Choose timezone
Your profile timezone:

The CHEP conference series addresses the computing, networking and software issues for the world’s leading data‐intensive science experiments that currently analyse hundreds of petabytes of data using worldwide computing resources.
The CHEP conference location rotates between the Americas, Asia and Europe, and is typically held eighteen months apart. The CHEP 2024 conference will be hosted by the AGH University of Kraków, Institute of Nuclear Physics Polish Academy of Sciences and Jagiellonian University.

Financial partner:

EGI Foundation supports CHEP with two coordinated projects:
![]()
See special offer for Conference Attendees! LINK
See INDICO for detailas.
Note the registration options LINK and list of recommended accomodation LINK.
Due to the tense political situation and conflict between Ukraine and the Russian Federation, all research institutions in Poland suspend scientific cooperation with institutions in Russia until further notice. Regrettably, we may not allow registration for individuals affiliated with Russian institutions.
Meeting point: in front of the venue, the Auditorium Maximum of Jagiellonian University - Krupnicza 33 Street
The IRIS-HEP software institute, as a contributor to the broader HEP Python ecosystem, is developing scalable analysis infrastructure and software tools to address the upcoming HL-LHC computing challenges with new approaches and paradigms, driven by our vision of what HL-LHC analysis will require. The institute uses a “Grand Challenge” format, constructing a series of increasingly large, complex, and realistic exercises to show the vision of HL-LHC analysis. Recently, the focus has been demonstrating the IRIS-HEP analysis infrastructure at scale and evaluating technology readiness for production.
As a part of the Analysis Grand Challenge activities, the institute executed a “200 Gbps Challenge”, aiming to show sustained data rates into the event processing of multiple analysis pipelines. The challenge integrated teams internal and external to the institute, including operations and facilities, analysis software tools, innovative data delivery and management services, and scalable analysis infrastructure. The challenge showcases the prototypes — including software, services, and facilities — built to process around 200 TB of data in both the CMS NanoAOD and ATLAS PHYSLITE data formats with test pipelines.
The teams were able to sustain the 200 Gbps target across multiple pipelines. The pipelines focusing on event rate were able to process at over 30 MHz. These target rates are demanding; the activity revealed considerations for future testing at this scale and changes necessary for physicists to work at this scale in the future. The 200 Gbps challenge has established a baseline on today’s facilities, setting the stage for the next exercise at twice the scale.
For the High-Luminosity Large Hadron Collider era, the trigger and data acquisition system of the Compact Muon Solenoid experiment will be entirely replaced. Novel design choices have been explored, including ATCA prototyping platforms with SoC controllers and newly available interconnect technologies with serial optical links with data rates up to 28 Gb/s. Trigger data analysis will be performed through sophisticated algorithms, including widespread use of Machine Learning, in large FPGAs, such as the Xilinx Ultrascale family. The system will process over 50 Tb/s of detector data with an event rate of 750 kHz. The talk will discuss the technological and algorithmic aspects of the upgrade of the CMS trigger system, emphasizing the use of low-latency Machine Learning and AI algorithms with several examples.
Since the beginning of Run 3 of LHC the upgraded LHCb experiment is using a triggerless readout system collecting data at an event rate of 30 MHz and a data rate of 4 TB/s. The trigger system is split in two high-level trigger (HLT) stages. During the first stage (HLT1), implemented on GPGPUs, track reconstruction and vertex fitting for charged particles is performed to reduce the event rate to 1 MHz, where the events are buffered to a disk. In the second stage (HLT2), deployed on a CPU server farm, a full offline-quality reconstruction of charged and neutral particles and their selection is performed, aided by the detector alignment and calibration run in quasi-real time on buffered events. This allows to use the output of the trigger directly for offline analysis. In this talk we will give a review of the implementation and challenges of the heterogenous LHCb trigger system, discuss the operational experience and first results of Run 3 together with the prospects for the High-Luminosity LHC era.
Julia is a mature general-purpose programming language, with a large ecosystem of libraries and more than 10000 third-party packages, which specifically targets scientific computing. As a language, Julia is as dynamic, interactive, and accessible as Python with NumPy, but achieves run-time performance on par with C/C++. In this paper, we describe the state of adoption of Julia in HEP, where momentum has been gathering over a number of years.
HEP-oriented Julia packages can, via UnROOT.jl, already read HEP's major file formats, including TTree and RNTuple formats. Interfaces to some of HEP's major software packages, such as through Geant4.jl, are available too. Jet reconstruction algorithms in Julia show excellent performance. A number of full HEP analyses have been performed in Julia.
We show how, as the support for HEP has matured, developments have benefited from Julia's core design choices, which makes reuse from and integration with other packages easy. In particular, libraries developed outside HEP for plotting, statistics, fitting, and scientific machine learning are extremely useful.
We believe that the powerful combination of flexibility and speed, the wide selection of scientific programming tools, and support for all modern programming paradigms and tools, make Julia the ideal choice for a future language in HEP.
Detailed event simulation at the LHC is taking a large fraction of computing budget. CMS developed an end-to-end ML based simulation that can speed up the time for production of analysis samples of several orders of magnitude with a limited loss of accuracy. As the CMS experiment is adopting a common analysis level format, the NANOAOD, for a larger number of analyses, such an event representation is used as the target of this ultra fast simulation that we call FlashSim. Generator level events, from PYTHIA or other generators, are directly translated into NANOAOD events at several hundred Hz rate with FlashSim. We show how training FlashSim on a limited number of full simulation events is sufficient to achieve very good accuracy on larger datasets for processes not seen at training time. Comparisons with full simulation samples in some simplified benchmark analysis are also shown. With this work, we aim at establishing a new paradigm for LHC collision simulation workflows in view of HL-LHC.
The ATLAS Collaboration has released an extensive volume of data for research use for the first time. The full datasets of proton collisions from 2015 and 2016, alongside a wide array of matching simulated data, are all offered in the PHYSLITE format. This lightweight format is chosen for its efficiency and is the preferred standard for ATLAS internal analyses. Additionally, the inclusion of Heavy Ion collision data considerably widens the scope for research within the particle physics community. To ensure accessibility and usability, the release includes a comprehensive suite of software tools and detailed documentation, catering to a varied audience. Code examples, from basic Jupyter notebooks to more complex C++ analysis packages, aim to facilitate engagement with the data. This contribution details the available data, corresponding metadata, software, and documentation, and initial interactions with researchers outside the ATLAS collaboration, underscoring the project's potential to foster new research and collaborations.
Online and real-time computing
Since 2022, the LHCb detector is taking data with a full software trigger at the LHC proton-proton collision rate, implemented in GPUs in the first stage and CPUs in the second stage. This setup allows to perform the alignment & calibration online and to perform physics analyses directly on the output of the online reconstruction, following the real-time analysis paradigm. This talk will give a detailed overview of the LHCb trigger implementation and its underlying computing infrastructure, discuss challenges of using a heterogeneous architecture and report its performance in nominal data taking conditions during 2024 after two commissioning years.
The ATLAS experiment in the LHC Run 3 uses a two-level trigger system to select
events of interest to reduce the 40 MHz bunch crossing rate to a recorded rate
of up to 3 kHz of fully-built physics events. The trigger system is composed of
a hardware based Level-1 trigger and a software based High Level Trigger.
The selection of events by the High Level Trigger is based on a wide variety of
reconstructed objects, including leptons, photons, jets, b-jets, missing
transverse energy, and B-hadrons in order to cover the full range of the ATLAS
physics programme.
We will present an overview of improvements in the reconstruction, calibration,
and performance of the different trigger objects, as well as computational
performance of the High Level Trigger system.
Timepix4 is an innovative multi-purpose ASIC developed by the Medipix4 Collaboration at CERN for fundamental and applied physics detection systems. It is composed by a ~7cm$^2$ area matrix with about 230k independent pixels, each one with a charge integration circuit, a discriminator and a time-to-digital converter that allows to measure Time-of-Arrival with 195 ps width bins and Time-over-Threshold with 1.56 ns width bins. Timepix4 can produce up to 160 Gbps of output data, so a strong software counterpart is needed for fast and efficient data processing.
We developed an open-source multi-thread C++ framework to manage the Timepix4 ASIC, regardless of which control board is used for communication with the server. The software can configure Timepix4 through low and high level functions, depending on the final user’s expertise and his need for customization. Those methods also allow the user to easily perform complex routines, like pixel matrix equalization and calibration, with user-friendly C++ scripts.
When the acquisition starts, some read-out threads can safely store Timepix4 data on disk. Offline post-acquisition classes can be used to analyze the data, using a custom clustering algorithm that can process more than 1M events/s and, if needed, an ad-hoc convolutional neural network for particle track identification. If the acquisition rate is lower than 1M events/s, clustering can be performed online, exploiting a dedicated thread, connected to read-out ones, that runs the same algorithm. Moreover, an online monitor thread can be connected to clustering object to view up to O(100)kEvents/s, showing a hit-map and real-time statistics like cluster dimension and energy.
In this contribution we will present the software architecture, its performances and some results obtained during acquisitions using radioactive sources, X-ray tubes and monochromatic synchrotron X-ray beams.
The NA62 experiment is designed to study kaon’s rare decays using a decay-in-flight technique. Its Trigger and Data Acquisition (TDAQ) system is multi-level, making it critically dependent on the performance of the inter-level network.
To manage the enormous amount of data produced by the detectors, three levels of triggers are used. The first level L0TP, implemented using an FPGA device, has been in operation since the start of data taking in 2016.
To increase the efficiency of the system and implement additional algorithms, an upgraded system (L0TP+) was developed starting in 2018. This upgrade utilizes a high-end FPGA available on the market, offering more computing power, larger local memory, and higher transmission bandwidth.
We have planned tests for a new trigger algorithm that implements quadrant-based logic for the veto systems. This new approach is expected to improve the main trigger efficiency by several percent.
Extensive tests were conducted using a parasitic setup that included a set of Network TAPs and a commodity server, allowing for proficient comparison of trigger decisions on an event-by-event basis. The experience gained from this parasitic mode operation can be leveraged for the next data-taking period as a development setup to implement additional features, thereby accelerating the TDAQ upgrade.
After the testing period, the new system has been adopted as the online processor since 2023. Preliminary results on the efficiency of the new system will be reported. Integration with the new AI-based FPGA-RICH system, which performs online partial particle identification, will also be discussed.
Digital ELI-NP List-mode Acquisition (DELILA) is a data acquisition (DAQ) system for the Variable Energy GAmma (VEGA) beamline system at Extreme Light Infrastructure – Nuclear Physics (ELI-NP), Magurele, Romania [1]. ELI-NP has been implementing the VEGA beamline and entirely operate the beamline in 2026. Several different detectors/experiments (e.g. High Purity Ge (HPGe) detectors, Si detectors and scintillator detectors) will be placed at the VEGA beam line and read out by CAEN digitizers, Mesytec ADC and TDC, and some other electronics [2]. DELILA has been developed using mainly DAQ-Middleware and CAEN digitizer libraries to fit the experiments and the read-out electronics [3]. The main requirements are network transparency and synchronized time stamps. DAQ-Middleware allows us to fetch data from different electronics and computers to a data merger via Ethernet.
DELILA uses two databases to record experimental information: MongoDB for the run information and InfluxDB for event rates. DELILA uses ROOT libraries for online monitoring and recording experiment data.
The DAQ system has been used for several experiments at IFIN-HH 9MV and 3MV tandem beamlines in Romania [4]. The presenter will present the implementation and results of DELILA.
[1] S. Gales, K.A. Tanaka et al., Rep. Prog. Phys. 81 094301 (2018)
[2] N.V. Zamfir et al., Romanian Reports in Physics 68 Supplement, S3–S945 (2016)
[3] Y. Yasu et al., J. Phys.: Conf. Ser. 219 022025 (2010)
[4] S.Aogaki et al. Nuclear Inst. and Methods in Physics Research, A 1056 (2023) 168628
The ePIC collaboration adopted the JANA2 framework to manage its reconstruction algorithms. This framework has since evolved substantially in response to ePIC's needs. There have been three main design drivers: integrating cleanly with the PODIO-based data models and other layers of the key4hep stack, enabling external configuration of existing components, and supporting timeframe splitting for streaming readout. The result is a unified component model featuring a new declarative interface for specifying inputs, outputs, parameters, services, and resources. This interface enables the user to instantiate, configure, and wire components via an external file. One critical new addition to the component model is a hierarchical decomposition of data boundaries into levels such as Run, Timeframe, PhysicsEvent, and Subevent. Two new component abstractions, Folder and Unfolder, are introduced in order to traverse this hierarchy, e.g. by splitting or merging. The pre-existing components can now operate at different event levels, and JANA2 will automatically construct the corresponding parallel processing topology. This means that a user may write an algorithm once, and configure it at runtime to operate on timeframes or on physics events. Overall, these changes mean that the user requires less knowledge about the framework internals, obtains greater flexibility with configuration, and gains the ability to reuse the existing abstractions in new streaming contexts.
Offline Computing
Tracking charged particles in high-energy physics experiments is a computationally intensive task. With the advent of the High Luminosity LHC era, which is expected to significantly increase the number of proton-proton interactions per beam collision, the amount of data to be analysed will increase dramatically. As a consequence, local pattern recognition algorithms suffer from scaling problems.
In this work, we investigate the possibility of using machine learning techniques in combination with quantum computing. In particular, we represent particle trajectories as a graph data structures and train a quantum graph neural network to perform global pattern recognition. We show recent results on the application of this method, with scalability tests for increasing pileup values. We discuss the critical points and give an outlook of potential improvements and alternative approaches.
We also provide insights into various aspects of code development in different quantum programming frameworks such as Pennylane and IBM Qiskit.
With the future high-luminosity LHC era fast approaching high-energy physics faces large computational challenges for event reconstruction. Employing the LHCb vertex locator as our case study we are investigating a new approach for charged particle track reconstruction. This new algorithm hinges on minimizing an Ising-like Hamiltonian using matrix inversion. Performing this matrix inversion classically achieves reconstruction efficiency akin to the current state-of-the-art algorithms but is hindered by worse time complexity. Exploiting the Harrow-Hassadim-Lloyd (HHL) quantum algorithm for linear systems holds the promise of an exponential speedup in the number of input hits over its classical counterpart. Contingent upon the following conditions: efficient quantum phase estimation (QPE) and an intuitive way to read out the algorithm's output. This contribution builds on previous work (DOI 10.1088/1748-0221/18/11/P11028) and strives to fulfil these conditions and streamlines the proposed algorithm's circuit depth, by a factor up to $10^4$. We propose a modified version of the HHL algorithm by restricting QPE precision to two bits. Enabling us to introduce a novel post-processing algorithm, which estimates event Primary Vertices (PVs), then efficiently computes all event tracks though an Adaptive Hough Transform. This alteration significantly reduces circuit depth and addresses HHL's readout issue, bringing the reconstruction of small events closer to current hardware implementation. The findings presented here aim to further illuminate the potential of harnessing quantum computing for the future of particle track reconstruction in high-energy physics.
The Super Tau Charm Facility (STCF) is a future electron-positron collider proposed with a center-of-mass energy ranging from 2 to 7 GeV and a peak luminosity of 0.5$\times10^{35}$ ${\rm cm}^{-2}{\rm s}^{-1}$. In STCF, the identification of high-momentum hadrons is critical for various physics studies, therefore two Cherenkov detectors (RICH and DTOF) are designed to boost the PID performance.
In this work, targeting the pion/kaon identification at STCF, we developed a PID algorithm based on the convolutional neural network (CNN) for the DTOF detector, which combines the hit channel and arrival time of Cherenkov photons at multi-anode microchannel plate photomultipliers. The current performance meets the physics requirements of STCF, with a pion identification efficiency exceeding 97% along with a kaon misidentification rate of less than 2% at p = 2Gev/c. In addition, based on classical CNN, we conducted a proof-of-concept study on quantum convolutional neural networks (QCNN) to explore potential quantum advantages and feasibility. Preliminary results indicate that QCNN has a promising potential to outperform classical CNN on a same dataset.
Noisy intermediate-scale quantum (NISQ) computers, while limited by imperfections and small scale, hold promise for near-term quantum advantages in nuclear and high-energy physics (NHEP) when coupled with co-designed quantum algorithms and special-purpose quantum processing units.
Developing co-design approaches is essential for near-term usability, but inherent challenges exist due to the fundamental properties of NISQ algorithms.
In this contribution we therefore investigate the core algorithms, which can solve optimisation problems via the abstraction layer of a quadratic Ising model or general unconstrained binary optimisation problems (QUBO), namely quantum annealing (QA) and the quantum approximate optimisation algorithm (QAOA).
Applications in NHEP utilising QUBO formulations range from particle track reconstruction, over job scheduling on computing clusters to experimental control.
While QA and QAOA do not inherently imply quantum advantage, QA runtime for specific problems can be determined based on the physical properties of the underlying Hamiltonian, albeit it is a computationally hard problem itself.
Our primary focus is on two key areas:
Firstly, we estimate runtimes and scalability for common NHEP problems addressed via QUBO formulations by identifying minimum energy solutions of intermediate Hamiltonian operators encountered during the annealing process.
Secondly, we investigate how the classical parameter space in the QAOA, together with approximation techniques such as a Fourier-analysis based heuristic, proposed by Zhou et al. (2018), can help to achieve (future) quantum advantage, considering a trade-off between computational complexity and solution quality.
Our computational analysis of seminal optimisation problems suggests that only lower frequency components in the parameter space are of significance for deriving reasonable annealing schedules, indicating that heuristics can offer improvements in resource requirements, while still yielding near-optimal results.
Quantum computing can empower machine learning models by enabling kernel machines to leverage quantum kernels for representing similarity measures between data. Quantum kernels are able to capture relationships in the data that are not efficiently computable on classical devices. However, there is no straightforward method to engineer the optimal quantum kernel for each specific use case.While recent literature has focused on exploiting the potential offered by the presence of symmetries in the data to guide the construction of quantum kernels, we adopt here a different approach, which employs optimization techniques, similar to those used in neural architecture search and AutoML, to automatically find an optimal kernel in a heuristic manner. The algorithm we present constructs a quantum circuit implementing the similarity measure as a combinatorial object, which is evaluated based on a cost function and is then iteratively modified using a meta-heuristic optimization technique. The cost function can encode many criteria ensuringfavorable statistical properties of the candidate solution, such as the rank of the Dynamical Lie Algebra. Importantly, our approach is independent of the optimization technique employed.The results obtained by testing our approach on a high-energy physics problem demonstrate that, in the best-case scenario, we can either match or improve testing accuracy with respect to the manual design approach, showing the potential of our technique to deliver superior results with reduced effort.
Offline Computing
RNTuple is the new columnar data format designed as the successor to ROOT's TTree format. It allows to make use of modern hardware capabilities and is expected to be used in production by the LHC experiments during the HL-LHC. In this contribution, we will discuss the usage of Direct I/O to fully exploit modern SSDs, especially in the context of the recent addition of parallel RNTuple writing. In contrast to buffered I/O where files are accessed via the operating system's page cache, Direct I/O circumvents all caching by the kernel and thereby enables higher bandwidths. However, to achieve this advantage, Direct I/O imposes strict alignment requirements on the I/O requests sent to the operating system: In particular, file offsets, byte counts and userspace buffer addresses must be aligned appropriately. This is challenging for columnar data formats and RNTuple pages that have variable size after compression. We will discuss possible strategies and performance results for both synthetic benchmarks as well as real-world applications.
Machine Learning (ML)-based algorithms play increasingly important roles in almost all aspects of the data analyses in ATLAS. Diverse ML models are used in detector simulations, event reconstructions, and data analyses. They are being deployed in the ATLAS software framework, Athena. The primary approach to perform ML inference in Athena is to use the ONNXRuntime. However, some ML models could not be converted to ONNXRuntime because certain ML operations, such as the MultiAggregation in pyG as of writing, are not supported. Furthermore, a scalable inference strategy that maximises the event processing throughput is needed to cope with the ever-increasing simulation and collision data. A key element in that strategy should be enabling these ML algorithms to run on coprocessors like GPUs because not all computing sites have coprocessors. To that end, we introduce AthenaTriton, a tool that runs ML inference as a service based on the NVIDIA Triton Inference Server. With AthenaTriton, we give Athena the capability to act as a Triton client that sends requests to a remote or local server that performs the model inference. We will present the AthenaTriton design and its scalability in running ML-based algorithms. We emphasise that AthenaTriton can be used in both online and offline computing.
The KM3NeT collaboration is constructing two underwater neutrino detectors in the Mediterranean Sea sharing the same technology: the ARCA and ORCA detectors. ARCA is optimized for the observation of astrophysical neutrinos, while ORCA is designed to determine the neutrino mass hierarchy by detecting atmospheric neutrinos. Data from the first deployed detection units are being analyzed and several physics analyses have already been presented. As the detector configurations are growing and therefore, the amount of the recorded data, efficient data quality and processing management are essential.
Data reconstruction and Monte Carlo simulations are handled separately for each data taking period (run), to achieve complete processing output and optimal computing performance. A Run-by-Run simulation procedure is followed, to reproduce the conditions, possible seawater environment variations as well as the acquisition setup for each run. To handle computing requirements such as portability, reproducibility and scalability, the collaboration implemented this approach using Snakemake, a trending workflow management system.
The High Energy cosmic-Radiation Detection facility (HERD) is a scientific instrument planned for deployment on the Chinese Space Station, aimed at indirectly detecting dark matter and conducting gamma-ray astronomical research. HERD Offline Software (HERDOS) is developed for the HERD offline data processing, including Monte Carlo simulation, calibration, reconstruction and physics analysis tasks. HERDOS is developed based on SNiPER, a lightweight framework designed for HEP experiments, as well as a few state-of-the-art software in the HEP community, such as Detector Description Toolkit (DD4hep), the plain-old-data I/O (podio) and Intel Thread Building Blocks (TBB), etc.
This contribution will provide an overview of the design and implementation details of HERDOS, and in particular, the following details will be addrssed:
1. The design of the Event Data Model (EDM) based on Podio, and the implementation of data management system (DMS) through the integration of Podio and SNiPER.
2. The parallelized DMS based on SNiPER and TBB, specifically the development of GlobalStore based on the Podio to enable concurrent data access and data I/O.
3. The parallelized detector simulation based on MT-SNiPER,including both event-level and track-level parallelism.
4. The geometry management system based on DD4hep that provides consistent detector description, an easy-to-use interface to retrieve detector description information.
At present, HERDOS is operating effectively to support the design of the detector, as well as the exploration of its physics potential.
Run 4 of the LHC will yield an unprecedented volume of data. In order
to process this data, the ATLAS collaboration is evolving its offline
software to be able to use heterogenous resources such as GPUs and FPGAs.
To reduce conversion overheads, the event data model (EDM) should be
compatible with the requirements of these resources. While the
ATLAS EDM has long allowed representing data as a structure of arrays,
further evolution of the EDM can enable more efficient sharing of data
between CPU and GPU resources. Some of this work will be summarized here,
including extensions to allow controlling how memory for event data
is allocated and implementation of jagged vectors.
After two successful physics runs the LHCb experiment underwent a comprehensive upgrade to enable LHCb to run at five times the instantaneous luminosity for Run 3 of the LHC. With this upgrade, LHCb is now the largest producer of data at the LHC. A new offline dataflow was developed to facilitate fast time-to-insight whilst respecting constraints from disk and CPU resources. The Sprucing is an offline data processing step that further refines the selections and persistency of physics channels coming out of the trigger system. In addition, the Sprucing splits the data into multiple streams, which are written in a format that facilitates more efficient compression. Next, Analysis Productions provide LHCb analysts with a declarative approach to tupling this data, efficiently exploiting WLCG resources in a centralised way.
The Sprucing and Analysis Productions offline chain provides analysts with their customised tuples within days of the data being taken by the LHCb experiment.
This talk will present the development of this offline data processing chain with a focus on performance results gathered during operations in 2024.
Simulation and analysis tools
At the LHC experiments, RNTuple is emerging as the primary data storage solution, and will be ready for production next year. In this context, we introduce the latest development in UnROOT.jl, a high-performance and thread-safe Julia ROOT I/O package that facilitates both the reading and writing of RNTuple data.
We briefly share insights gained from implementing RNTuple Reader twice: first in Python, and then in Julia. We discuss the composability of the RNTuple type system and demonstrate how Julia's multiple dispatch feature has been effectively employed to realize this concisely.
Regarding the implementation of RNTuple Writer, we outline the current capabilities and illustrate how they support end-user analyses. Furthermore, we present a roadmap for future development aimed at achieving seamless data I/O interoperability across various programming languages and libraries, including C++, Python, and Julia.
Lastly, we showcase the capabilities and performance of our Julia implementation with real examples. We highlight how our solution facilitates interactive analysis for end-users utilizing RNTuple.
The Fair Universe project is organising the HiggsML Uncertainty Challenge, which will/has run from June to October 2024.
This HEP and Machine Learning competition is the first to strongly emphasise uncertainties: mastering uncertainties in the input training dataset and outputting credible confidence intervals.
The context is the measurement of the Higgs to tau+ tau- cross section like in HiggsML challenge on Kaggle in 2014, from a dataset of the 4-momentum signal state. Participants should design an advanced analysis technique that can not only measure the signal strength but also provide a confidence interval, from which correct coverage will be evaluated automatically from pseudo-experiments.
The confidence interval should include statistical and systematic uncertainties (concerning detector calibration, background levels, etc…). It is expected that advanced analysis techniques that can control the impact of systematics will perform best, thereby pushing the field of uncertainty-aware AI techniques for HEP and beyond.
