Choose timezone
Your profile timezone:
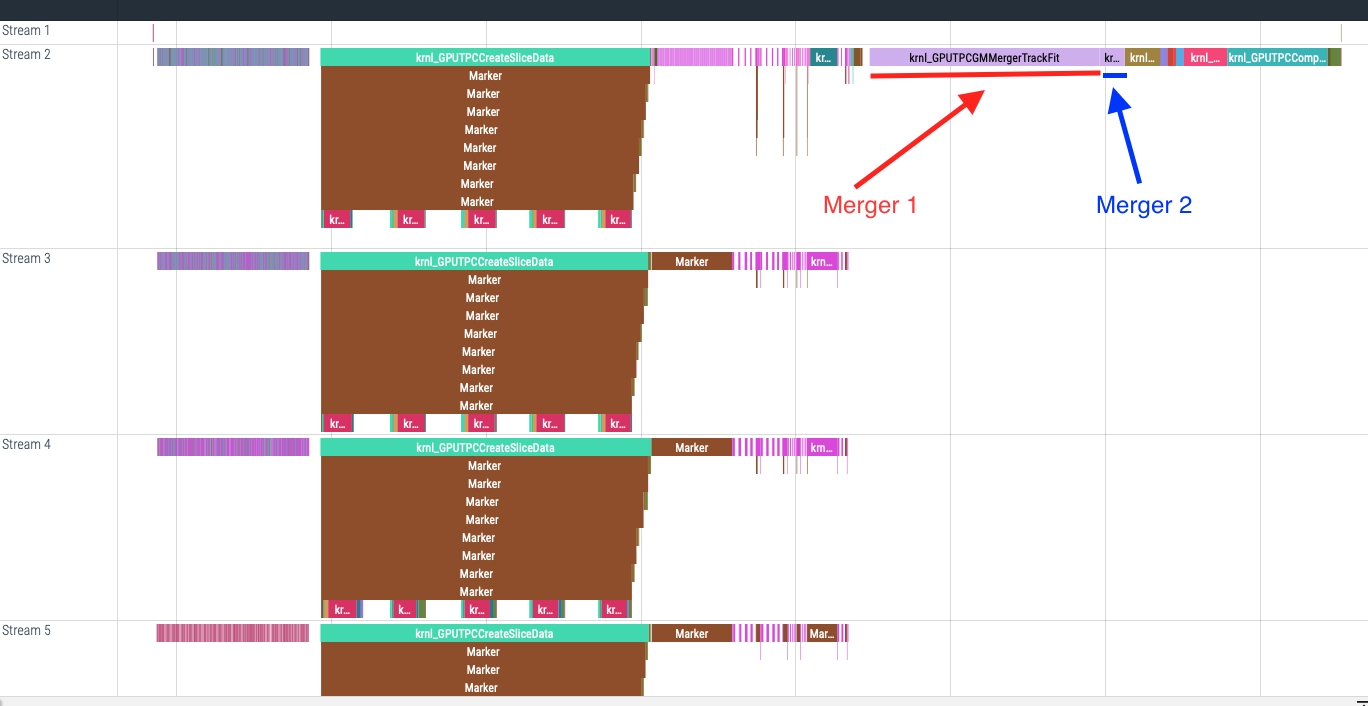
Tried manual tuning of GMMergerTrackFit. This kernel is called twice:
block size: 128grid size s.t. grid size*block size >= #tracksblock size: 128grid size: 120
The two mergers are located here in the GPUChain (sync chain in the image below):
Used same configuration for both kernels (instead of two separate configurations). Kept 128 threads per block, increased block size: 120 * {1,2,3,4,5,6,7}
Tested on MI100.
