Color code: (critical, news during the meeting: green, news from this week: blue, news from last week: purple, no news: black)
High priority RC YETS issues:
- Fix dropping lifetime::timeframe for good: No news
- Still pending: problem with CCDB objects getting lost by DPL leading to "Dropping lifetime::timeframe", saw at least one occation during SW validation.
- Expandable tasks in QC. Everything merged on our side.
- Start / Stop / Start:
- Problems in readout and QC fixed. Now 2 new problems left:
- Some processes are crashing randomly (usually ~2 out of >10k) when restarting. Stack trace hints to FMQ. https://its.cern.ch/jira/browse/O2-4639
- TPC ITS matching QC crashing accessing CCDB objects. Not clear if same problem as above, or a problem in the task itself.
- Stabilize calibration / fix EoS: New scheme: https://its.cern.ch/jira/browse/O2-4308: No news
- Problem with FIT workflow and a single EPN causing backpressure hopefully fixed by improving metric-feedback mechanism.
- Since this week with the fix in, we have problems with workflows getting stuck that have a large number of time frames in flight.
- Though not clear if at all realted to the fix.
- As workaround, limited the max tf in flight variable to be smaller than DPL_PIPELINE_LENGTH.
- Created a JIRA ticket with a summary to follow this up.
- Causes a flood of infologger warnings when calib tasks need long and few EPNs in the run. Working on a heustistic to reduce the warnings from the TF rate limiting.
- Implemented the heuristic and merged it today, to be seen with next SW update if the InfoLogger flood disappears.
- Fix problem with ccdb-populator: no idea yet, no ETA.
- Run 548532 crashed with internal-dpl-ccdb-backend PSS size going to > 60 GB causing OOM.
- Improved Grafana pllots to show USS instead of PSS. It is clearly private memory of the internal-dpl-ccdb-backend that goes OOM. Any progress?
High priority framework topics:
Other framework tickets:
- TOF problem with receiving condition in tof-compressor: https://alice.its.cern.ch/jira/browse/O2-3681
- Grafana metrics: Might want to introduce additional rate metrics that subtract the header overhead to have the pure payload: low priority.
- Backpressure reporting when there is only 1 input channel: no progress: https://alice.its.cern.ch/jira/browse/O2-4237
- Stop entire workflow if one process segfaults / exits unexpectedly. Tested again in January, still not working despite some fixes. https://alice.its.cern.ch/jira/browse/O2-2710
- https://alice.its.cern.ch/jira/browse/O2-1900 : FIX in PR, but has side effects which must also be fixed.
- https://alice.its.cern.ch/jira/browse/O2-2213 : Cannot override debug severity for tpc-tracker
- https://alice.its.cern.ch/jira/browse/O2-2209 : Improve DebugGUI information
- https://alice.its.cern.ch/jira/browse/O2-2140 : Better error message (or a message at all) when input missing
- https://alice.its.cern.ch/jira/browse/O2-2361 : Problem with 2 devices of the same name
- https://alice.its.cern.ch/jira/browse/O2-2300 : Usage of valgrind in external terminal: The testcase is currently causing a segfault, which is an unrelated problem and must be fixed first. Reproduced and investigated by Giulio.
- Found a reproducible crash (while fixing the memory leak) in the TOF compressed-decoder at workflow termination, if the wrong topology is running. Not critical, since it is only at the termination, and the fix of the topology avoids it in any case. But we should still understand and fix the crash itself. A reproducer is available.
- Support in DPL GUI to send individual START and STOP commands.
- Problem I mentioned last time with non-critical QC tasks and DPL CCDB fetcher is real. Will need some extra work to solve it. Otherwise non-critical QC tasks will stall the DPL chain when they fail.
- DPL sending SHM metrics for all devices, not only input proxy: https://alice.its.cern.ch/jira/browse/O2-4234
- Some improvements to ease debugging: https://alice.its.cern.ch/jira/browse/O2-4196 https://alice.its.cern.ch/jira/browse/O2-4195 https://alice.its.cern.ch/jira/browse/O2-4166
- We desperately need to do a cleanup session and go through all these pending DPL tickets with a higher priority, and finally try to clean up the backlog.