The challenge is hosted on Codabench (an evolution of the popular Codalab platform); the significant resources needed (to run the thousands of pseudo-experiments needed) are possible thanks to using NERSC infrastructure as a backend.
The competition will have ended just before CHEP 2024 so that a first glimpse of the competition results could be made public for the first time.
The high luminosity LHC (HL-LHC) era will deliver unprecedented luminosity and new detector capabilities for LHC experiments, leading to significant computing challenges with storing, processing, and analyzing the data. The development of small, analysis-ready storage formats like CMS NanoAOD (4kB/event), suitable for up to half of physics searches and measurements, helps achieve necessary reductions in data processing and storage. However, a large fraction of analyses frequently require very computationally expensive machine learning output or data only stored in larger and less accessible formats, such as CMS MiniAOD (45kB/eevent) or AOD (450kB/event). This necessitates the non-volatile storage of derived data in custom formats. In this work, we present research on the development of workflows and integration of tools with ServiceX to efficiently fetch, cache, and join together data for use with columnar analysis tools.
We leverage scaleable, distributed SQL query engines like Trino to join disparate columns sourced from multiple files and without a restriction on relative row ordering. By replacing many customized datasets, containing largely overlapping contents, with smaller and unique sets of information that can be joined on demand with common central data, duplication can be reduced. Caching of these results keeps the cost of subsequent retrieval low, fitting well with modern physics analysis paradigms.
The software toolbox used for "big data" analysis in the last few years is rapidly changing. The adoption of software design approaches able to exploit the new hardware architectures and improve code expressiveness plays a pivotal role in boosting data processing speed, resources optimisation, analysis portability and analysis preservation.
The scientific collaborations in the field of High Energy Physics (e.g. the LHC experiments, the next-generation neutrino experiments, and many more) are devoting increasing resources to the development and implementation of bleeding-edge software technologies in order to cope effectively with always growing data samples, pushing the reach of the single experiment and of the whole HEP community.
The introduction of declarative paradigms in the analysis description and implementation is growing interest and support in the main collaborations. This approach can simplify and speed-up the analysis description phase, support the portability of the analyses among different datasets/experiments and strengthen the preservation and reproducibility of the results.
Furthermore this approach, providing a deep decoupling between the analysis algorithm and back-end implementation, is a key element for present and future processing speed, potentially even with back-ends not existing today.
In the landscape of the approaches currently under study, an activity is ongoing in the ICSC (Centro Nazionale di Ricerca in HPC, Big Data and Quantum Computing, Italy) which focuses on the development of a framework characterised by a declarative paradigm for the analysis description and able to operate on datasets from different experiments.
The existing NAIL (Natural Analysis Implementation Language [1]) Python package, developed in the context of the CMS data analysis for the event processing, is used as a building base for the development of a demonstrator able to provide a general and effective interface characterised by a declarative paradigm and targeted to the description and implementation of a full analysis chain for HEP data, with support for different data formats.
Status and development plan of the demonstrator will be discussed.
[1]https://indico.cern.ch/event/769263/contributions/3413006/attachments/1840145/3016759/NAIL_Project_Natural_Analysis_Implementation_Language_1.pdf
The ATLAS experiment is in the process of developing a columnar analysis demonstrator, which takes advantage of the Python ecosystem of data science tools. This project is inspired by the analysis demonstrator from IRIS-HEP.
The demonstrator employs PHYSLITE OpenData from the ATLAS collaboration, the new Run 3 compact ATLAS analysis data format. The tight integration of ROOT features within PHYSLITE presents unique challenges when integrating with the Python analysis ecosystem. The demonstrator is constructed from ATLAS PHYSLITE OpenData, ensuring the accessibility and reproducibility of the analysis.
The analysis pipeline of the demonstrator incorporates a comprehensive suite of tools and libraries. These include uproot for data reading, awkward-array for data manipulation, Dask for parallel computing, and hist for histogram processing. For the purpose of statistical analysis, the pipeline integrates cabinetry and pyhf, providing a robust toolkit for analysis. A significant component of this project is the custom application of corrections, scale factors, and systematic errors using ATLAS software. Therefore for this component we conduct a comparative analysis of event processing throughput across both the event-loop and columnar analysis environments. The infrastructure and methodology for these applications will be discussed in detail during the presentation, underscoring the adaptability of the Python ecosystem for high-energy physics analysis.
Over the past few decades, there has been a noticeable surge in muon tomography research, also referred to as muography. This method, falling under the umbrella of Non-Destructive Evaluation (NDE), constructs a three-dimensional image of a target object by harnessing the interaction between cosmic ray muons and matter, akin to how radiography utilizes X-rays. Essentially, muography entails scanning a target object by analyzing its interaction with muons, with the interaction mode contingent upon the energy of the incident muon and the characteristics of the medium involved. As cosmic muons interact electromagnetically with atoms within the target medium, their trajectories are likely to deviate prior to reaching the position sensitive detectors placed at suitable locations around the object under study. These deviations serve as a rich source of data that can be used to generate images and infer the material composition of the target.
In this study, a numerical simulation has been conducted using the GEANT4 framework to assess the efficacy of various position sensitive charged particle detectors in muography. The feasibility of detectors with a broad range of position resolutions has been tested, particularly in the context of developing an imaging algorithm to monitor drums containing nuclear waste. The Cosmic Ray Shower Library (CRY) has been employed to simulate muon showers on the detector-target system. The reconstruction of muon tracks, crucial for analyzing muon scattering, has been achieved by collecting hits from all detector layers. Incoming muon tracks have been reconstructed using hits from the upper set of detectors, while outgoing muon tracks have been reconstructed using hits from the lower set. In this presentation, the discussion will center on track reconstruction algorithms, emphasizing the use of efficient single scattering point algorithms like Point of Closest Approach (PoCA) for simplified implementation and fast computation. To enhance material discrimination confidence, a Support Vector Machine (SVM) based algorithm has been applied, utilizing features such as scattering vertices density (𝜌𝑐) and average deviation angle (𝜃𝑎𝑣𝑔) as inputs. SVM hyperplanes have been generated to segregate various material classes, and corresponding confusion matrices have been obtained. Additionally, for analyzing the shape of materials within nuclear waste drums, an algorithm based on Pattern Recognition Method (PRM) has been employed. This presentation will delve into studies of track reconstruction algorithms applied to GEANT4 data for particle detectors with varying position resolutions, followed by shape and image analysis based on the PRM with the motivation of optimizing storage of nuclear waste that can be efficiently monitored by techniques such as muography.
Simulation and analysis tools
The Jiangmen Underground Neutrino Observatory (JUNO) is a neutrino experiment under construction in the Guangdong province of China. The experiment has a wide physics program with the most ambitious goal being the determination of the neutrino mass ordering and the high-precision measurement of neutrino oscillation properties using anti-neutrinos produced in the 50 km distant commercial nuclear reactors of Taishan and Yangjiang.
To reach its aims, the detector features an acrylic sphere of 35.4 meters in diameter filled with 20 kt of liquid scintillator and equipped with 17612 20-inch photomultiplier tubes (PMTs) and 25 600 3-inch PMTs to provide an energy resolution better than 3% at 1 MeV. In addition to the cutting-edge features and performance of the detector, a critical aspect for achieving the physics goals is a deep understanding of such a complicated detector. In this respect, an accurate Monte Carlo (MC) simulation of the detector and the interactions happening inside of it is crucial. The simulation depends on many effective parameters, which must be tuned to accurately describe the data acquired.
In this contribution, we propose a novel machine-learning approach to MC tuning that combines Generative Learning and data acquired during calibration campaigns. We study Generative Adversarial Networks (GAN) as a way to speed up event simulation and as an efficient model to interpolate within the parameter space. We consider three main parameters related to the energy response of the JUNO detector and optimize their value in the MC by comparing calibration data to the GAN simulations. Parameter estimation is performed via Bayesian optimization based on a Nested Sampling algorithm to cope with the wide and complex parameter space.
The presented approach is easily scalable to include more parameters and is general enough to be employed in most modern physics experiments.
The ATLAS experiment at the LHC heavily depends on simulated event samples produced by a full Geant4 detector simulation. This Monte Carlo (MC) simulation based on Geant4 is a major consumer of computing resources and is anticipated to remain one of the dominant resource users in the HL-LHC era. ATLAS has continuously been working to improve the computational performance of this simulation for the Run 3 MC campaign. This update highlights the implementation of recent and upcoming optimizations. These improvements include enhancements to the core Geant4 software, strategic choices in simulation configuration, simplifications in geometry and magnetic field descriptions, and technical refinements in the interface between ATLAS simulation code and Geant4. Overall, these improvements have resulted in a more than 100% increase in throughput compared to the baseline simulation configuration utilized during Run 2.
For the start of Run-3 CMS Full Simulation was based on Geant4 10.7.2. In this work we report on evolution of usage of Geant4 within CMSSW and adaptation of the newest Geant4 11.2.1, which is expected to be used for CMS simulation production in 2025. Physics validation results and results on CPU performance are reported.
For the Phase-2 simulation several R&D are carried out. A significant update for CMS geometry description is performed using DD4hep and VecGeom tools, modifications of the CMS geometry concern a new tracker, a new timing detector, an extended muon system, and a new endcap high granular calorimeter. Different aspects of geometry description and physics simulation for the new detectors will be discussed. Progress on R&D efforts for the Phase-2 simulation will be presented, which includes reports on experience of application of G4HepEm, Seleritas, and AdePT external libraries.
The Compressed Baryonic Matter (CBM) is an under-construction heavy-ion physics experiment for exploring the QCD phase diagram at high $\mu_{B}$ which will use the new SIS-100 accelerator at the Facility for Anti-Proton and Ion Research (FAIR) in Darmstadt, Germany. The Silicon Tracking System (STS) is to be the main detector for tracking and momentum determination. A scaled-down prototype of various detector systems including mini STS (mSTS) is undergoing meticulous testing in the mini CBM (mCBM) experiment at the existing SIS-18 accelerator at GSI, Helmholtzzentrum f$\ddot{u}$r Schwerionenforschung in Darmstadt. This initiative seeks to comprehensively assess both hardware and software components, ensuring their efficacy in online capturing, processing and analyzing the intricate topological data generated by real events detected by the detector sub-systems.
In recent years, much effort has been put into a better and more accurate description of the detector geometries to better model the background. The direct conversion of Computer-Aided Design (CAD) based geometry model to Geometry Description Markup Language (GDML), XML-based format using different software toolkits has attracted considerable attention. The solids extracted from CAD models and represented in GDML format typically consist of triangular or quadrilateral facets. $\texttt{TGDMLParser}$ functionality in the ROOT and $\texttt{G4GDMLParser}$ in the GEANT facilitate the reading of different volumes from the GDML file and the creation of volume assemblies. However, this approach leads to an increase in simulation computation run-time.
We will present a comparative analysis of simulation studies with two distinct representations of the mSTS geometry: one employing simplified primitive ROOT/TGeo solids and the other utilizing Tessellated solid-based geometry, including secondary particle production, the significance of passive volumes, computation time; as well as a comparison of simulation data with real data measured with Ni-Ni collisions at 1.93 AGeV.
The IceCube Neutrino Observatory instruments one cubic kilometer of glacial ice at the geographic South Pole. Cherenkov light emitted by charged particles is detected by 5160 photomultiplier tubes embedded in the ice. Deep antarctic ice is extremely transparent, resulting in absorption lengths exceeding 100m. However, yearly variations in snow deposition rates on the glacier over the last 100 thousand years have created roughly horizontal layers which vary significantly in scattering and absorption coefficients. Theses variations must be taking into account when simulating IceCube events. In addition, anisotropies in photon propagation have been observed and recently described by deflection by birefringent polycrystals. Modeling of ice properties remains one of the largest sources of systematic uncertainties in IceCube analyses, requiring intensive studies of the ice. Despite the fact that photon tracking is highly parallelizable and is an ideal case for GPUs, the limiting constraint for these studies is time spent simulating photon propagation. In order to efficiently and accurately perform these simulations, custom software has been developed and optimized for our specific use case. IceCube's current production simulation code CLSim is based on OpenCL and is tightly coupled to the IceCube's simulation stack and is in need of modernization. This talk will discuss the current requirements for Photon tracking code in IceCube and the effort to transition the code to new C++ frameworks which uses std::par.
Collaborative software and maintainability
The ATLAS offline code management system serves as a collaborative framework for developing a code base totaling more than 5 million lines. Supporting up to 50 nightly release branches, the ATLAS Nightly System offers abundant opportunities for updating existing software and developing new tools for forthcoming experimental stages within a multi-platform environment. This paper describes the utilization of container technology for the ATLAS nightly jobs. By conducting builds and tests of offline releases within containers, we ensure portability across various build nodes. The controlled container environment enhances stability by removing dependencies on operating system updates. Furthermore, it sets the base and facilitates the production of containerized software across different user activity areas and pipelines. The ATLAS experiment has accumulated data since 2009. It is important to maintain access to software for processing and analyzing historical data developed on outdated operating systems. Container technology plays an indispensable role in providing secure and operationally sound environments for building and testing on such operating systems. This document provides details on the organizational support for OS containers used in software building, including methods for setting up runtime environments.
