Choose timezone
Your profile timezone:
Color code: (critical, news during the meeting: green, news from this week: blue, news from last week: purple, no news: black)
High priority Framework issues:
Sync reconstruction
Async reconstruction
AliECS related topics:
GPU ROCm / compiler topics:
TPC / GPU Processing
Other Topics
EPN major topics:
Other EPN topics:
/home/epn/odc/files in DPL workflows to remove the dependency on the NFS
logWatcher.sh and logFetcher scripts modified by EPN to remove dependencies on epnlog user
log_access role to allow access in logWatcher mode to retrieve log files, e.g. for on-call shiftersBEAMTYPE for oxygen period
| Dataset | Default sync time | Optimized sync time |
| pp 2MHz | 2658.22 ms ± 4.50 ms | 2507.92 ms ± 4.26 ms (5.65%) |
| PbPb 50kHz | 4708.97 ms ± 14.41 ms | 4352.53 ms ± 6.35 ms (7.57%) |
events = interaction_rate * n_orbits * 0.0000894events = 143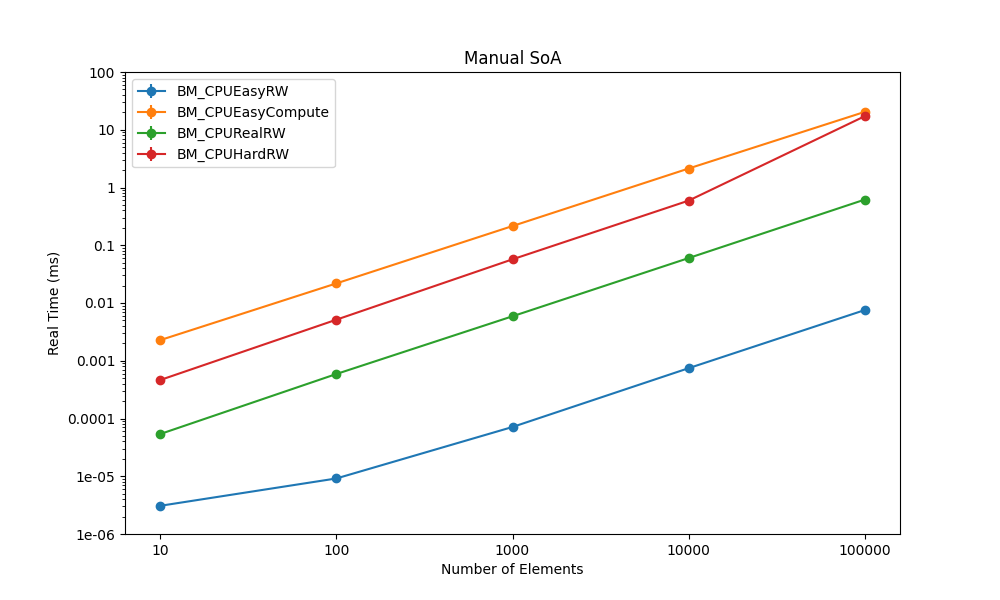 |
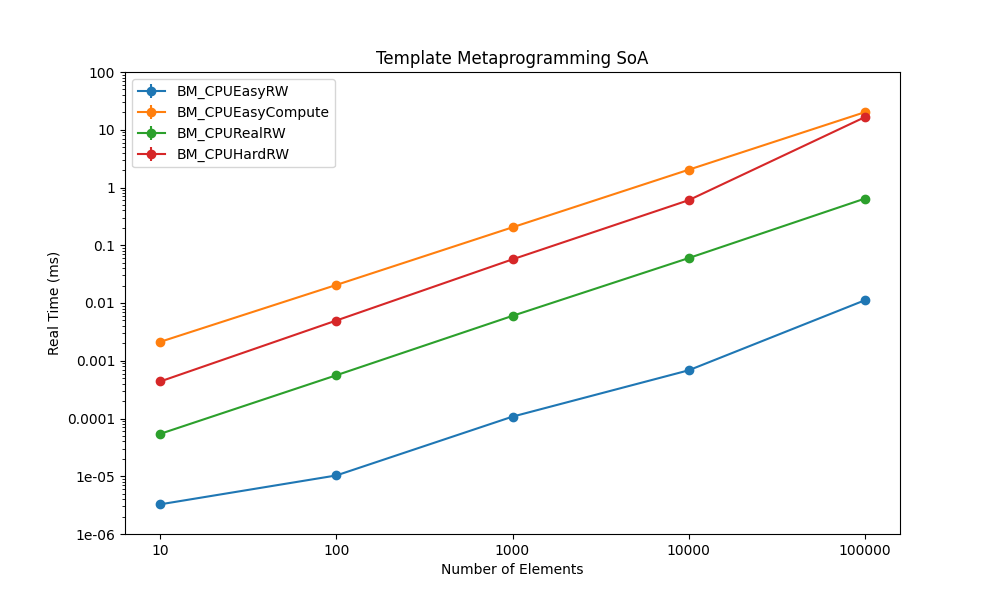 |
#include <vector>
struct SoA_Points { std::vector<float> x, y, z; };
struct S_ref { float &x, &y, &z; };
struct wrapper {
SoA_Points soa_points;
S_ref operator[]( int i ) {
return { soa_points.x[i], soa_points.y[i], soa_points.z[i] };
}
};
int main() {
int N = 100;
wrapper w {{ std::vector<float>(N), std::vector<float>(N), std::vector<float>(N) }};
w[42].x = 3; // Accesses all data members of soa_points, although only x is needed
return 0;
}
When we enable -DGPUCA_DETERMINISTIC_MODE Cmake setting or--PROCdeterministicGPUReconstruction
GPU.out is same but --RTCdeterministic command line option1. Orchestrate the access of ALICE to the CERN NGT benchmark/development hardware, and alternatively to other CERN resources, to benchmark the ALICE GPU code on modern / new GPUs.
2. Establish a software infrastructure / scripts, to run the ALICE GPU processing benchmarks on CPUs and GPUs over different data set, and provide performance results in a way that enables further analysis.
- In principle the standalone benchmark should be enough, but pp and Pb-Pb data sets of different interaction rates should be tested.
3. Extend the Alice O2 CI infrastructure to run actual code on the GPU, check for correctness and performance, for pull requests.
- Should be a fast test for the CI. The standalone benchmark should be enough. Ideally we can perhaps use the deterministic mode, to validate results between CPU and GPU.
4. Establish automated continuous benchmarking, to monitor the evolution of the GPU processing performance per O2 version.
- We already have/had such benchmarking on the alibi server with some old GPUs. But this should be extended, we need to use more modern GPUs, and we need monitoring and alerting.
