Speaker
Description
The surge in data volumes from large scientific collaborations, like the Large Hadron Collider (LHC), poses challenges and opportunities for High Energy Physics (HEP). With annual data projected to grow thirty-fold by 2028, efficient data management is paramount. The HEP community heavily relies on wide-area networks for global data distribution, often resulting in redundant long-distance transfers. This work studies how regional data caches [1] mitigate network congestion and enhance application performance, using millions of access records from regional caches in Southern California, Chicago, and Boston, serving the LHC’s CMS experiment [2]. Our analysis demonstrates the potential of in-network caching to revolutionize large-scale scientific data dissemination.
We analyzed the cache utilization trends, see examples in Figure 1, and identified distinct patterns from the three deployments. Our exploration further employed machine learning models for predicting data access patterns within regional data caches. These findings offer insights crucial for resource usage estimation, including storage cache and network requirements, and can inform improvements in application workflow performance within regional data cache systems. Figure 2 shows the sample prediction result of the hourly cache utilization for SoCal Cache. While the predictions capture volume spikes, they may not precisely match the heights.
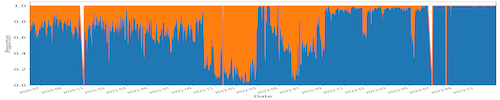
Fig. 1(a). SoCal Cache (capacity 2PB) from June 2020 to Dec. 2023, with 29.48 million data access requests where 23.8PB were read from this cache (i.e., cache hits) and 11.8PB from remote locations (i.e., cache misses). On average, 66.9% of requested data was served from this cache.
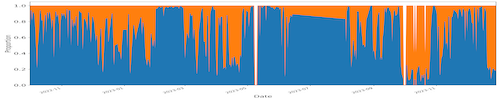
Fig. 1(b). Chicago Cache (capacity 340TB) from Oct. 2022 to Dec. 2023, with 5.7 million data access requests where 11.0PB were read from this cache (i.e., hits) and 13.2PB from remote locations (i.e., misses). On average, 45.5% of the requested data was served from this cache.
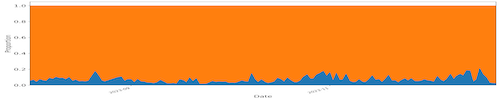
Fig. 1(c). Boston Cache (capacity 170TB) from Aug. 2023 to Dec. 2023, with 27.7 million data access requests where 5.0PB were read from this cache (i.e., hits) and 76.0PB from remote locations (i.e., misses). On average, 6.1% of the requested data was served from this cache.
Fig. 1. Fraction (by data volume) of cache hits (blue) and cache misses (orange) every day for three different in-network cache installations

Fig. 2. Hourly cache hit volume from SoCal Cache, showing actual measurements (blue bars), training predictions (orange bars), and testing predictions (red bars).
In this study, we present a detailed analysis of cache utilization trends across the SoCal, Chicago, and Boston regional caches serving the LHC CMS experiment. Our investigation reveals distinct patterns in cache usage unique to each region, highlighting the need for tailored approaches in cache design. Our exploration of neural network models were demonstrated to provide accurate predictions of cache usage trends, these models could be used anticipate future needs for storage and network resources. By understanding and leveraging these insights, we could significantly enhance the efficiency of resource allocation and optimize application workflow performance.
REFERENCES
[1] E. Fajardo, D. Weitzel, M. Rynge, M. Zvada, J. Hicks, M. Selmeci, B. Lin, P. Paschos, B. Bockelman, A. Hanushevsky, F. W¨urthwein, and I. Sfiligoi, "Creating a content delivery network for general science on the internet backbone using XCaches," EPJ Web of Conferences, vol. 245, p. 04041, 2020. [Online]. Available: https://doi.org/10.1051/epjconf/202024504041
[2] C. Sim, K. Wu, A. Sim, I. Monga, C. Guok, D. Hazen, F. Wurthwein, D. Davila, H. Newman, and J. Balcas, "Predicting resource utilization trends with southern california petabyte scale cache," in 26th International Conference on Computing in High Energy & Nuclear Physics (CHEP2023), 2023.