General summary on GPU param optimisation
Can we optimize parameters individually, and which parameters do we have to optimize globally?
Image below is the GPU sync TPC processing chain. Each colored box is a GPU kernel, time flows in this direction -->.

Drawn following conclusions:
- Compression and decompression steps: these steps contain kernels which do not execute concurrently. Parameters are independent and can be optimised separately.
- Clusterizer step: small concurrent kernels, dependent parameters, need global optimisation.
-
TrackingSlices step: medium concurrent kernels, dependent parameters, need global optimisation.
- Merger step: mix of medium/long single stream kernels and small concurrent kernels. Some parameters can be optimisied individually while concurrent kernels require global opt.
Are the optimal parameters the same for different input data pp vs PbPb and low vs high IR?
Measured on Alma 9.4, ROCm 6.3.1, MI50 GPU. Tested four different configurations: pp 100kHz, pp 2MHz, PbPb 5kHz and PbPb 50kHz. Simulated TFs with 128 lhc orbits.
Independent params optimisation
MergerTrackFit

Executed two times (Merger 1 and Merger 2)
pp
Merger 1

- Low IR same performance as normal configuration (grid size dependent on number of tracks)
- High IR same as low IR, except for (64,240) where it also has the same performance as normal
Merger 2
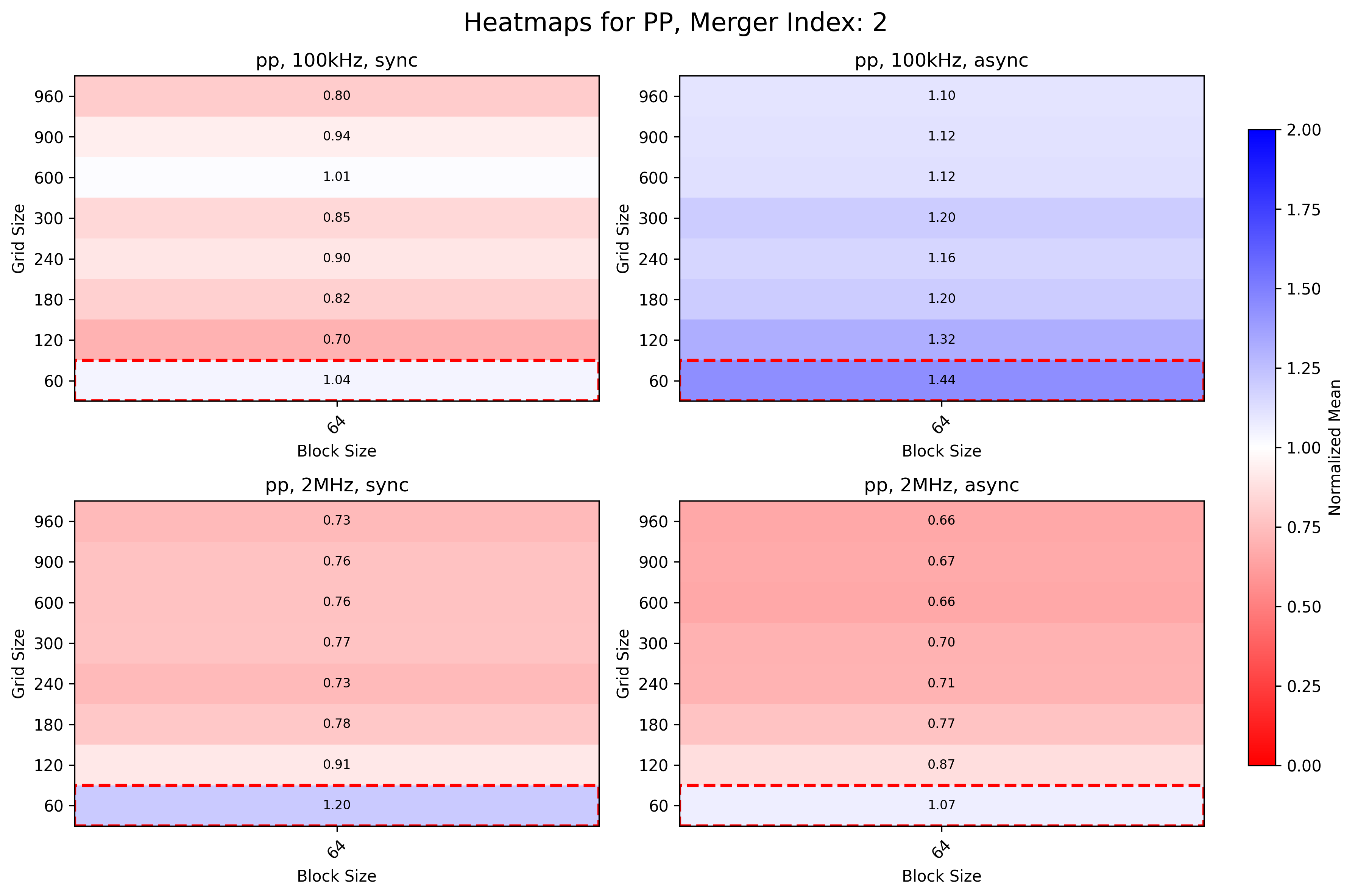
- Low and High IR sync benefits from bigger grid sizes
- High IR async is 34% faster with higher grid sizes than current configuration for async
PbPb
Merger 1

- Larger grid sizes almost reaches current configuration (grid_size * block_size >= n_tracks)
Merger 2
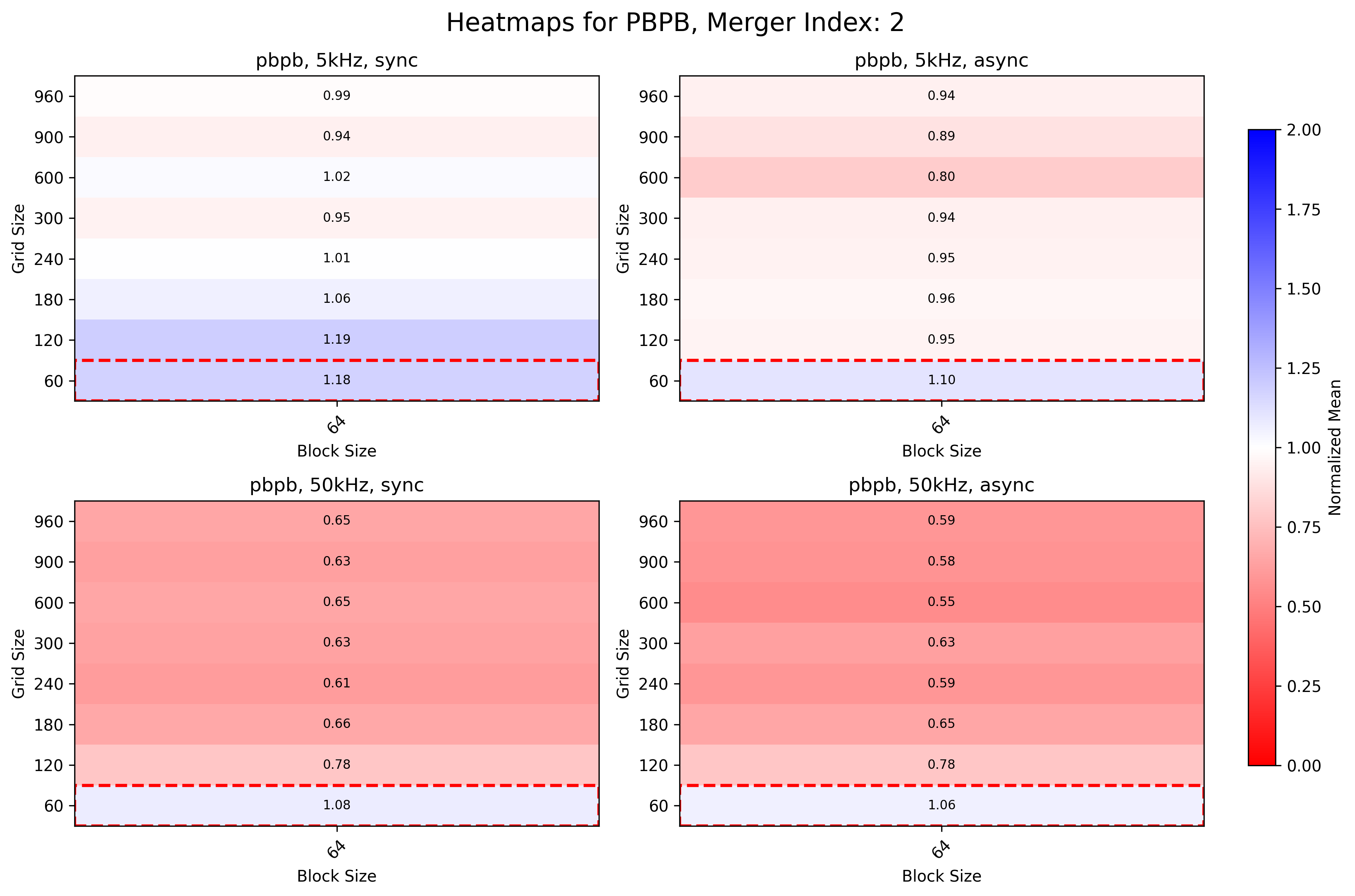
- Low IR can be 10% faster with bigger grid sizes
- High IR is 40% faster with bigger grid sizes
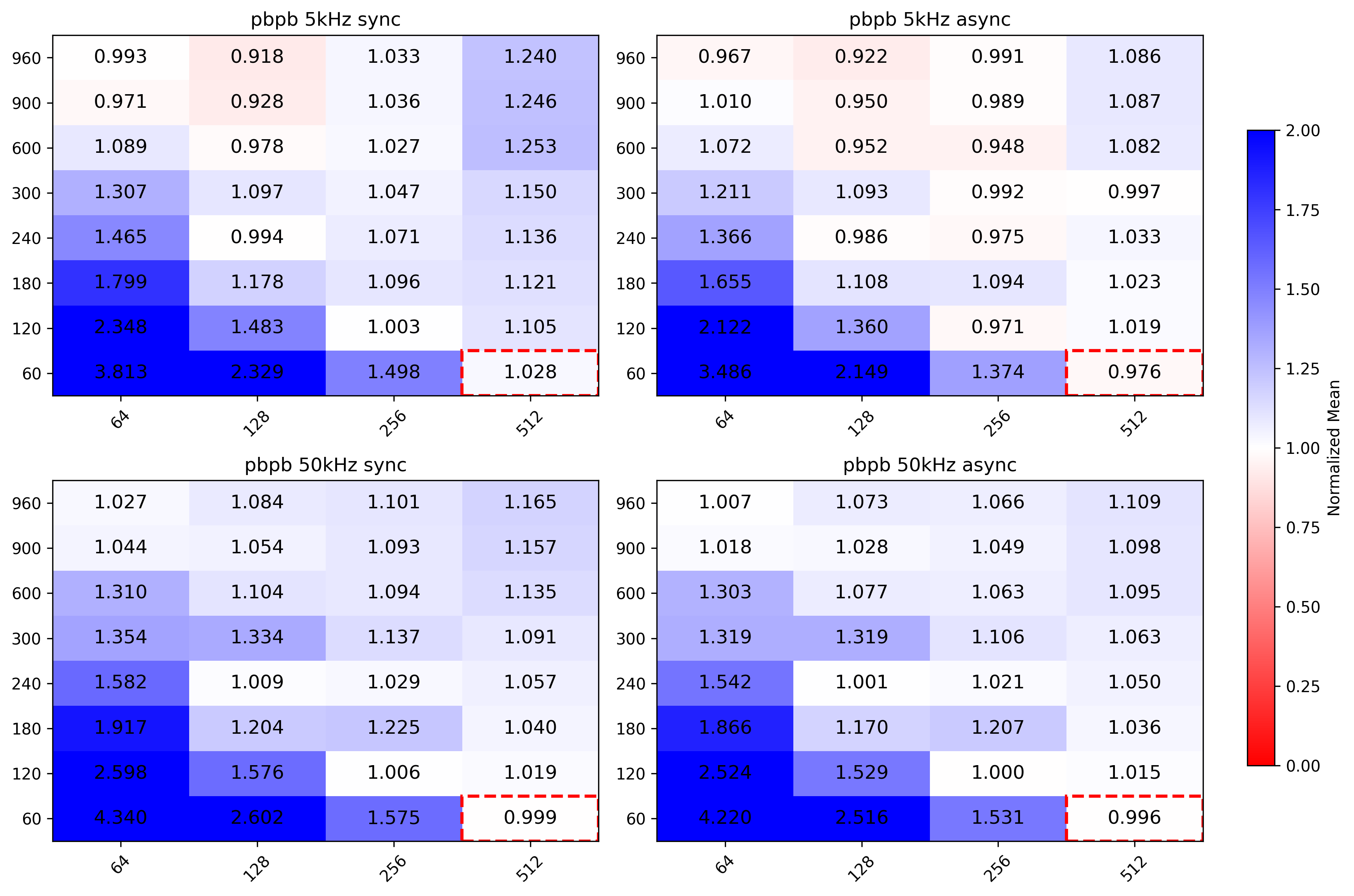
MergerSliceRefit

Kernel is executed 36 times (once per TPC sector).