Keep in mind: in the following plots "Normal" for Merger 1 means grid size s.t. grid size*block size >= #tracks. In practice:
grid size = 492 for pp 100kHzgrid size = 10907 for pp 2MHzgrid size = 1795 for PbPb 5kHzgrid size = 19709 for PbPb 50kHz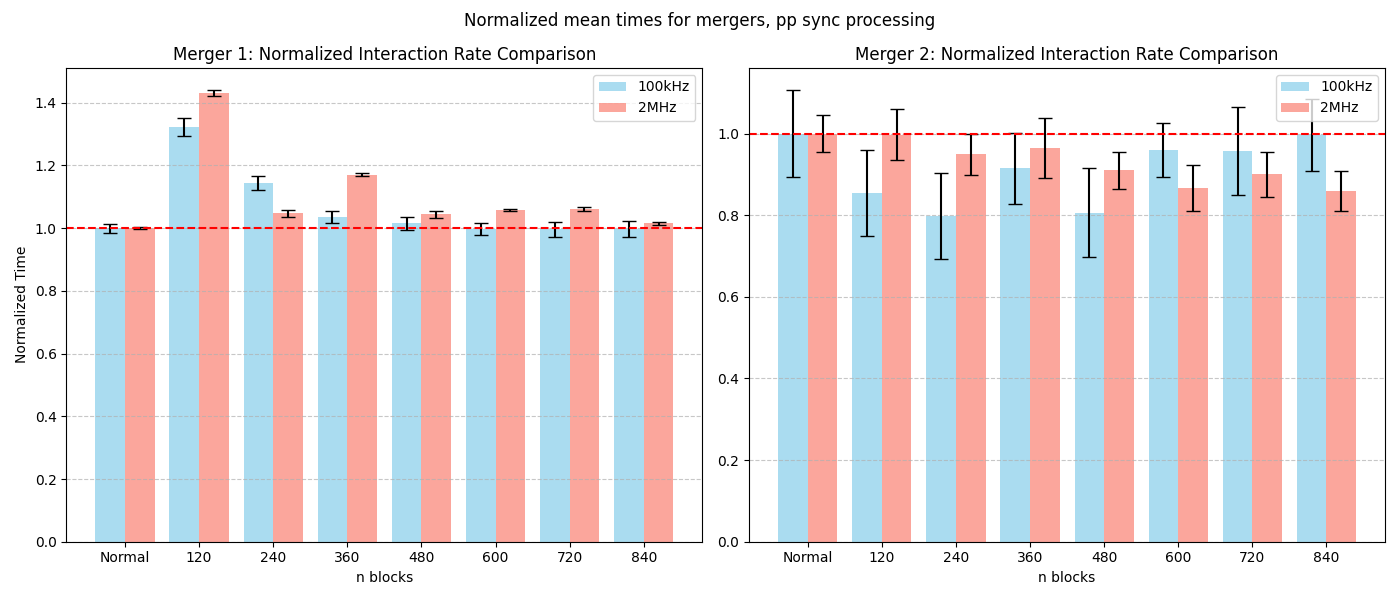

More or less same result as sync for async merger 1 and 2


Same observations for the asynchronous reco as the sync
Attempted a grid search approach on MI100. The parameter search span is defined as block_size = {32, 64, 128} and grid_size = {120, 240, 360, 480, 600, 840}. Block size is a multiple of warp size (64). I put also 32 experimentally, to see what happens with a non-optimal block size. Grid size is a multiple of the number of Compute Units of the MI100 (120 CUs).
Thus the parameter search space is {32, 64, 128} x {120, 240, 360, 480, 600, 840}.
