Real data reconstruction
- Used LHC24ar, apass2
- Full chain done for the following configurations:
- GPU CF (default reco)
- NN 0.03, CF regression
- NN 0.03, full
- NN 0.05, full
- NN 0.1 full
PID calibration
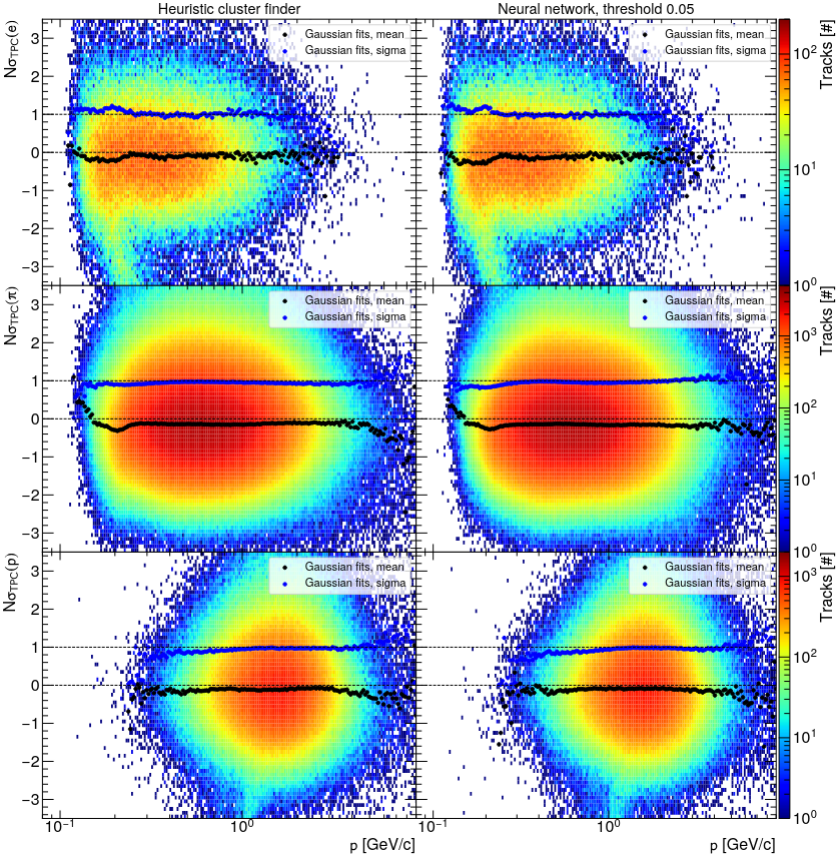
- Successful for all periods, quality maintained (left: NN, right: heuristic)
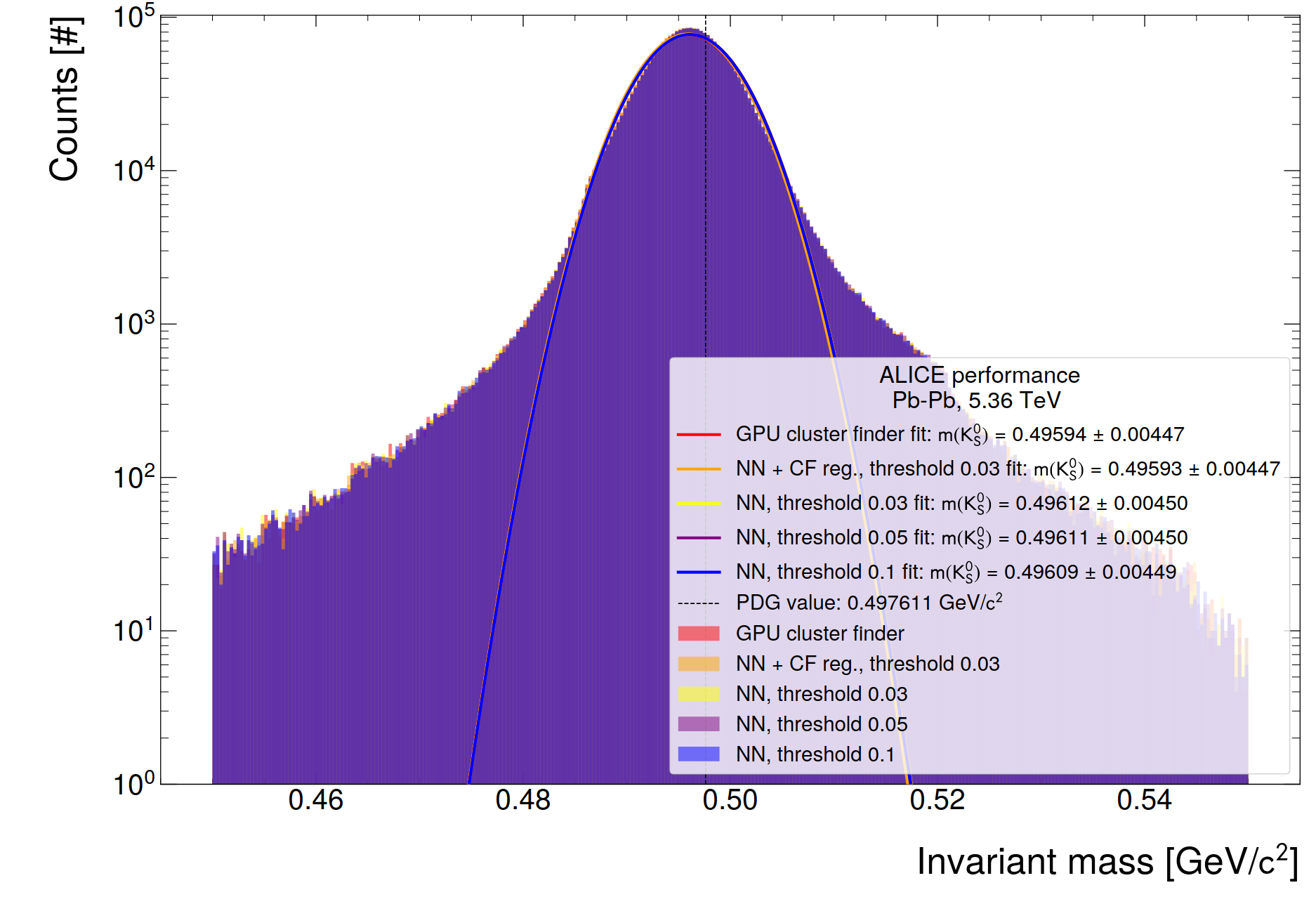
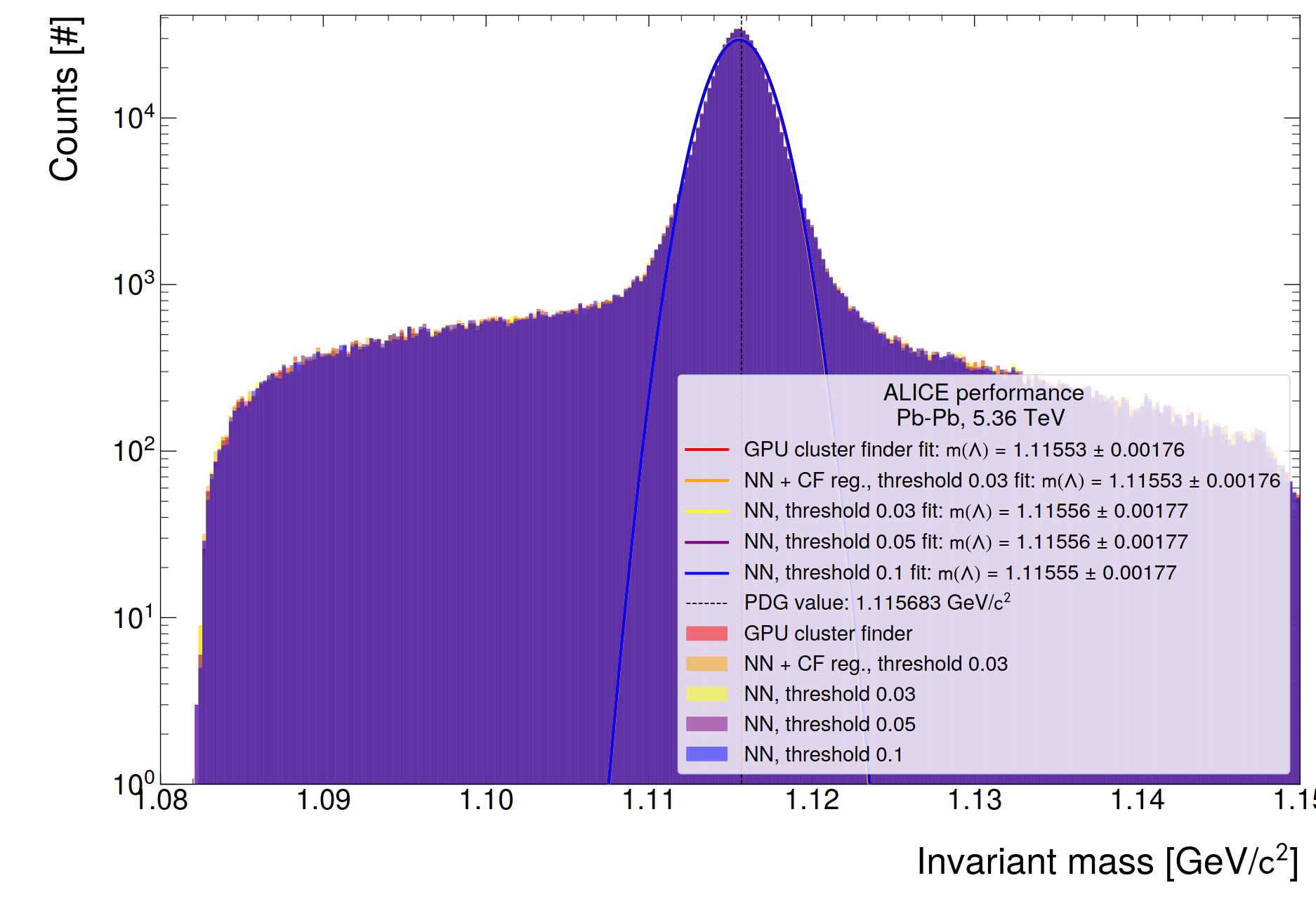
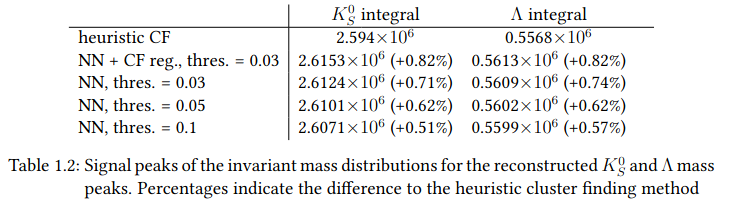
- Ratio of track distribution from 200 TFs
- Reduction until max. 300 MeV, as expected from MC
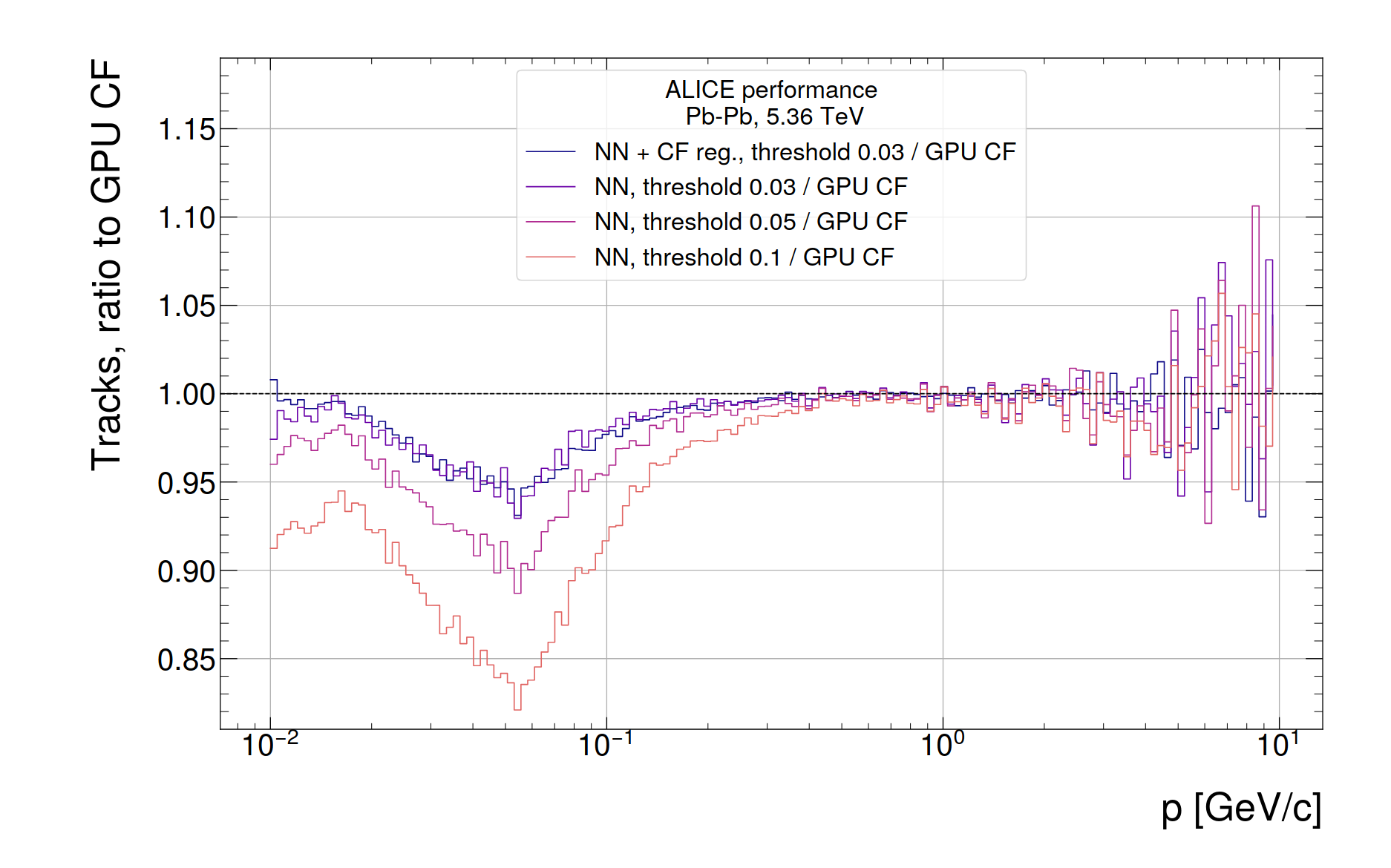
- NCL distribution of tracks from 200 TFs
- Reduction mainly observed for very short tracks
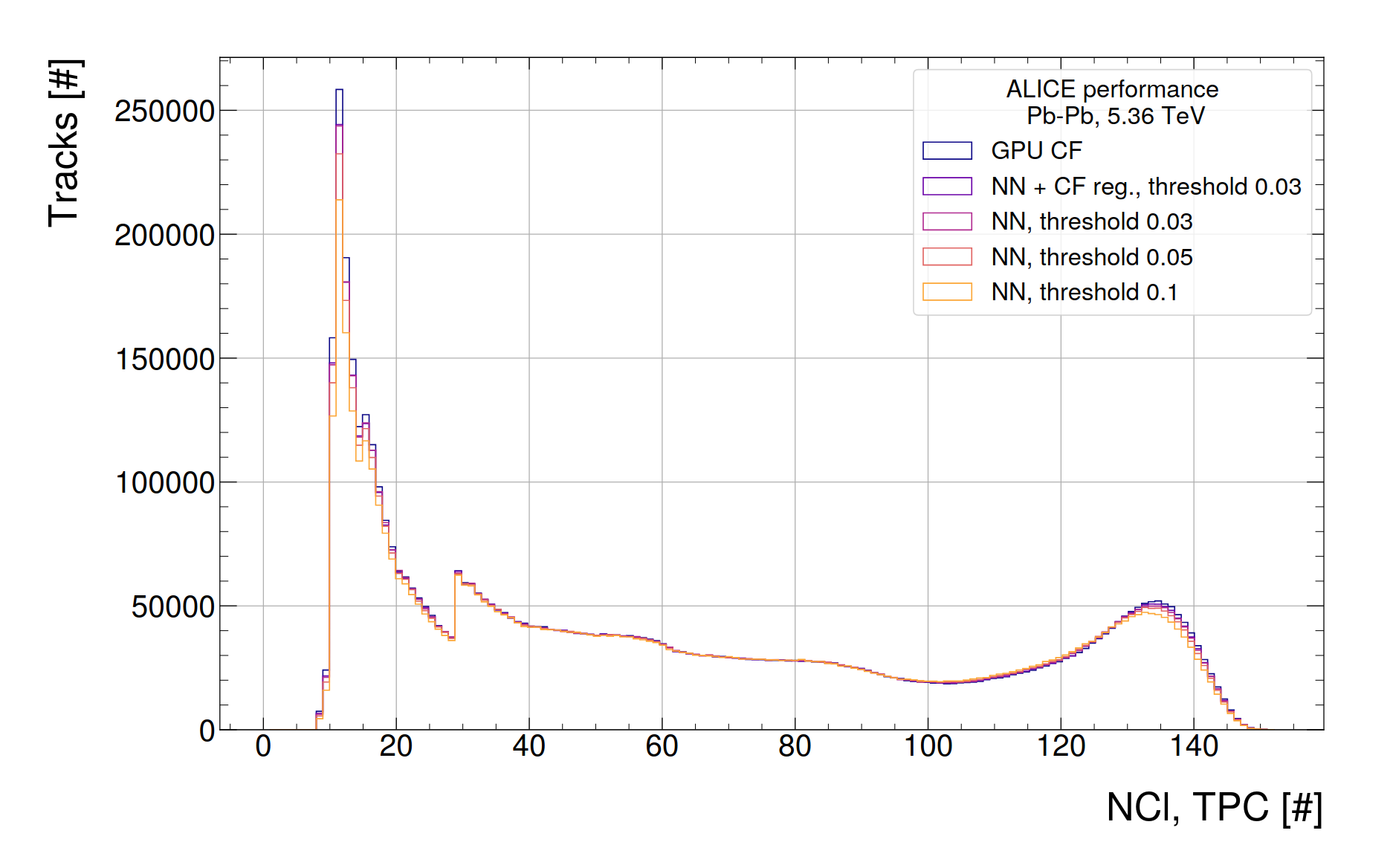
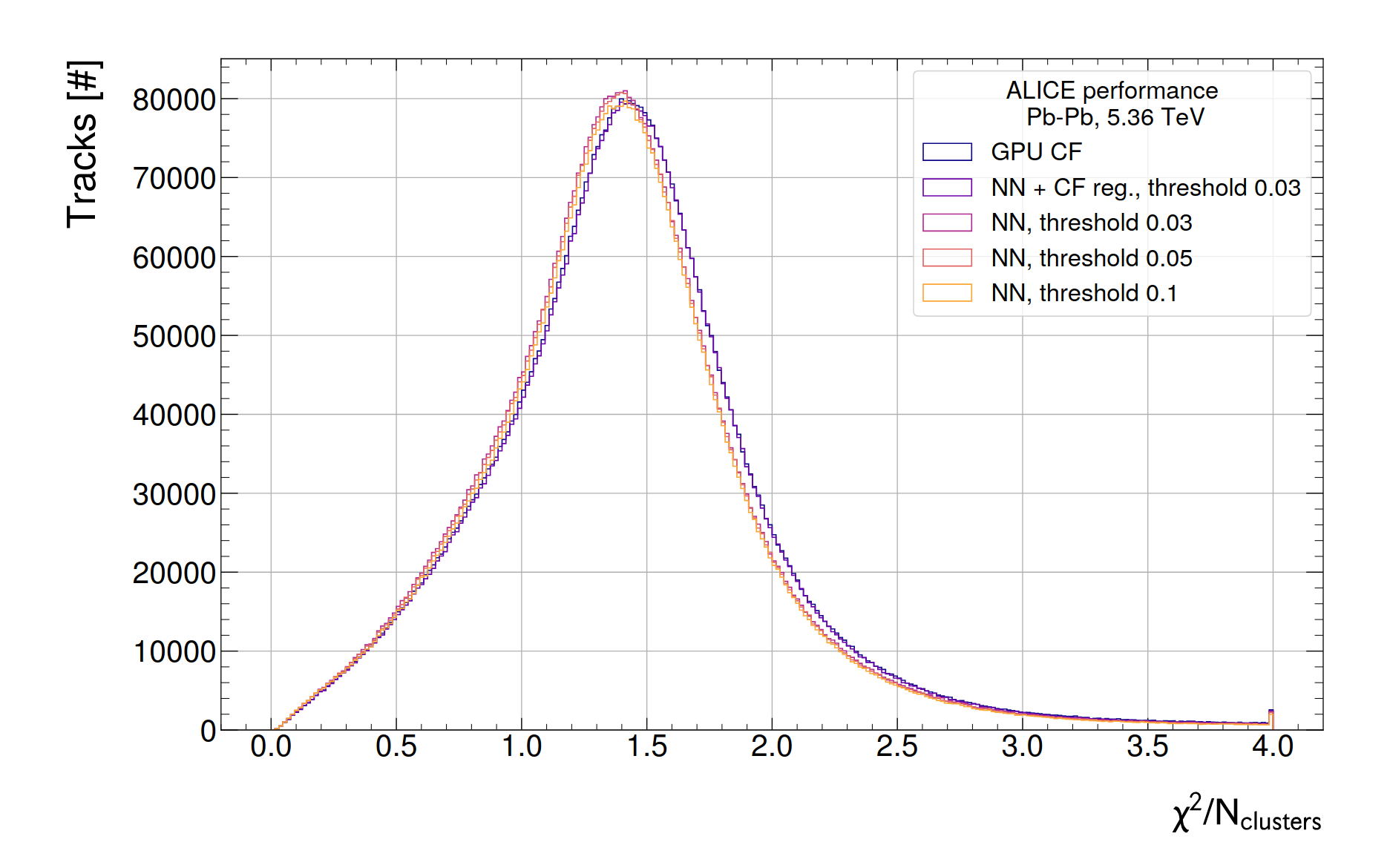
- chi2/NCL (analysis variable) from 200 TFs
- Improvement noticeable for all cases where NN regression is used

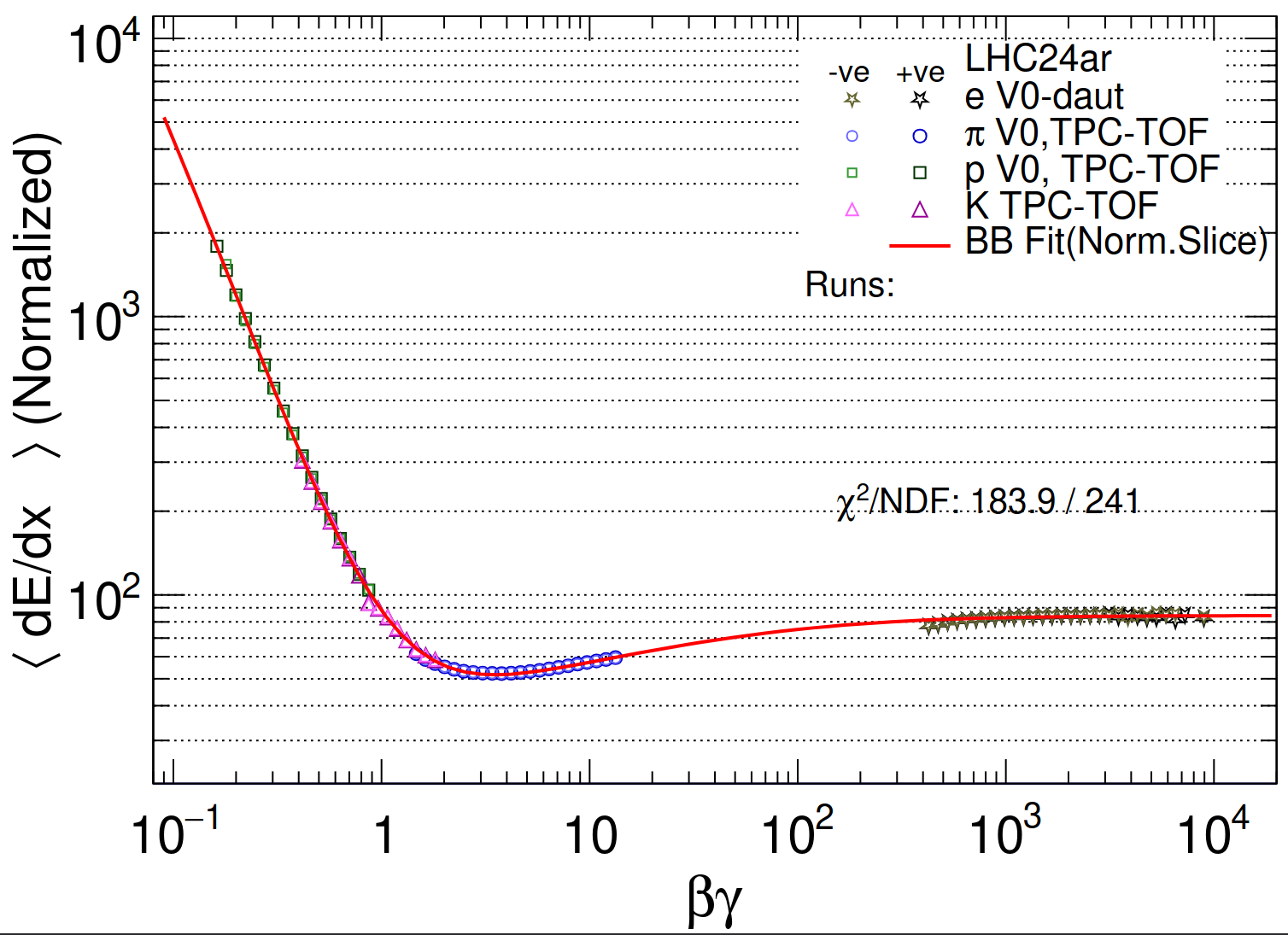
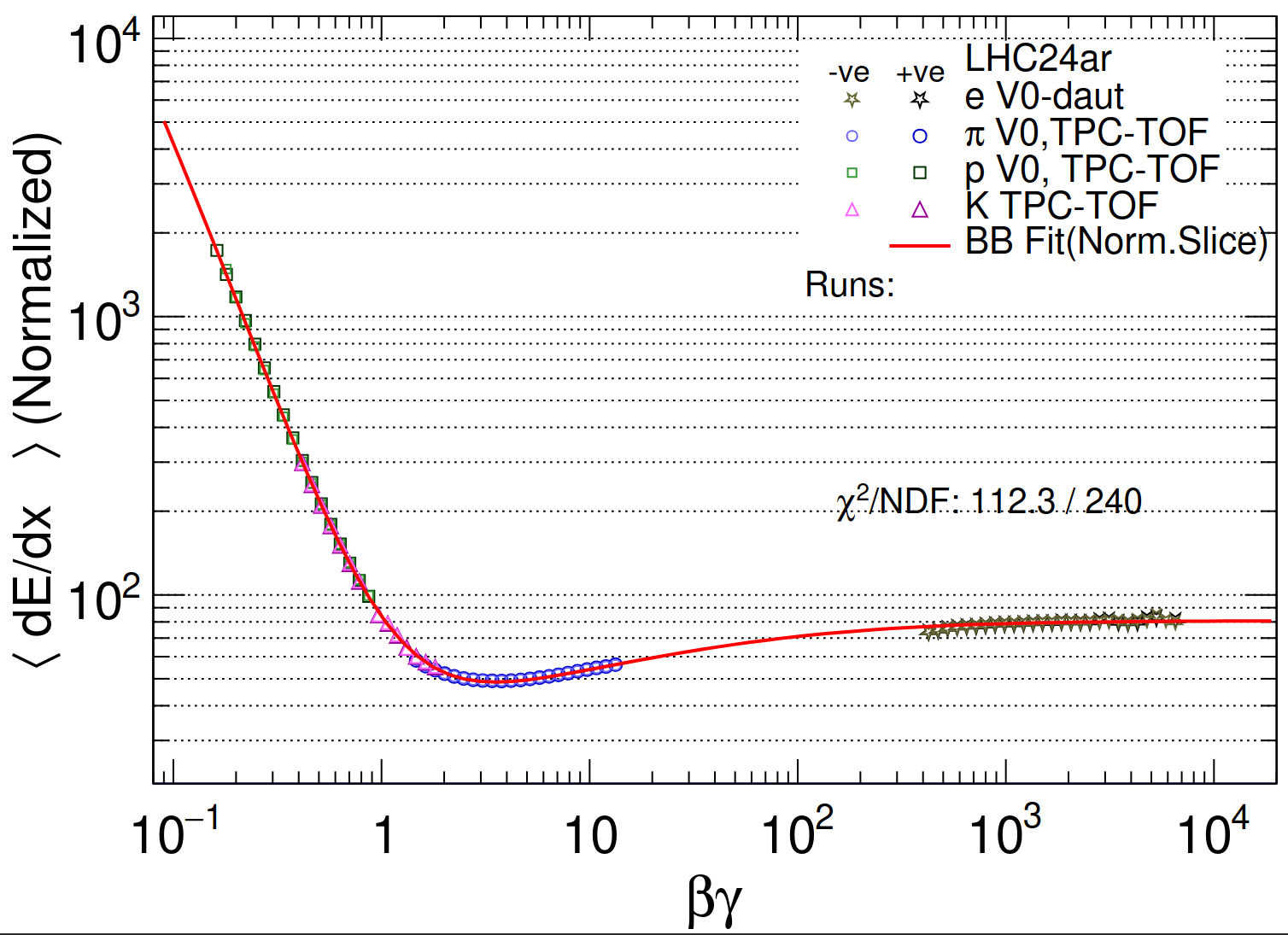
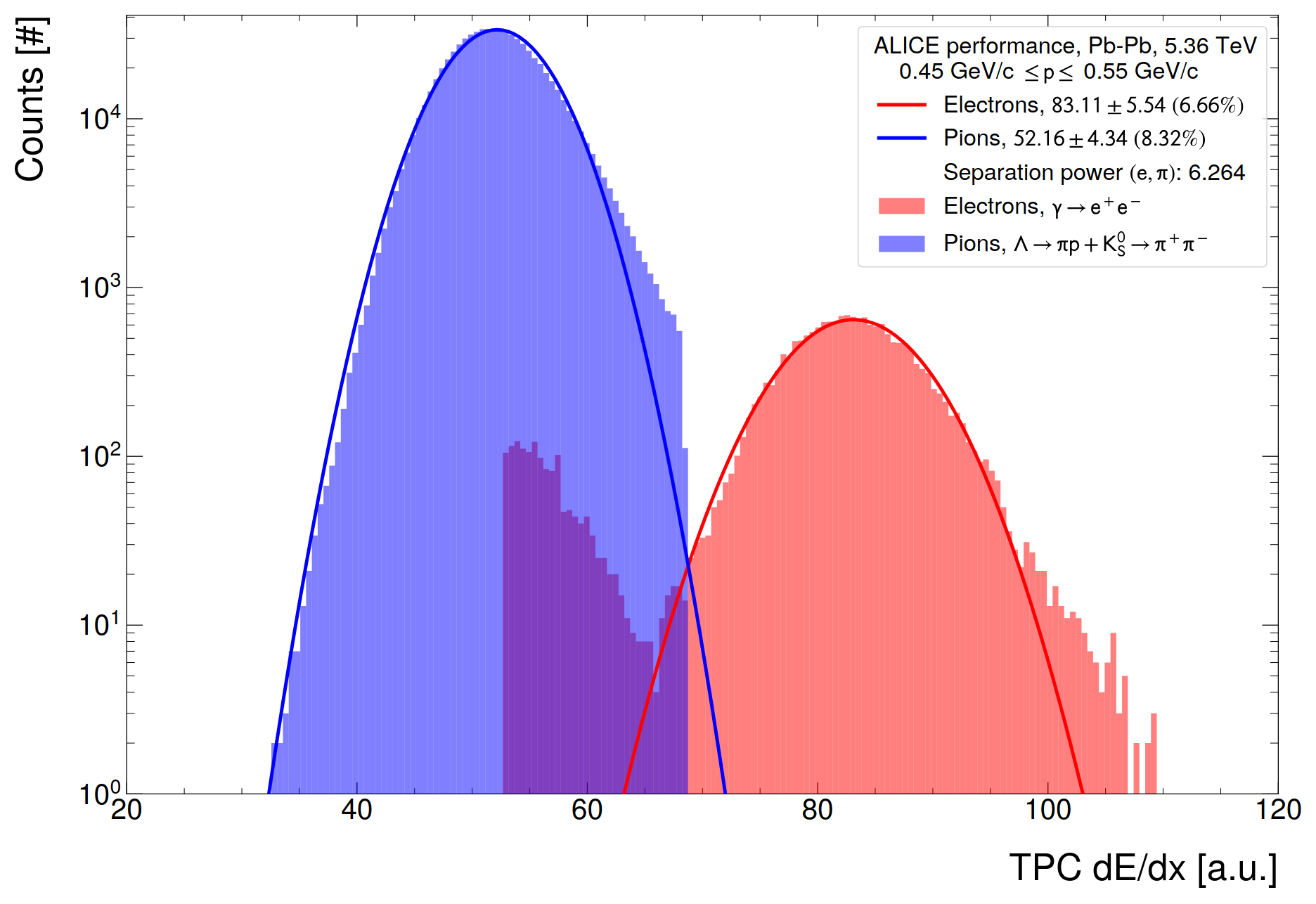
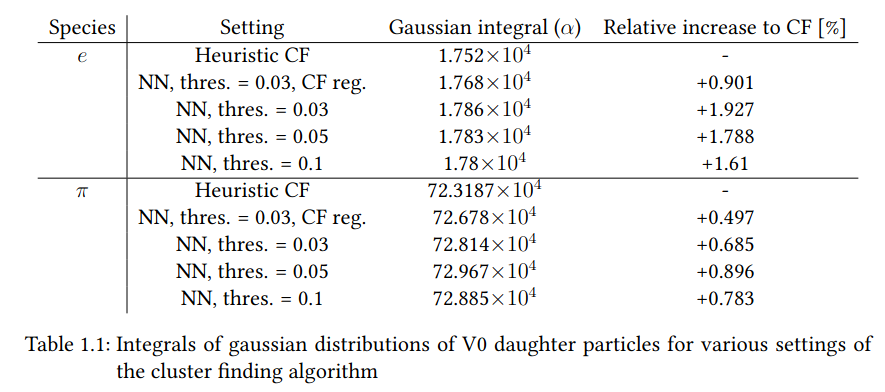
- Separation of pion and electron band from selected V0s
- Showing one figure as example (NN, 0.05)
Commissioning runs
- It ran in online (03.10.2025) 🥳🥳🥳