The ATLAS experiment will undergo major upgrades for operation at the high luminosity LHC. The high pile-up interaction environment (up to 200 interactions per 40MHz bunch crossing) requires a new radiation-hard tracking detector with a fast readout.
The scale of the proposed Inner Tracker (ITk) upgrade is much larger than the current ATLAS tracker. The current tracker consists of ~4000 modules while ITk will be made of ~28,000 modules. To ensure a good production quality, all the items to build modules as well as bigger structures on which they will be placed need to be tracked along with the relevant quality control and quality assurance information. Hence, the ITk production database (PDB) is vital to follow the complex production flow for each item and institutes around the globe. The database also allows close monitoring of the production quality and production speed. After production the information will be stored for 10 years of data-taking to trace potential operational issues to specific production items.
A PDB API allows development of tools for database interaction by different user types: technicians, academics, engineers and vendors. Several options have been pursued to meet the needs by the collaboration: pythonic API wrapper, data-acquisition GUIs with integrated scripts, commandline scripts distributed via git repositories, containerised applications, and CERN hosted resources.
This presentation promotes information exchange and collaboration for tools which supports detector construction in a large-scale experiment. Examples of front-end development and reporting will be shown. Through these examples, the general themes of large-scale data management and multi-user global accessibility will be discussed. These concepts are relevant not only for modern high-energy particle physics (HEP) but also for large experiments beyond HEP.
XRootD is a robust, scalable service that supports globally distributed data management for diverse scientific communities. Within GridPP in the UK, XRootD is used by the Astronomy, High-Energy Physics (HEP) and other communities to access >100PB of storage. The optimal configuration for XRootD varies significantly across different sites due to unique technological frameworks and site-specific factors.
XRootD's adaptability has made it a cornerstone of the national data-management strategy for GridPP. Given its high-profile role, new releases, and features of XRootD undergo rigorous testing and verification before national deployment. Historically, this process involved manual integration testing and dedicated test deployments, which required substantial input from both local site administrators and remote support teams. This approach has placed considerable demands on support staff, requiring extensive technical expertise and significant time for verification.
To support the storage community within GridPP, we have developed a system that automates the deployment of a virtual grid using Kubernetes for XRootD testing, "XKIT". Using a container-based approach this system enables high-level integration tests to be performed automatically and reproducibly. This not only simplifies the support process but also significantly reduces the time staff need to dedicate to repetitive testing for new deployments.
We have identified >20 unique XRootD configurations necessary for XKIT. By deploying each of these setups on our platform, we aim to provide the GridPP community with a consistent suite of functional tests tailored to various site topologies.
This presentation will explore the development of the XKIT platform, discuss the challenges we encountered, and highlight the advantages this system offers to GridPP and the wider community.
For over two decades, the dCache project has provided open-source to satisfy ever-more demanding storage requirements. More than 80 sites around the world, rely on dCache to provide services for LHC experiments, Belle-II, EuXFEL and many others. This can be achieved only with a well-established process from a whiteboard, where ideas are created, through development, packaging and testing. The project's build and test infrastructure is based on Jenkins CI and a set of virtual machines. This infrastructure is maintained by dCache developers. With the introduction of the DESY-central Gitlab server, the developers have started migrating from VM-based testing to container-based deployments in the onsite Kubernetes cluster. As a result, we have packaged dCache containers and Helm charts that can be used by other sites to reproduce our test and build steps quickly or to evaluate new releases on their pre-production systems, and, eventually, become a standard model of dCache deployment at the sites.
This presentation will show challenges that we have faced, the techniques how they were solved and issues that still need to be addressed.
ROOT is an open source framework, freely available on GitHub, at the heart of data acquisition, processing and analysis of HE(N)P experiments, and beyond.
It is developed collaboratively: contributions are not authored only by ROOT team members, but also by a veritable nebula of developers and scientists from universities, labs as well as the private sector. More than 1500 GitHub Pull Requests are merged on average per year. It is in this context that code integration acquires a primary role: not only code contributions need to be reviewed, but they need to be thoroughly tested through a powerful CI infrastructure on several different platforms to comply with the high code quality standards of the project. Since the end of 2023, ROOT moved its continuous integration system from a Jenkins one to a GitHub Actions based one.
In this contribution, we characterise the transition to the GitHub CI, focussing our strategy, its implementation and the lesson learned, as well as the advantages the new system offers with respect to the previous one. Particular emphasis will be given to the evaluation of the cost-benefit ratio for Jenkins and GitHub Actions for the ROOT project. We’ll also describe how we manage to run in less than one hour thousands of unit, integration, functional and end-to-end tests on different flavours of Windows, four versions of macOS, as well as about ten of the most used Linux distributions, taking advantage of the CERN computing infrastructure.
Collaboration, Reinterpretation, Outreach and Education
The CMS experiment at the Large Hadron Collider (LHC) regularly releases open data and simulations, enabling a wide range of physics analyses and studies by the global scientific community. The recent introduction of the NanoAOD data format has provided a more streamlined and efficient approach to data processing, allowing for faster analysis turnaround. However, the larger MiniAOD format retains richer information that may be crucial for certain research endeavors.
To ensure the long-term usability of CMS open data to their full extent, this work explores the potential of leveraging public cloud resources for the computationally intensive processing of the MiniAOD format. Many open data users may not have access to the necessary computing resources for handling the large MiniAOD datasets. By offloading the heavy lifting to scalable cloud infrastructure, researchers can benefit from increased processing power and improved overall efficiency in their data analysis workflows, with a moderate short-term cost.
The study investigates best practices and challenges for effectively utilizing public cloud platforms to handle the processing of CMS MiniAOD data, with a focus on quantifying the overall time and cost of using these resources. The ultimate aim is to empower the CMS open data community to maximize the scientific impact of this valuable resource.
The Large Hadron Collider Beauty (LHCb) experiment offers an excellent environment to study a broad variety of modern physics topics. Its data from the major physics campaigns (Run 1 and 2) at the Large Hadron Collider (LHC) has accumulated over 600 scientific publications. In accordance with the CERN Open Data Policy, LHCb announced the release of the full Run 1 dataset gathered from proton-proton collisions, amounting to approximately 800 terabytes. The Run 1 data was released on the CERN Open Data portal in 2023. However, due to the large amount of data collected during Run 2, it is no longer feasible to make the reconstructed data accessible to the public in the same way.
We have, therefore, developed a new and innovative approach to publishing Open Data by means of a dedicated LHCb Ntupling Service which allows third-party users to query the data collected by LHCb and request custom samples in the same columnar data format used by LHCb physicists. These samples are called Ntuples and can be individually customized in the web interface using LHCb standard tools for saving measured or derived quantities of interest. The configuration output is kept in a pure data structure format (YAML) and is interpreted by internal parsers generating the necessary Python scripts for the LHCb Ntuple production job. In this way, the LHCb Ntupling Service serves as a gateway for third-party users for preparing custom Ntuple jobs eliminating the need for real-time interaction with the LHCb database and solving potential access control and computer security issues related to opening LHCb internal tools to the public.
The LHCb Ntupling Service was developed as a collaborative effort by LHCb and the CERN Open Data team from the CERN Department of Information Technology. The service consists of the web interface frontend allowing users to create Ntuple production requests, the backend application processing the user requests and storing them in the GitLab repositories, offering vetting capabilities to the LHCb Open Data team, and automatically dispatching user requests to the LHCb Ntuple production systems after the approval. The produced Ntuples are then collected and exposed back to the users by the frontend web interface.
This talk is a joint presentation by LHCb and CERN IT and will elaborate on the LHCb Ntupling Service system infrastructure as well as its typical use case scenarios allowing to query and study the LHCb open data.
ATLAS Open Data for Education delivers proton-proton collision data from the ATLAS experiment at CERN to the public along with open-access resources for education and outreach. To date ATLAS has released a substantial amount of data from 8 TeV and 13 TeV collisions in an easily-accessible format and supported by dedicated documentation, software, and tutorials to ensure that everyone can access and exploit the data for different educational objectives. Along with datasets, ATLAS also provides data visualisation tools and interactive web based applications for studying the data, along with Jupyter Notebooks and downloadable code enabling users to further analyse data for known and unknown physics cases. The Open Data educational platform which hosts the data and tools is used by tens of thousands of students worldwide, and we present the project development, lessons learnt, impacts, and future goals.
High Energy (Nuclear) Physics and Open Source are a perfect match with a long history. CERN has created an Open Source Program Office (CERN OSPO [1]) to help open-source hardware and software in the CERN community - for CERN staff and the experiments’ users. In the wider context, open source and CERN’s OSPO have key roles in CERN’s Open Science Policy [2]. With the OSPO, open-source projects should have more visibility inside and outside the organization, as contributions to society; the OSPO’s team of practitioners want to make open source at CERN an easier, obvious task.
This presentation will provide you with an overview of the mission and objectives of the CERN Open Source Program Office (OSPO). This contribution exposes how the OSPO can and needs to help, what the OSPO wants to achieve, and what an OSPO’s role might be in the HE(N)P software ecosystem. After more than a year in active engagement, we will share insights encountered so far, including the different challenges of open source in different parts of CERN. The presentation will share some behind-the-scenes stories: what the challenges were in creating it, what makes it special compared to other OSPOs, and why the OSPO won’t do some things you might expect it to do. We will present the initial set of technical recommendations (“best practices”) as proposed by the CERN OSPO; some alignment across institutions might be beneficial for the global HE(N)P community.
By sharing the CERN OSPO’s journey, challenges, and lessons learned, we hope to provide valuable insights relevant to other HE(N)P centers, open-source projects, and the wider open source community.
[1] https://opensource.cern/mandate
[2] https://openscience.cern/policies
The CERN Open Data Portal holds over 5 petabytes of high-energy physics experiment data, serving as a hub for global scientific collaboration. Committed to Open Science principles, the portal aims to democratize access to these datasets for outreach, training, education, and independent research.
Recognizing the limitations of current disk-based storage, we are starting a project to expand our data storage methodologies. Our approach involves integrating hot storage (such as spinning disks) for immediate data access and cold storage (such as tape, or even interfaces to the experiment frameworks) for cost-effective long-term preservation. This innovative strategy will significantly expand the portal’s capacity to accommodate more experiment data. However, we anticipate challenges in navigating technical complexities and logistical hurdles. These challenges include the latency to access cold data, monitoring and automatizing the transitions between hot and cold and ensuring the long-term preservation of data in the experiment frameworks. The strategy is to integrate existing solutions like EOS, FTS, CTA and Rucio.
In our presentation, we will discuss these challenges, present our prototype solution, and outline future developments aimed at enhancing the accessibility, efficiency, and resilience of the CERN Open Data Portal’s data ecosystem.
In recent years, there has been significant political and administrative interest in “Open Science”, which on one hand has lead to additional obligations but also to significant financial backing. For institutes and scientific collaborations, the funding opportunities may have brought some focus on these topics, but there is also a the significant hope, though engagement in open science infrastructure and culture, a possible multiplying effect on scientific output though the sharing of knowledge among and between scientists and citizens.
The Facility for AntiProton and Ion Research in Europe (FAIR) is a particle accelerator just outside Darmstadt in Germany, which is under final construction at a site adjacent to the GSI Helmholtz Centre for Heavy Ion Research. One of its five scientific pillars is the Compressed Baryonic Matter (CBM) experiment, which is now prioritised and expected to receive its first beam in 2028. For CBM, as a leading international scientific collaboration, an active open science policy is an imperative.
In this contribution, we outline our fully-formed policy towards “Open Software” and describe how we overcame difficulties to facilitate a F.A.I.R.-level of openness. We discuss the internally controversial issue of “Open Data” and the availability to technically test data policies at the prototype experiment mini-CBM, before application to our more important physics-rich data coming from our future world-class experiment. Lastly we discuss what it means to be an “Open Collaboration” and how engagement in open science strategy within the collaboration could facilitate a plethora of new citizen science projects and help progress our research and the open science agenda.
The poster will present FunRootAna library.
This is a simple framework allowing to do ROOT analysis in a more functional way. In comparison to RDFrame it offers more functional feel for the data analysis and can be used in any circumstances, not only with ROOT trees. Collections processing is inspired by Scala Apache Spark and the histograms creation and filling is much simplified. As consequence, a single line containing selection, data extraction & histogram definition is sufficient to obtain one unit of result.Basically, with FunRootAna the number of lines of analysis code per histogram is converging to 1. More here: https://tboldagh.github.io/FunRootAna/
The ATLAS detector produces a wealth of information for each recorded event. Standard calibration and reconstruction procedures reduce this information to physics objects that can be used as input to most analyses; nevertheless, there are very specific analyses that need full information from some of the ATLAS subdetectors, or enhanced calibration and/or reconstruction algorithms. For these use cases, a novel workflow has been developed that involves the selection of events satisfying some basic criteria, their extraction in RAW data format using the EventIndex data catalogue and the Event Picking Server, and their specialised processing. This workflow allows us in addition to commission and use new calibration and reconstruction techniques before launching the next full reprocessing (important given the longer and longer expected time between full reprocessing campaigns), to use algorithms and tools that are too CPU or disk intensive if run over all recorded events, and in the future to apply AI/ML methods that start from low-level information and could profit from rapid development/use cycles. This presentation describes the tools involved, the procedures followed and the current operational performance.