- pp low IR benefits from lower block sizes
- pp high IR benefits from larger grid and block sizes
- PbPb low IR better with lower block sizes
- PbPb high IR better with larger grid and block sizes
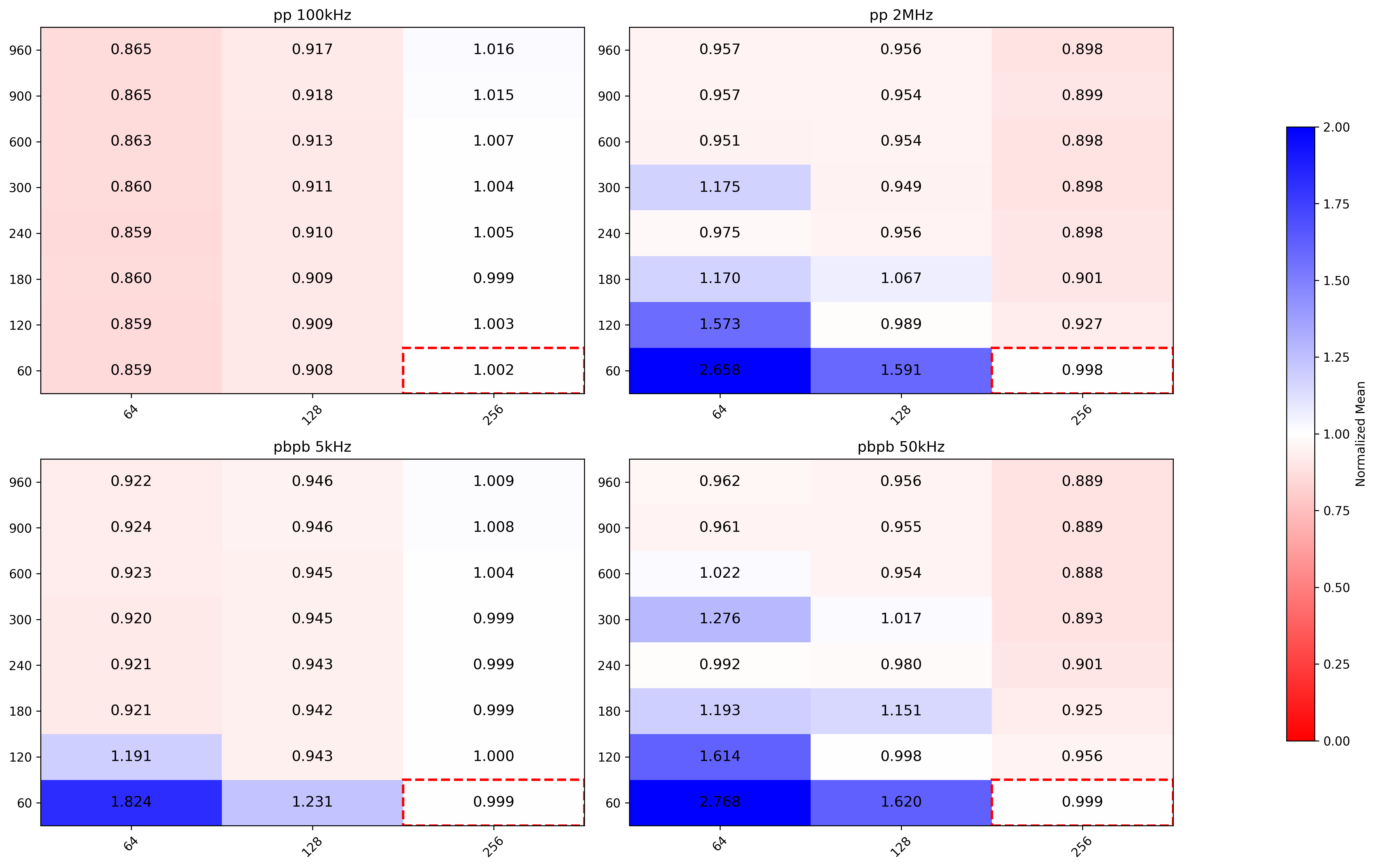
MergerCollect

pp

Overall best performance given by (64, 960), while current configuration is (512,60).
