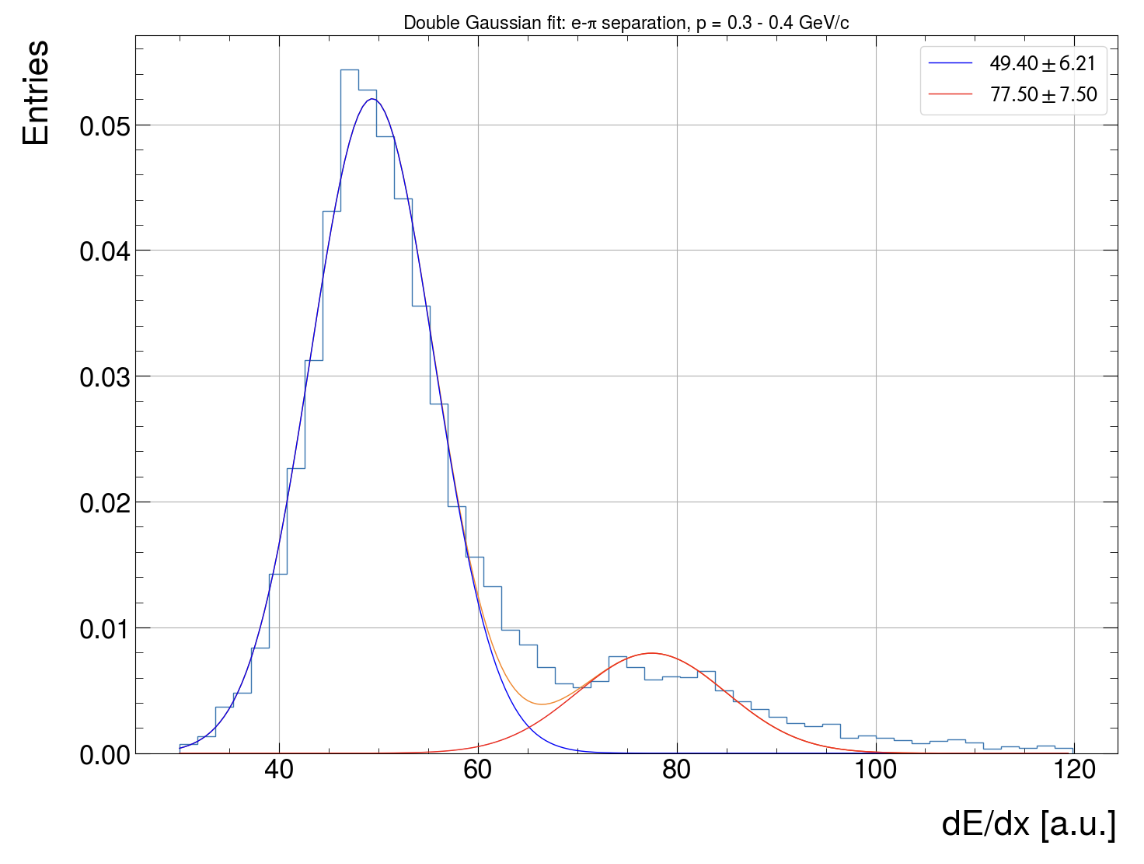
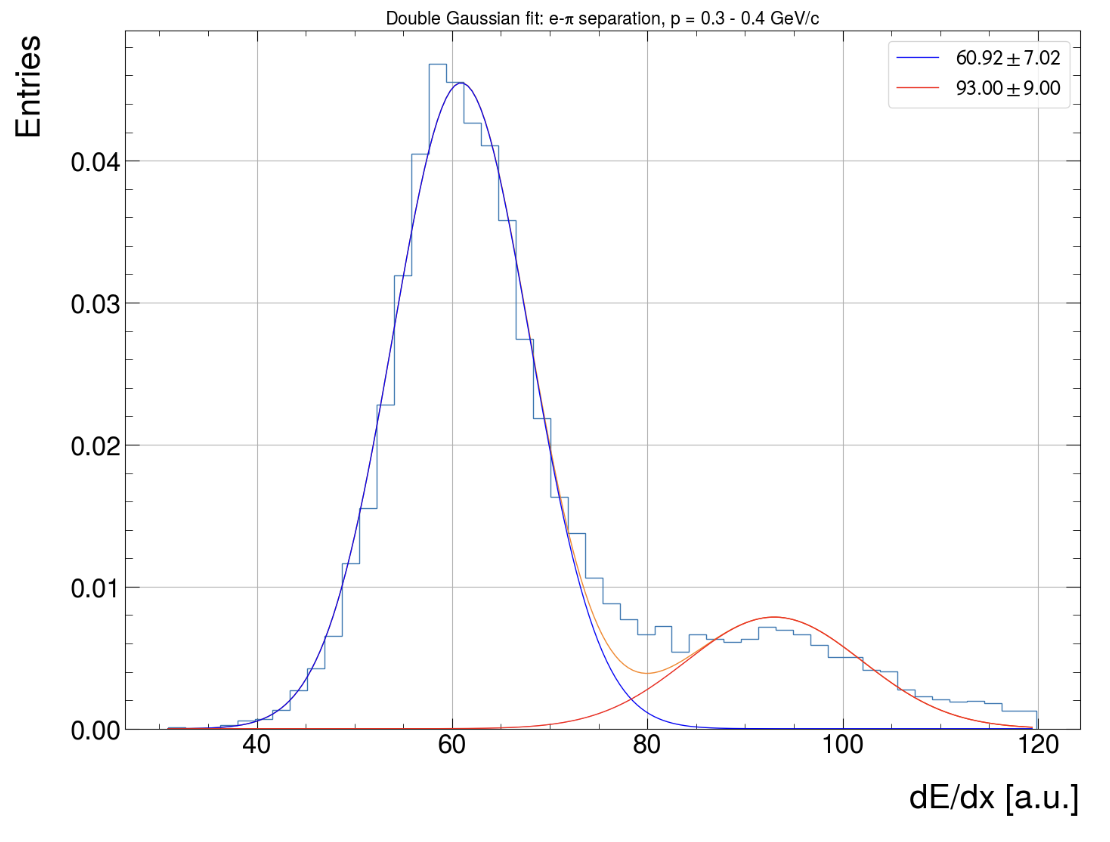
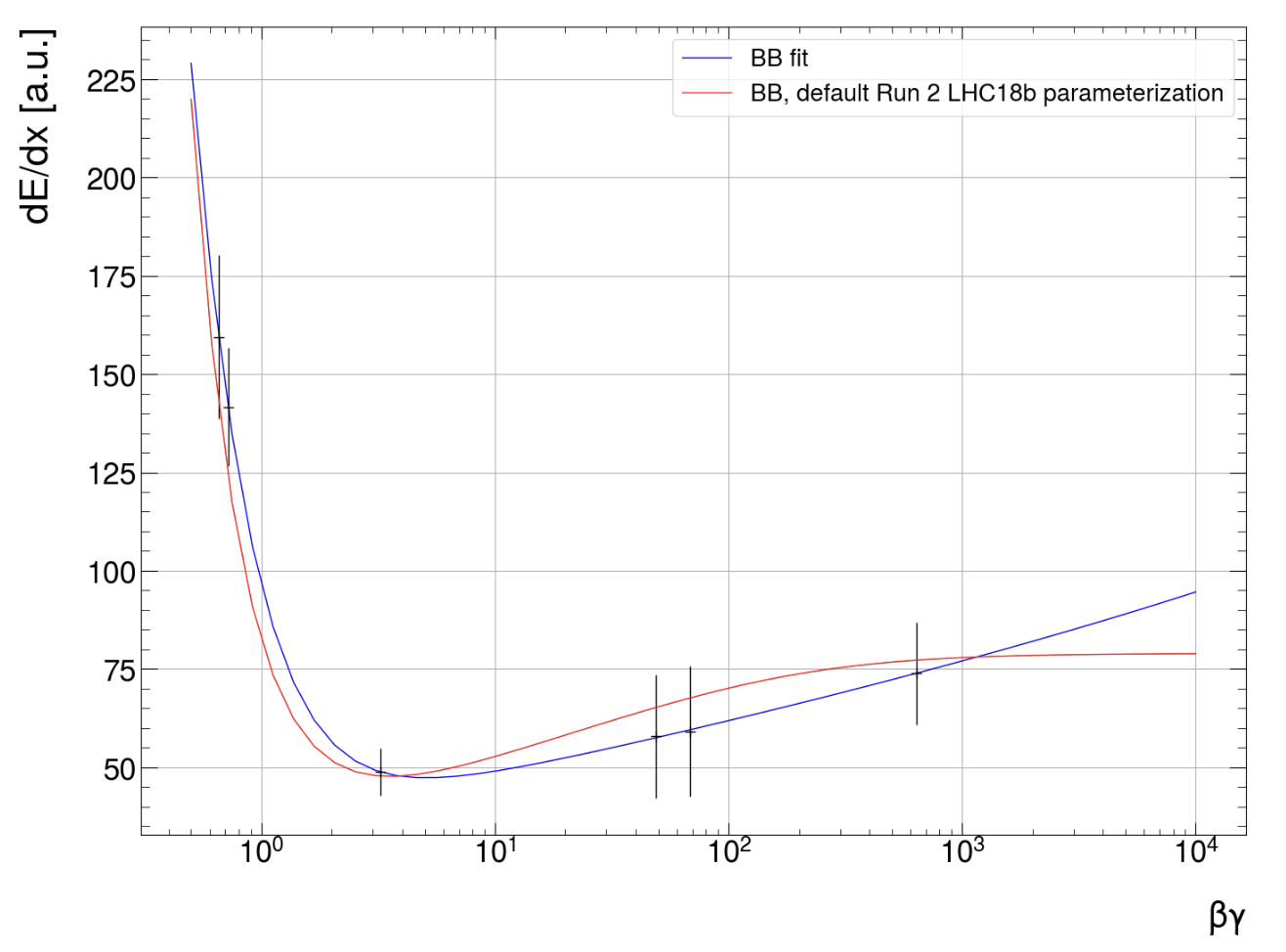
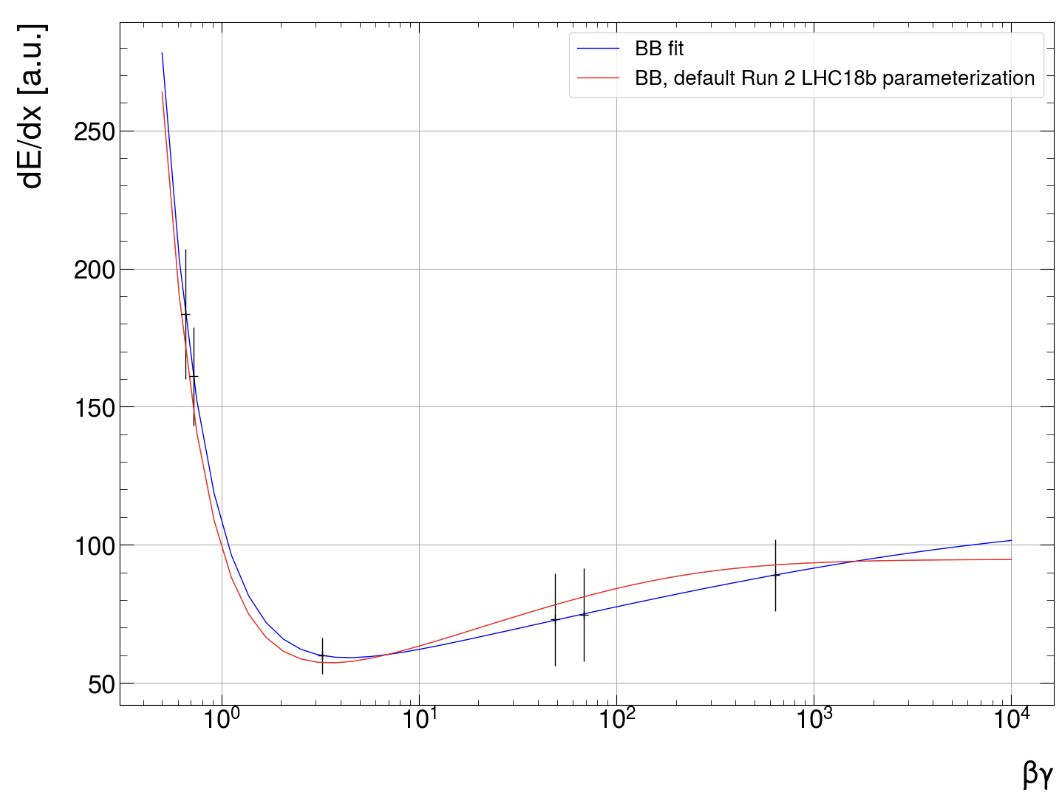
Global Parameter Optimisation
Input dataset simulation
Simulated several timeframes:
- pp: 100kHz, 200kHz, 500kHz, 1MHz, 2MHz
- PbPb: 10kHz, 15kHz, 20kHz, 27kHz, 35kHz, 42kHz, 47kHz, 50kHz
Every timeframe simulated twice, one for 32 orbits timeframe and one for 128 orbits timeframe
For the moment just one simulation per configuration (beam type - interaction rate - timeframe length)
GPU Parameters study