Global calibration topics:
- TPC IDC and SAC workflow issues to be reevaluated with new O2 at restart of data taking. Cannot reproduce the problems any more.
Sync processing
- Proposal to parse InfoLogger message and alert automatically: https://alice.its.cern.ch/jira/browse/R3C-992
- Demoted some InfoLogger messages for missing data from CRORC detectors from alarm to warning, since in low-IR run the data can be missing. I proposed instead readout / DD should send dummy data, so that the reconstruction knows that there is actually no data, but this seems impossible, so we just disable the error and do not care any more.
Async reconstruction
- Remaining oscilation problem: GPUs get sometimes stalled for a long time up to 2 minutes.
- Checking 2 things: does the situation get better without GPU monitoring? --> Inconclusive
- We can use increased GPU processes priority as a mitigation, but doesn't fully fix the issue.
- ḾI100 GPU stuck problem will only be addressed after AMD has fixed the operation with the latest official ROCm stack.
EPN major topics:
- Fast movement of nodes between async / online without EPN expert intervention.
- 2 goals I would like to set for the final solution:
- It should not be needed to stop the SLURM schedulers when moving nodes, there should be no limitation for ongoing runs at P2 and ongoing async jobs.
- We must not lose which nodes are marked as bad while moving.
- Interface to change SHM memory sizes when no run is ongoing. Otherwise we cannot tune the workflow for both Pb-Pb and pp: https://alice.its.cern.ch/jira/browse/EPN-250
- Lubos to provide interface to querry current EPN SHM settings - ETA July 2023, Status?
- Improve DataDistribution file replay performance, currently cannot do faster than 0.8 Hz, cannot test MI100 EPN in Pb-Pb at nominal rate, and cannot test pp workflow for 100 EPNs in FST since DD injects TFs too slowly. https://alice.its.cern.ch/jira/browse/EPN-244 NO ETA
- DataDistribution distributes data round-robin in absense of backpressure, but it would be better to do it based on buffer utilization, and give more data to MI100 nodes. Now, we are driving the MI50 nodes at 100% capacity with backpressure, and then only backpressured TFs go on MI100 nodes. This increases the memory pressure on the MI50 nodes, which is anyway a critical point. https://alice.its.cern.ch/jira/browse/EPN-397
- TfBuilders should stop in ERROR when they lose connection.
- EPN bumped some test nodes to ALMA 8.9
Other EPN topics:
Raw decoding checks:
- Add additional check on DPL level, to make sure firstOrbit received from all detectors is identical, when creating the TimeFrame first orbit.
Full system test issues:
Topology generation:
- Should test to deploy topology with DPL driver, to have the remote GUI available.
- DPL driver needs to implement FMQ state machine. Postponed until YETS issues solved.
QC / Monitoring / InfoLogger updates:
- TPC has opened first PR for monitoring of cluster rejection in QC. Trending for TPC CTFs is work in progress. Ole will join from our side, and plan is to extend this to all detectors, and to include also trending for raw data sizes.
AliECS related topics:
- Extra env var field still not multi-line by default.
GPU ROCm / compiler topics:
- Found new HIP internal compiler error when compiling without optimization: -O0 make the compilation fail with unsupported LLVM intrinsic. Reported to AMD.
- Found a new miscompilation with -ffast-math enabled in looper folllowing, for now disabled -ffast-math.
- Must create new minimal reproducer for compile error when we enable LOG(...) functionality in the HIP code. Check whether this is a bug in our code or in ROCm. Lubos will work on this.
- Found another compiler problem with template treatment found by Ruben. Have a workaround for now. Need to create a minimal reproducer and file a bug report.
- Debugging the calibration, debug output triggered another internal compiler error in HIP compiler. No problem for now since it happened only with temporary debug code. But should still report it to AMD to fix it.
- Checked AMD ROCm 6.0.2 on both MI50 and MI100. Not stable on both of them, was crashing after a while, ~30 minutes on MI50 nodes. Also saw 3%-4% performance degradation on MI50 compared to ROCm 5.5/5.6. Reported this back to AMD.
