Choose timezone
Your profile timezone:
Framework
Computing
Evaluated different network sizes: 5 x (2 TF, FST, only classification network (+ CF regression), float16) per NN


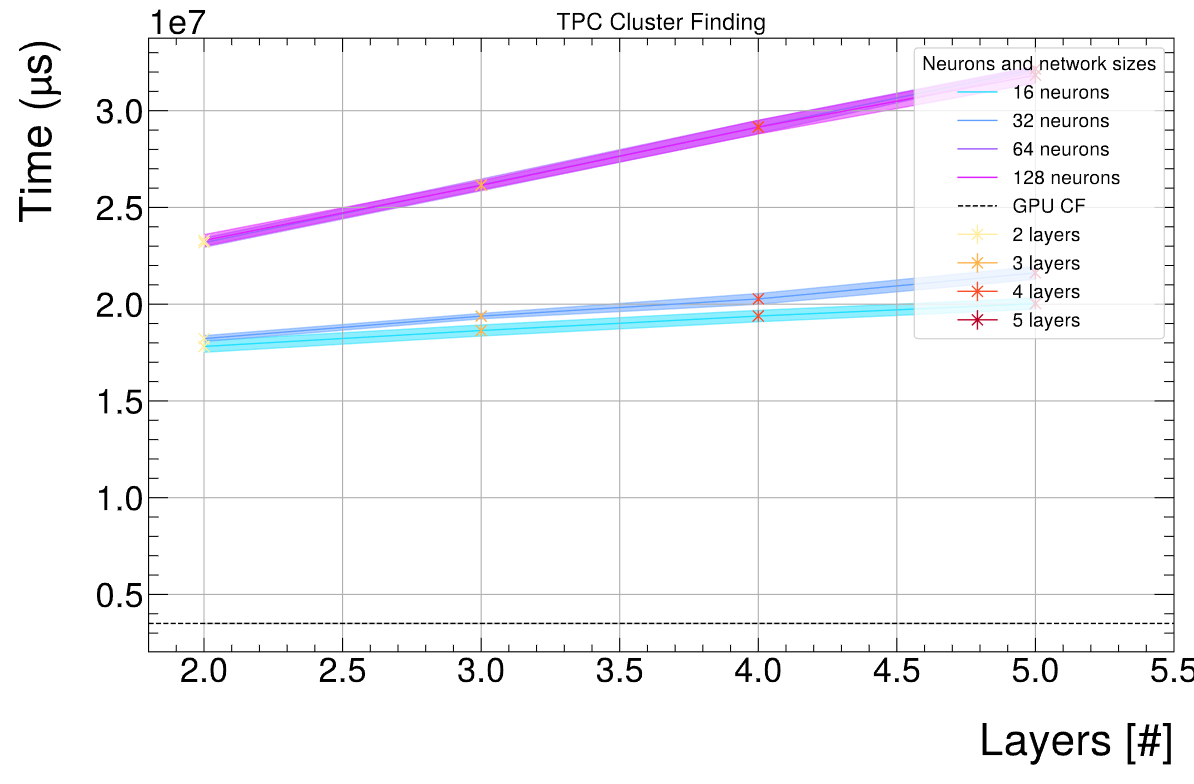





Question
# ITS tracking status
1. Quick overview of current CPU refactoring
2. New features currently in development
3. Status of the GPU part
---
