Choose timezone
Your profile timezone:
Color code: (critical, news during the meeting: green, news from this week: blue, news from last week: purple, no news: black)
High priority Framework issues:
Global calibration topics:
Sync reconstruction
Async reconstruction
EPN major topics:
Other EPN topics:
Full system test issues:
Topology generation:
AliECS related topics:
GPU ROCm / compiler topics:
TPC GPU Processing
TPC processing performance regression:
General GPU Processing
Several smaller updates
Next up
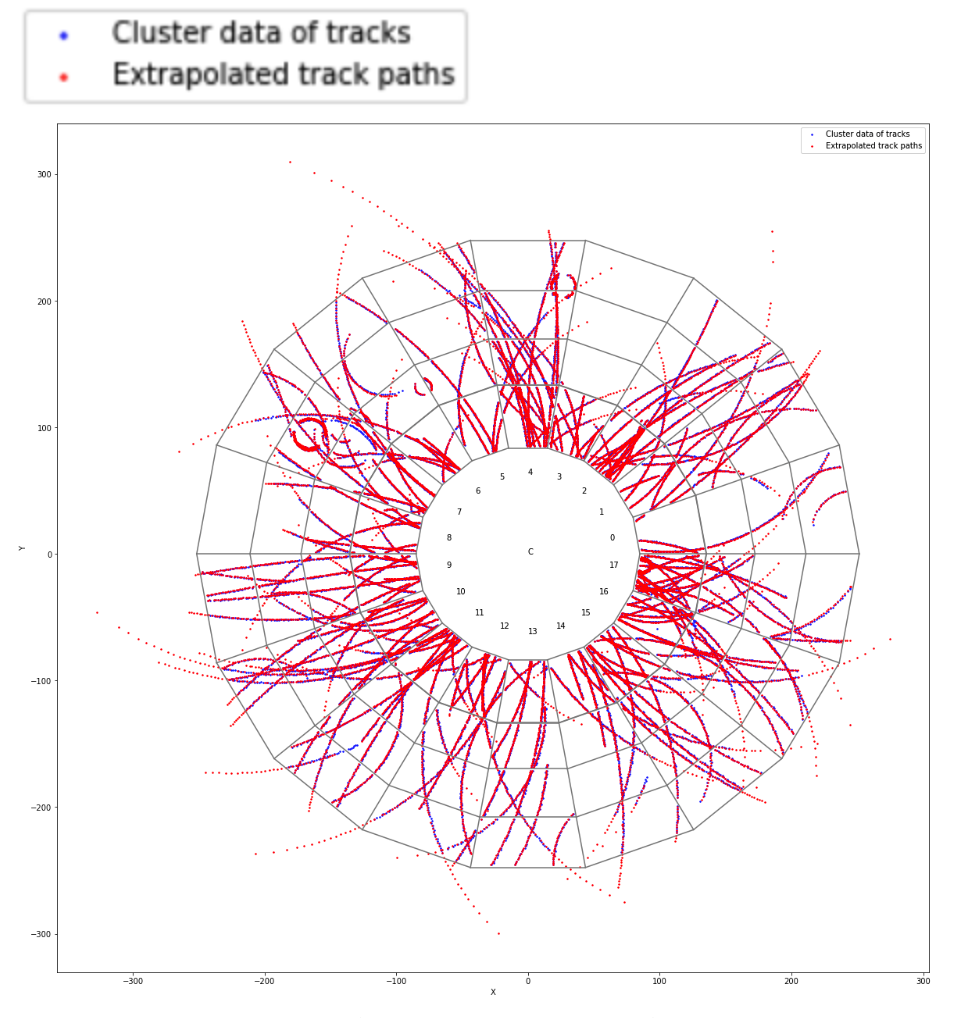
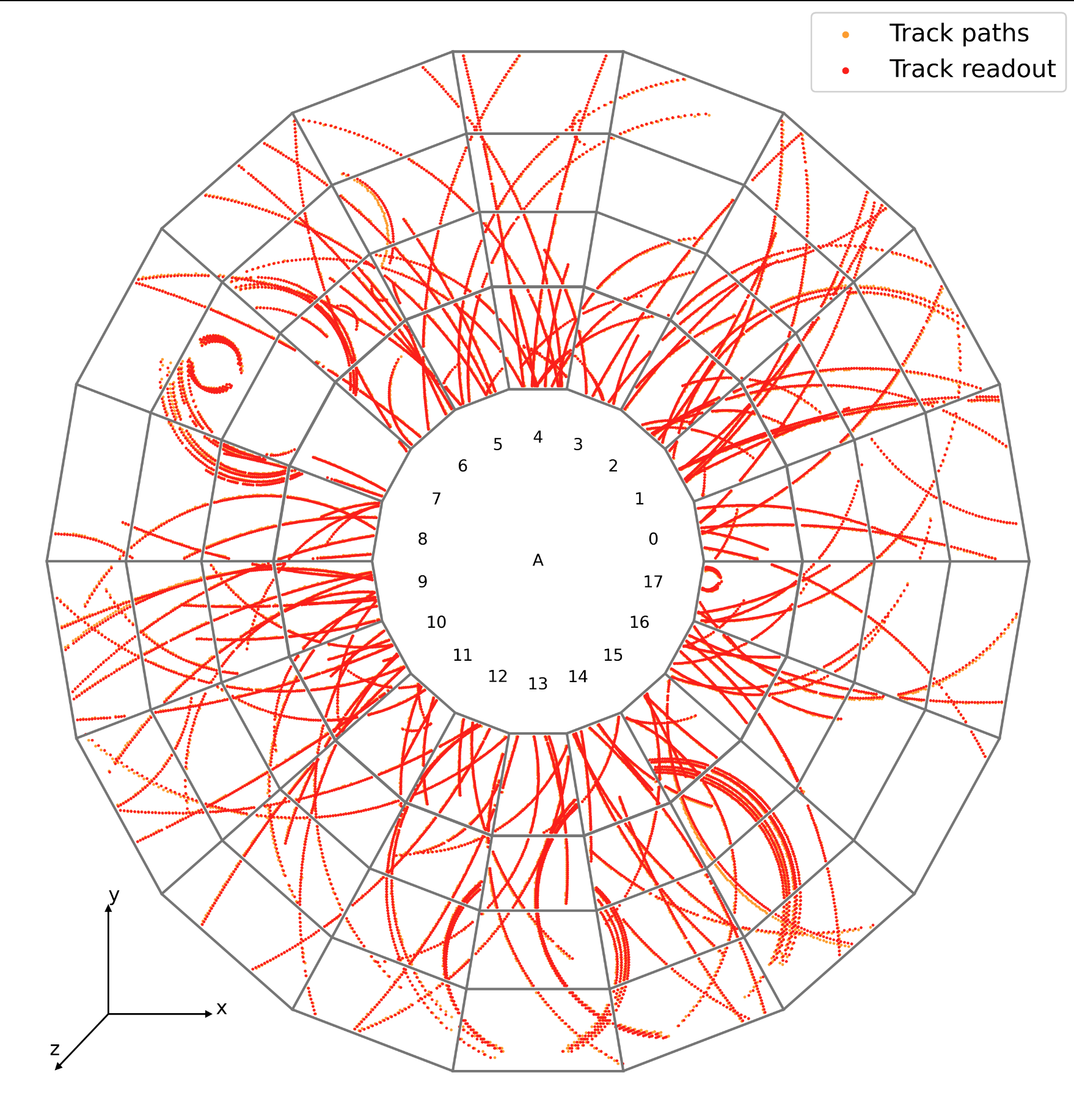
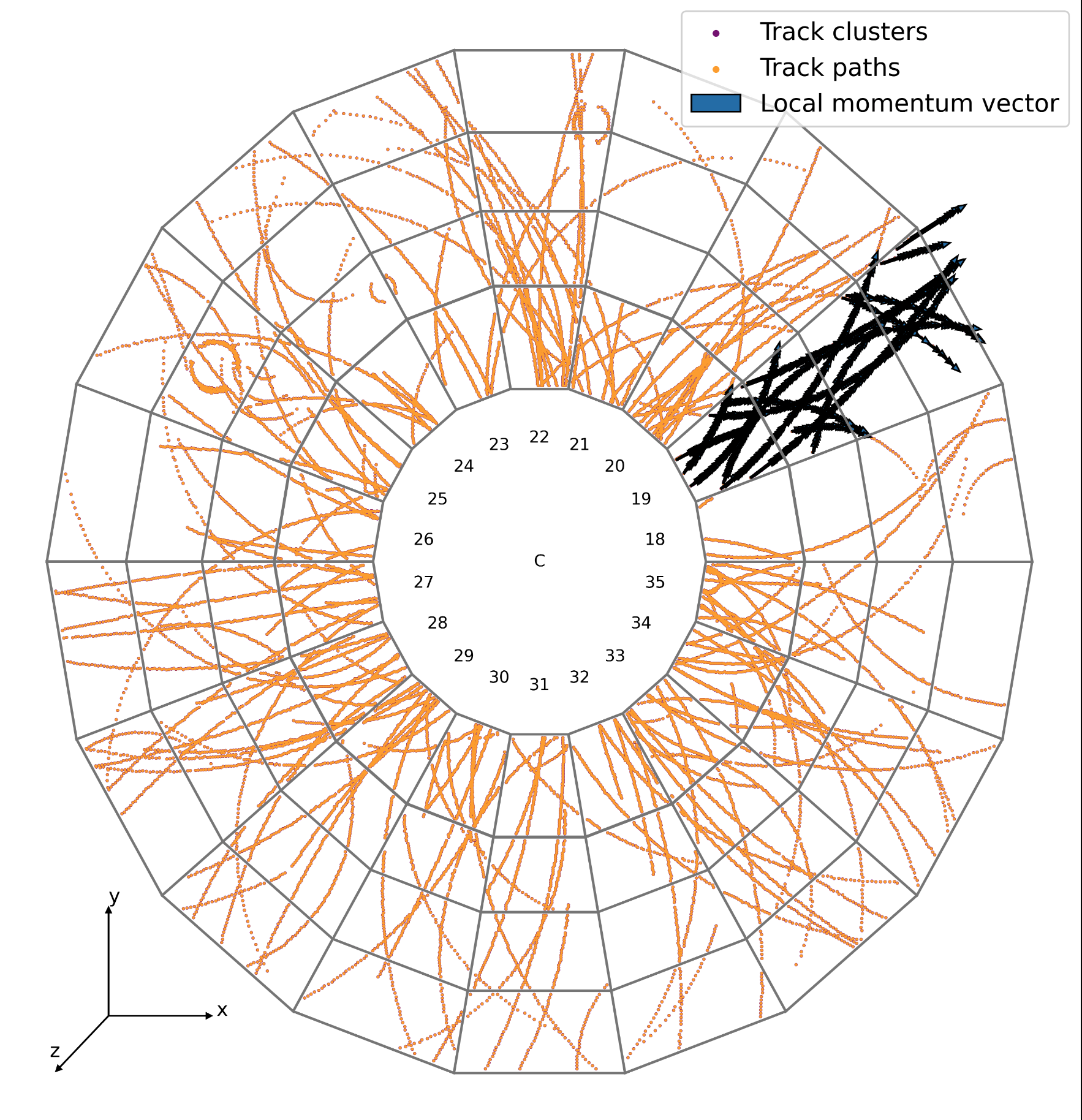
doProcessOnDevice(&fitter, &track1, &track2) instead of fitter.process(t1, t2)DCAFitterCUDA lib privately and separate linked to the GPUTrackingCUDAExternalProvider lib (for TrackParCov and later Propagator definitions). There I also define the kernels, so to have everything in the same TU.DCAFitterAPICUDA lib privately linked to the previous one, to only get cpu interface to expose at any linked case (e.g. testDCAFitter) so to possibly link both DCAFitterN and DCAFitterNCUDAAPI
ldd o2-test-gpu-DCAFitterNCUDA ... libO2DCAFitterAPICUDA.so => /ssd_data/builds/latest/sw/BUILD/O2-latest-gpu-dca-fitter/O2/stage/lib/libO2DCAFitterAPICUDA.so (0x0000732bc9b92000) libO2DCAFitter.so => /ssd_data/builds/latest/sw/BUILD/O2-latest-gpu-dca-fitter/O2/stage/lib/libO2DCAFitter.so (0x0000732bc9b57000) ... libO2DCAFitterCUDA.so => /ssd_data/builds/latest/sw/BUILD/O2-latest-gpu-dca-fitter/O2/stage/lib/libO2DCAFitterCUDA.so (0x0000732bc3600000)
