Choose timezone
Your profile timezone:
Online runs - summary
Physics: ITS-TPC matching
Reminder: Major losses observed in 0.2 < | q/pT | < 2, ...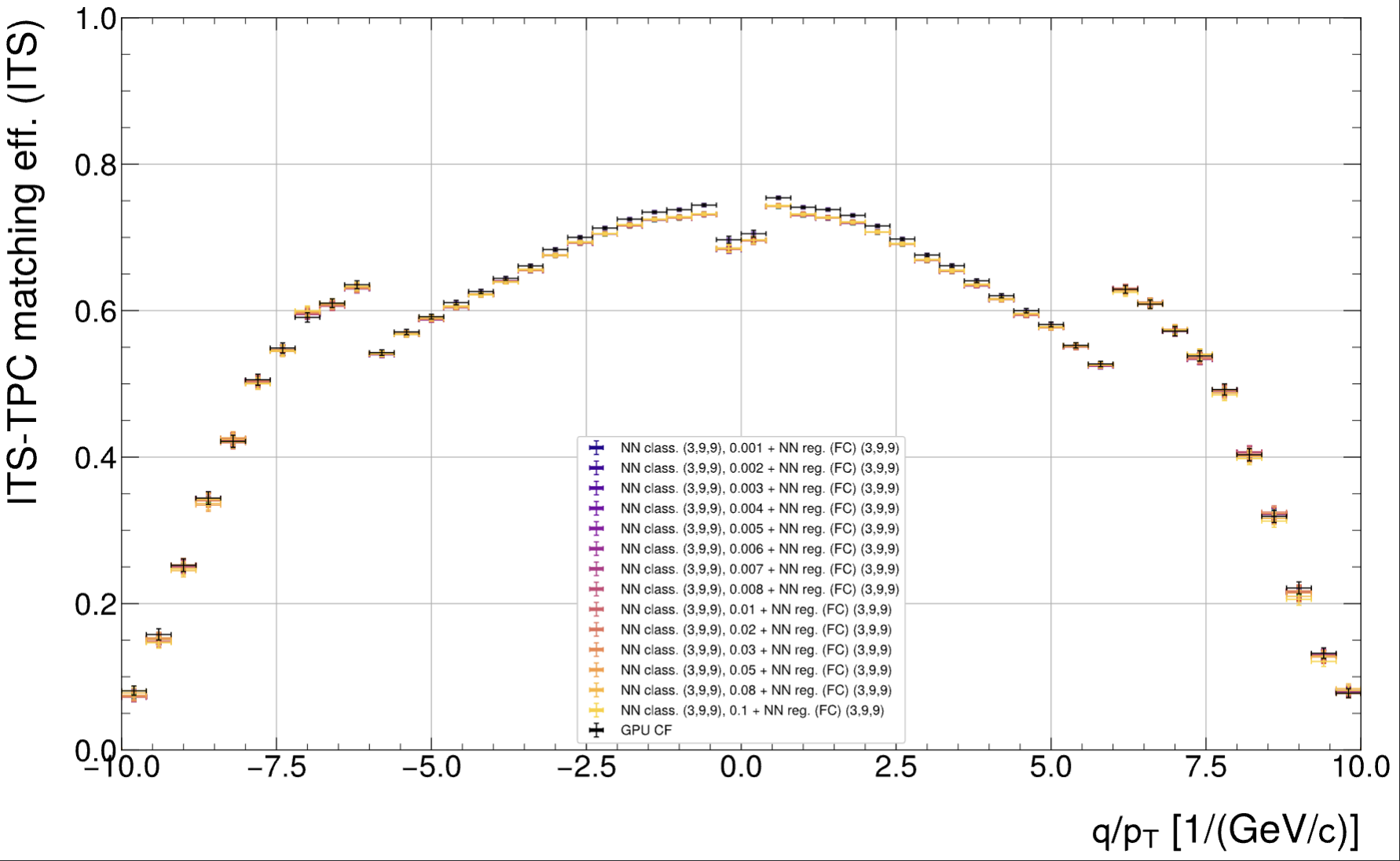
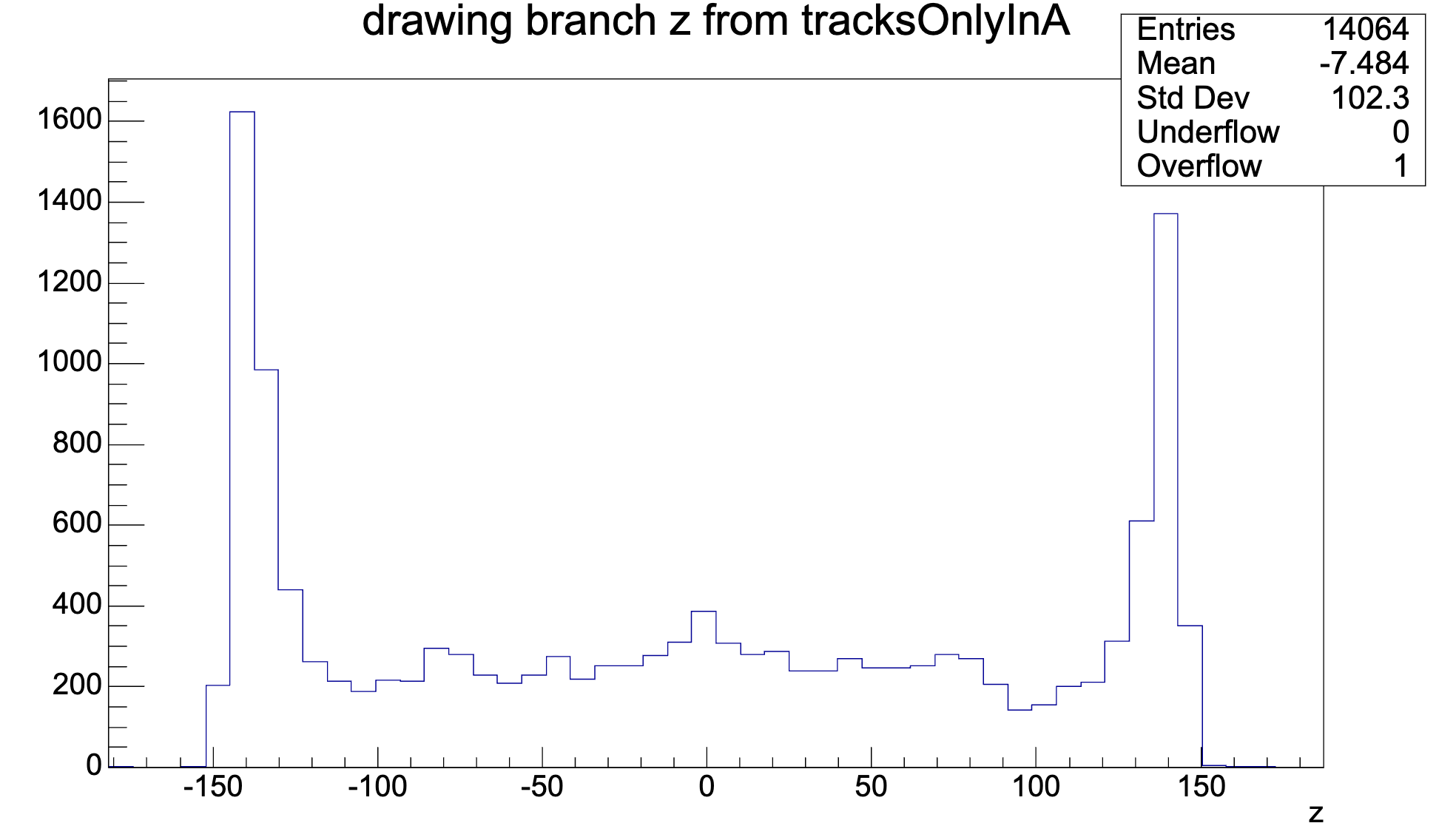
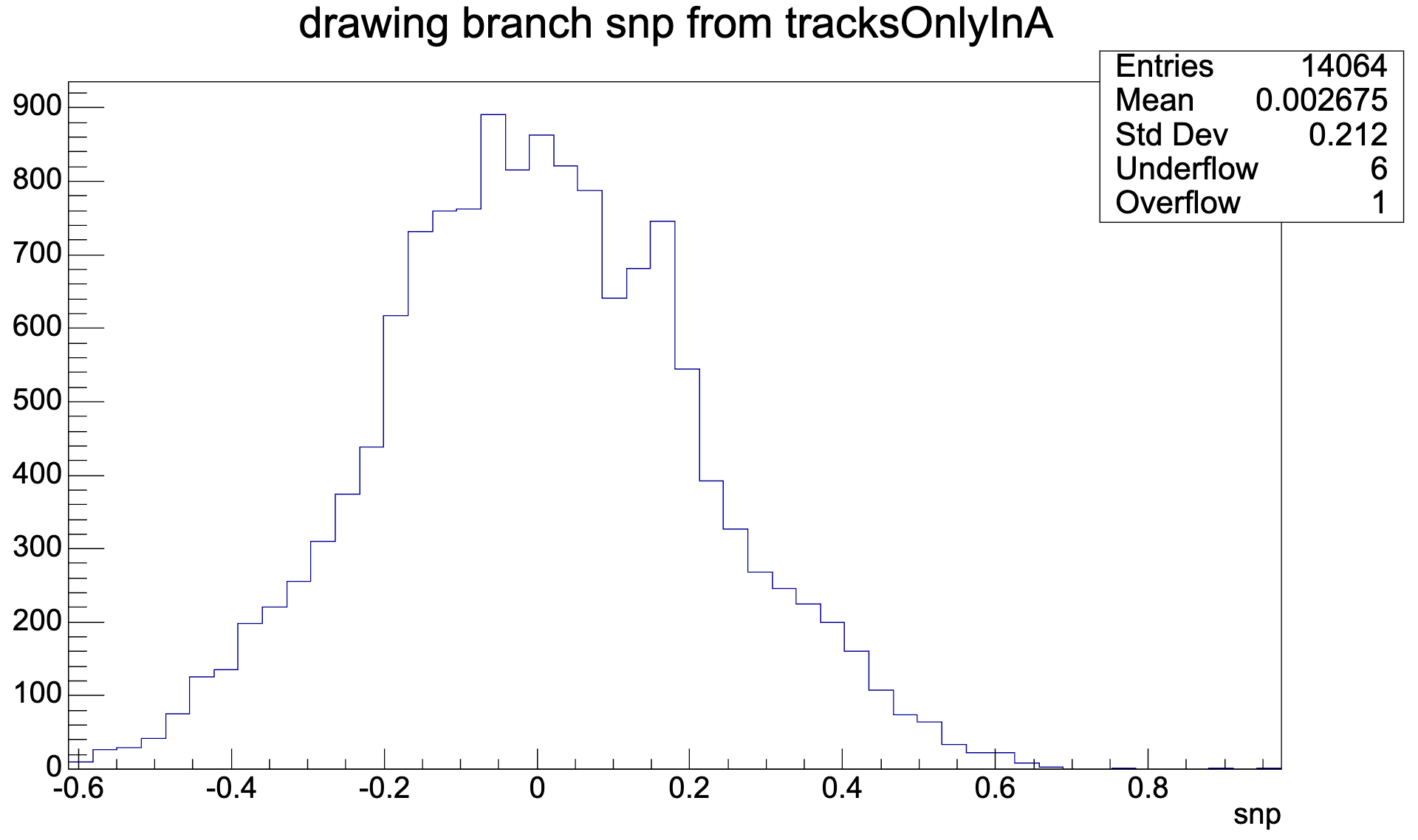
... as found in the debug trees:
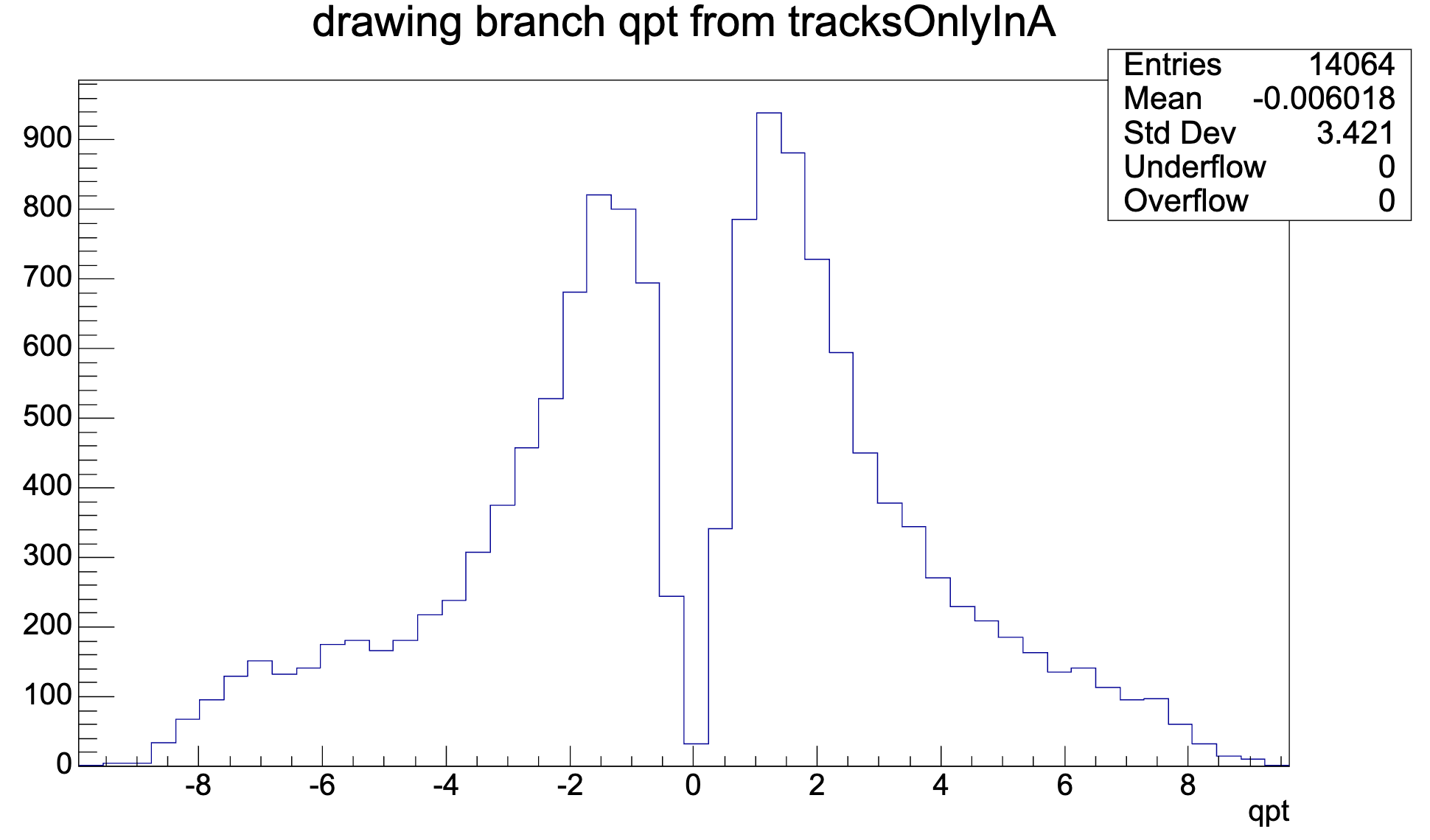
Z:
sin(phi):
tan(lambda):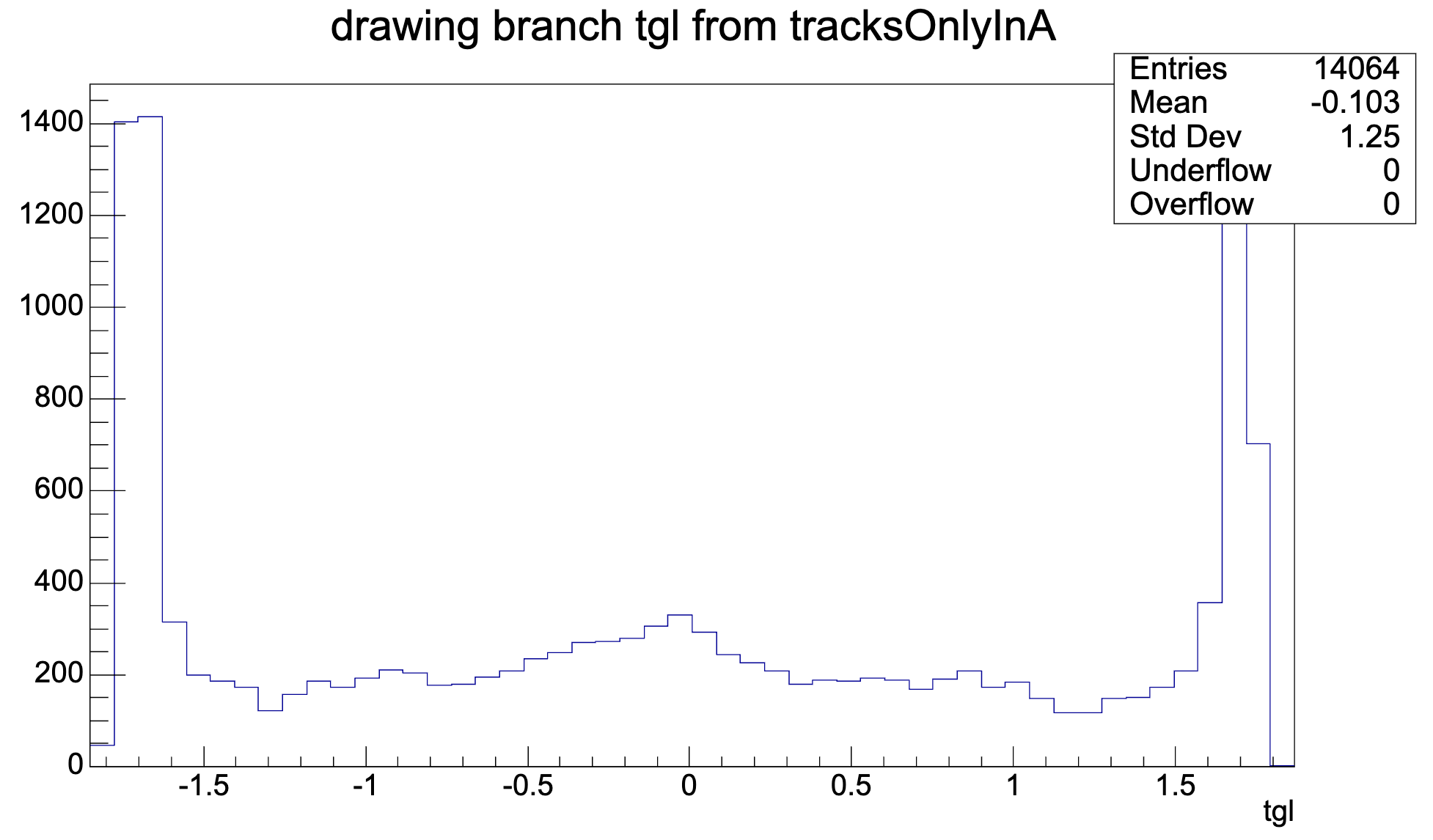
Reason why I didn't see them in the eta distribution: Window of the plot was too small.
nClustersTPC:
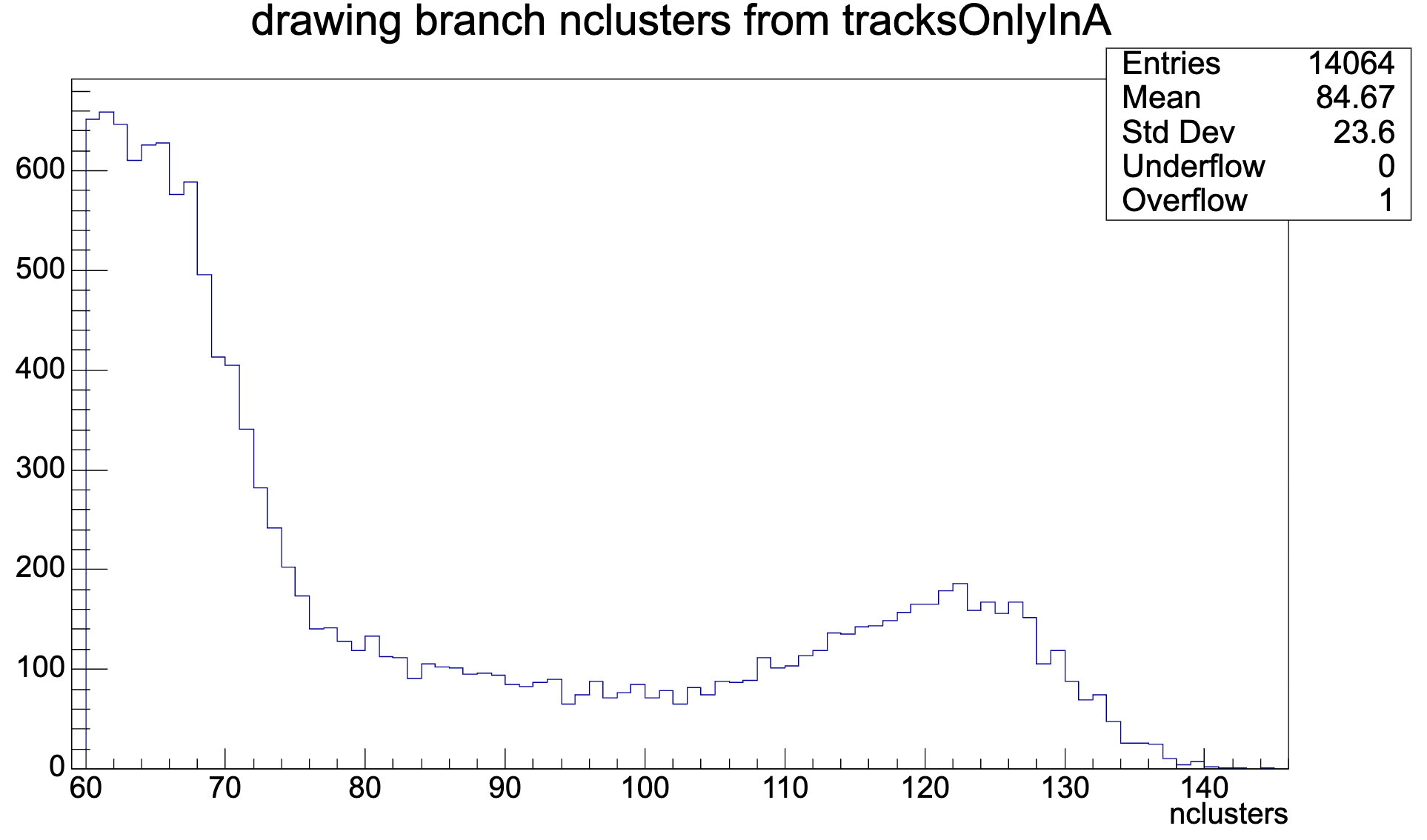
So many of the lost tracks are at NCL -> 60. How about the ones with NCL > 100?