- Old ROCm seems stable with O2/dev, so seems to be indeed a regression in ROCm 6.0.2.
- On top of that, did a bit of debugging, and the majority of the crashes on the MI100 are due to the known synchronization bug we had on the MI100 beginning of last year, which suddenly disappeared in a new ROCm version. Apparently it was never really fixed, just the race condition didn't occur, and now it is back.
- On top of that, also MI50 crashes, which is not affected by this bug, so there are at least 2 independent bugs in ROCm 6.0 that make our code fail.
TPC GPU Processing
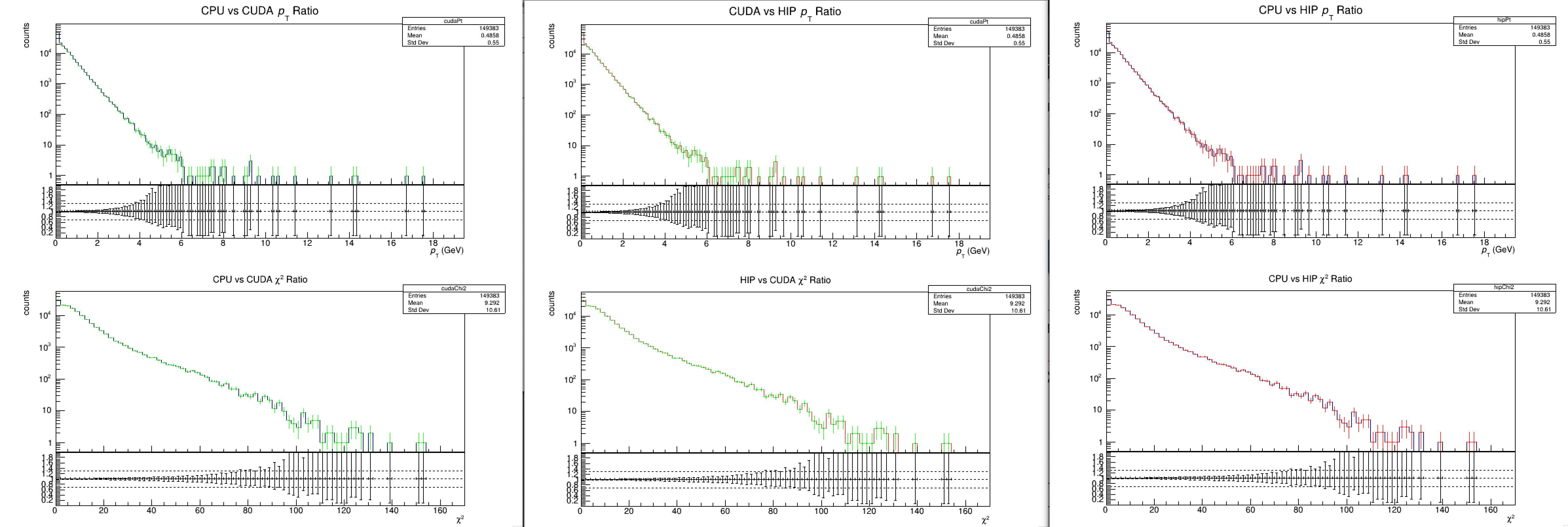
- Bug in TPC QC with MC embedding, TPC QC does not respect sourceID of MC labels, so confuses tracks of signal and of background events.
- New problem with bogus values in TPC fast transformation map still pending. Sergey is investigating, but waiting for input from Alex.
- Status of cluster error parameterizations
- Everything implemented for the TPC fit - but not yet for track seeding, and for the global refit!
- Refit lacks access to occupancy map (to be shipped with DPL), seeding lacks access to charge information.
- Marian requested to have additional debug streamers during the refit.
- Need to port all of this to stable-async branch, but again the latest changes do not apply cleanly since stable-async is too old.
- TPC processing performance regression: Currently we need 43% more time than in last year's Pb-Pb, i.e. we are too slow for Pb-Pb this year. This must be fixed!
- Bisected regressions down to the commits:
- 18.9.2023 IFC Errors + related 2.48%
- This comes from multiple commits adding features to the error estimation step by step, none of them causing an increase above 0.5% on its own. This slowdown is not recoverable.