Heatmaps are plotted. Every mean execution time is normalised to the mean execution time with the current standard parameters. Hence:
cell < 1 (red cell) better configuration than current confcell = 1 (white cell) equal configuration than current confcell > 1 (blue cell) worse configuration than current conf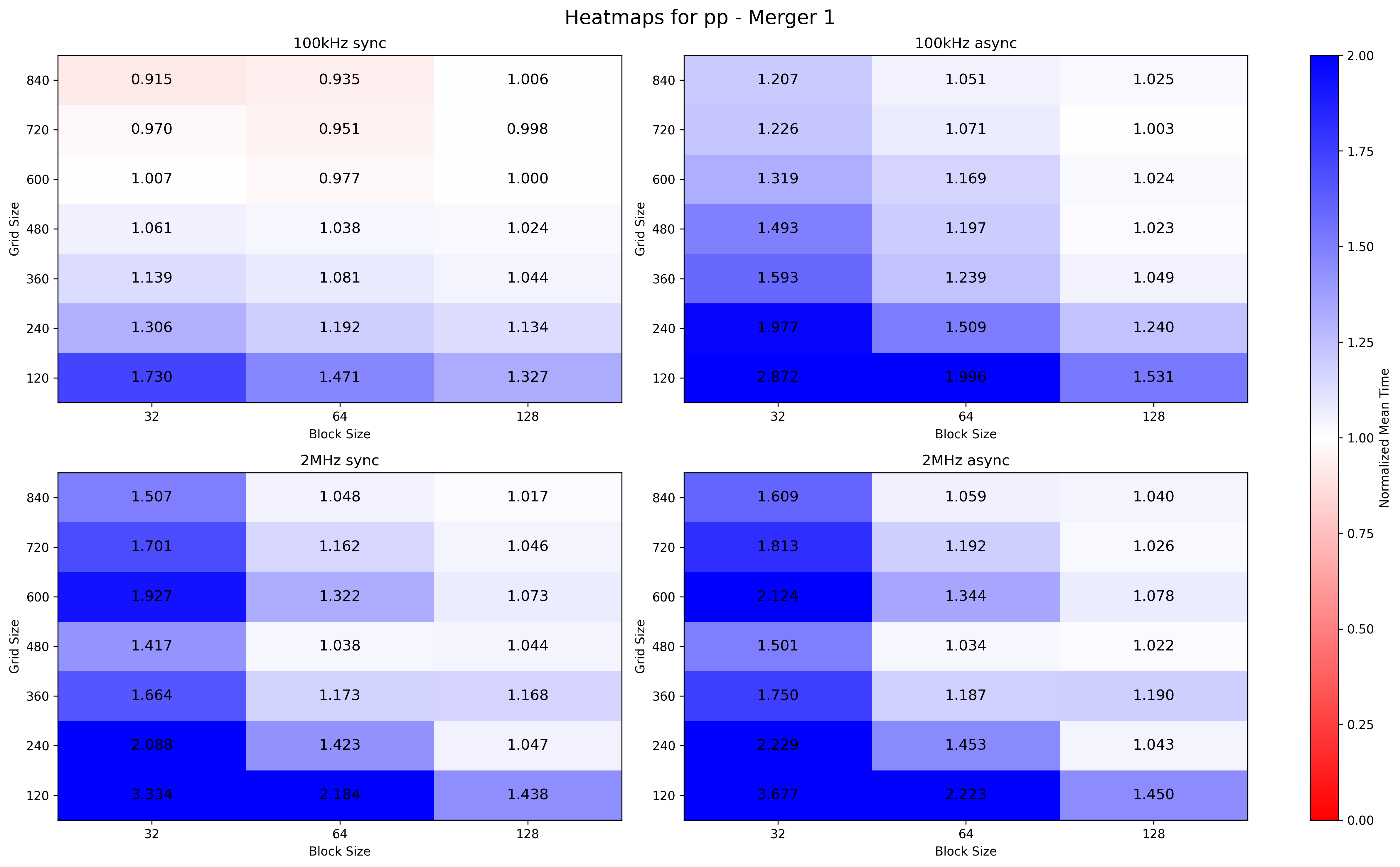
For merger 1, both for low and high IRs and for sync and async, same performance are reached with the {128,840}configuration, instead of the dynamic configuration which results in {128,492} for 100kHz and {128, 10907} for 2MHz (based on #tracks).