Focusing on grid and block size. Analysed the GPU workflow of the sync/async TPC processing. Image below is the workflow of two HIP streams of the sync TPC processing:
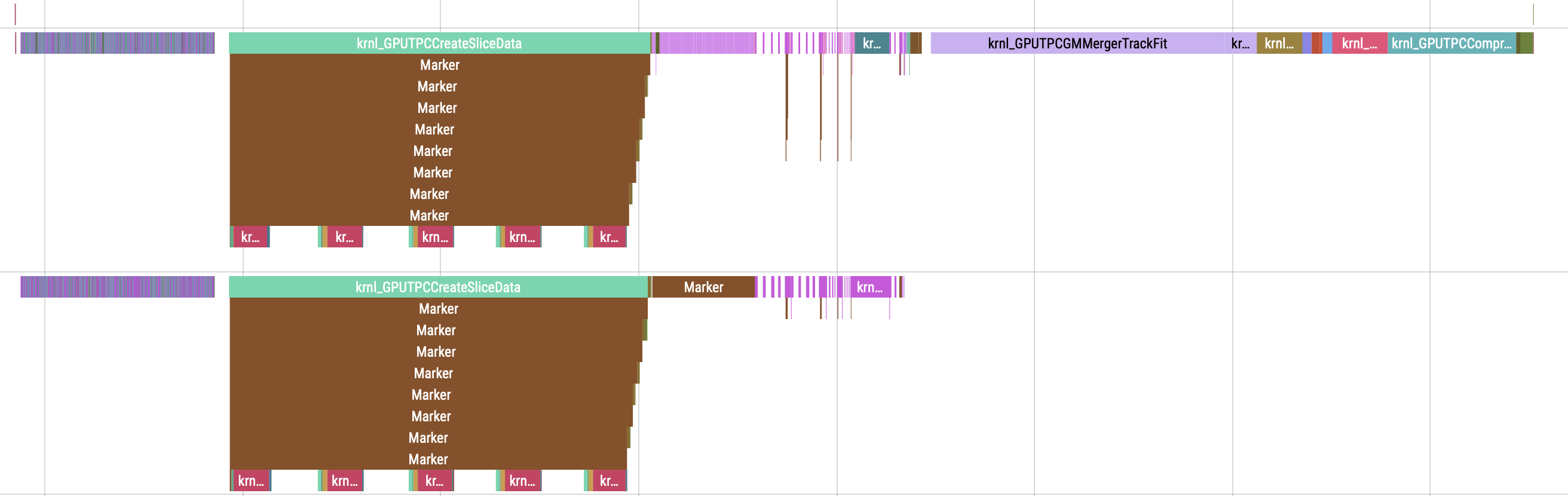
By looking at the tracefile:
- Clusterizer chain:
- small concurrent kernels
- overlap during execution
- overall taking considerable time
- --> dependent parameters, global optimisation
- SliceTracker chain:
- Merger chain:
-
MergeBorders_step2: lots of small concurrent kernels, concurrent to a limited set of other one stream kernels --> dependent parameters, global optimisation (within set)
-