- 24.10.2023: Revert "MatLUT: faster phi-sector determination; reduction of divisions (#12030)" 3.80%
- This is a weird behavior in the AMD compiler, triggered by the combination of the revert of this commit, another commit that was added in the meantime, and compile flags. I should be able to find a workaround for this.
- 30.1.2024: Dead channel map + V-Shape distortion correction 15.77%
- Dead channel map usage makes 0.8%, which is not recoverable.
- the remaining 15% come from the V-Shape correction changes in the TPCFastTransform class.
- 4.3.2024: fix inverse for M-Shape distortions 6.26%
- Again, changes to the TPCFastTransform class cause the regression.
- 5.3.2024: 8.90%
- 0.34% is from using qMax in the error estimation
- 0.1% from improvements to dEdx computation
- 1% from building the average of 1/sqrt(qmax)
- The rest comes from fixes in the tracking code, where cluster to track association got broken, and cuts were applied incorrectly. These 7.5% will not be recoverable.
- Then, found that some compile flags (fast-math, O2) are overridden by the O2 CMake, and not passed to the GPU compiler, which caused a performance regression compared to the standalone benchmark. This is fixed, but still ~2% performance difference. Checking where this comes from.
- WIth standalone benchmark and optimized GPU compiler flags, checked performance of TPCFastTransform:
- O2/dev:
- Total time: 4.695s, Track Fit Time 1.147s, Seeding Time 1.241s
- O2/dev with commit from 4.3. reverted:
- Total time 4.351s, Track Fit Time 1.089, Seeding Time 1.008s
- For reference: before introduction of the V-Shape map:
- Total time 3.8421s (didn't measure individual times)
- O2/dev with scaling factors hard-coded to 0 (essentially using one single transformation map without any scaling):
- Total time 3.093 Track Fit Time 0.682s Seeding Time 0.429s
- In summary, having the 3 maps in the code (even if the scaling factor is 0 and the V-Shape map is not used) compared to using one single map, increases the total TPC reconstruction time by > 50%, the track fit time by 100% and the seeding time by 200% on the GPU. As is, the map access on the GPU is extremely inefficient.
- Proposed 3 ideas to speed up the map access:
- We merge the maps on-the-fly to one combined map, and query only one map.
- We could add plenty of #ifdef in the code, to make sure that for online purposes all the code for the non-static map is not seen.
- We could try to optimize the code to make it easier for the compiler.
General GPU Processing
- Started work to make O2 propagator easily usable in ITS tracking, which is not part of the GPU reconstruction library:
- All GPU framework / common code changes needed for deterministic ITS tracking are merged.
- Used Giulio's workaround to update the CMAKE flags for lower-case build types.
- All CUDA code for the external propagator usage have been ported to HIP, confirmed to work by Matteo.-
- Porting CUDA features to HIP:
- Changes CUDA and HIP CMake files to be more similar, to be able to port new feature in a simpler way.
- Ported the per-kernel template file generation to HIP, fully working now.
- Problem is that the actual per-kernel compilation cannot work with the CMake HIP language feature, as that lacks some required settings. For now, will have to resort to calling hipcc directly on the kernel template files.
- Started to port RTC compilation to HIP:
- Host code to invoke hipcc for RTC implemented and tested.
- Identified some bugs that were introduced meanwhile, which broke RTC compilation in general, also for CUDA. Fixed.
- Started implementing RTC tests, to be run as part of the FullCI.
- RTC for HIP currently does not work due to ITS code including hip_runtime.h in headers, which is not allowed in our RTC code. Need to change that.
- Ruben reported a crash on his NVIDIA 4090 running TPC tracking. But cannot reproduce it and neither can I.
- Should observe if it happens again.
- N.B. On my laptop with mobile 4090, running TPC tracking sometimes kills the X server - could indicate a problem with NVIDIA 4000 series and our code. Not clear if bug on our or NVIDIA side.
- General improvements to the GPU framework wrt to kernel calls. Function call and argument passing overhead reduced by reducing rvalue-ref / const ref / tuples. Also code cleaned up. Should not change much in the end, but was on the agenda for a while...