Beijing Spectrometer (BESIII) detector is used for high-precision studies of hadron physics and tau-charm physics. Accurate and reliable particle identification (PID) is crucial to improve the signal-to-noise ratio, especially for K/π separation. The time-of-flight (TOF) system, which is based on plastic scintillators, is a powerful tool for particle identification at BESIII experiment. The measured time is obtained using an empirical formula, which is used for time walk and hit position corrections, with Bhabha events used as calibration samples. Time difference is defined as the difference between the measured time and the expected time. Systematic time deviations of charged hadrons have been observed in the time differences for different particle species. This kind of systematic time deviation, which depends on the momentum and particle species, has been reported in several experiments using TOF based on plastic scintillation counters. Similar behaviors have also been observed in simulations with different deviations. In this study, the dependence of time deviations on pulse heights and hit positions is systematically investigated using different species of hadron control samples. By applying corrections to the measured time, the time deviations are substantially reduced to nearly zero. The PID efficiencies of hadrons are enhanced both for real data and MC samples, and the systematic uncertainties of PID efficiencies are also optimized with further tuning. This study offers a new perspective on investigating time deviation in scintillation TOF detectors and provides a reference for improving detection accuracy.
The future development projects for the Large Hadron Collider towards HL-LHC will constantly bring nominal luminosity increase, with the ultimate goal of reaching, e.g., a peak luminosity of $5 \cdot 10^{34} cm^{−2} s^{−1}$ for ATLAS and CMS experiments. This rise in luminosity will directly result in an increased number of simultaneous proton collisions (pileup), up to 200, that will pose new challenges for track reconstruction in such a dense environment.
In response to these challenges, many experiments have started rewriting an increasing fraction of their track reconstruction software to run on heterogeneous architectures. While very successful in some cases, most of the time these efforts have stayed confined to single experiment projects.
In this work we will show the potentiality of a unique standalone software, running on multiple backends (CPUs, NVIDIA GPUs and AMD GPUs) aiming at the reconstruction of the tracker detector of multiple HEP experiments with a cylindrical geometry. We will discuss both the physics and computational performance for different detectors.
This represents the first step towards a unique standalone tool capable of carrying out the reconstruction of a model detector for HL-LHC leveraging on heterogeneous resources. A detector defined solely by its constituent elements: a silicon tracker, at least one calorimeter and a muon detector.
Vector is a Python library for 2D, 3D, and Lorentz vectors, especially arrays of vectors, to solve common physics problems in a NumPy-like way. Vector currently supports creating pure Python Object, NumPy arrays, and Awkward arrays of vectors. The Object and Awkward backends are implemented in Numba to leverage JIT-compiled vector calculations. Furthermore, vector also supports JAX and Dask operations on Awkward arrays of vectors.
We introduce a new SymPy backend in vector to allow symbolic computations on high energy physics vectors. Along with experimental physicists using vector for numerical computations, the SymPy backend will enable theoretical physicists to utilize the library for symbolic computations. Since the SymPy vector classes and their momentum equivalents operate on SymPy expressions, all of the standard SymPy methods and functions work on the vectors, vector coordinates, and the results of operations carried out on vectors. Moreover, vector’s SymPy backend will create a stronger connection between software used by experimentalists and software used by theorists.
This talk will introduce vector and its backends to the users and funnel down to the SymPy backend. Finally, vector’s SymPy backend is relatively new; hence, we aim to collect suggestions and recommendations from both theoretical and experimental physicists.
New strategies for the provisioning of compute resources, e.g. in the form of dynamically integrated resources enabled by the COBalD/TARDIS software toolkit, require a new approach of collecting accounting data. AUDITOR (AccoUnting DatahandlIng Toolbox for Opportunistic Resources), a flexible and expandable accounting ecosystem that can cover a wide range of use cases and infrastructures, was developed specifically for this purpose. Accounting data is collected via so-called collectors and stored in a database. So-called plugins can access the data and act based on the accounting information. Access to the data is handled by the core component of AUDITOR, which provides a REST API together with a Rust and a Python client library.
An HTCondor collector, a Slurm collector and a TARDIS collector are currently available, and a Kubernetes collector is already in the works.
The APEL plugin enables, for example, the creation of APEL accounting summaries and their transmission to the APEL accounting server. Although the original aim of the development of AUDITOR was to enable the accounting of opportunistic resources managed by COBalD/TARDIS, it can also be used for standard accounting of a WLCG computing resource. As AUDITOR uses a highly flexible data structure to store accounting data, extensions such as GPU resource accounting can be added with minimal effort.
This contribution provides insights into the design of AUDITOR and shows how it can be used to enable a number of different use cases.
The aim of this paper is to give an overview of the progress made in the EOS project - the large scale data storage system developed at CERN - during the preparation and during LHC Run-3. Developments consist of further simplification of the service architecture, metadata performance improvements, new memory inventory and cost & value interfaces, a new scheduler implementation, a generated REST API derived from the GRPC protocol, and new or better integration of features such as SciTags and SciTokens. We will report on operational experiences and the massive migration process to ALMA9, improvements in the quality assurance process and results achieved. Looking to the future, we will describe the development and evolution of EOS for Run-4 and highlight various software R&D and technology evaluation activities (e.g. SMR support) that have the potential to help realize the Run-4 requirements for physics storage at CERN and elsewhere.
The CMS Experiment at the CERN Large Hadron Collider (LHC) relies on a Level-1 Trigger system (L1T) to process in real time all potential collisions, happeing at a rate of 40 MHz, and select the most promising ones for data acquisition and further processing. The CMS upgrades for the upcoming high-luminosity LHC run will vastly improve the quality of the L1T event reconstruction, providing opportunities for a complementary Data Scouting approach where physics analysis is performed on a data stream containing all collisions but limited to L1T reconstruction. This poster describes the future Data Scouting system, some first estimates of its physics capabilities, and the demonstration setups used to assess its technical feasibility.
The CMS experiment has recently established a new Common Analysis Tools (CAT) group. The CAT group implements a forum for the discussion, dissemination, organization and development of analysis tools, broadly bridging the gap between the CMS data and simulation datasets and the publication-grade plots and results. In this talk we discuss some of the recent developments carried out in the group, including the structure of the group, the facilities and services provided, the communication channels, the ongoing developments in the context of frameworks for data processing, strategies for the management of analysis workflows and their preservation and tools for the statistical interpretation of analysis results.
The recently approved SHiP experiment aims to search for new physics at the intensity frontier, including feebly interacting particles and light dark matter, and perform precision measurements of tau neutrinos.
To fulfill its full discovery potential, the SHiP software framework is crucial, and faces some unique challenges due to the broad range of models under study, and the extreme statistics necessary for the background studies. The SHiP environment also offers unique opportunities for machine learning for detector design and anomaly detection.
This poster will give an overview of the general software framework and of past, ongoing and planned simulation and machine learning studies.
Data analysis in the field of High Energy Physics presents typical big data requirements, such as the vast amount of data to be processed efficiently and quickly. The Large Hadron Collider in its high luminosity phase will produce about 100 PB/year of data, ushering in the era of high precision physics. Currently, analysts are building and sharing their software on git-based platforms which improve reproducibility and offer a high level of workflow automatization. On the other hand, it’s becoming more and more critical to complement this aspect with an easy and user-friendly access to distributed resources for CPU-intensive calculations. In this talk, it will be shown how it is possible to enable Continuous Integration (CI) with CMS datasets by using the XRootD IO protocol and dynamic proxy generation and, in combination with the GitLab CI/CD functionalities, how to trigger an analysis execution with a simple commit. By using dynamic auth access tokens it’s possible to offload all the CPU-heavy work from the gitlab workers to on-demand computing resources: from regional CMS Tier-2 resources to the national-wide datalake model currently under deployment within the ICSC (the italian national center for research in HPC, big data and quantum computing) project. Thanks to this alternative approach, in particular, integrating the submission of jobs to HTCondor into the gitlab CI will become easier, automatising the handling of big datasets. In this way analysts will be able to quickly run different tests on their data, perform different analyses in parallel and, at the same time, keep tracks of all the changes made.
The BESIII experiment operates as an electron-positron collider in the tau-charm energy region, pursuing a range of physics goals related to charm, charmonium, light hadron decays, and so on. Among these objectives, achieving accurate particle identification (PID) plays a crucial role, ensuring both high efficiency and low systematic uncertainty. In the BESIII experiment, PID performance heavily relies on two key measurements: the energy deposit per unit length (dE/dx) obtained from the main drift chamber (MDC) sub-detector, and the time of flight (TOF) measurement from the TOF sub-detector.
This contribution focuses specifically on the dE/dx aspect and provides a comprehensive overview of the dE/dx software employed in the BESIII experiment. The presentation encompasses simulation, calibration, and reconstruction techniques implemented in the analysis pipeline. Last but not least, with the help of machine learning (ML) technique, a study of ML-based dE/dx simulation will also be presented.
A modern version control system is capable of performing Continuous Integration (CI) and Continuous Deployment (CD) in a safe and reliable manner. Many experiments and software projects of High Energy Physics are now developing based on such modern development tools, GitHub for example. However, refactoring a large-scale running system can be challenging and difficult to execute. This is the reason why the BES Offline Software System (BOSS) continues to be developed using an outdated version control system, specifically, Concurrent Versions System (CVS). CVS does not automatically check the committed code during the commit process. To address this issue, a new auto-validation system has been developed, which overrides parts of the 'cvs' subcommand, enabling automatic code checks immediately after committing. Besides, with the integration of Gitlab, it includes functions designed for the convenience of developers and system managers, allowing them to work on multiple tasks simultaneously and automatically collects validated code. This approach strikes a balance between stability and innovation, allowing developers and system managers to enjoy the benefits of a modern-like version control system without having to much alter their work habits. The system is currently in use for the development and maintenance of BOSS.
Users may have difficulties to find the needed information in the documentation for products, when many pages of documentation are available on multiple web pages or in email forums. We have developed and tested an AI based tool, which can help users to find answers to their questions. The Docu-bot uses Retrieval Augmentation Generation solution to generate answers to various questions. It uses github or open gitlab repositories with documentation as a source of information. Zip files with documentation in a plain text or markdown format can also be used for input. Sentence transformer model and Large Language Model generate answers.
Different LLM models can be used. For performance reasons, in most tests we use the model Mistral-7B-Instruct-v0.2, which fits into the memory of the Nvidia T4 GPU. We have also tested a larger model Mixtral-8x7B-Instruct-v0.1, which requires more GPU memory, available for example on Nvidia A100, A40 or H100 GPU cards. Another possibility is to use the API of OpenAI models like gpt-3.5-turbo, but the user has to provide his/her own API access key to cover expenses.
EDM4hep aims to establish a standard event data model for the store and exchange of event data in HEP experiments, thereby fostering collaboration across various experiments and analysis frameworks. The Julia package EDM4hep.jl is capable of generating Julia-friendly structures for the EDM4hep data model and reading event data files in ROOT format (either TTree or RNTuple) that are written by C++ programs, utilising the UnROOT.jl package. This paper explores the motivations behind the primary design choices of this package, such as the exclusive use of structure of arrays (SoA) to access the stored collections, which then empower users to develop ergonomic data analyses using Julia’s high-level concepts and functionality, while maintaining performance comparable to C++ programs. Several examples are given to illustrate how efficient data analysis can be achieved using high-level objects, eliminating the need to resort to flat n-tuples.
2024 marks not just CERN’s 70th birthday but also the end of analogue telephony at the laboratory. Traditional phone exchanges and the associated copper cabling cannot deliver 21st-century communication services and a decade-long project to modernize CERN’s telephony infrastructure was completed earlier this year.
We report here on CERN’s modern fixed telephony infrastructure, firstly our in-house development of an exchange which, based on open-source components and standard VoIP protocols, supports softphones, call centers, safety communications, interconnections with other voice services and an automatic switchboard, and secondly the two CERNphone applications that have replaced fixed phones, and which are used by more than 6000 users each week.
The dCache storage management system at Brookhaven National Lab plays a vital role as a disk cache, storing extensive datasets from high-energy physics experiments, mainly the ATLAS experiment. Given that dCache’s storage is significantly smaller than the total ATLAS data, it’s crucial to have an efficient cache management policy. A common approach is to keep files that are accessed often, ready for future use. In our research, we analyze both recent and past patterns of file usage to predict the chances of them being needed again. Although dCache considers each file separately, we’ve observed that files within a dataset tend to be used together. Therefore, the system manager often gets requests to retain entire datasets in the cache, especially if they’re expected to be in high demand soon. Our main focus is to determine if we could accurately forecast a dataset’s future demand to automate the process of deciding which datasets to prioritize in the cache.
Our approach’s cornerstone is a dynamic learning mechanism that regularly analyzes recent access logs. This process updates our machine learning models, enabling them to forecast the popularity of various datasets shortly. Specifically, our predictive model estimates the expected number of accesses for each dataset in the upcoming days. We then synchronize these predictions with the cache space allocated for monitoring sought-after datasets. This allows us to proactively load the most in-demand datasets into the disk cache. This strategic reservation method operates in conjunction with the current file removal policy, collectively improving the overall efficiency of the system.
To develop a predictive model for our caching system, we assessed several techniques and metrics to distinguish popular datasets from less popular ones effectively. Employing k-means clustering, we categorized datasets based on their popularity and explored diverse methods to precisely measure dataset usage. Given our constrained disk space, our aim was to optimize the selection of retained datasets, thereby improving cache efficiency.
Prior study [1] has demonstrated the feasibility of detecting popular datasets using a machine learning approach. In this study, we compare the predictive efficacy of two distinct models: a neural network model and a gradient-boosted trees regression model (XGBoost). The models, configured with 17 input variables, are trained on 127 million data points, collected over a span of three years from our data processing pipeline. Additionally, both models underwent hyperparameter tuning via Optuna, conducted on Perlmutter at NERSC.
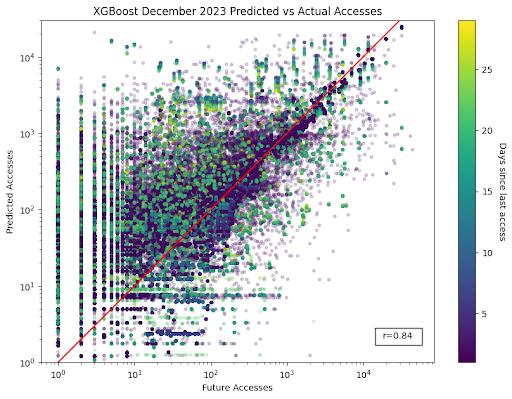
Fig. 1. December 2023 comparison of predicted and actual dataset accesses using XGBoost. Axes represent next-day actual (x) vs. predicted (y) accesses. Points are colored based on the recency of last access, with lighter points indicating predictions are made with older data records. The red diagonal line indicates perfect predictions. A high correlation coefficient (0.84) reflects strong prediction accuracy, especially at higher access counts.
Despite the inherent difficulty in forecasting future dataset accesses, our models showed promising performance. Notably, the XGBoost model displayed a lower root mean squared error (RMSE) for testing datasets compared to the neural network. Specifically, the relative ratios of testing RMSE to standard deviation were 0.28 for XGBoost and 0.84 for the neural network models.
Our research confirms that predicting dataset popularity is feasible through careful analysis of data features and the application of well-designed models. While the real-world application of these models in live caching policies requires further testing, our study underscores the potential of machine learning in improving dCache systems. Future endeavors will concentrate on implementing, benchmarking, and validating the efficacy of these proposed methods.
REFERENCES
[1] J. Bellavita, C. Sim, K. Wu, A. Sim, S. Yoo, H. Ito, V. Garonne, and E. Lancon, "Understanding data access patterns for dcache system," in 26th International Conference on Computing in High Energy & Nuclear Physics (CHEP2023), 2023.
How to effectively and efficiently stage a large number of requests from an IBM HPSS environment using a MariaDB database to keep track of requests and use Python for all business logic and to consume the HPSS API. The goal is to be able to scale to handle a large number of requests and to meet different needs of different experiments, and to make the program adaptable enough to allow for each experiment to have its own unique business logic. This update will take advantage of features of the newest versions of HPSS, as well as MariaDB, Python, and Linux. Furthermore, the hope is that the application will be able to log and handle a wider array of errors and exceptions, and allow for more in depth monitoring as the status of each request will be stored in a database which allows for easy querying. Furthermore this may allow for additional enhancements such as staging requests by priority.
The interTwin project, funded by the European Commission, is at the forefront of leveraging 'Digital Twins' across various scientific domains, with a particular emphasis on physics and earth observation. One of the most advanced use-cases of interTwin is event generation for particle detector simulation at CERN. interTwin enables particle detector simulations to leverage AI methodologies on cloud to high-performance computing (HPC) resources by using itwinai - the AI workflow and method lifecycle module of interTwin.
The itwinai module, a comprehensive solution for AI workflow and method lifecycle developed collaboratively by CERN and the Julich Supercomputing Center (JSC), serves as the cornerstone for researchers, data scientists, and software engineers engaged in developing, training, and maintaining AI-based methods for scientific applications, such as the particle event generation. Its role is advancing interdisciplinary scientific research through the synthesis of learning and computing paradigms. This framework stands as a testament to the commitment of the interTwin project towards co-designing and implementing an interdisciplinary Digital Twin Engine. Its main functionalities and contributions are:
Distributed Training: itwinai offers a streamlined approach to distributing existing code across multiple GPUs and nodes, automating the training workflow. Leveraging industry-standard backends, including PyTorch Distributed Data Parallel (DDP), TensorFlow distributed strategies, and Horovod, it provides researchers with a robust foundation for efficient and scalable distributed training. The successful deployment and testing of itwinai on JSC's HDFML cluster underscore its practical applicability in real-world scenarios.
Hyperparameter Optimization: One of the core functionalities of itwinai is its hyperparameter optimization, which plays a crucial role in enhancing model accuracy. By intelligently exploring hyperparameter spaces, itwinai eliminates the need for manual parameter tuning. The functionality, empowered by RayTune, contributes significantly to the development of more robust and accurate scientific models.
Model Registry: A key aspect of itwinai is its provision of a robust model registry. This feature allows researchers to log and store models along with associated performance metrics, thereby enabling comprehensive analyses in a convenient manner. The backend, leveraging MLFlow, ensures seamless model management, enhancing collaboration and reproducibility.
In line with the “Computing infrastructure” track of CHEP 2024, interTwin and its use-cases empowered by itwinai are positioned at the convergence of computation and physics and showcase the significant potential of AI research supported by HPC resources. Together, they contribute to a narrative of interconnected scientific frontiers, where the integration of digital twins, AI frameworks, and physics research broadens possibilities for exploration and discovery through itwinai’s user-friendly interface and powerful functionalities.
In conclusion, itwinai is a valuable and versatile resource, empowering researchers and scientists to embark on collaborative and innovative scientific research endeavors across diverse domains. The integration of physics-based digital twins and AI frameworks broadens possibilities for exploration and discovery through itwinai's user-friendly interface and powerful functionalities.
Machine Learning (ML)-based algorithms play increasingly important roles in almost all aspects of data processing in the ATLAS experiment at CERN. Diverse ML models are used in detector simulation, event reconstruction, and data analysis. They are being deployed in the ATLAS software framework, Athena. Our primary approach to perform ML inference in Athena is to use ONNXRuntime. ONNXRuntime is a cross-platform ML model acceleration library, with a flexible interface to integrate hardware-specific libraries. In this talk, we will describe the ONNXRuntime interface in Athena and the impact of advanced ONNXRuntime settings on various ML models and workflows at ATLAS.
CMS Analysis Database Interface (CADI) is a management tool for physics publications in the CMS experiment. It acts as a central database for the CMS collaboration, keeping track of the various analysis projects being conducted by researchers. Each analysis paper written by the authors goes through an extensive journey from early analysis to publication. There are various stakeholders involved in that process who can provide their comments/feedback and may be involved in the approval/disapproval process of the analysis. Front End Engine for Glance (FENCE) is a technology developed by the UFRJ team that emerged to unify and facilitate the development of UFRJ-CERN collaboration systems. It allows system interfaces to be created by simply editing a configuration file in JSON, without the need for deep programming knowledge of users and changing the system's internal source code. Thus, the current system of ATLAS experiment, which uses the Glance technology in its foundation and FENCE as an abstraction layer above, is developed, allowing users to access the heterogeneous data sources related to the experiments in a simple and efficient way. Originally developed by ATLAS, it was recently redesigned by LHCb following a more modular architecture – splitting the code base in a PHP based RestAPI backend and a VueJS based frontend service – and this version was also adopted for use in the LHCb and Alice experiments. CMS decided to migrate CADI to the new version of the FENCE system. For CMS, two subsystems of the FENCE system are initially considered: the “membership” and “analysis life cycle management” (ALCM). The membership subsystem is a prerequisite of ALCM. It contains information on members, institutes, authorships, and various reports. In contrast, the ALCM subsystem is primarily used for the management of publication workflows like CADI. In this talk, we’ll describe the procedure that we followed to migrate CADI to FENCE. We encountered various issues during this process and will report the lessons learned while doing this migration so that other experiments in future will not have to undergo these issues if they migrate their system to FENCE.
Graph neural networks (GNN) have emerged as a cornerstone of ML-based reconstruction and analysis algorithms in particle physics. Many of the proposed algorithms are intended to be deployed close to the beginning of the data processing chain, e.g. in event reconstruction software of running and future collider-based experiments. For GNN to operate, the input data are represented as graphs. The creation of the graphs and the associated cost are often limiting factors in high-throughput production environments. We discuss the specific example of charged-particle track reconstruction in the ATLAS detector. The HL-LHC upgrade of the ATLAS detector brings an unprecedented track reconstruction challenge, both in terms of the large number of silicon hit cluster readouts, and the throughput required. The GNN4ITk project has designed GNN-based algorithms for tracking with a similar level of physics performance to traditional techniques, that scale sub-quadratically, provided that the large input graphs can be created efficiently. In this contribution, we present novel methods that are able to produce these graphs quickly and efficiently, and describe their computing performance.
Monte Carlo (MC) simulations are a crucial component when analysing the Standard Model and New physics processes at the Large Hadron Collider. The goal of this work is to explore the performance of generative models for complementing the statistics of classical MC simulations in the final stage of data analysis by generating additional synthetic data that follows the same kinematic distributions for a limited set of analysis-specific observables to a high precision. A normalizing flow architecture was adapted for this task and its performance was systematically evaluated using a well-known benchmark sample containing the Higgs boson production beyond the Standard Model and the corresponding irreducible background. The applicability of normalizing flows under different model parameters and a restricted number of initial events used in training was investigated. The best performing model was then chosen for further evaluation with a set of statistical procedures and a simplified physics analysis. We demonstrate that the the number of events used in training coupled with the flow architecture are crucial for the physics performance of the generative model. By implementing and performing a series of statistical tests and evaluations we show that a machine-learning-based generative procedure can can be used to generate synthetic data that matches the original samples closely enough and that it can therefore be incorporated in the final stage of a physics analysis with some given systematic uncertainty.
In response to increasing data challenges, CMS has adopted the use of GPU offloading at the High-Level Trigger (HLT). However, GPU acceleration is often hardware specific, and increases the maintenance burden on software development. The Alpaka (Abstraction Library for Parallel Kernel Acceleration) portability library offers a solution to this issue, and has been implemented into the CMS software (CMSSW) for use online at HLT.
A portion of the final-state particle candidate reconstruction algorithm, Particle Flow, has been ported to Alpaka and deployed at HLT for 2024 data taking. The formation of hadronic Particle Flow clusters represented a target for increased performance through parallel operation. We will discuss the port of hadronic Particle Flow clustering to Alpaka, and the validation of physics and performance at HLT.
With the upcoming upgrade of High Luminosity LHC, the need for computation
power will increase in the ATLAS trigger system by more than an order of
magnitude. Therefore, new particle track reconstruction techniques are explored
by the ATLAS collaboration, including the usage of Graph Neural Networks (GNN).
The project focusing on that research, GNN4ITk, considers several heterogeneous
computing options, including the usage of Graphics Processing Units (GPU). The
framework can reconstruct tracks with high efficiency, however, the computing
requirements of the pipeline are high. We will report on the efforts to reduce
the memory consumption and inference time enough to enable the usage of
commercially available and affordable GPUs for the future ATLAS trigger system
while maintaining high tracking performance.
The escalating demand for data processing in particle physics research has spurred the exploration of novel technologies to enhance efficiency and speed of calculations. This study presents the development of a porting of MADGRAPH, a widely used tool in particle collision simulations, to FPGA using High-Level Synthesis (HLS).
Experimental evaluation is ongoing, but preliminary assessments suggest a promising enhancement in calculation speed compared to traditional CPU implementations. This potential improvement could enable the execution of more complex simulations within shorter time frames.
This study describes the complex process of adapting MADGRAPH to FPGA using HLS, focusing on optimizing algorithms for parallel processing. A key aspect of the FPGA implementation of the MADGRAPH software is reduction of the power consumption, which important implications for the scalability of computer centers and for the environment. These advancements could enable faster execution of complex simulations, highlighting FPGA's crucial role in advancing particle physics research and its environmental impact.
