Color code: (critical, news from this week: blue, news from last week: purple, no news: black)
CHEP Abstracts: https://indico.cern.ch/event/1471803/abstracts/ Deadline Dec. 19.
Sync reconstruction
Async reconstruction
- Need to investigate short GPU stall problem.
- Limiting factor for pp workflow is now the TPC time series, which is to slow and creates backpressure (costs ~20% performance on EPNs). Enabled multi-threading as recommended by Matthias - need to check if it works.
- New GPU architecture selection for async in O2DPG looks good, should be merged.
- Test with GPU GRID jobs at NERSC pending.
- Asked DPG to run first test with ITS tracking on GPU on EPNs.
GPU ROCm / compiler topics:
- Issues that disappeared but not yet understood: random server reboot with alma 9.4, miscompilation with ROCm 6.2, GPU getting stuck when DMA engine turned off, MI100 stalling with ROCm 5.5.
- Problem with building ONNXRuntime with MigraphX support.
- Need to find a way to build ONNXRuntime with support for CUDA and for ROCm.
- Try to find a better solution for the problem with __device__ inline functions leaking symbols in the host code.
- Miscompilation / internal compiler error fixed in new clang for ROCm 7.x, SDMA engine synchronization bug still not fixed.
- Serialization bug pending.
- Miscompilation on MI 100 leading to memory error pending.
- New miscompilation on MI 50 with ROCm 7.0 when RTC disabled.
- New miscompilation on MI 50 on ROCm 6.3 and 7.0 when RTC enabled, with latest software. Have a workaround for Pb-Pb data taking, but not compatible to latest tracking developments.
- No update from AMD, but AMD wrote they are reorganizing their support process, and should have a meeting in the next weeks.
TPC / GPU Processing
- WIP: Use alignas() or find a better solution to fix alignment of monte carlo labels: https://its.cern.ch/jira/browse/O2-5314
- Waiting for TPC to fix bogus TPC transformations for good, then we can revert the workaround.
- Waiting for TPC to check PR which uses full cluster errors including average charge and occupancy map errors during seeding.
- Final solution: merging transformation maps on the fly into a single flat object:
- Sergey opened a new PR with the fixes and compatibility layer in, currently fails in the CI. Must be fixed, then Matthias can continue commissioning.