- Noise is significantly higher in real data than in MC
- Adjustment needed for qTot threshold
- Criterion: Adjust until number of tracks and number of clusters roughly match default reco, without using any classification by the NN
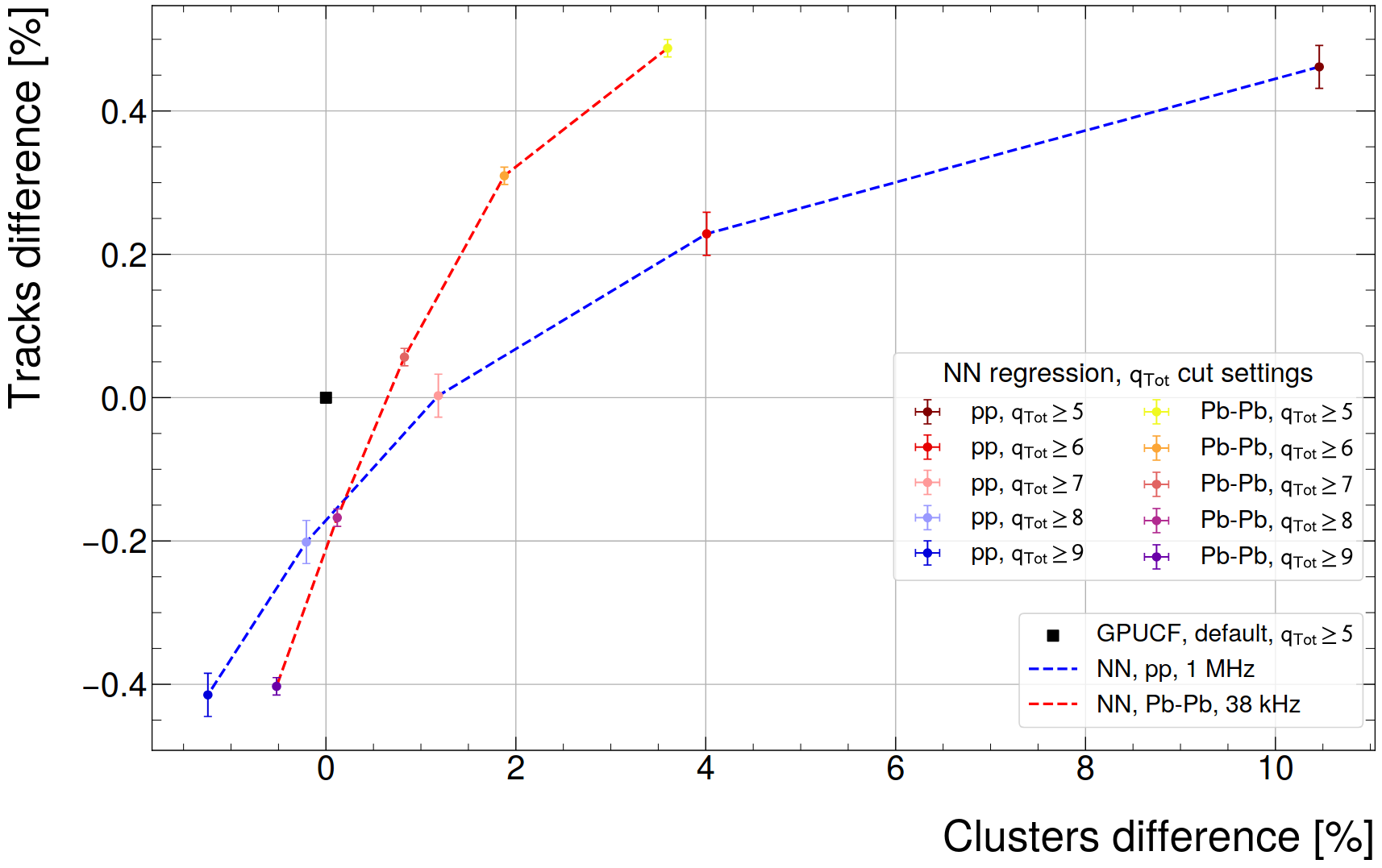
- Bonus: Is the current qTot thershold a good choice for the default reconstruction?
- Spoiler: Good for pp but could be loosened for Pb-Pb
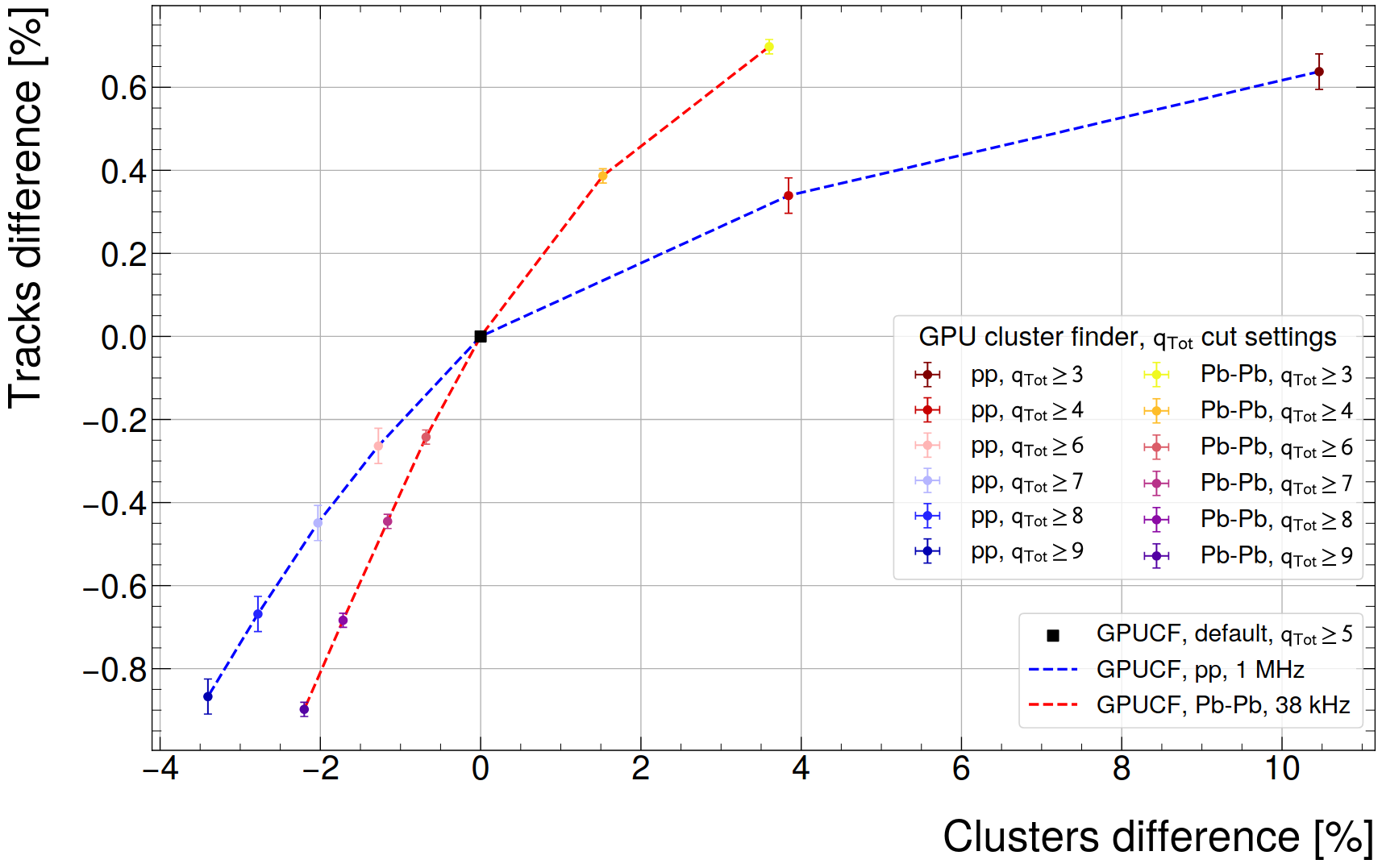
- Chosen threshold for online run: qTot \geq 8
- Actual comissioning runs
- 566696: NN, full configuration, threshold 0.05
- 566697: NN classification, threshold 0.05 + heuristic regression
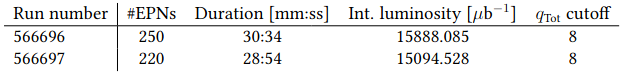
- Unfortunate mistake: 566697 also has qTot \geq 8, even though it uses the heuristic regression
- Previous investigation: Makes a difference of 2.8% clusters and 0.7% tracks (pp, 1 MHz)
- Realistic check on CTF size: more like 1.4% clusters, because the run was a pp, 500 kHz
- Data-size reduction: GB / lumi

- Shows expected behavior of 9.4% reduction in total data volume
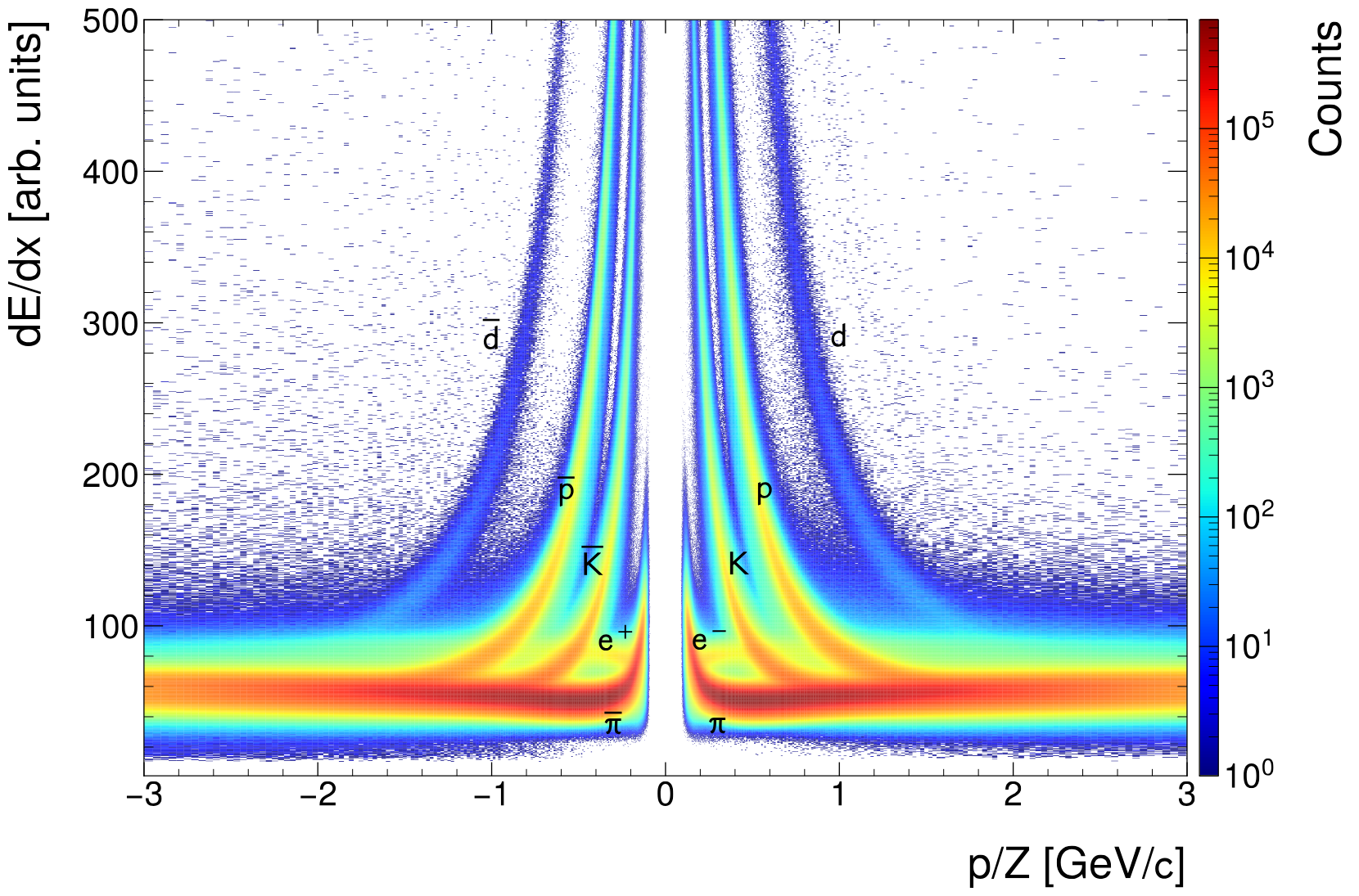
- Electron-pion separation power at MIP, not V0 but full distribution
- Left: NN, Right: Default reco from another run