Deep sets network architectures have useful applications in finding
correlations in unordered and variable length data input, thus having the
interesting feature of being permutation invariant. Its use on FPGA would open
up accelerated machine learning in areas where the input has no fixed length or
order, such as inner detector hits for clustering or associated particle tracks
for jet tagging. We adapted DIPS (Deep Impact Parameter Sets), a deep sets
neural network flavour tagging algorithm previously used in ATLAS offline
low-level flavour tagging and online b-jet trigger preselections, for use on
FPGA with the aim to assess its performance and resource costs. QKeras and
HLS4ML are used for quantisation-aware training and translation for FPGA
implementation, respectively. Some challenges are addressed, such as finding
replacements for functionality not available in HLS4ML (e.g. Time Distributed
layers) and implementations of custom HLS4ML layers. Satisfactory
implementations are tested on an actual FPGA board for the assessment of true
resource consumption and latency. We show the optimal FPGA-based algorithm
performance relative to CPU-based full precision performance previously
achieved in the ATLAS trigger, as well as performance trade-offs when reducing
FPGA resource usage as much as possible. The project aims to demonstrate a
viable solution for performing sophisticated Machine Learning-based tasks for
accelerated reconstruction or particle identification for early event rejection
while running in parallel to other more intensive tasks on FPGA.
Simulation of the detector response is a major computational challenge in modern High-Energy Physics experiments, accounting for about 40% of the total computational resources used in ATLAS. The simulation of the calorimeter response is particularly demanding, consuming about 80% of the total simulation time.
In order to make the best use of the available computational resources, fast simulation tools based on Machine Learning techniques have been developed to simulate the calorimeter response faster than Geant4 while maintaining a high level of accuracy. One such tool, developed by the ATLAS Collaboration and currently in production for LHC Run 3, is FastCaloGAN, which uses Generative Adversarial Networks (GANs) to generate electromagnetic and hadronic showers.
To facilitate the training and optimisation of the GANs, and to enable a more efficient use of computational resources, a container-based system, FastCaloGANtainer, facilitates the deployment of the FastCaloGAN training on complementary high-performance resources such as High Performance Computing (HPC) farms and ensures its operational independence from the underlying system.
This talk presents the latest developments in FastCaloGAN and FastCaloGANtainer, discussing their technical details and recent improvements in terms of Physics and computational performance. For FastCaloGAN, these improvements include an improved voxelisation and extension to further use cases (e.g. particle types not yet covered), while for FastCaloGANtainer they concern its deployment on a wider variety of resources with multi-CPU/GPU nodes and different architectures (including cutting-edge HPC clusters such as Leonardo at CINECA in Bologna, Italy).
GitLab Runners have been deployed at CERN since 2015. A GitLab runner is an application that works with GitLab Continuous Integration and Continuous Delivery (CI/CD) to run jobs in a pipeline. CERN provides runners that are available to the whole GitLab instance and can be used by all eligible users. Until 2023, CERN was providing a fixed amount of Docker runners executing in OpenStack virtual machines, following an in-house, customized solution that utilized the Docker+machine executor. This solution served its purpose for several years, however needed to be reviewed due to the deprecation by Docker Inc., and only a fork maintained by GitLab Inc.
During the last few years, the demand and the number of running pipelines have substantially increased, as the adoption of Continuous Integration and Delivery has been rapidly growing.
In view of the above, CERN needed to provide a supported, scalable infrastructure that would accommodate our users' demand.
This paper describes the process of how CERN migrated from the legacy in-house solution to a new scalable, reliable and easy-to-maintain solution of runners based on Kubernetes, including the challenges and lessons learned that have been faced during this complex migration process.
Amazon S3 is a leading object storage service known for its scalability, data reliability, security and performance. It is used as a storage solution for data lakes, websites, mobile applications, backup, archiving and more. With its management features, users can optimise data access to meet specific requirements and compliance standards. Given its popularity, many tools utilise the S3 interfaces. To enhance CERN’s EOS Big Data storage, we are integrating an S3 interface into XRootD that is customised for EOS. This article describes the design, progress and future plans for the integration of the S3 API.
Since 2016, CERN has been using the OpenShift Kubernetes Distribution to host a platform-as-a-service (PaaS). This service is optimized for hosting web applications and has grown to tens of thousands of individual websites. By now, we have established a reliable framework that deals with varied use cases: thousands of websites per ingress controller (8K+ hostnames), handling with long-lived connections (30K+ concurrent sessions) and high traffic applications (25TB+ per day).
This session will discuss:
Reinforcement Learning is emerging as a viable technology to implement autonomous beam dynamics setup and optimization in particle accelerators. A Deep Learning agent can be trained to efficiently explore the parameter space of an accelerator control system and converge to the optimal beam setup much faster than traditional methods. Training these models requires programmatic execution of a high volume of simulations. This contribution introduces pytracewin, a Python wrapper of the TraceWin beam dynamics simulator, which exposes simple methods to run simulations and retrieve results. It can be easily combined with the large Python ecosystem of Machine Learning and Reinforcement Learning libraries to develop optimization models. Still, the training process is computationally constrained by the number of simulations that can be run in a reasonable time. It is thus crucial to scale such workload on a dedicated computing infrastructure while retaining a simple high-level user interface.
We exploit Ray, an open-source library, to enable embarrassingly parallel execution of TraceWin simulations on Kubernetes, using a dynamically scalable number of workers and requiring minimal user code modifications. Workers are instantiated with a custom docker image combining Ray and pytracewin. The approach is validated using two Kubernetes clusters on INFN Cloud and CloudVeneto to simulate the ADIGE beam line at Legnaro National Laboratories.
In ATLAS and other high-energy physics experiments, the integrity of Monte-Carlo (MC) simulations is crucial for reliable physics analysis. The continuous evolution of MC generators necessitates regular validation to ensure the accuracy of simulations. We introduce an enhanced validation framework incorporating the Job Execution Monitor (JEM) resulting in the established Physics Modeling Group (PMG) Architecture for Validating Evgen with Rivet (PAVER). This setup automates the validation process, facilitating systematic evaluation of MC generator updates and their compliance with experimental data.
This approach allows for early detection of discrepancies in simulation outputs, ensuring that potential issues and bugs are addressed before the production of large-scale samples for the ATLAS collaboration. MC generator Validation is specially imoprtant to save energy and money and to reduce the carbon footprint in future simulation campaigns significantly which aligns very well with the importance of reaching sustainability within ATLAS. The result is a streamlined, robust, and accessible validation system that supports sustainable MC production in ATLAS.
This presentation will summarize the implementation of PAVER by highlighting its impact on enhancing simulation reliability and efficiency. It will furthermore include an overview of the massive validation program throughout the past years resulting in many successfully validated generator and software updates. In addition, this talk will present insights into the challenges and solutions in MC generator validation, with implications for future developments in high-energy physics simulations.
The Jiangmen Underground Neutrino Observatory (JUNO), located in Southern China, is a multi-purpose neutrino experiment that consists of a central detector, a water Cherenkov detector and a top tracker. The primary goal of the experiment is to determine the neutrino mass ordering (NMO) and precisely measure neutrino oscillation parameters. The central detector contains 20,000 ton liquid scintillator and is instrumented with 17,612 20-inch PMTs and 25,600 3-inch PMTs for anti-neutrino detection with an energy resolution of 3% at 1MeV. The electronics simulation is the crucial module of JUNO offline software (JUNOSW). It takes the photoelectron information from Geant4 based detector simulation as input to simulate the PMT response, trigger logic and electronics response of sub-detectors using an implementation based on SNiPER managed dynamically- loadable elements(DLE). Electronics simulation incorporates a “hit-level” event mixing implementation which combines different event types with different rates that mimic the data streaming of real experimental data. The event mixing uses a “pull” based workflow using SNiPER incident schema. The electronics simulation outputs become inputs to the online event classification algorithms (OEC) used for event tagging and then saved to file using ROOT I/O services. In this talk, a detailed introduction of the electronics simulation software will be presented.
The ATLAS experiment at the LHC at CERN uses a large, distributed trigger and
data acquisition system composed of many computing nodes, networks, and
hardware modules. Its configuration service is used to provide descriptions of
control, monitoring, diagnostic, recovery, dataflow and data quality
configurations, connectivity, and parameters for modules, chips, and channels
of various online systems, detectors, and the whole ATLAS experiment. Those
descriptions have historically been stored in more than one thousand
interconnected XML files, which are updated by various experts many times per
day. Maintaining error-free and consistent sets of such files and providing
reliable and fast access to current and historical configurations is a major
challenge. This paper gives details of the configuration service upgrade on the
modern git version control system backend for LHC Run 3 and its exploitation
experience. It may be interesting for developers using human-readable file
formats, where consistency of the files, performance, access control,
traceability of modifications, and effective archiving are key requirements.
The LHCb detector, a multi-purpose detector with a main focus on the study of hadrons containing b- and c-quarks, has been upgraded to enable precision measurements at an instantaneous luminosity of $2\times10^{33}cm^{-2}s^{-1}$ at $\sqrt{s}=14$ TeV, five times higher than the previous detector capacity. With the almost completely new detector, a software-only trigger system has been developed and all track reconstruction algorithms have been redesigned.
The knowledge of the track reconstruction efficiency at different momenta and regions of the detector is essential for many analyses including cross-section and asymmetry measurements. A tag-and-probe method is developed to estimate the tracking efficiency using muonic tracks from $J/\psi\rightarrow\mu^+\mu^-$ decays, where the probe tracks are reconstructed excluding hits from the tracking subdetectors under scrutinity.
A complementary method is exploited to address tracking efficiency corrections due to the hadronic interactions with the detector material using pions from $D^0\rightarrow K\pi$ and $D^0\rightarrow K\pi\pi\pi$ decays. In this talk, these data-driven methods and their applications to the data taken in 2023 and 2024 are presented.
CERNBox is an innovative scientific collaboration platform, built using solely open-source components to meet the unique requirements of scientific workflows. Used at CERN for the last decade, the service satisfies the 35K users at CERN and seamlessly integrates with batch farms and Jupyter-based services. Powered by Reva, an open-source HTTP and gRPC server written in Go, CERNBox has demonstrated the provision of Sync&Share capabilities on top of multiple storage systems such as EOS and CephFS, as well as enabling federated sharing with other institutions.
In this contribution, we present the evolution of CERNBox in supporting CephFS, which has been chosen as the storage system to address the Windows applications use-cases at CERN. As we are migrating out of DFS, the legacy Windows storage provided by Microsoft, and commissioning Windows Workspaces powered by CephFS, we show how CERNBox provides a flexible software stack to seamlessly integrate the Windows-based community, which includes the Engineering sector of the Organization.
We conclude by emphasizing the multiple synergies enabled by this approach. On one hand, Windows-based data-centric workflows can leverage the multi-protocol accesses (sync, web, SMB) provided by CERNBox. On the other hand, the widespread adoption of CephFS within the scientific community positions CERNBox as an out-of-the-box solution for implementing a scalable collaborative cloud storage service.
LUX-ZEPLIN (LZ) is a dark matter direct detection experiment. Employing a dual-phase xenon time projection chamber, the LZ experiment set a world leading limit for spin-independent scattering at 36 GeV/c2 in 2022, rejecting cross sections above 9.2×10−48 cm2 at the 90% confidence level. Unsupervised machine learning methods are indispensable tools in working with big data, and have been applied at various stages of LZ analysis for data exploration and anomaly detection. In this work, we discuss an unsupervised dimensionality reduction approach applied to a combination of both PMT waveforms and reconstructed features aiming to identify anomalous events. We examine the tradeoffs in this method, and compare our results to known anomalies in the data, as well as conventional data quality cuts.
The main reconstruction and simulation software framework of the ATLAS
experiment, Athena, underwent a major change during the LHC Run 3 in the way
the configuration step of its applications is performed. The new configuration
system, called ComponentAcumulator, emphasises modularity and provides a way
for standalone execution of parts of a job, as long as the inputs are
available, which allows unit-testing of individual components or groups of
components, as well as easier debugging.
The switch to the new configuration system of the High-Level Trigger (HLT)
software, which utilises Athena algorithms for object reconstruction and
hypothesis testing, required designing a special approach to prevent disruption
of data taking during the code migration to ComponentAccumulator. An additional
challenge is brought by a large amount of HLT chains, where in many cases
copies of the same algorithm with varying configurations are used, which
significantly increases the number of configured parameters compared to offline
reconstruction jobs.
This report describes migration of the HLT software to ComponentAccumulator
along with further improvements in the data acquisition introduced for Run 3
data taking.