Let's have a look at the inverse situation: ITS-TPC matches found in B but not in A:
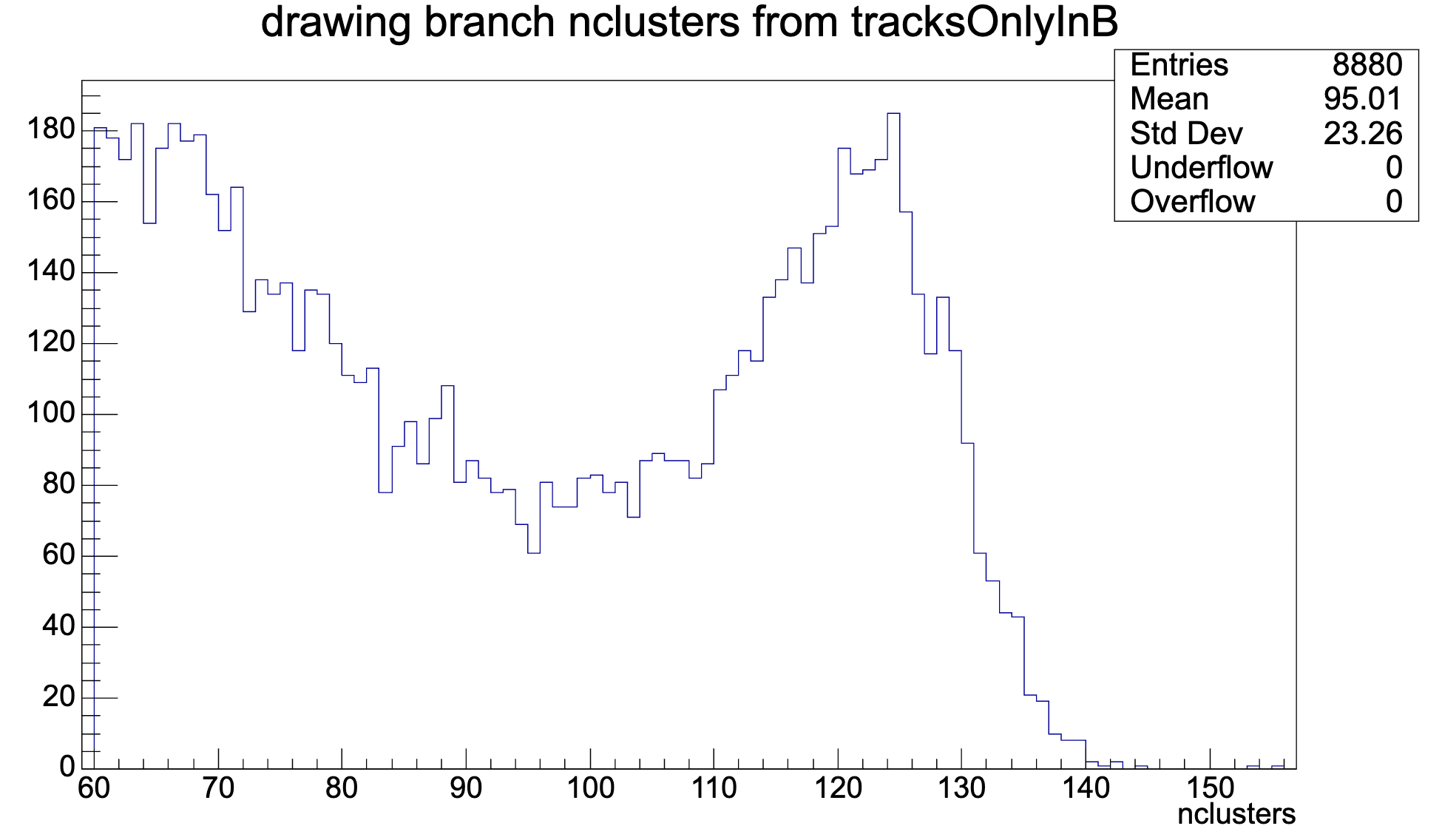
-> NCL > 100 similar here (so maybe its just an MC label mismatch: {track ID, event ID, source ID})
