Choose timezone
Your profile timezone:
Color code: (critical, news during the meeting: green, news from this week: blue, news from last week: purple, no news: black)
High priority Framework issues:
Sync reconstruction
Async reconstruction
AliECS related topics:
GPU ROCm / compiler topics:
TPC / GPU Processing
Other Topics
EPN major topics:
Other EPN topics:
/home/epn/odc/files in DPL workflows to remove the dependency on the NFS
logWatcher.sh and logFetcher scripts modified by EPN to remove dependencies on epnlog user
log_access role to allow access in logWatcher mode to retrieve log files, e.g. for on-call shiftersBEAMTYPE for oxygen period
Framework
-----------------------------------
tmux FST script for software validation on epn279
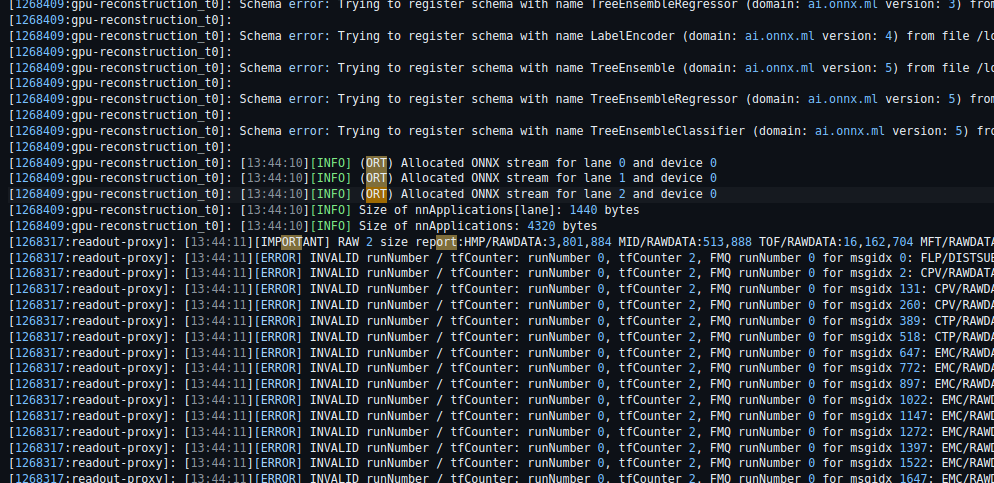
Regular reconstruction
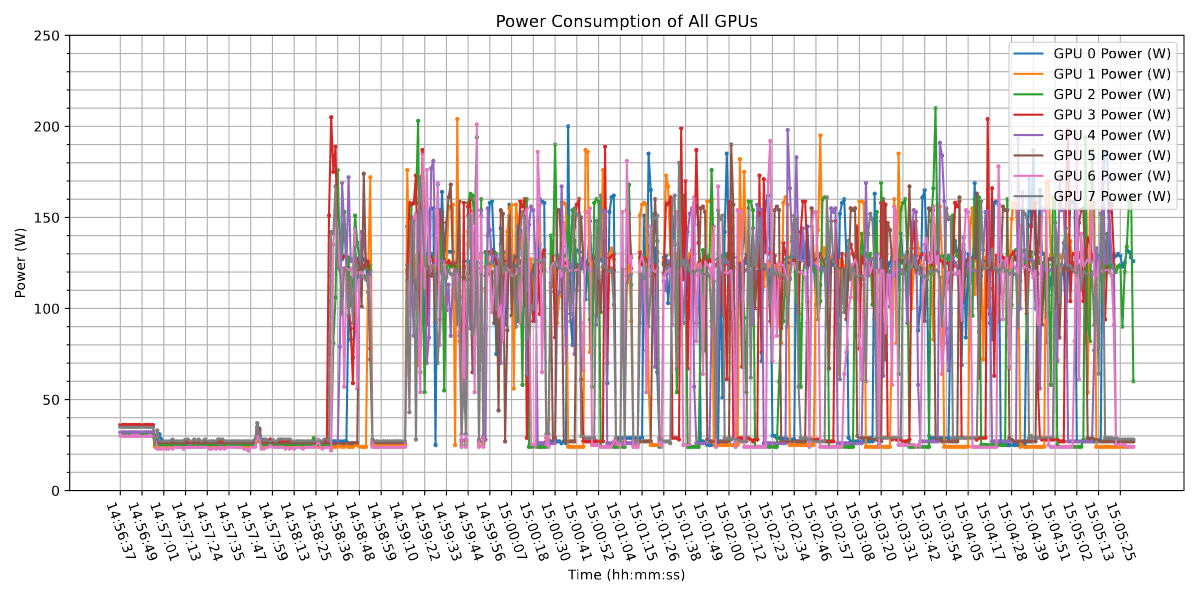
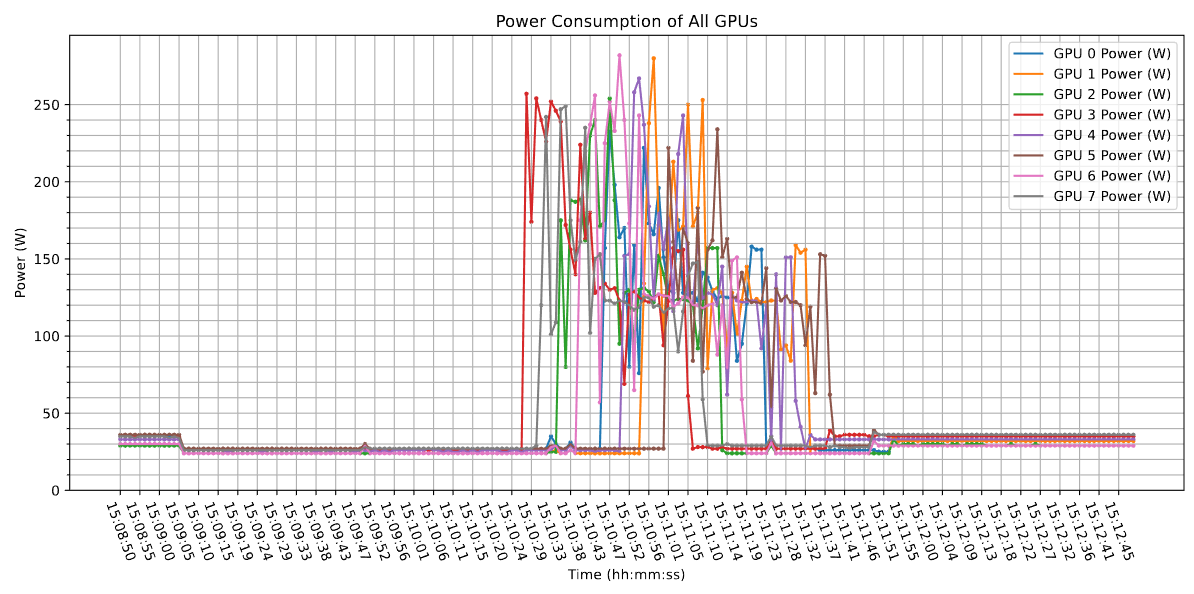