## 1.1 Current CPU refactoring
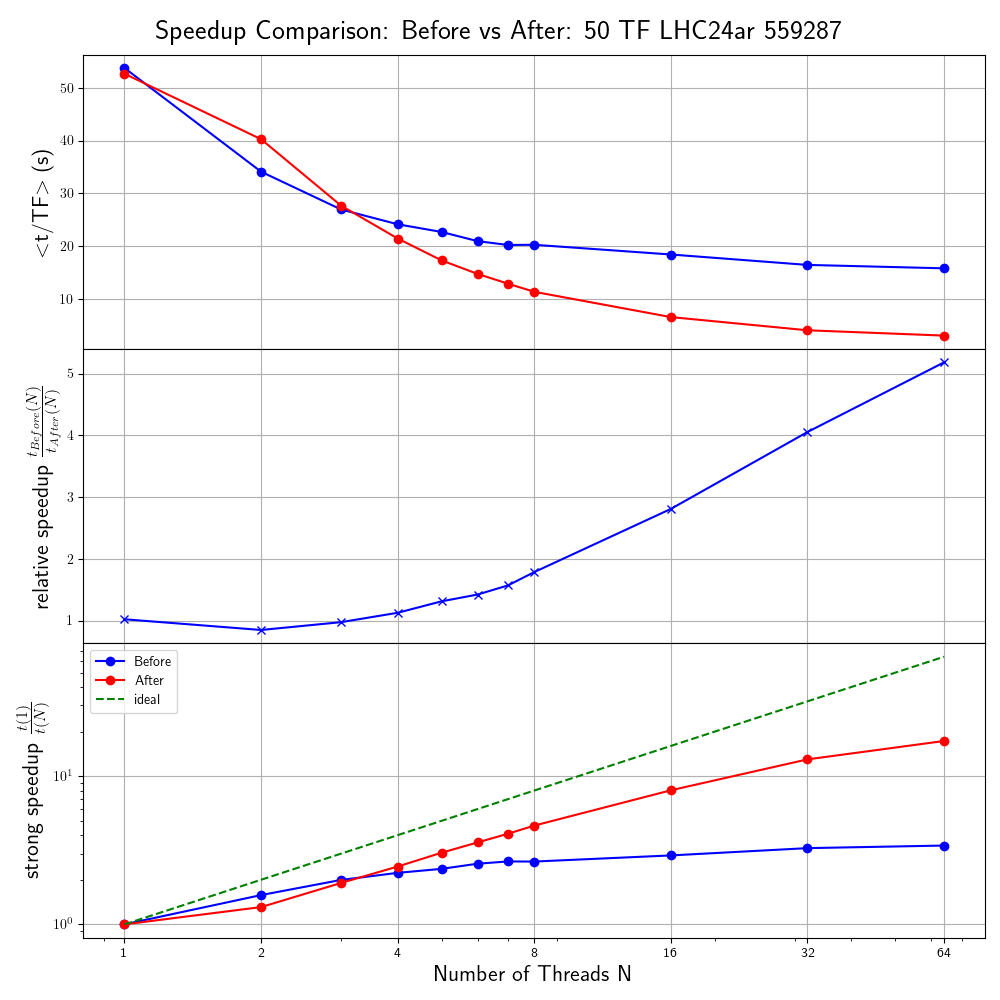
---
## 1.2 Memory consumption
Here for one particulary parasitic TF in Pb-Pb with two central collisions in on readout-frame.
Plot shows before(blue)/after(red) refactoring.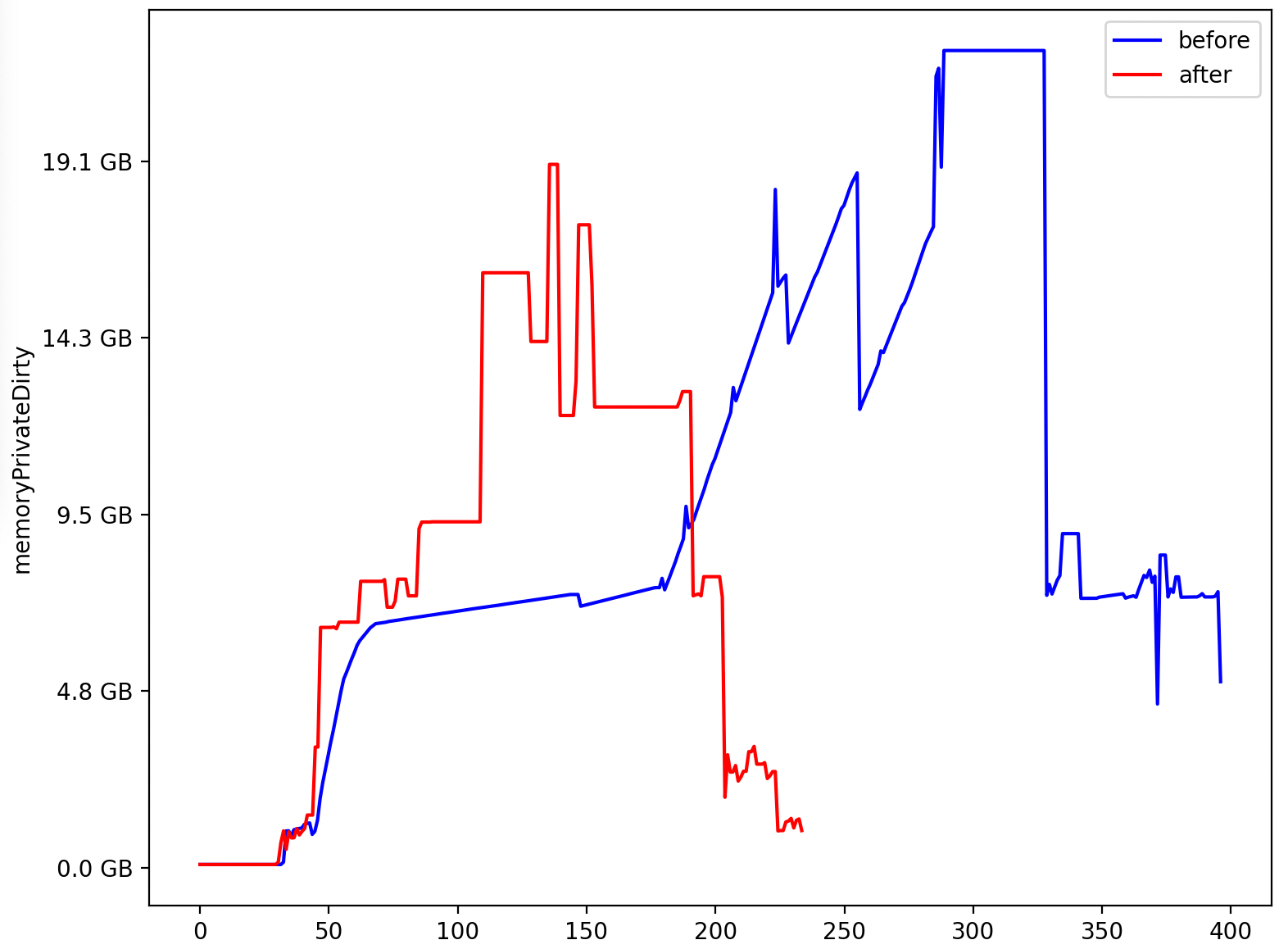
Plot shows a special mode `perPrimaryVertexProcessing` which reduces the comb. significantly but has some currently studied side effects. Blue is with this mode enabled now, red as it is before.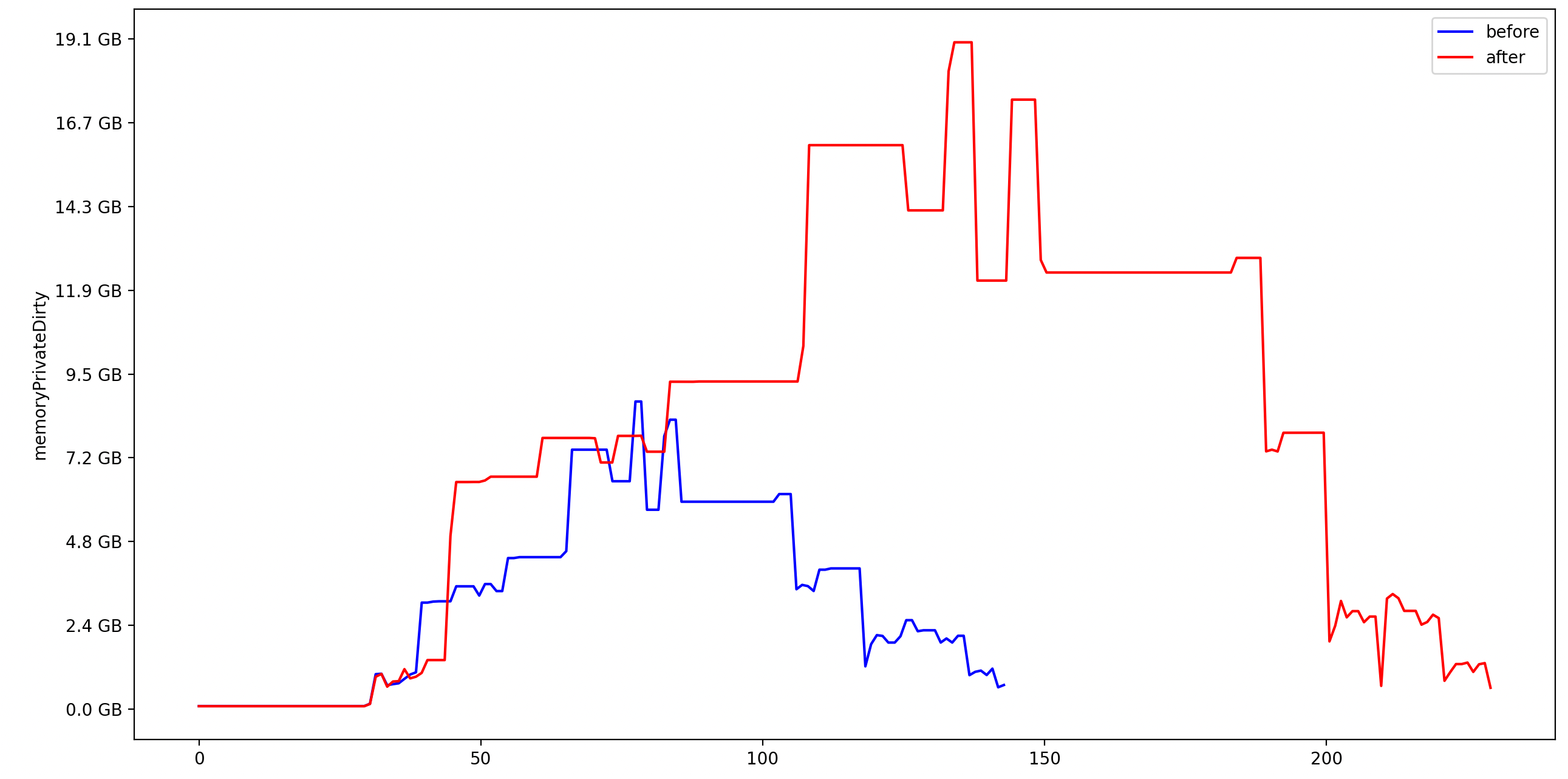
## 2. New/Improved features: `DeltaROF` tracking
In contrived MC with exagerated slope in the chip response function one can clearly see the drop of eff. towards the beginning/end of the readout-frame.
In analysis these collisions are completely cut away (standard selections) ~20% of data loss.