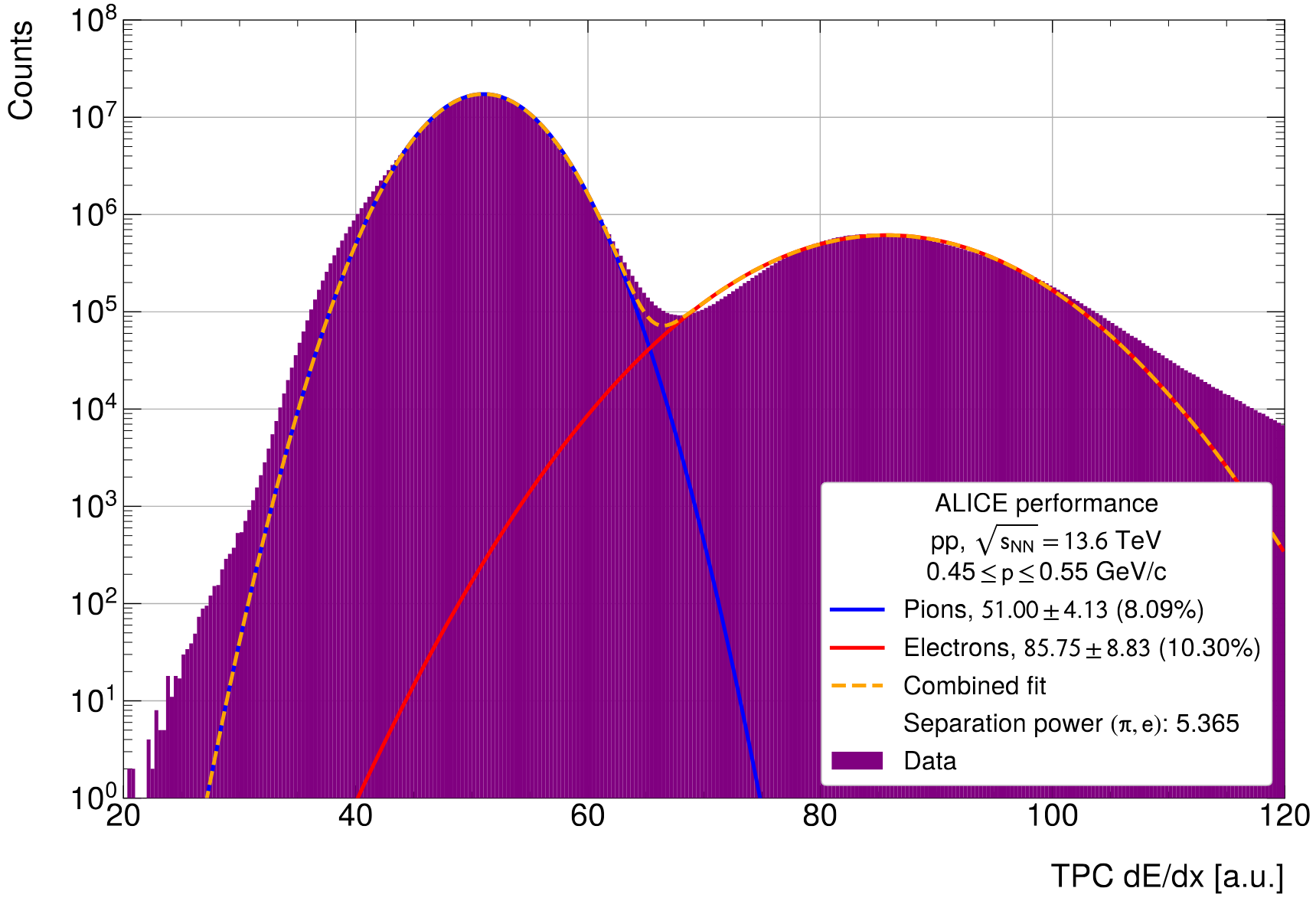
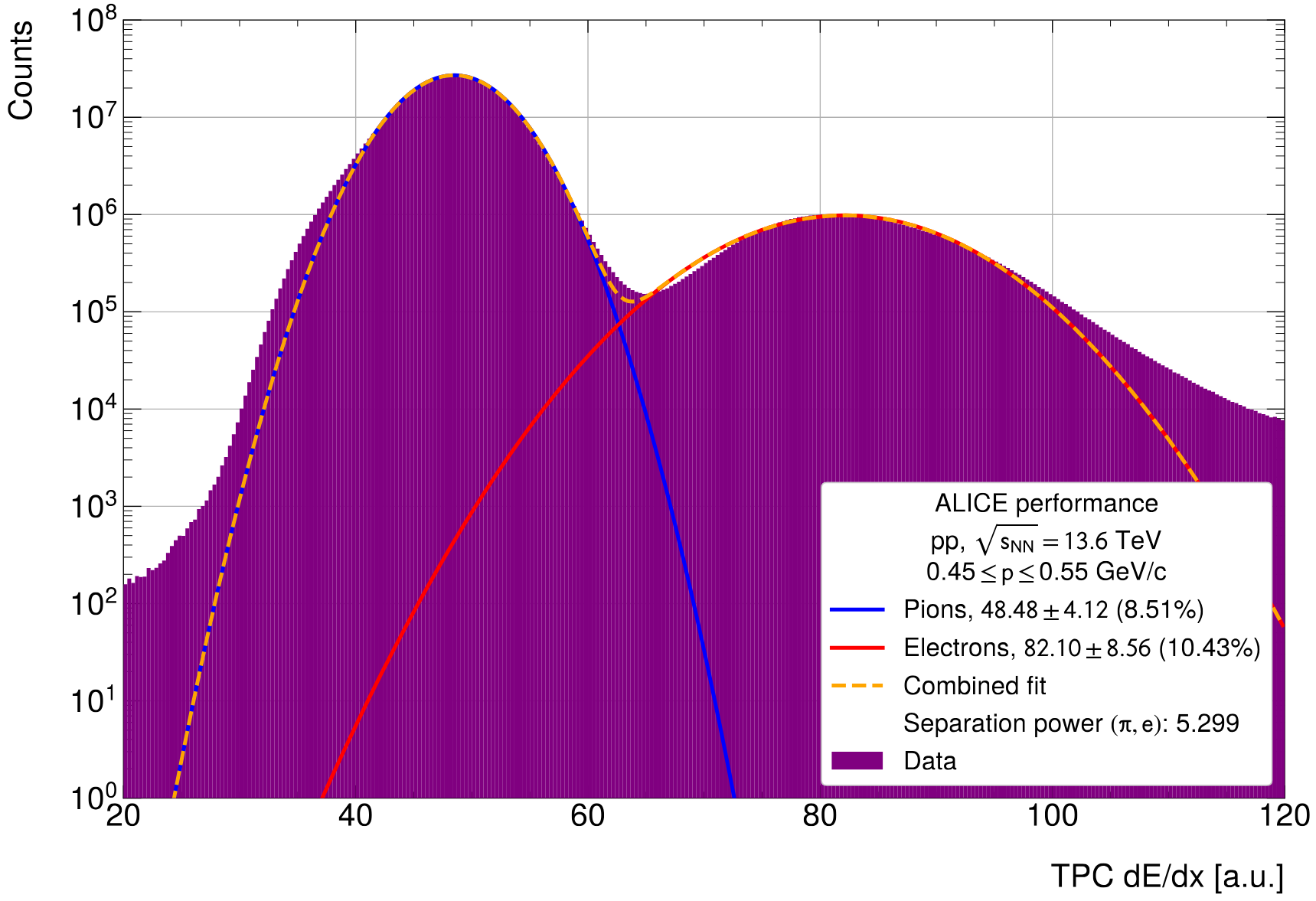
- Improves both electrons (1.25%) and pions (5%). Effect is not as strong as in Pb--Pb and not as strong as on V0 sample (because of potential surrounding noise)
- Separation power also improves by 1.3%
- Shared cluster distribution
- In any case not expected to be critically dominated by shared clusters in low-rate pp, but still good to check
- First: Check absolute counts
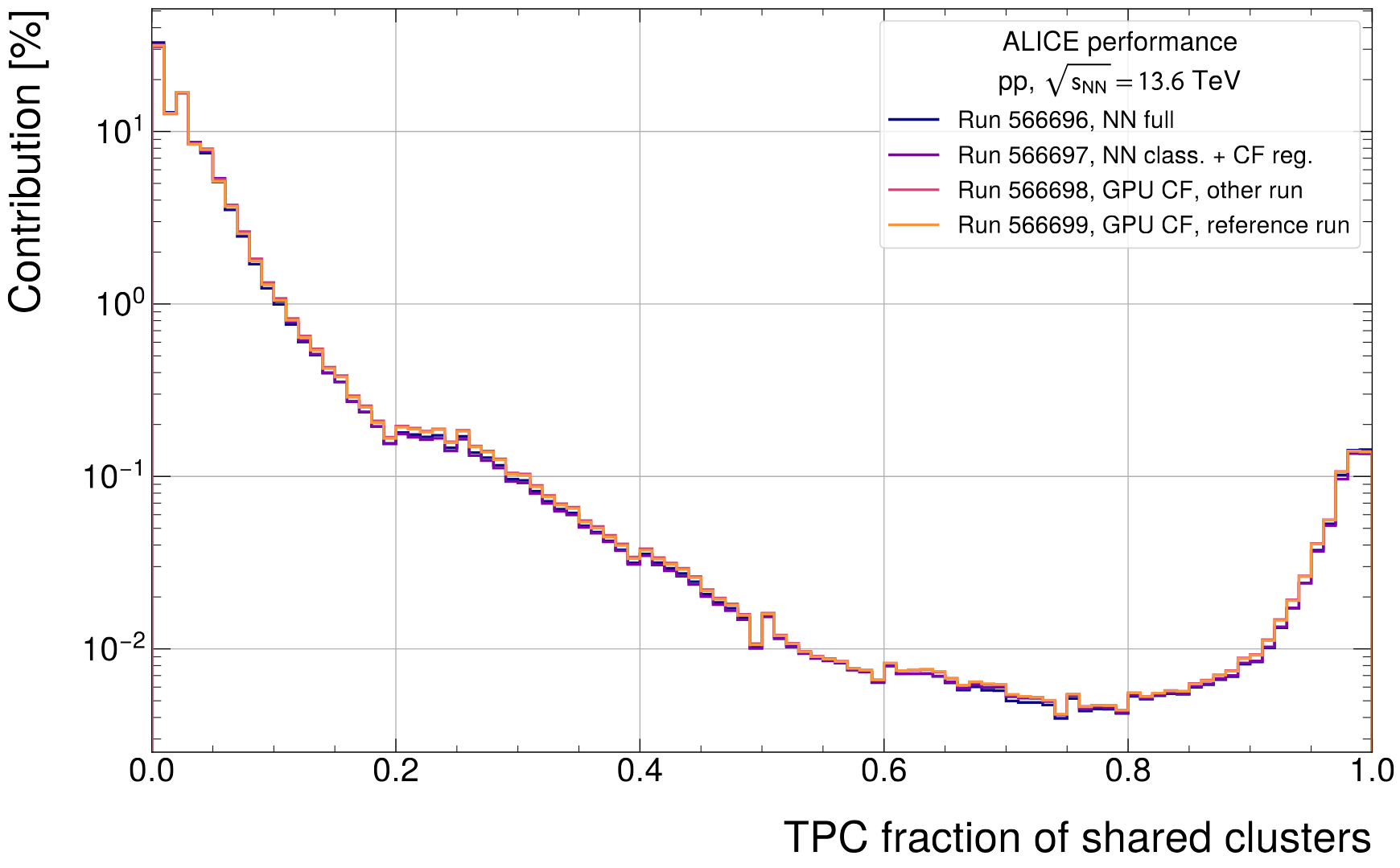
- Small, relative improvement close to bin at 0 will have most dominant effect (by orders of magnitude)
