Choose timezone
Your profile timezone:
Zoom information
Meeting ID: 993 2967 7148
Meeting password: 452400
Invite link: https://umich.zoom.us/j/99329677148?pwd=c29ObEdCak9wbFBWY2F2Rlo4cFJ6UT09
Thanks to everyone for getting in their WBS 2.3 quarterly reports.
WBS 2.3 top-level quarterly should be done soon.
WLCG/HSF meeting coming up in early May
Tier-2s need to work on finalizing procurement and ops plans (discuss in WBS 2.3.2)
Milestone updates still needed for WBS 2.3 https://docs.google.com/spreadsheets/d/1Y0-KdvsRVCXYGd2t-SqCEFlppZn_PjvUUVDGp2vJjc4/edit?gid=1906829311#gid=1906829311
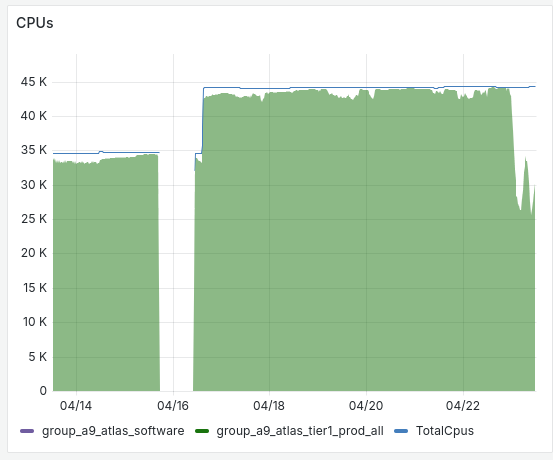
Updates on US Tier-2 centers
HIOPS
TACC: job submission suspended during the weekend. Stop the harvester instance right now. ~1.5K SU.
Perlmutter: maintenance last week. CPU usage is slightly below expectation. MCORE job rate is quite stable (not Premium). Suggestions from NERSC (on Rucio) reduce the job in queue to improve the throughput
ACCESS: need to discuss with Doug on details