SliceRefit: lots of small one stream kernels --> independent parameters, local optimisation
- MergerTrackFit: one stream long kernel --> independent parameters, local optimisation (maybe limited since values dependent also on number of tracks)
-
MergerFollowLoopers: one stream medium kernel --> independent parameters, local optimisation
- Compression/Decompression chain:
- One stream kernels --> independent parameters, local optimisation
- Multiple stream kernels, not overlapping --> independent parameters, local optimisation
Optimisation strategy
- For the moment just a "Manual Trial-and-Error" using observations from the output
- Started from MergerTrackFit, why:
- Long kernel
- One stream
- Not concurrent to any other kernels
- Caveat: grid size dependent on number of tracks
- Changing values in GPUDefGPUParameters.h takes a loooong time to compile, even with standalone benchmark
- Currently forcing custom krnlExec object in kernel calls, e.g.:
runKernel<KernelClass, KernelClass::step>({{n_blocks,n_threads,stream}});
- Not handy, but way faster
- Created script that automatically fetches grid and block size for all the kernels, useful for runtime grid/block numbers like GetGrid(Merger.NOutputTracks(), 0, deviceType)
Possible bug spotted
HIP_AMDGPUTARGET set to "default" in GPU/GPUTracking/Standalone/cmake/config.cmake translates in HIP_AMDGPUTARGET=gfx906;gfx908 and forces to use MI50 params
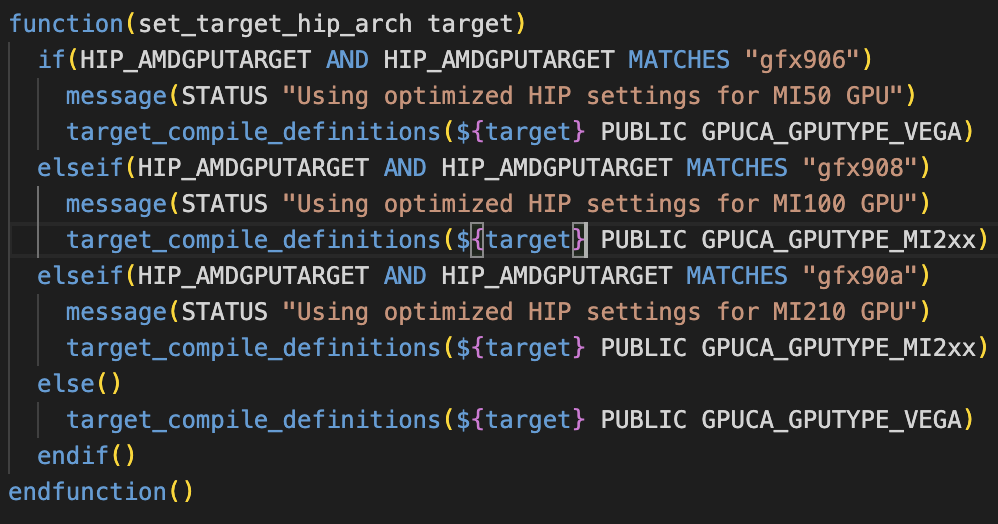
Basically here HIP_AMDGPUTARGET=gfx906;gfx908 enters the first if clause for MI50 even if I am compiling for MI100. Commented set(HIP_AMDGPUTARGET "default") on the config.cmake of the standalone benchmark and forced usage of MI100 parameters via
cmake -DCMAKE_INSTALL_PREFIX=../ -DHIP_AMDGPUTARGET="gfx908" ~/alice/O2/GPU/GPUTracking/Standalone/
Did not investigate further on this.