Overview of low-priority framework issues
Updates
-
- everything works as expected -> closed
Dropping incomplete errors at run stop
- fix deployed with SW update on 12/08
- error messages mostly gone
- still regularly rare errors
Expected Lifetime::Timeframe data MCH/HBPACKETS/0 was not created for timeslice 47383 and might result in dropped timeframes
Expected Lifetime::Timeframe data MCH/ERRORS/0 was not created for timeslice 20 and might result in dropped timeframes
Dropping incomplete <matcher query: (and origin:MCH (and description:ORBITS (just startTime:$0 )))> Lifetime::timeframe data in slot 14 with timestamp 20 < 21 as it can never be completed.
Dropping incomplete <matcher query: (and origin:MCH (and description:DIGITS (just startTime:$0 )))> Lifetime::timeframe data in slot 14 with timestamp 20 < 21 as it can never be completed.
Missing <matcher query: (and origin:MCH (and description:HBPACKETS (just startTime:$0 )))> (lifetime:timeframe) while dropping incomplete data in slot 14 with timestamp 20 < 21.
- happens usually for last empty TFs on one or two EPNs
- in some recent synthetic runs, it happened on a lot more EPNs (~40)
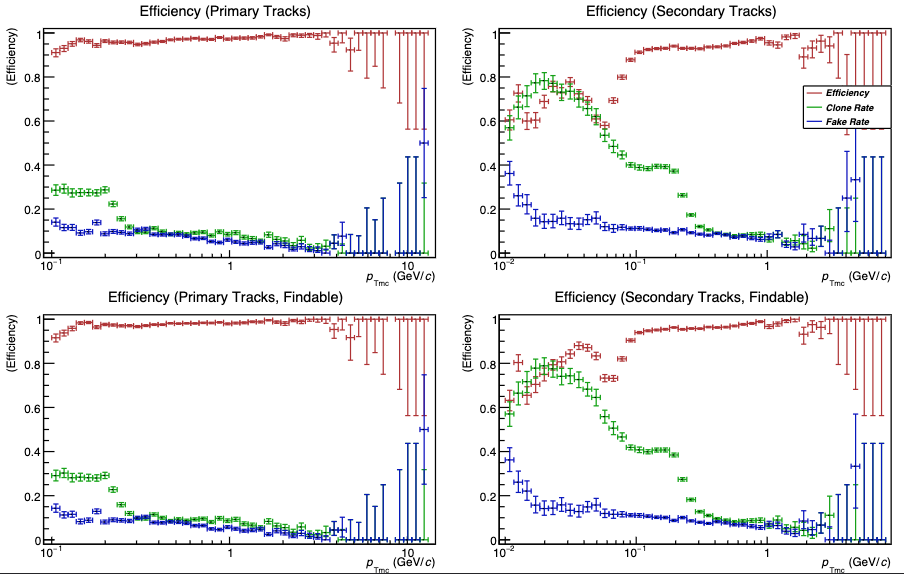
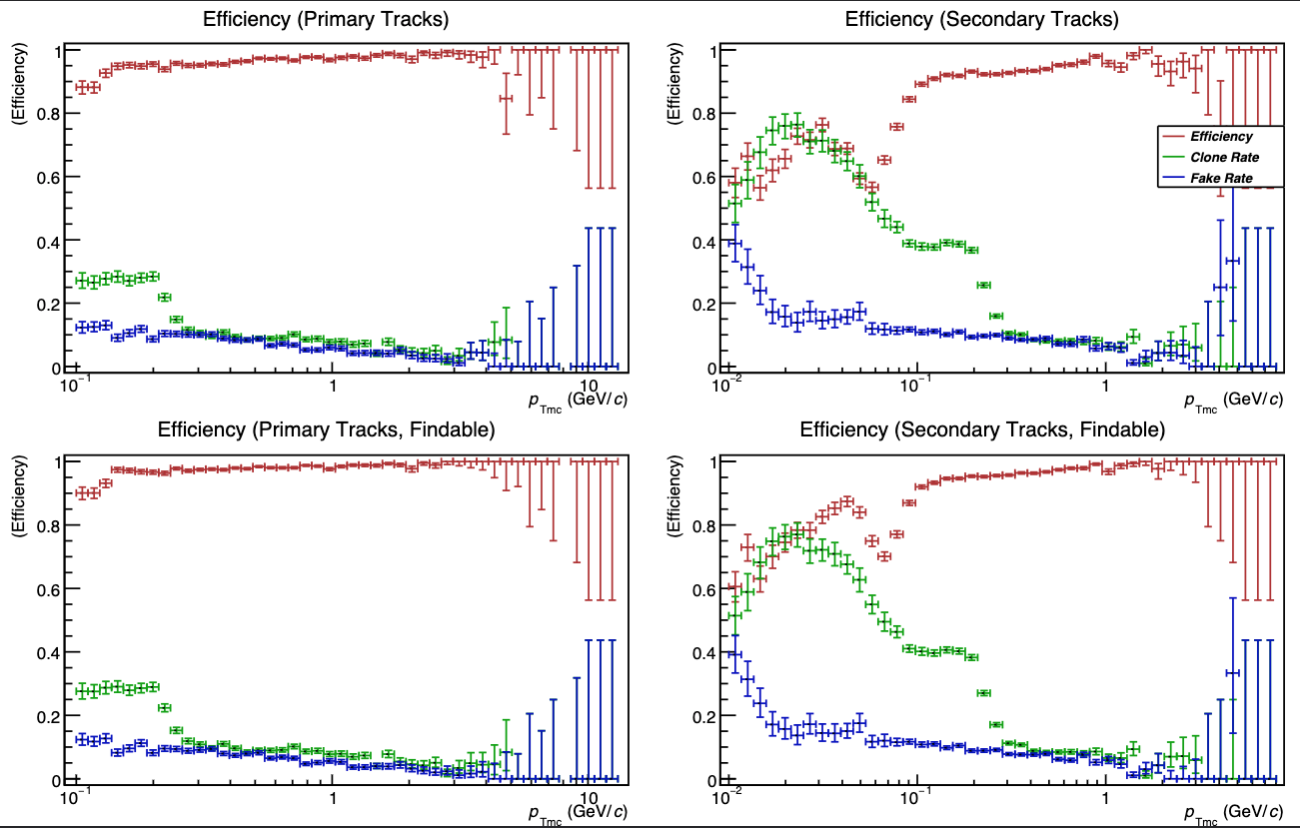

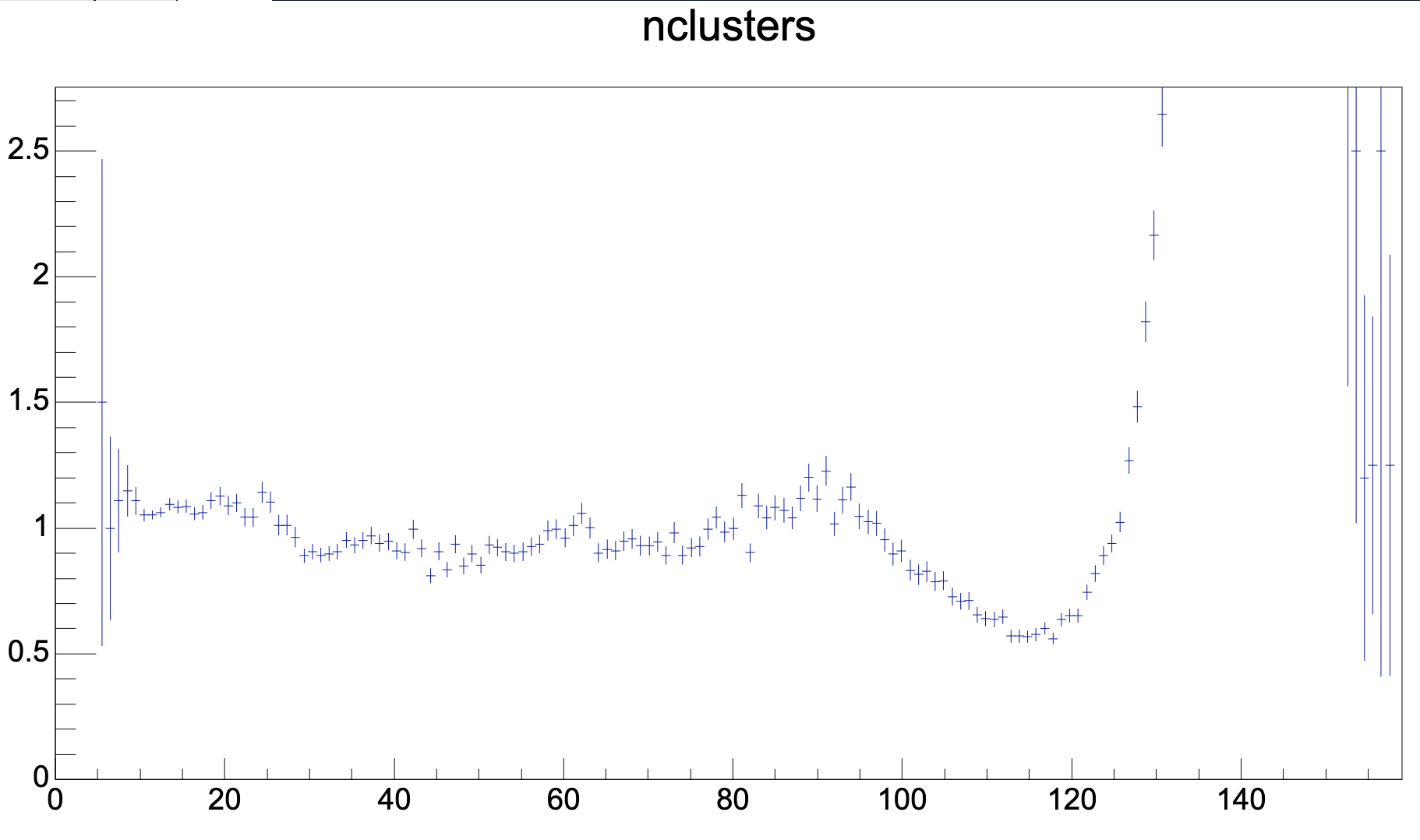


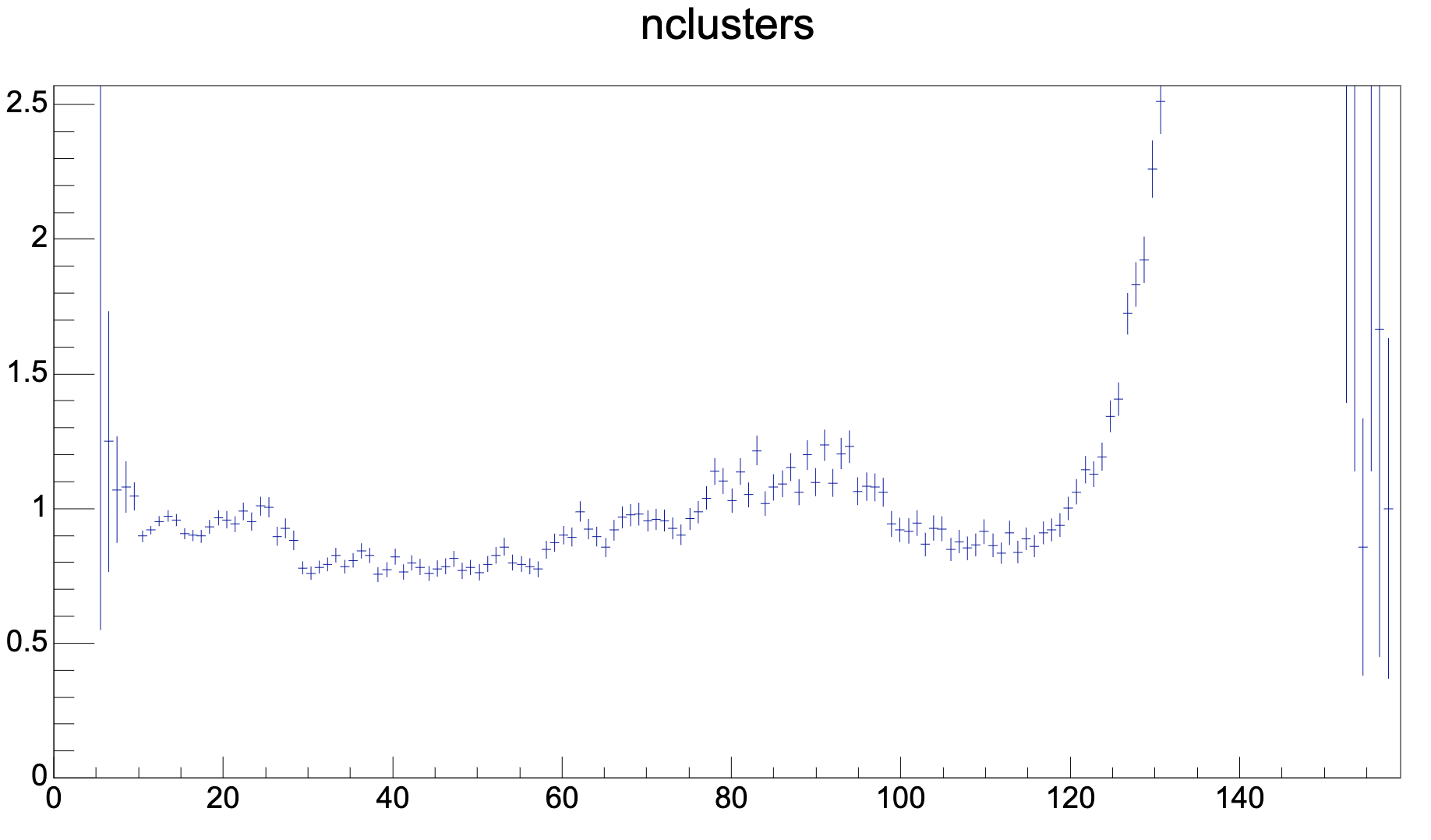
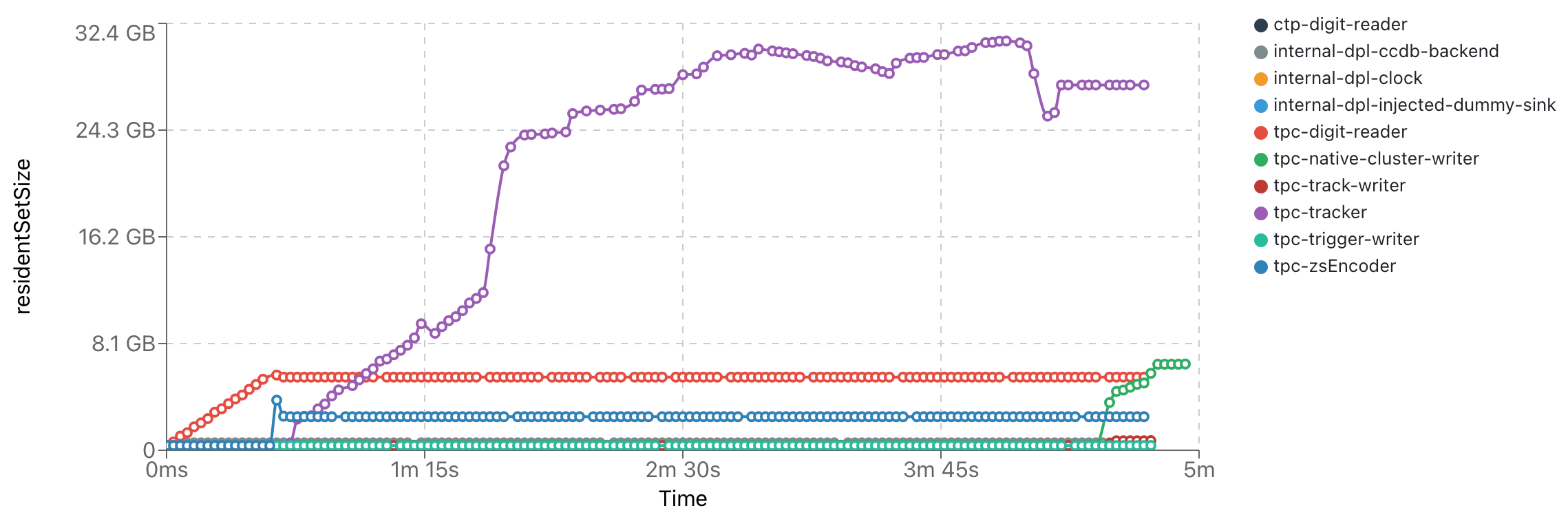
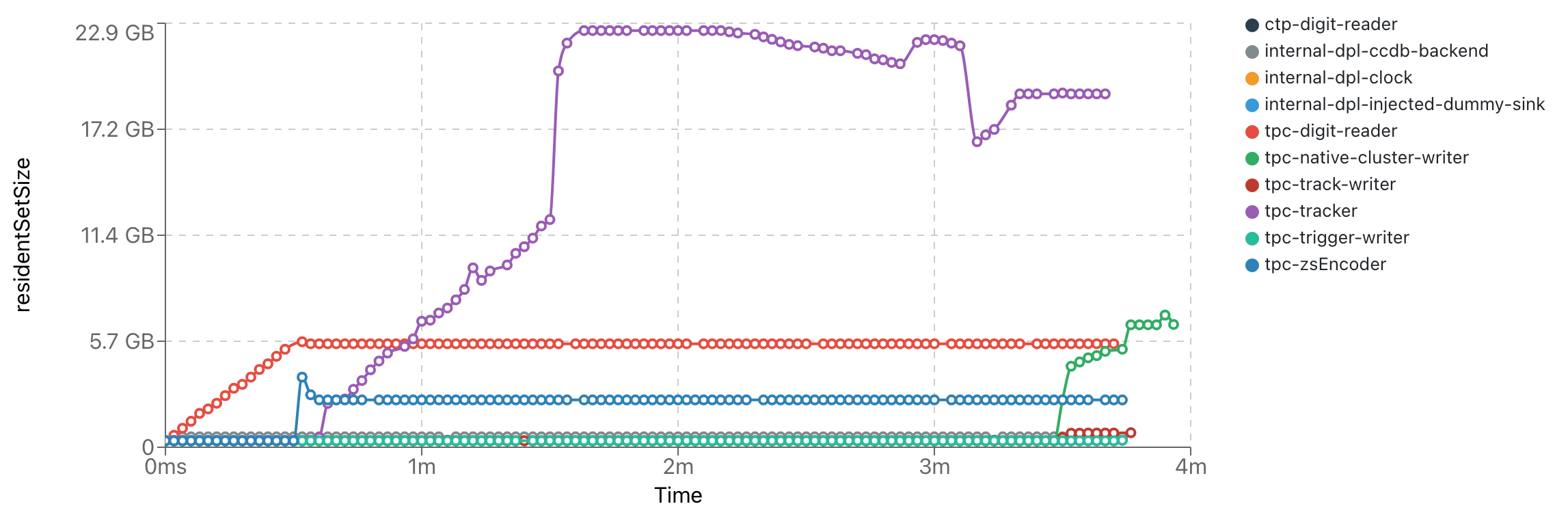
.png)
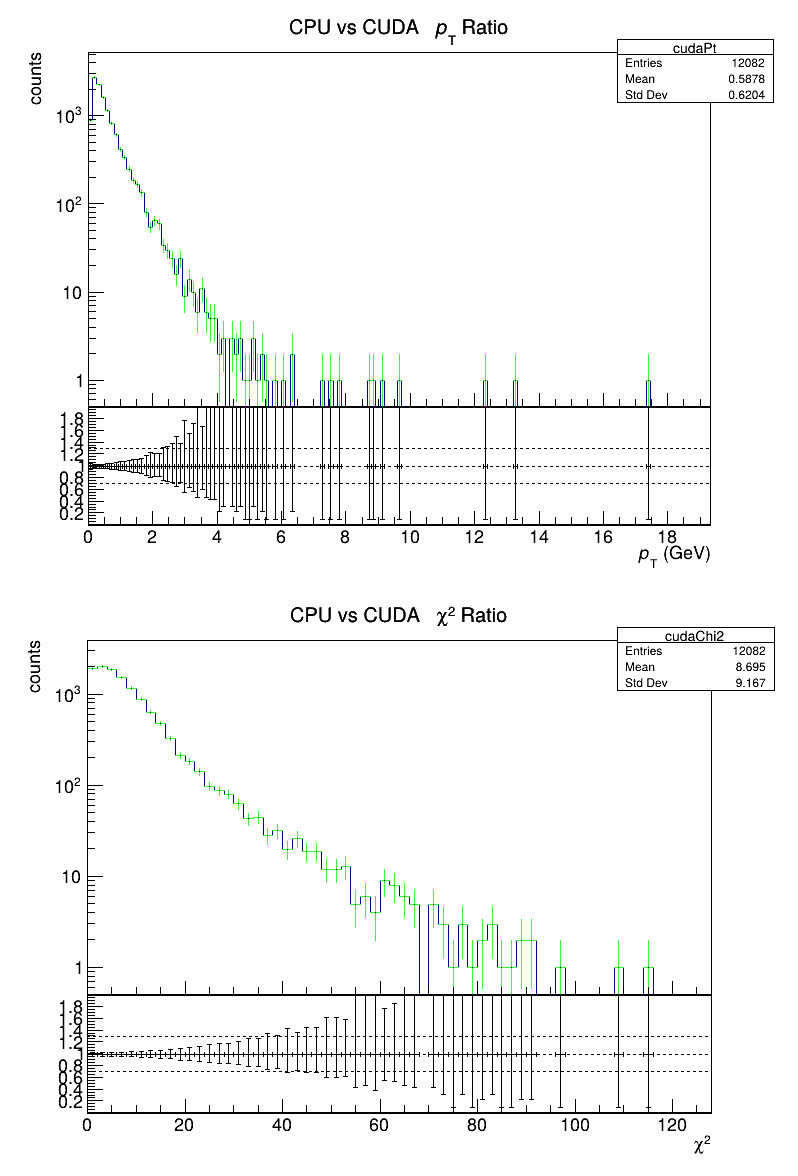.png)