PbPb
Roughly same as pp
MergerFollowLoopers


Best configuration uses 900 or 960 as grid size. Current configuration is (256,200).
Compression kernels

Step 0 attached clusters
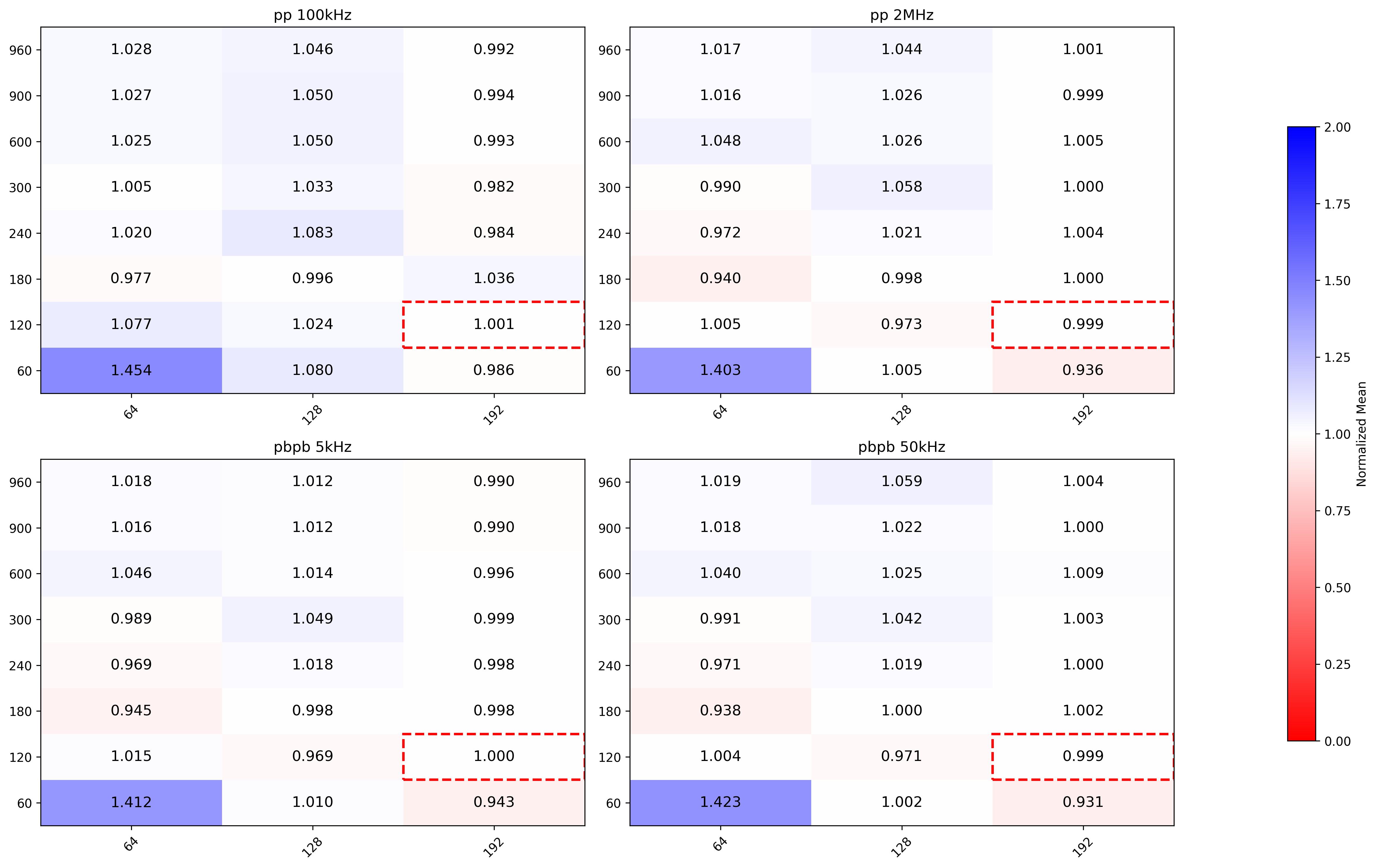
No significant improvements when changing grid and block sizes.
Step 1 unattached clusters

No significant improvements when changing grid and block sizes.