This feature should cure this.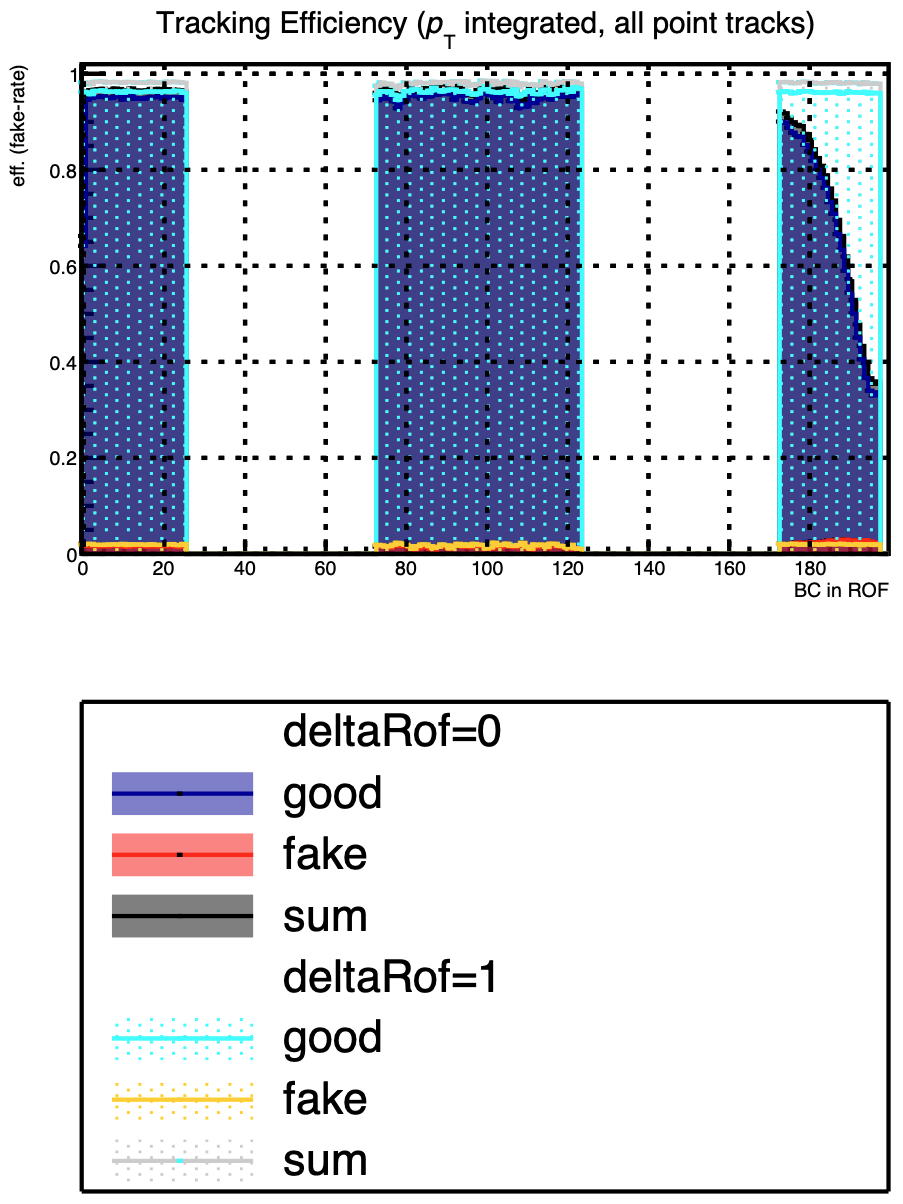
Comes with an increase cost in memory and time (but worth it)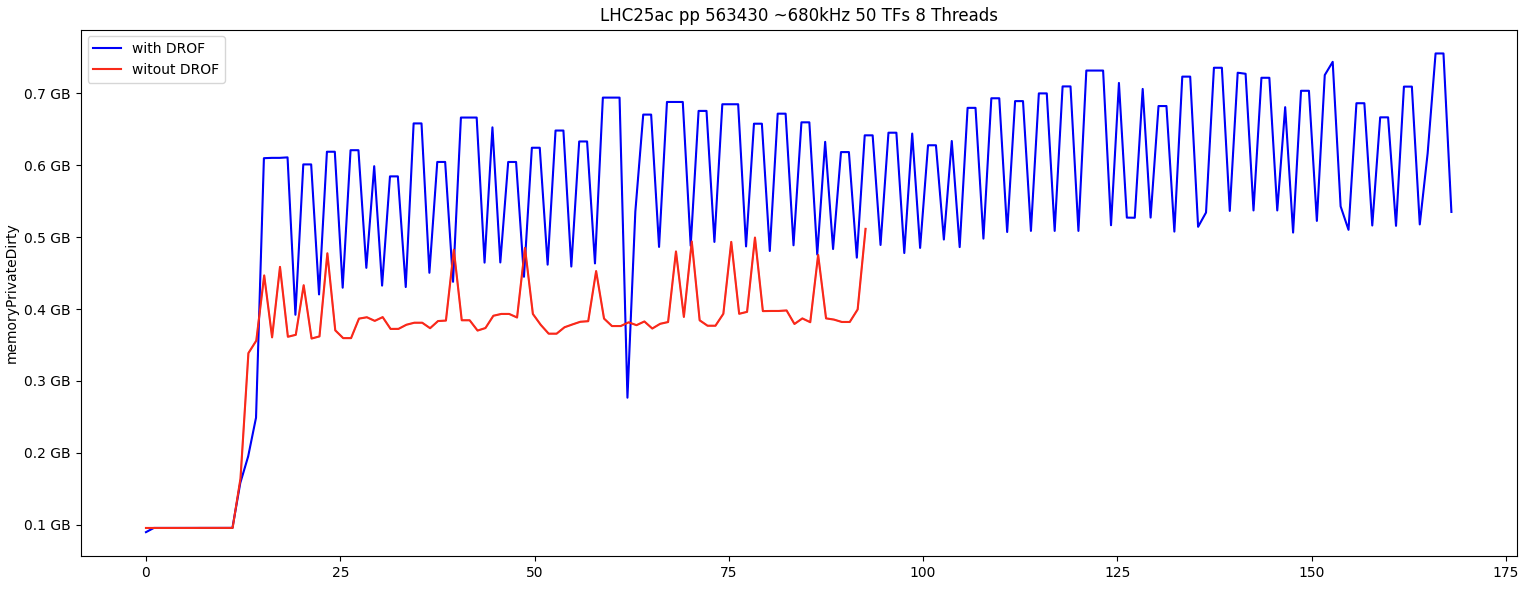
## GPU Part
After the refactoring of the reco code, checked again if GPU is now messed up. After some fixes minor fixes, in debug mode the output is 1:1 the one from the