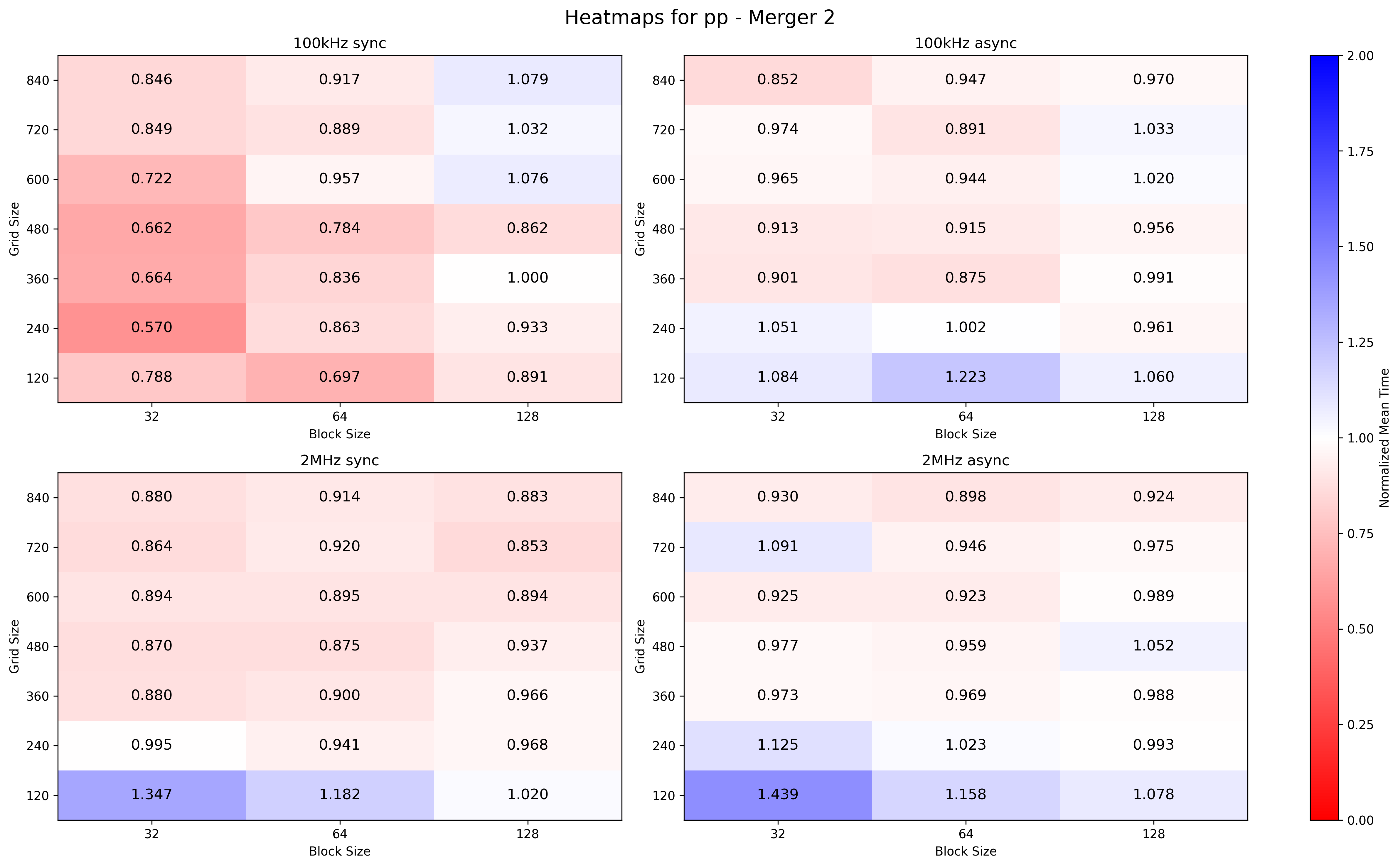
For merger 2, low IR seems to prefer smaller configurations, while for high IR bigger configurations works better. In any case there is room for improvement.