NN reconstruction
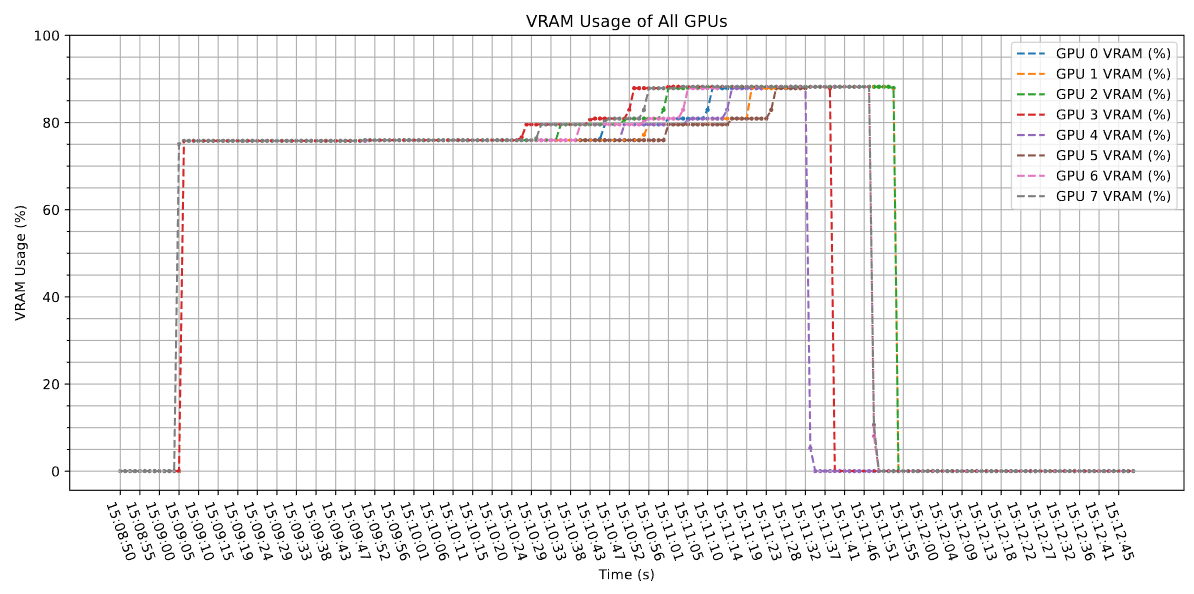
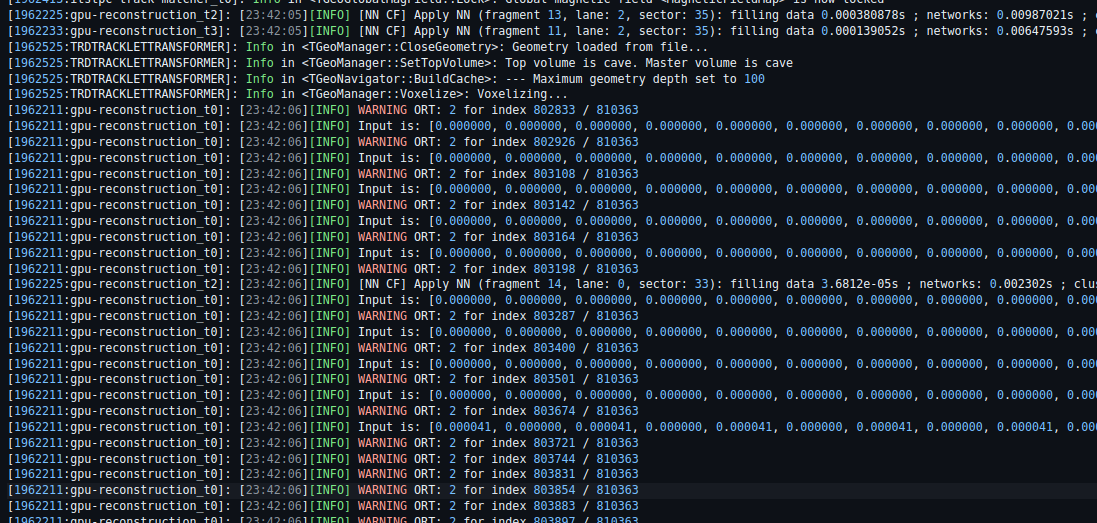
Crashes due to invalid read / writes. The logic for application seems correct, investigating why output gets corrupted.
--------------------------------------
To be improved
--------------------------------------
Next two weeks
TODO:
gpu-reco-workflow: no progress.SMatrixGPU on the host, under particular configuration: no progress.