cpu code (10TFs in 40kHz Pb-Pb):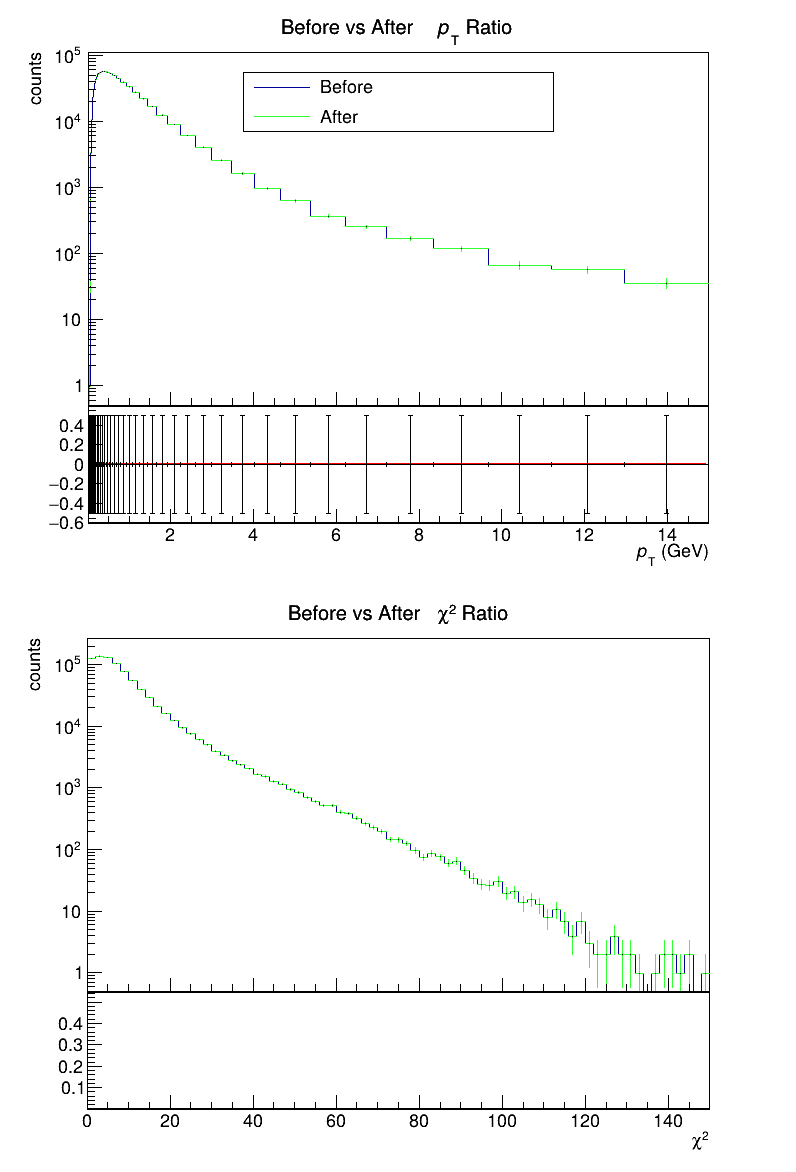
```cpp
#define GPU_BLOCKS GPUCA_DETERMINISTIC_CODE(1, 99999)
#define GPU_THREADS GPUCA_DETERMINISTIC_CODE(1, 99999)
// calling kernels like this -> effectively serializing the code (very slow)
gpu::computeLayerTrackletsMultiROFKernel<true><<<o2::gpu::CAMath::Min(nBlocks, GPU_BLOCKS),
o2::gpu::CAMath::Min(nThreads, GPU_THREADS),
0,
streams[iLayer].get()>>>(...)
// now this is not needed anymore and the det. mode is `fast-ish`
```
- Have a CI procedure/periodic check that runs ITS GPU reconstruction and then gets some automatic checks and numbers (deterministic mode is more important)
- Ensure gpu-reco-workflow with ITS enabled are the same that one gets from its-reco-workflow --gpu