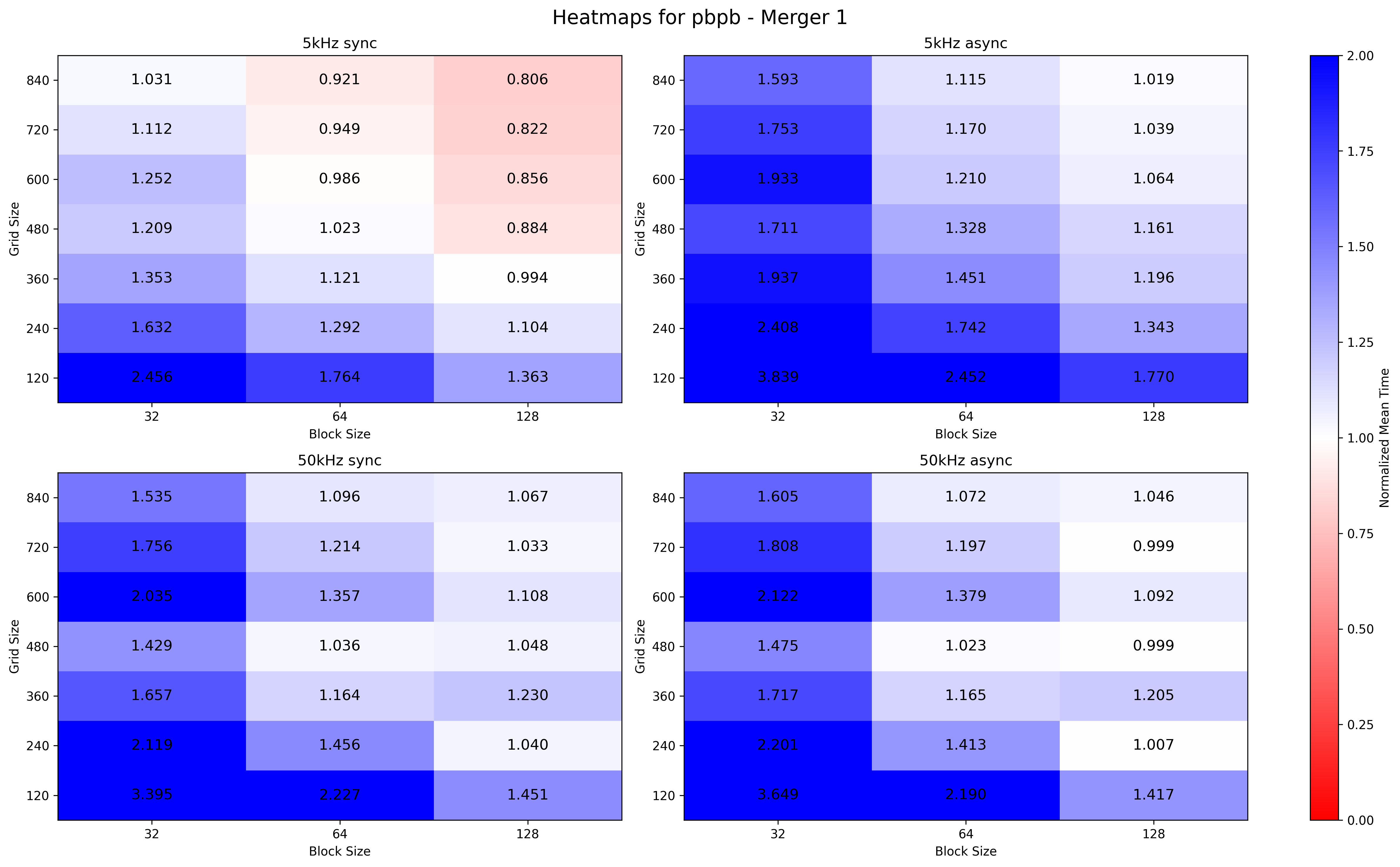
For Merger 1, configuration {128,840} runs faster for low IR rather than {128,1795}, while for high IR the performance is equal ( w.r.t {128,19709}).

Merger 2 can be leveraged better with several configurations.
Based on these observations:
grid size