Finally, the loss is found: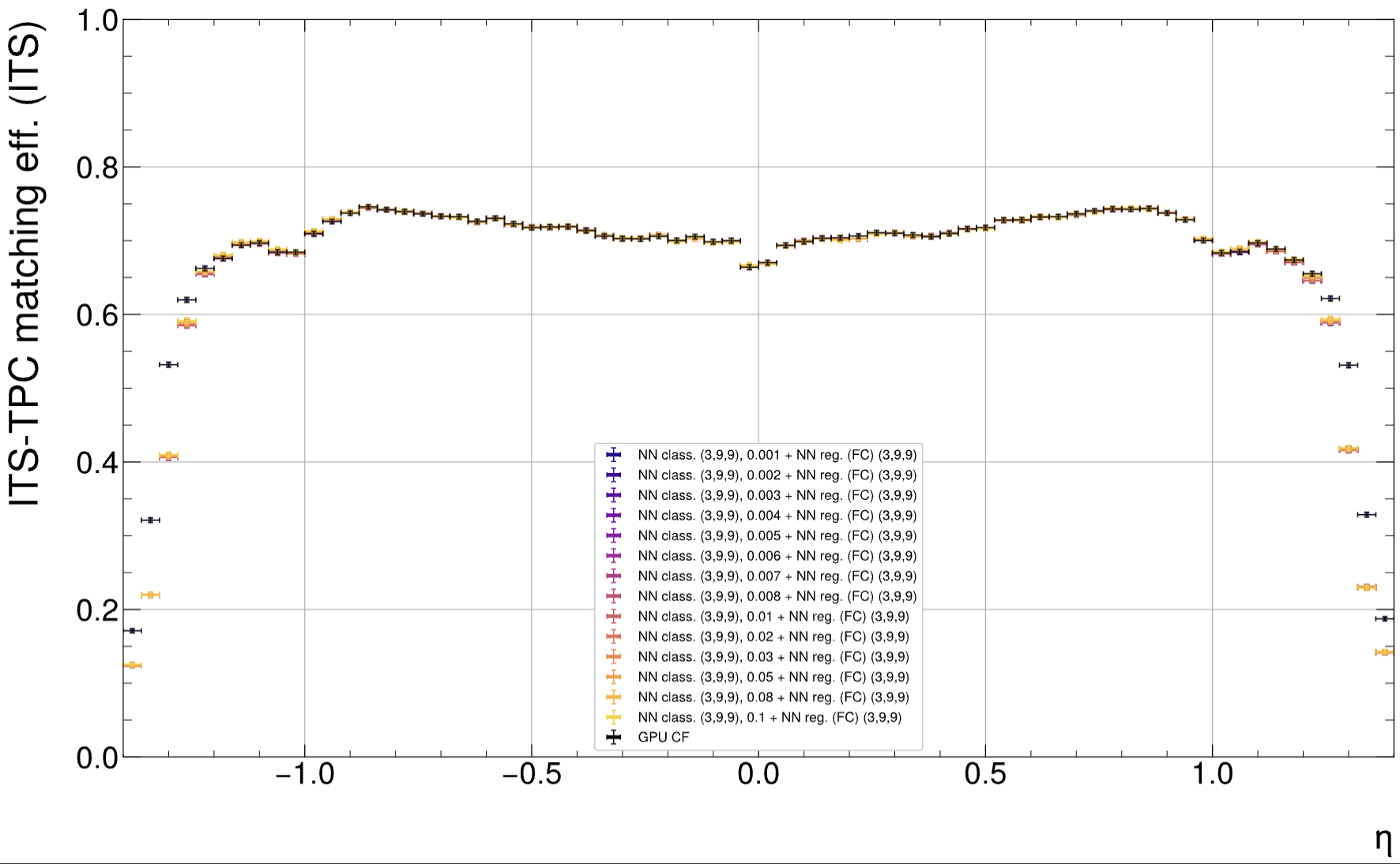
So the matching efficiency loss is now understood and comes from the high inclination region. Q: Anything to do about it?