| Beamtype | IR | Best Block Size | Best Grid Size | Best Mean Kernel Time (ms) | Search Duration (minutes) |
| pp | 100kHz | 64 | 960 | 152.66 | 29.53 |
| pp | 2MHz | 256 | 180 | 1899.74 | 74.41 |
| PbPb | 5kHz | 512 | 60 | 337.52 | 34.35 |
| PbPb | 50kHz | 256 | 960 | 4816.70 | 137.68 |
| Beamtype | IR | Best Block Size | Best Grid Size | Best Mean Kernel Time (ms) | Search Duration (minutes) |
| pp | 100kHz | 192 | 720 | 148.55 | 22.38 |
| pp | 2MHz | 192 | 180 | 1871.80 | 40.78 |
| PbPb | 5kHz | 64 | 840 | 336.51 | 21.06 |
| PbPb | 50kHz | 192 | 780 | 5160.10 | 95.41 |
| Beamtype | IR | Best Block Size | Best Grid Size | Best Mean Kernel Time (ms) | Search Duration (minutes) |
| pp | 100kHz | 64 | 60 | 4.49 | 29.80 |
| pp | 2MHz | 256 | 900 | 17.17 | 73.80 |
| PbPb | 5kHz | 64 | 900 | 4.76 | 34.23 |
| PbPb | 50kHz | 256 | 960 | 28.94 | 135.18 |
| Beamtype | IR | Best Block Size | Best Grid Size | Best Mean Kernel Time (ms) | Search Duration (minutes) |
| pp | 100kHz | 64 | 60 | 4.49 | 17.88 |
| pp | 2MHz | 256 | 720 | 19.22 | 39.40 |
| PbPb | 5kHz | 64 | 660 | 4.80 | 22.51 |
| PbPb | 50kHz | 256 | 120 | 32.18 | 59.51 |
| Beamtype | IR | Best Block Size | Best Grid Size | Best Mean Kernel Time (ms) | Search Duration (minutes) |
| pp | 100kHz | 128 | 900 | 24.64 | 30.05 |
| pp | 2MHz | 256 | 300 | 241.75 | 71.96 |
| PbPb | 5kHz | 256 | 300 | 52.54 | 34.05 |
| PbPb | 50kHz | 256 | 300 | 368.05 | 128.08 |
| Beamtype | IR | Best Block Size | Best Grid Size | Best Mean Kernel Time (ms) | Search Duration (minutes) |
| pp | 100kHz | 192 | 480 | 22.86 | 23.06 |
| pp | 2MHz | 256 | 240 | 271.63 | 63.20 |
| PbPb | 5kHz | 320 | 540 | 44.60 | 26.70 |
| PbPb | 50kHz | 256 | 450 | 341.04 | 87.90 |
Checked with --debug 0 to serialize every kernel. Dependency seems mitigated but still present, will investigate further. In the meantime they are treated as one step with 4 parameters.
Create a file "session.yml" defining a pod. The marked lines you might have to change.
apiVersion: v1
kind: Pod
metadata:
name: session-1
labels:
mount-eos: "true"
inject-oauth2-token-pipeline: "true"
annotations:
sidecar.istio.io/inject: "false"
spec:
containers:
- name: session-1
image: registry.cern.ch/ngt-wp1.7/wp1.7-soa-wrapper:latest
command: ["sleep", "infinity"]
resources:
limits:
nvidia.com/gpu: 1
securityContext:
runAsUser: 0
runAsGroup: 0
In the terminal, run the following commands to start the pod and enter an interactive session.
kubectl apply -f session.yml
kubectl exec -it session-1 -- /bin/bash
Now you can "git clone" your code and build it.
[vsinghal@epn000 alisoft]$ source ~/alisoft/sw/SOURCES/O2/daily-20250326-0000/daily-20250326-0000/GPU/GPUTracking/Standalone/cmake/prepare.sh
[vsinghal@epn000 alisoft]$ cd ../standalone/
[vsinghal@epn000 standalone]$ ./ca -e o2-pp-10 --gpuDevice 0 --display
Reading events from Directory events/o2-pp-10
GPU Tracker library loaded and GPU tracker object created sucessfully
Created GPUReconstruction instance for device type HIP (3)
Read event settings from dir events/o2-pp-10/ (solenoidBz: -5.006680, home-made events 0, constBz 0, maxTimeBin 57025)
Standalone Test Framework for CA Tracker - Using GPU
Enabling event display (X11 backend)
HIP Initialisation successfull (Device 0: AMD Instinct MI50/MI60 (Frequency 1725000, Cores 60), 6442516480 / 6442516480 bytes host / global memory, Stack frame 8192, Constant memory 26887)
GPU Tracker initialization successfull
Rescaling buffer size limits from 20500000000 to 6442516480 bytes of memory (factor 0.314269)
Using random seed 414215023
Loading time: 576,053 us
Processing Event 0
Trigger handling only possible with TPC Dense Link Based data, received version 2, disabling
Event has 2794 8kb TPC ZS pages (version 2), 388869 digits
Event has 46278 TPC Clusters, 0 TRD Tracklets
Output Tracks: 502 (0 / 31692 / 0 / 46278 clusters (fitted / attached / adjacent / total) - O2 format)
could not open display
Error occured
Maximum Memory Allocation: Host 1,488,519,168 / Device 1,521,374,144
HIP Uninitialized
[vsinghal@epn000 standalone]$
Used -XY options during ssh, but how to enable display via srun?