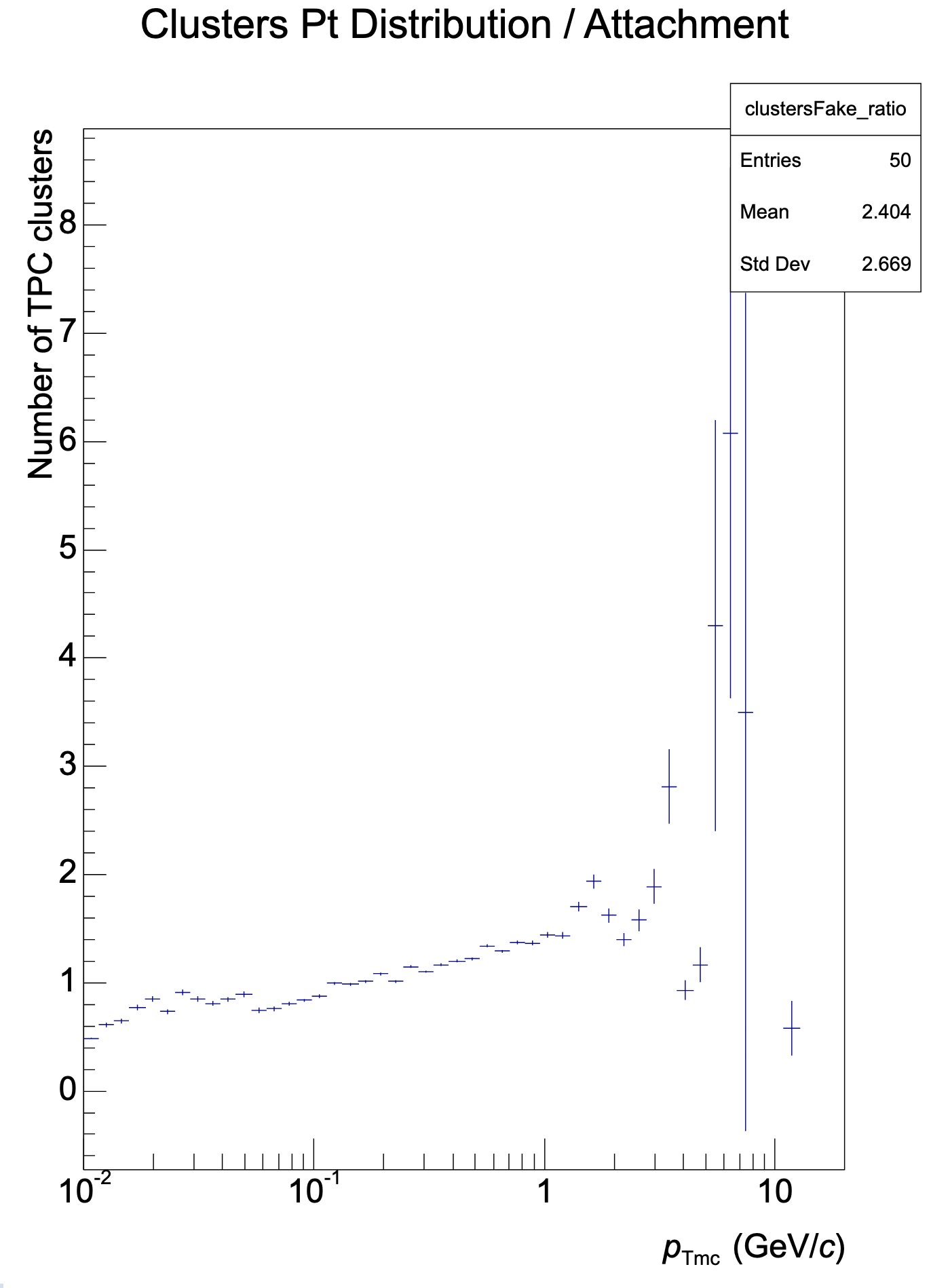
Further integration: Run only network classification and use regression from native clusterizer -> Reveals that weaknesses can mainly be found in regression network
PDP oncall training session: subscribe if you haven't already! https://doodle.com/meeting/organize/id/bYl1Npna