There is also no (significant) loss in TPC efficiency at high eta, independent of the threshold: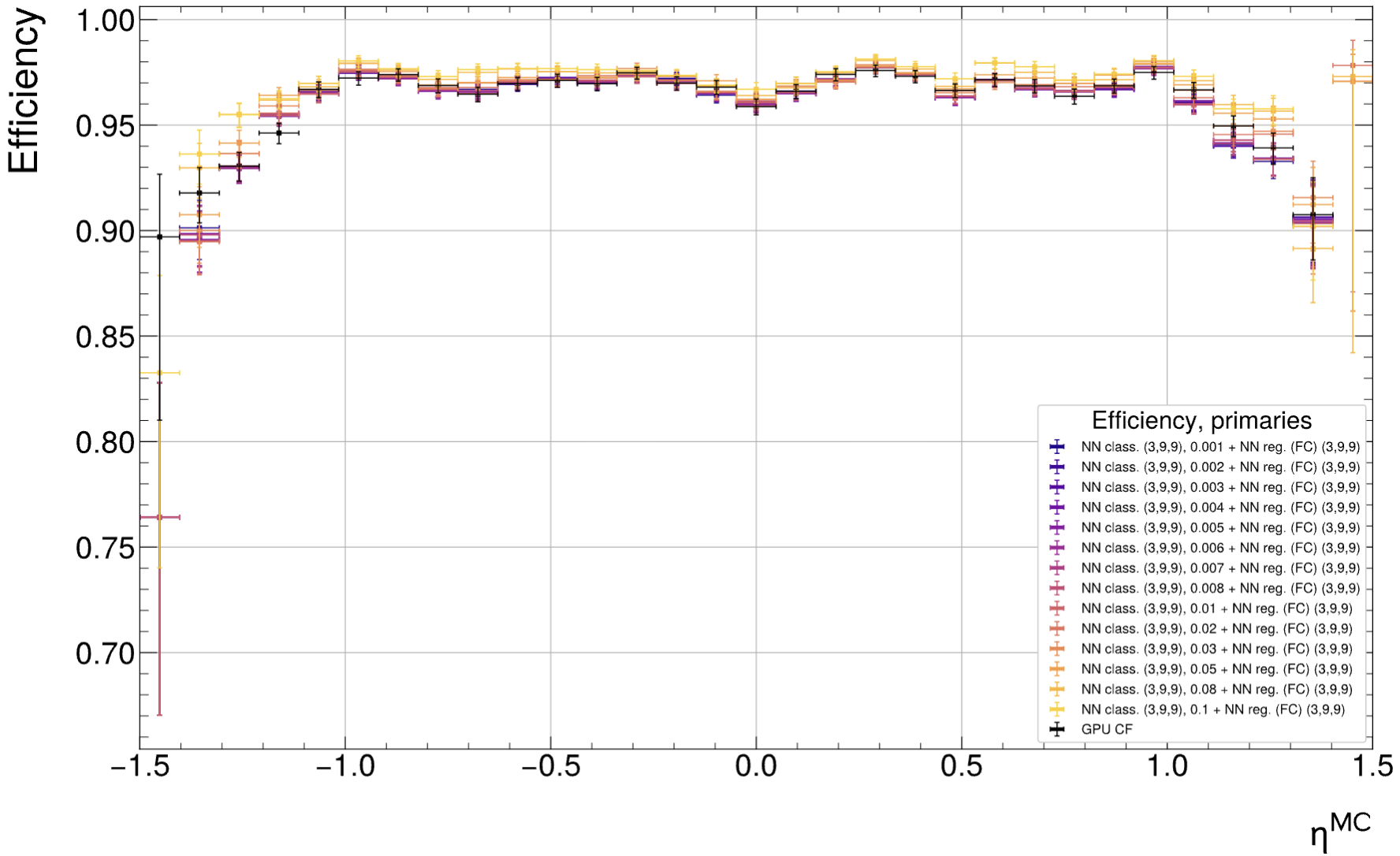
-> Conclusion: This must be an effect of changed track parameters.