- Expected behavior: Increase peak close to 0 (relative to reference run), decrease across the rest of shared clusters
- To be plotted as a ratio to the reference run by strength of relative contribution to absolute track / cluster count
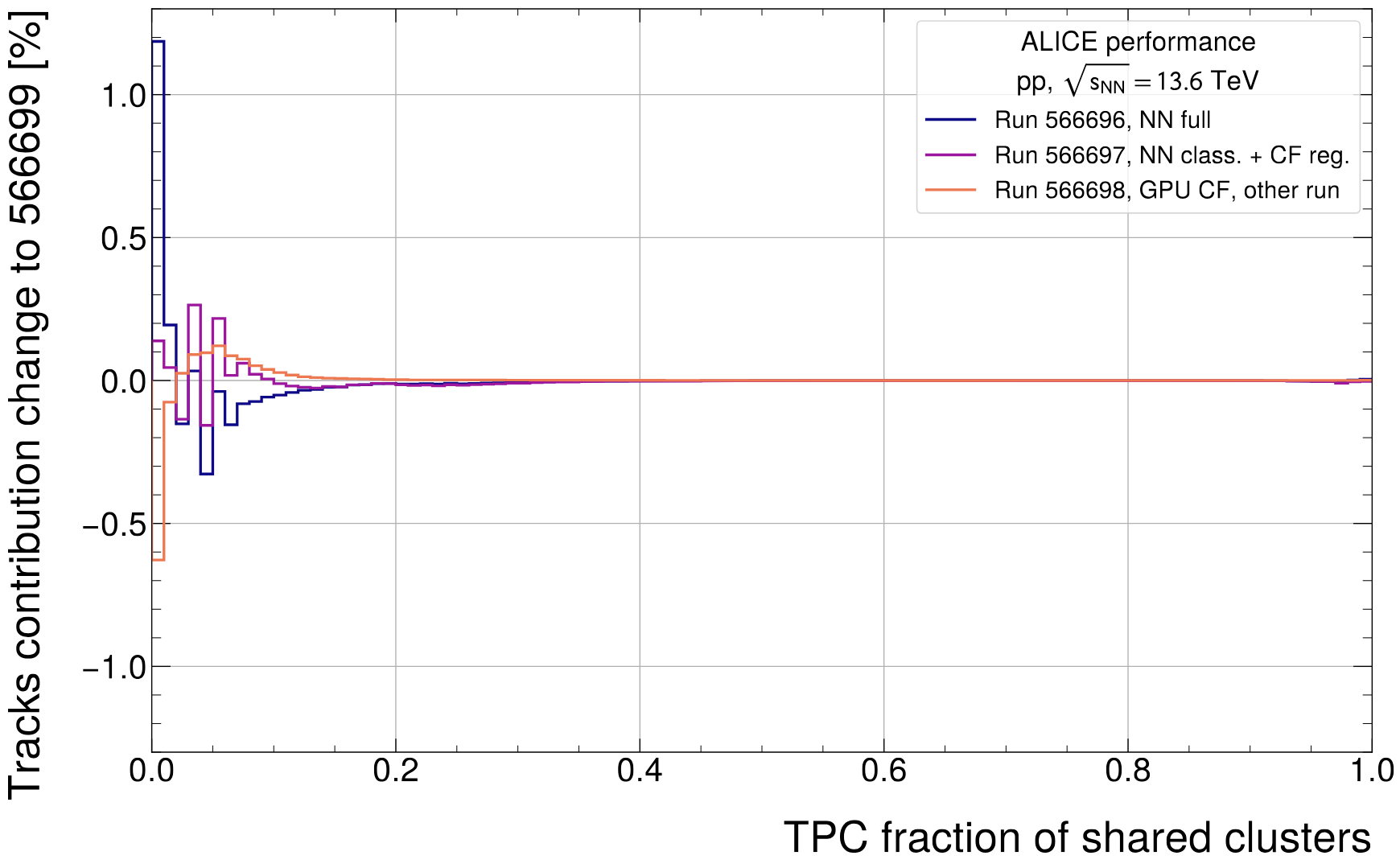
Something at higher level: Reconstruction of D0
Used BDT from Fabrizio Grosa for investigation on two different reconstructions: Default and NN (full) with threshold 0.05
- Wrote an OPTUNA based optimization class that optimises the input variables to a given score metric
- Chosen score metric:
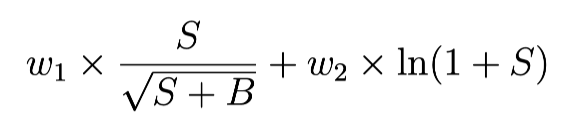
- w1 = 0.2, w2 = 0.8
- signal: gauss, background: pol3 (tried also exp, both work well)
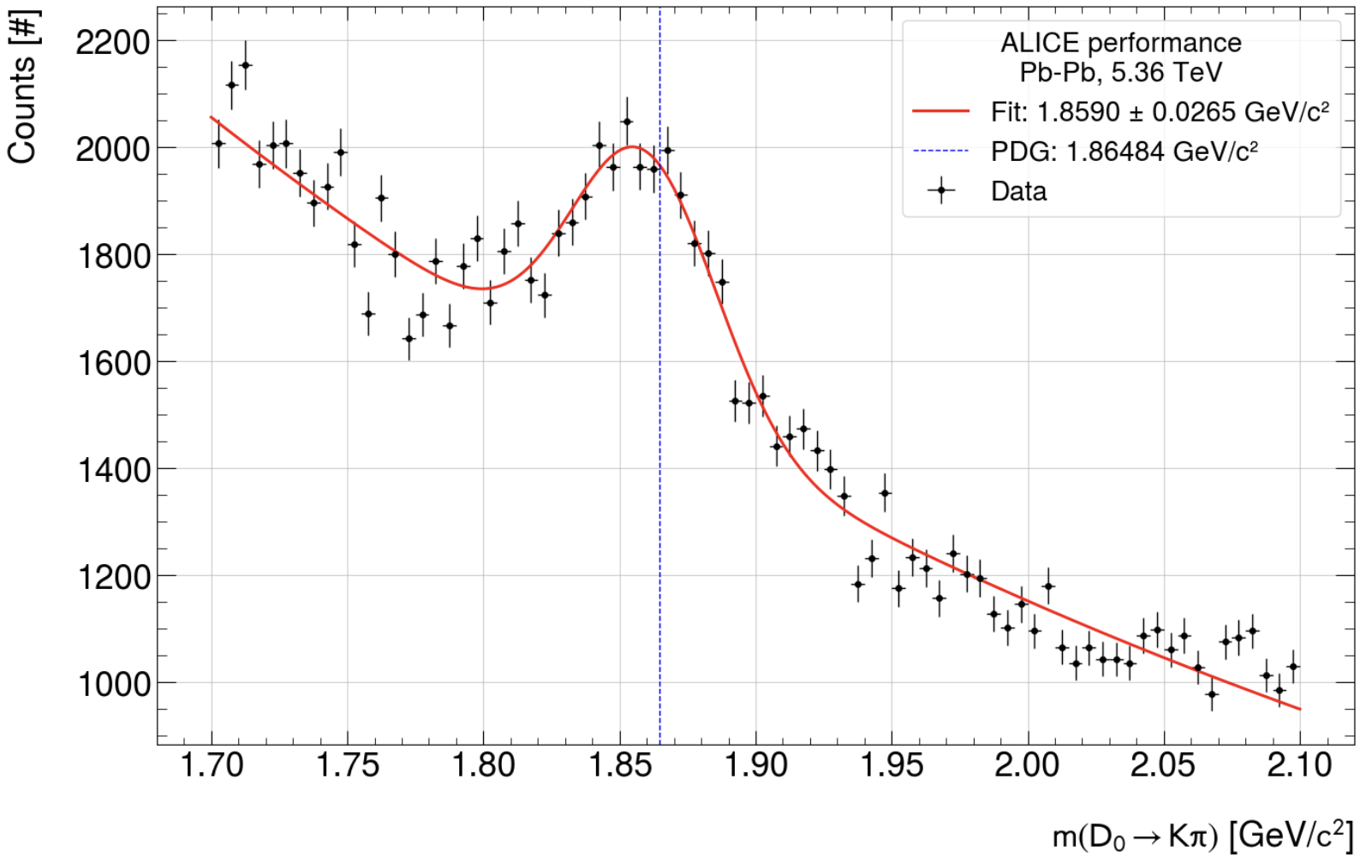
- Result (same cuts applied to both datasets)
-
- First: default reco: 'signal': 32.007845773858556, 'sigma': 0.026497547051550507, 'gauss peak': 4.81904342e+02
-
- Second: NN full, 0.05: 'signal': 26.3774060396624, 'sigma': 0.023521459662659887, 'gauss peak': 4.47381356e+02
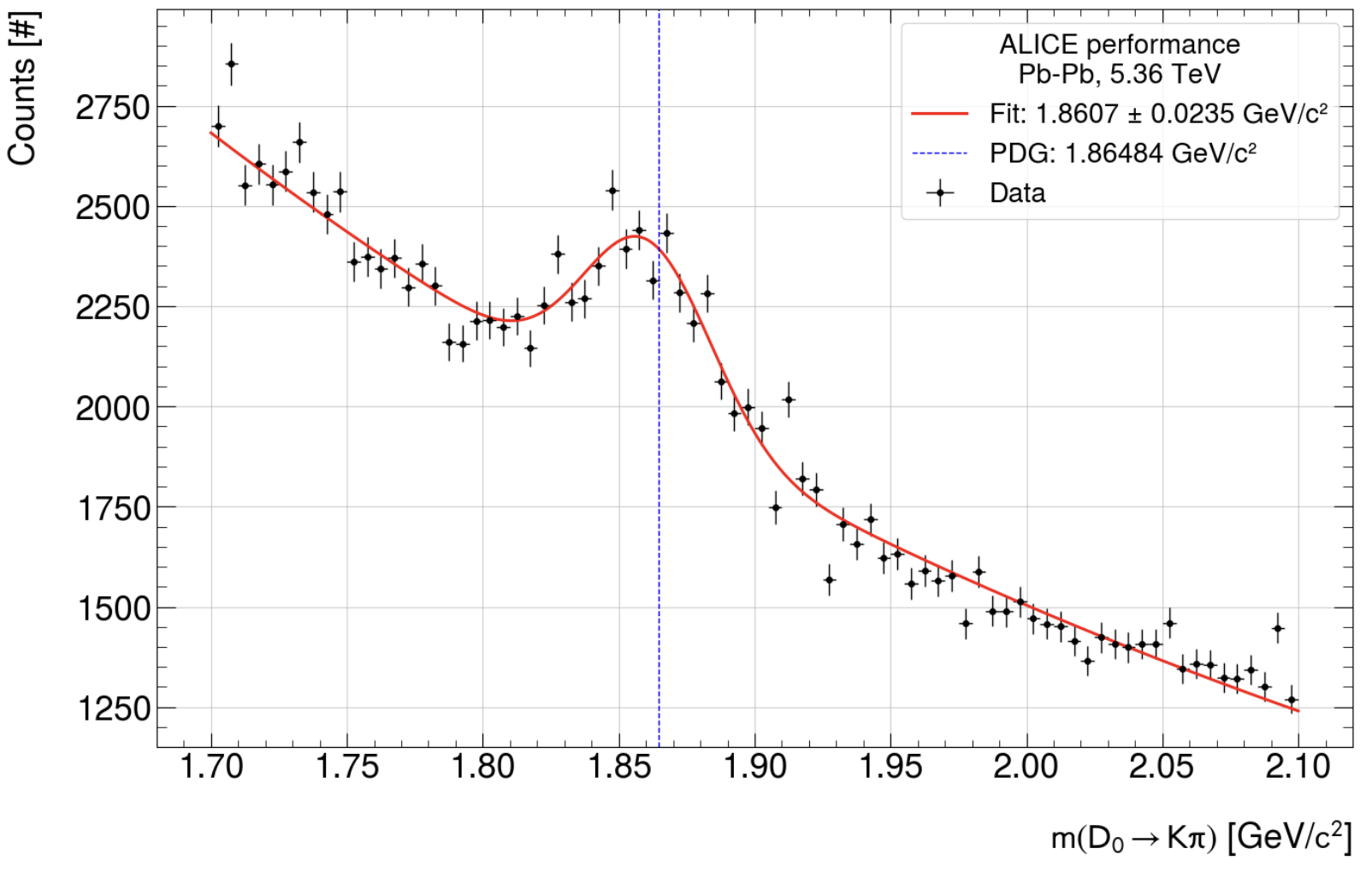
So: Default reco is still "better", but BDT was used from default reco in the same way with the same cuts for both reconstructions.
After talking to Fabrizio Grosa: The excess in background and signal could actually be real... This heavily depends on ITS-TPC matching, DCA and other observables. Not necessarily anything wrong in the reco.
Finally also something cool
3D render of one of the first collisions recorded with the neural network cluster finder in online reco! Full credit to Felix Schlepper

AOB
- CHEP abstract: https://www.overleaf.com/read/vqghvpvzwnks#9b3851
- Timing tests done for MI50 during MD, but MI100 not valid due to serialization issue
- Reran with new tracking on MC, interpretation stays the same