- Need to check the problem with ONNX external memory allocator.
- Next high priority topic: Improvements for cluster sharing and cluster attachment at lower TPC pad rows. PR: https://github.com/AliceO2Group/AliceO2/pull/14542
- New tracking is actually faster in the refit, but slower in the looper following. raw has more loopers than MC --> faster in MC, slower in raw overall. Can disable looper following to gain some speed for 50 kHz.
- TPC laser calib issue fixed, was a bug in tracking developments affecting only triggered data
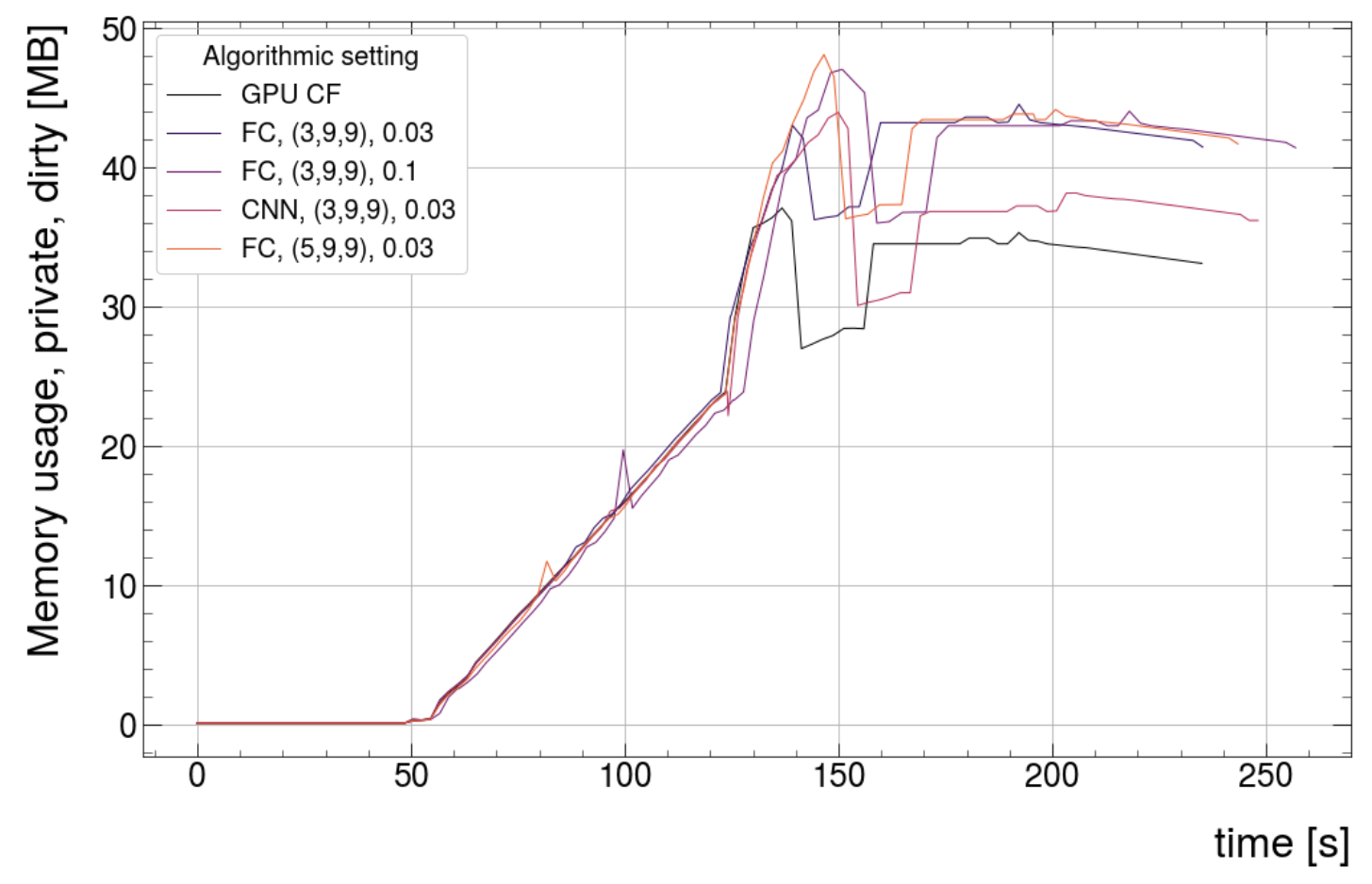
- Large memory usage in pp on the GRID - fixed.
- Gain calib issue was due to new miscompilation.
- Next iteration of tracking improvements in draft PR: https://github.com/AliceO2Group/AliceO2/pull/14651
- Should get Gabriele's new parameters merged for Pb-Pb.
- Merged, we definitely needed that speedup, Gabriele can report next week.
- Investigating deficiencies with TPC cluster removal.
- With the new tracking improvements, we are rejecting more clusters (reducing fakes), and such rejected clusters were not protected from removal. This led to some degradation in the async reco from CTF, since apparently such clusters were needed for the seeding. Fixed in latest O2.
- In sync reco, we were not using the relaxed cuts to find tracks. Thus we found less tracks in async, and some tracks were not protected. That is the main reason we loose tracks in reco from CTF compared to reco from Raw.
- Immediate measure is to use relaxed cuts in sync reco, which will increase processing time by ~20%. Doing some tests with Ernst. Still need to decide what to do finally with cluster rejection.
- Added more settings to O2 to steer cluster rejection, and run it in less aggressive mode.
Other topics:
- Assembled development server yesterday. Unfortunately, got only 32 GB DIMMs, and we have only 4 slots, so we'll have 128 GB not 256. But that should be OK. (We cannot return these modules and replace for 64 GB modules).
- Mass storage disks were ordered as SAS drives, checking if we can switch to SATA, otherwise will add a cheap SAS controller.
- Otherwise, server seems fully working. Felix can take care of installation once he is back after his PhD defense.
- GRID Memory moniroting: If PSS is monitored, GPU memory is shown as host memory, thus our GPU jobs are reported as using so much host memory.
EPN GPU Topics: