Choose timezone
Your profile timezone:
Share experiences with StackHPC and SKA folk on various topics.
Notes of discussions being built up here.
CERN - SKA/Stack HPC
Meeting: https://indico.cern.ch/event/739089/
Notes: https://docs.google.com/document/d/19K0kPoRwwCYnYTo-UM3fUgoy08R2O12h9hzF05T0P9E/edit copied here
Attendees
Jose Castro Leon
Spyros Trigazis
John Garbutt
Miles Deegan
Stig Telfer
Mark Goddard - mark@stackhpc.com
Belmiro Moreira - belmiro.moreira@cern.ch
Arne Wiebalck
Tim Bell (tim.bell@cern.ch)
Jan.van.Eldik@cern.ch
Konstantinos Samaras-Tsakiris
Daniel Abad
Jeremy Coles
Pablo Llopis Sanmillan (pablo.llopis@cern.ch) - CERN HPC
Carolina Lindqvist (carolina.lindqvist@cern.ch ) - CERN HPC
Overview of the status of the StackHPC prototype configuration to support a platform for scientists to try different approaches.
Spark running on Sahara, some modifications being done for Infiniband, to access the HDFS store. It’s working but Spark has significant memory usage so this may not be the final solution taken. CERN is running Spark on K8S using a K8S operator.
Usng SoftIron for the Ceph persistent storage.
Using Ansible to orchestrate Heat and Magnum clusters, e.g. deploying Slurm-as-a-Service style configuration with Heat creating resource groups for GPUs or large memory configurations. Heat stacks are very small. Basically to only used for node creation.
Some issues adding Inifiniband to Fedora Atomic, adding kernel drivers has been a problem. Some work at CERN on integrating kernel drivers using system containers but this also means making sure the driver levels are consistent. The containers are built using gitlab CI and installing the RPM are part of the pipeline.
Prometheus and Monasca being looked at for Telemetry.
25Ge is working better now, bare metal switch fabric now being used directly without going through gateways.
Looking at resource allocation using Blazar, mixing with pre-emptible instances to fill in. A confluence page organised the end user interactions, A similar approach is used on the US Chameleon project.
Some work going on with Heat as the keys are currently associated with users rather than shared. Investigating using Rundeck for delegated access. Authentication is using EGI Checkin federation but this has some issues regarding trustlss.
There was an approach developed by OATH, James and Ric (authenz seminar at https://indico.cern.ch/event/738867/contributions/3049600/attachments/1678718/2696223/go)
Code available at: https://github.com/yahoo/athenz
Good results for shared Swarm cluster. Users are being encouraged to not log in but just using the APIs.
Following the OATH visit, there are plans to add support for Software RAID. There is theoretical support for hardware RAID but it is early. This could be a topic at the PTG, with John and Surya attending. Also use cases for multiple partitions. Arne is co-ordinating the requirements. Deployment templates is one possibility using traits to indicate that a particular configuration. The need is for the end user to be able to specify the RAID structure they want, traits give an indication of what is possible. Flavors could cover it but would lead to flavor explosion. Adding on boot traits would be a potential solution but is not agreed yet. Deploy templates is the number one priority for Ironic for Stein.
OATH are currently using metadata to adapt the kickstart file. The alternative approach is building something into Ironic. The current CERN implementation using an extra spec on the flavor read by IPA at install time. It is suggested to raise in the PTG to see the approach for the community.
The goal is to be able to discover and converge some of the information about systems from Ironic. OATH also had interest in this. First step should be to collect the requirements as requested by Ironic upstream. Arne will prepare a doc to collect the requirements. Some possibility is to have this as an external service but it would also be a possible extend inspector. There is a python package called Hardware from eNovance which could be used. https://github.com/redhat-cip/hardware - Mark was recently talking with Dmitry Tantsur about bringing this under OpenStack governance. Cardiff tool in this package supports diff’ing nodes such as consistency checking.
There is a lifecycle question - should the inspection be done online too? Waiting until cleaning could be too long, e.g. firmware upgrades.
https://github.com/stackhpc/stackhpc-ipa-hardware-managers/blob/master/stackhpc_ipa_hardware_managers/system_bios.py: IPA agent that checks BIOS and firmware versions during cleaning and will set to the node to maintenance mode if the versions do not match the expected.
Could this be done simply by making the introspection data storage mechanism pluggable?
Working well for CERN. Some issues from StackHPC for multiple network connections and the order of activation. It may be possible already by including switches in the template. Spyros has some more details. Labels can be used to pass additional information as a first implementation such as management, 25G, 100G and Infiniband.
Spec is up for review regarding PENDING state. Should there be a new UUID (i.e. run again) vs re-using the same UUID which would be a benefit for some external tooling. It may be that the --wait logic on OSC or Terraform or Ansible os_server would need the same UUID.
Some work ongoing to clean up cell 0, looking at hard delete of the instance but soft delete may be the better way to proceed. The migrate record may be one possibility.
CERN to use this in a test environment soon. Finish initial implementation and blog about it before the PTG. Need to make it easy for interested parties to try it out. Prove that Terraform, Ansible os_server, etc. work.
Consider integration with Kubernetes OpenStack cloud provider. Does the cloud provider expect to own the full instance life cycle? How would we exert backpressure on the provider when the cloud is full?
Organise a hangout with Matt Riedemann before the PTG to determine his reservations.
Belmiro wants separate per-project quotas for normal instances and preemptible instances. SImilar to how Cinder does quotas for types. Current workaround is to use separate projects just for preemptibles.
In google cloud there are GPU quotas and Preemptible GPU quotas
https://cloud.google.com/compute/docs/instances/preemptible
As well as SSD quotas.
Nova spec was written for flavor classes but was not implemented.
How to solve race conditions in the reaper - will my resources still be available when requested? This is only an issue when aiming for 100% utilisation.
StackHPC are interested in the operational experience of Cells v2. Additions to kolla-ansible would be required to introduce this as the default.
The cell size used at CERN would be similar to that used in Cells v1 (~200 compute nodes). CERN moved during the migration to Queens with over 70 cells. One goal was to allow a single failure domain, sometimes cells are for dedicated projects or shared cells.
Some of the design choices for Cells v2 were difficult to test. One issue encountered is that the Cells v2 handling of Cell down can currently cause a larger scale impact for operations such as scheduling/create/delete and quota calculations.
Some ideas would be a cache for list instance information but the current approach is to provide the minimum information such as UUID which is at the top level cell.
Live migration does not work between cells, because broadcast domains are limited to a single cell.
A per-cell VM (4 core, 8GB) runs conductor & rabbit (non-HA). Databases are provided by a separate service & managed by DBAs.
For the network, there is a single Neutron instance (as there is no cell concept). Thus, this is a single failure domain.
For bare metal, there is a single cell for all bare metal, with around 1,300 servers currently.
Support for Cells v2 in Kolla Ansible is being added by GoDaddy, with RabbitMQ being added first: https://review.openstack.org/#/c/569219/
Tests have been done with PCI passthrough and show no loss of performance. There are license limits to be able to do vGPUs. Presentations are attached to agenda.
StackHPC are using V100s.For monitoring, there are two solutions being investigated using Prometheus and Monasca but these do not seem to understand GPUs fully. Currently, bare metal deployments only.
Some tests have been done with containers and GPUs. For k8s, there is a device plug in. The NVidia depends on the runtime for docker but there is also a google version which has no dependency in k8s but needs the driver on Atomic. This would look a good collaboration to investigate further.
Accounting/Utilisation is another area to investigate which would probably need some developments, although the NVidia plug in seems to have better functionality in this area.
Pablo presented the CERN HPC use-cases. The cluster has ~5k cores, infiniband. Configuration is done using Puppet.
Hyper converged configuration with CephFS.
SLURM used as a batch queueing system. Cgroups used to restrict resources used by user jobs.
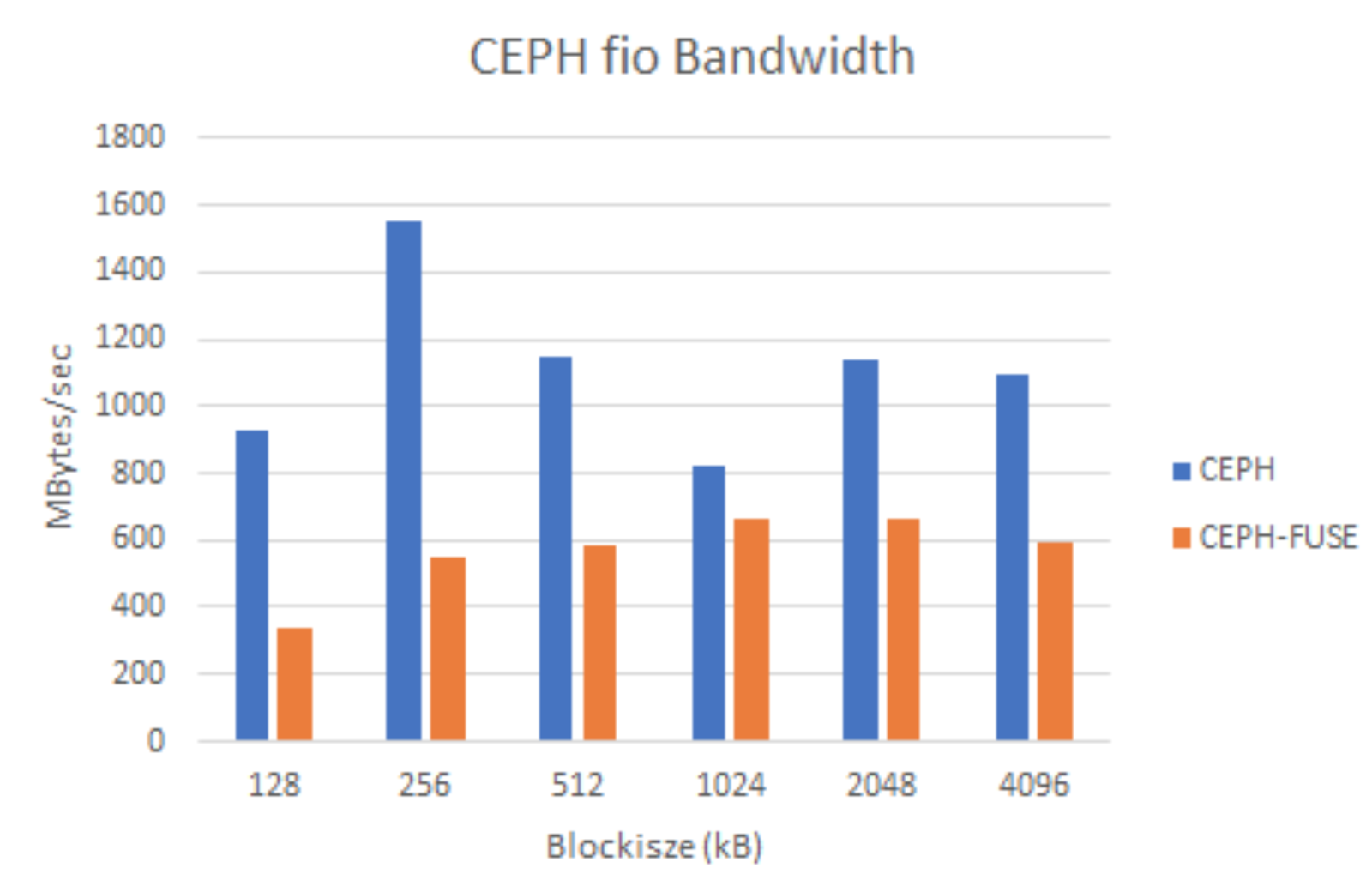
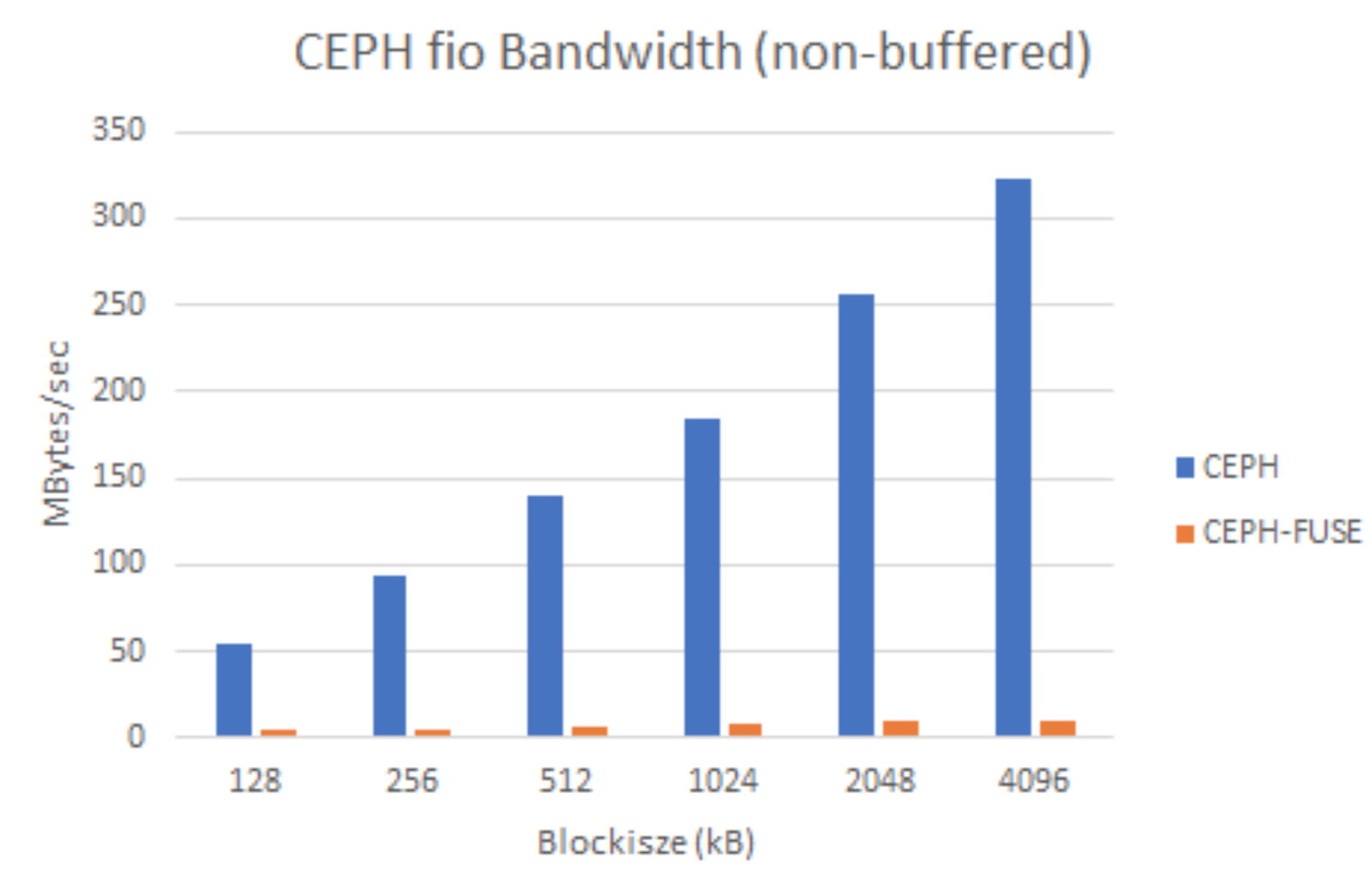
In the hyperconverged infrastructure CERN uses 3 OSDs, and ceph-fuse. To be understood the CPU, network degradation.
Flavor used per-rack for ironic nodes - uses the resource class for scheduling.
SKA described that the HPC prototype is 2 racks, 40 servers. They have 3 networks (one is 100Gb infiniband). Ansible is used extensible to create the user environments.
An interesting point is how to collect metrics from the environment and present them to the user. SKA is using OpenStack Monasca. With it it will be possible to correlate workload/node metrics.
Next steps are: Improving performance telemetry and evaluate the impact of hyperconverged filesystems.
Interest on how CPU heat can influence workload performance.
Dan presented CephFS at CERN.
Stig presented Ceph benchmarks:
Write performance of Cephfs kernel driver vs FUSE driver - buffered and synchronous (unbuffered) writes:
CSI for CephFS upstream? No.
Two parts: CephFS driver, Manila provisioner (to provide shares).
Can be used with existing shares (by specifying the ID) or new shares (by specifying the size).
Blog post about the CSI driver:
https://techblog.web.cern.ch/techblog/post/container-storage-cephfs-csi-part1/
CephFS CSI Driver: https://github.com/ceph/ceph-csi
Manila Provisioner: https://github.com/kubernetes/cloud-provider-openstack/tree/master/pkg/share/manila
CVMFS CSI Driver: https://gitlab.cern.ch/cloud-infrastructure/cvmfs-csi
CERN: Tried OVS and OVS+OpenDaylight. Neither scaled very well, due to neutron OVS agent.
Added a new region using tungsten fabric (ex Opencontrail). Firewall as a service & VPNaaS not supported. Have a CNI driver for k8s. Supports bare metal. VXLAN, MPLS over UDP (licensed) or GRE. L3 to TOR - ECMP. Uses XMPP to talk to vrouters on hypervisors. Uses NETCONF, OVSDB or eVPN to talk to switches. Ebay has a deployment with 70k cores. Requires uses of a non-ML2 neutron plugin. Vrouter agent typically runs in a container, requires a kernel module. Most current switch hardware is Brocade. Requires k8s, cassandra, redis, rabbit.
OpenDaylight is too complicated - large blob of java. Juniper were very helpful.
Network performance tests (Stig, OpenStack Summit - Sydney 2017)
https://www.openstack.org/videos/sydney-2017/five-ways-with-hypervisor-network-performance
Some background at https://docs.google.com/document/d/144g8E_fzGD4WZzMvswkeowzcILL4hxg4QDS-46KYCcQ/edit?ts=5b4f5b76#
Ironic instances boot from volume. Currently using iSCSI, investigating RBD & security holes.
https://docs.openstack.org/ironic/queens/admin/boot-from-volume.html
CERN’s issues:
Adoption of remaining 10k nodes
Deploy time software RAID
CMDB
StackHPC proposes ironic to send the info to the existing databases instead of gathering by itself.
The (very ITIL) based presentation is attached.
Joint presentation proposal for the OpenStack Summit (Berlin, November 13-15)
Title:
Science Demonstrations: Preemptible Instances at CERN and Bare Metal Containers for HPC at SKA
Abstract:
The next generation of research infrastructure and large scale scientific instruments will face new magnitudes of data. This talk presents two flagship programmes: the next generation of the Large Hadron Collider (LHC) at CERN and the Square Kilometre Array (SKA) radio telescope. Each in their way will push infrastructure to the limit.
In this talk, we will provide an update on recent developments in adapting OpenStack to compute-intensive workflows. We will demonstrate the use of pre-emptible instances at CERN, and bare metal containers optimised for HPC at the SKA.
===
CERN - SKA/StackHPC
Agenda
Topics to discuss:
Preemptible VMs
Containers on Baremetal (Kubernetes/Docker Swarm)
Helm experiences / LOCI
Ironic workflow
Feedback from OATH visit (https://indico.cern.ch/event/738867/)
RAID set up following OATH discussions
Details on the BIOS configuration work in StackHPC
Experiences with Hyperconverged
Ceph RDMA
Plans for talks -
PTG in Denver
Summit in Berlin
SKA CERN openlab interest
Cells
GPUs
vGPU vs PCI Passthrough
Monitoring
Nvidia license questions
CERN ongoing procurement
HPC
StackHPC dashboards for SLURM visualisation