After grid search
Create set of best parameters per beamtype (pp, PbPb) and per IR (100kHz, 2MHz for pp and 5kHz, 50kHz for PbPb). How to choose best configuration:
- compute
conf_mean_time - default_conf_mean_time
- propagate error (std dev) of the difference and compute 95% confidence interval
- if 0 is in the interval, can not tell with confidence if current configuration is better than the default
- if one or more CIs have upperbound < 0, choose the one with smaller mean (i.e. the best)
Plug in the best parameters for each beamtype / IR configuration and check if there is a noticable improvement in the whole sync / async chain (work in progress).
Dependent params optimisation
- More difficult to tackle. Group kernels which run in parallel and optimise this set.
- Identified following kernels which are the longest which are concurrently executed with other kernels:
- CreateSliceData
- GlobalTracking
- TrackletSelector
- NeighboursFinder
- NeighboursCleaner
- TrackletConstructor_singleSlice
- Started with grid search approach on TrackletConstructor_singleSlice. Measured both kernel mean execution time and whole SliceTracking execution time, as chaning parameters may influence the execution time of other kernels and thus on the whole SliceTracking slice.
- Block size is multiple of warp size (64 for AMD EPN GPUs), Grid size is multiple of number of Streaming Multiprocessors (Compute Units in AMD jargon).
Possible ideas for post manual optimization
- Isolate the parameters which are dependent, i.e. kernels from the same task which run in parallel (e.g. Clusterizer step, SliceTracking slice)
- Apply known optimization techniques to such kernel groups
- Grid/random search
- Bayesian optimization?
See: F.-J. Willemsen, R. Van Nieuwpoort, and B. Van Werkhoven, “Bayesian Optimization for auto-tuning GPU kernels”, International Workshop on Performance Modeling, Benchmarking and Simulation of High Performance Computer Systems (PMBS) at Supercomputing (SC21), 2021. Available: https://arxiv.org/abs/2111.14991
Possible bug spotted
HIP_AMDGPUTARGET set to "default" in GPU/GPUTracking/Standalone/cmake/config.cmake translates in HIP_AMDGPUTARGET=gfx906;gfx908 and forces to use MI50 params
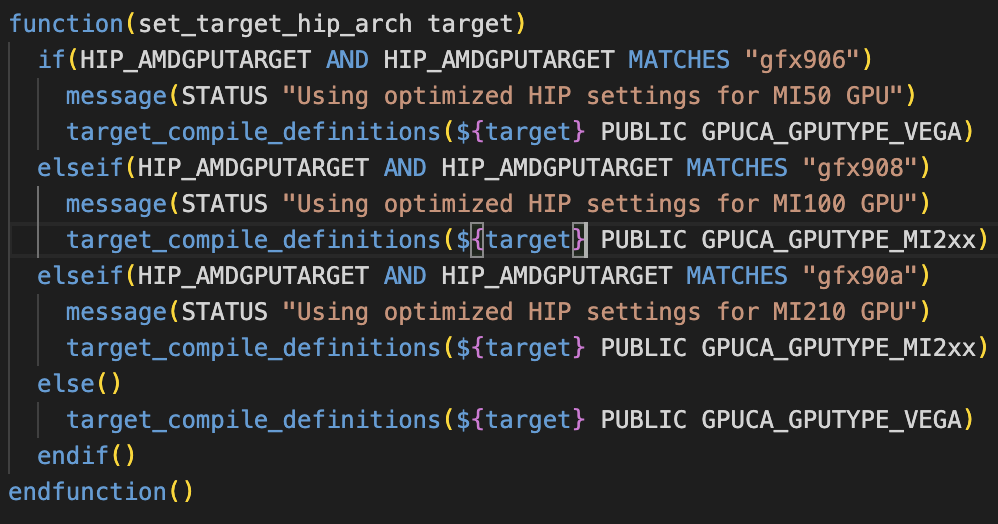
Basically here HIP_AMDGPUTARGET=gfx906;gfx908 enters the first if clause for MI50 even if I am compiling for MI100. Commented set(HIP_AMDGPUTARGET "default") on the config.cmake of the standalone benchmark and forced usage of MI100 parameters via
cmake -DCMAKE_INSTALL_PREFIX=../ -DHIP_AMDGPUTARGET="gfx908" ~/alice/O2/GPU/GPUTracking/Standalone/
Did not investigate further on this.
