Data and Metadata Organization, Management and Access
ATLAS is participating in the WLCG Data Challenges, a bi-yearly program established in 2021 to prepare for the data rates of the High Luminosity HL-LHC. In each challenge, transfer rates are increased to ensure preparedness for the full rates by 2029. The goal of the 2024 Data Challenge (DC24) was to reach 25% of the HL-LHC expected transfer rates, with each experiment deciding how to execute the challenge based on agreed general guidelines and common dates. The ATLAS challenge was designed to test the ATLAS distributed infrastructure across 66 sites and was carried out over 12 days, with increasing rates and more complex transfer topologies, putting significant strain on the system. It was also the first time the new OAuth 2.0 authorization system was tested at such a large scale. This paper will discuss the planning of the challenge, the tools used to execute it, the agreed-upon transfer rates for the connections, and finally, the achieved results and any unachieved goals, along with an analysis of the bottlenecks. We will then describe how the challenge itself was executed, the results obtained, and the lessons learned. Finally, we will look ahead to the next challenge, currently scheduled for 2026, with 50% of HL-LHC rates.
To verify the readiness of the data distribution infrastructure for the HL-LHC, which is planned to start in 2029, WLCG is organizing a series of data challenges with increasing throughput and complexity. This presentation addresses the contribution of CMS to Data Challenge 2024, which aims to reach 25% of the expected network throughput of the HL-LHC. During the challenge CMS tested various network flows, from the RAW data distribution to the "flexible" model, which adds network traffic resulting from data reprocessing and MC production between most CMS sites.
The overall throughput targets were met on the global scale utilizing several hundred links. Valuable information was gathered regarding scaling capabilities of key central services such as Rucio and FTS. During the challenge about half of the transferred volume was carried out via token based authentication. In general sufficient performance of individual links was observed and sites coped with the target throughput. For links that did not reach the target, attempts were made to identify the bottleneck, whether in the transfer tools, the network link, the involved storage systems or any other component.
ALICE introduced ground-breaking advances in data processing and storage requirements and presented the CERN IT data centre with new challenges with the highest data recording requirement of all experiments. For these reasons, the EOS O2 storage system was designed to be cost-efficient, highly redundant and maximise data resilience to keep data accessible even in the event of unexpected disruptions or hardware failures. With 150 PB of usable storage space, EOS O2 is now the largest disk storage system in use at CERN. We will report on our experience and the effectiveness of operating this full production system in Run-3 and during the LHC heavy-ions run and on how this will help in paving the road towards the data deluge coming with Hi-Luminosity LHC. In particular, we will report on our experience with RS(10+2) erasure coding in production, the achievable performance of EOS O2, reliability figures, life cycle management, capacity extension and rebalancing operations.
High-Energy Physics (HEP) experiments rely on complex, global networks to interconnect collaborating sites, data centers, and scientific instruments. Managing these networks for data-intensive scientific projects presents significant challenges because of the ever-increasing volume of data transferred, diverse project requirements with varying quality of service needs, multi-domain infrastructure, WAN distances, and limited visibility into network traffic flows. This lack of visibility hinders network operators' ability to understand actual user behavior across different network segments, optimize performance, undertake effective traffic engineering and shaping, and effectively debug and troubleshoot issues.
This project addresses these challenges by focusing on improving network visibility through standardized packet marking and flow labeling techniques. We present the Scitags initiative, a collaborative effort formed within the Research Networking Technical Working Group (RNTWG) in 2020. Scitags aims to develop a generic framework and standards for identifying the owner and associated scientific activity of network traffic. This framework extends beyond HEP/WLCG experiments, and it has a potential to benefit all global communities using Research and Education (R&E) networks.
The presentation will detail the current state of the Scitags initiative, including the evolving framework, the underlying technologies being explored (e.g., eBPF, IPv6, HbH, etc.), and the roadmap for production deployment within R&E networks. By enabling improved network visibility, Scitags will empower network operators to optimize performance, troubleshoot issues more effectively, and ultimately support the growing needs of data-intensive scientific collaborations.
To address the needs of forthcoming projects such as the Square Kilometre Array (SKA) and the HL-LHC, there is a critical demand for data transfer nodes (DTNs) to realise O(100)Gb/s of data movement. This high-throughput can be attained through combinations of increased concurrency of transfers and improvements in the speed of individual transfers. At the Rutherford Appleton Laboratory (RAL), the UK's Tier-1 centre for the Worldwide LHC Computing Grid, and initial site for the UK SKA Regional Centre (SRC), we have provisioned 100GbE XRootD servers in preparation for SKA development and operations. This presentation details the efforts undertaken to reach 100Gb/s data ingress and egress rates using the WebDAV protocol through XRootD endpoints, including the use of a novel XRootD plug-in designed to asses XRootD performance independently of physical storage backend. Results are also presented for transfer tests against a CephFS storage backend under different configuration settings (e.g. via tunings to file layouts). We discuss the challenges encountered, bottlenecks identified, and insights gained, along with a description of the most effective solutions developed to date and areas of future activities.
To address the need for high transfer throughput for projects such as the LHC experiments, including the upcoming HL-LHC, it is important to make optimal and sustainable use of our available capacity. Load balancing algorithms play a crucial role in distributing incoming network traffic across multiple servers, ensuring optimal resource utilization, preventing server overload, and enhancing performance and reliability. At the Rutherford Appleton Laboratory (RAL), the UK's Tier-1 centre for the Worldwide LHC Computing Grid (WLCG), we started with a DNS round robin then moved to XRootD's cluster management service component, which has an active load balancing algorithm to distribute traffic across 26 servers, but encountered its limitations when the system as a whole is under heavy load. We describe our tuning of the configuration of the existing algorithm before proposing a new tuneable, dynamic load-balancer based on a weighted random selection algorithm.
Online and real-time computing
The CBM experiment, currently being constructed at GSI/FAIR, aims to investigate QCD at high baryon densities. The CBM First-level Event Selector (FLES) serves as the central event selection system of the experiment. It functions as a high-performance computer cluster tasked with the online analysis of physics data, including full event reconstruction, at an incoming data rate which exceeds 1 TByte/s.
The CBM detector systems operate in a free-running and self-triggered manner, delivering time-stamped data streams. Without inherent event separation, timeslice building replaces global event building. The FLES HPC system integrates data from around 5000 input links into self-contained, overlapping processing intervals and distributes these to the compute nodes.
Using a combination of RDMA and zero-copy techniques, timeslices can be built efficiently over a high-throughput InfiniBand network and distributed to available online computing resources for a full online event reconstruction and analysis in a heterogeneous HPC cluster system. A new IPC online interface to timeslice data utilizes a Posix shared memory governed by a reference-counting item distributor. This design combines maximum performance and flexibility with minimum memory consumption. These new developments have already been successfully field-tested in production at the CBM predecessor experiment mCBM at the GSI/FAIR SIS18.
This work is supported by BMBF (05P21RFFC1).
The High-Luminosity Large Hadron Collider (HL-LHC), scheduled to start
operating in 2029, aims to increase the instantaneous luminosity by a factor of
10 compared to the LHC. To match this increase, the ATLAS experiment has been
implementing a major upgrade program divided into two phases. The first phase
(Phase-I), completed in 2022, introduced new trigger and detector systems that
have been used during the Run 3 data taking period which began in July 2022.
These systems have been used in conjunction with the new Data Acquisition (DAQ)
Readout system, based on a software application called Software Readout Driver
(SW ROD). SW ROD receives and aggregates data from the front-end electronics
via the Front-End Link eXchange (FELIX) system and passes aggregated data
fragments to the High-Level Trigger (HLT) system. During Run 3, SW ROD operates
in parallel with the legacy Readout System (ROS) at an input rate of 100 kHz.
For the Phase-II, the legacy ROS will be completely replaced with a new system
based on the next generation of FELIX and an evolution of the SW ROD
application called Data Handler. Data Handler has the same functional
requirements as SW ROD but must be able to operate at an input rate of 1 MHz.
To facilitate this evolution the SW ROD has been implemented using plugin
architecture.
This contribution presents the design and implementation of the SW ROD
application for Run 3, along with the strategy for its evolution to the
Phase-II Readout system. It discusses the lessons learned during Run 3 and
describes the challenges that have been addressed to accomplish the demanding
performance requirements of HL-LHC.
The data acquisition (DAQ) system stands as an essential component within the CMS experiment at CERN. It relies on a large network system of computers with demanding requirements on control, monitoring, configuration and high throughput communication. Furthermore, the DAQ system must accommodate various application scenarios, such as interfacing with external systems, accessing custom electronics devices for data readout, and event building. We present a versatile and highly modular programmable C++ framework designed for crafting applications tailored to various needs, facilitating development through the composition and integration of modules to achieve the desired DAQ capabilities. This framework takes advantage of reusable components and readily available off-the-shelf technologies. Applications are structured to seamlessly integrate into a containerized ecosystem, where the hierarchy of components and their aggregation is specified to form the final deployable unit to be used across multiple computers or nodes within an orchestrating environment. The utilization of the framework, along with the containerization of applications, enables coping with the complexity of implementing the CMS DAQ system by providing standardized structures and components to achieve a uniform and consistent architecture.
The CBM First-level Event Selector (FLES) serves as the central data processing and event selection system for the upcoming CBM experiment at FAIR. Designed as a scalable high-performance computing cluster, it facilitates online analysis of unfiltered physics data at rates surpassing 1 TByte/s.
As the input to the FLES, the CBM detector subsystems deliver free-streaming, self-triggered data to the common readout interface (CRI), which is a custom FPGA PCIe board installed in the FLES entry nodes. A subsystem-specific part of the FPGA design time-partitions the input streams into context-free packages. The FLES interface module (FLIM), a component of the FPGA design, acts as the interface between the subsystem-specific readout logic and the generic FLES data distribution. It transfers the packed detector data to the host's memory using a low-latency, high-throughput PCIe DMA engine. This custom design enables a shared-memory-based, true zero-copy data flow.
A fully implemented FLIM for the CRI board is currently in use within CBM test setups and the FAIR Phase-0 experiment mCBM. We present an overview of the FLES input interface architecture and provide performance evaluations under synthetic as well as real-world conditions.
This work is supported by BMBF (05P21RFFC1).
The ATLAS experiment at the Large Hadron Collider (LHC) at CERN continuously
evolves its Trigger and Data Acquisition (TDAQ) system to meet the challenges
of new physics goals and technological advancements. As ATLAS prepares for the
Phase-II Run 4 of the LHC, significant enhancements in the TDAQ Controls and
Configuration tools have been designed to ensure efficient data collection,
processing, and management. This abstract presents the evolution of ATLAS TDAQ
Controls and Configuration system leading up to Phase-II Run4. As part of the
evolution towards Phase-II, Kubernetes has been chosen to orchestrate the Event
Filter farm. By leveraging Kubernetes, ATLAS can dynamically allocate computing
resources, scale processing capacity in response to changing data taking
conditions, and ensure high availability of data processing services. The
integration of the Kubernetes with the TDAQ Run Control framework enables
perfect synchronisation between the experiment's data acquisition components
and the computing infrastructure. We will discuss the architectural
considerations and implementation challenges involved in Kubernetes integration
with the ATLAS TDAQ controls and configuration system. We will highlight the
benefits of using Kubernetes as an event filter farm orchestrator, including
improved resource utilization, enhanced fault tolerance, and simplified
deployment and management of data processing workflows. In addition, we will
report on the extensive testing of Kubernetes that was conducted using a farm
of 2500 servers within the experiment data taking environment, demonstrating
its scalability and robustness in handling the demands of the ATLAS TDAQ system
for Phase-II. The adoption of Kubernetes represents a significant step forward
in the evolution of ATLAS TDAQ controls and configuration system, aligning with
industry best practices in container orchestration and cloud-native computing.
The DarkSide-20k detector is now under construction in the Gran Sasso National Laboratory (LNGS) in Italy, the biggest underground physics facility. It is designed to directly detect dark matter by observing weakly interacting massive particles (WIMPs) scattering off the nuclei in 20 tonnes of underground-sourced liquid argon in the dual-phase time projection chamber (TPC). Additionally two layers of veto detectors allow operating with virtually zero instrumental background in the region of interest, leaving only irreducible neutrino interaction. When operating the DarkSide-20k experiment is expected to lead the field for high mass WIMPs searches in the next decade and due to the low background will have a high discovery potential. Thanks to its size and sensitivity the detector will allow a broad physics program including supernova neutrino detection.
The light generated during the interactions in the liquid argon is detected by custom silicon photomultipliers (SiPMs) assemblies of size 20 cm by 20 cm. The units installed in the veto detectors are equipped with application specific integrated circuits (ASICs) coupled to SiPMs allowing linear signal response up to 100 photons and signal to noise ratio of 6 for a single photon, while those for the TPC employ a discrete element front-end with similar performances.
The data acquisition system (DAQ) for the DarkSide-20k experiment is designed to acquire signals from the 2720 channels of these photosensors in a triggerless mode. The data rate from the TPC alone is expected to be at the level of 2.5 GB/s and will be acquired by 36 newly available commercial VX2745 CAEN 16 bit, 125 MS/s, high channel density (64 ch.) waveform digitizers. The Veto detector is readout by an additional 12 modules. The data is first transferred to 24 Frontend Processor machines for filtering and reduction. Finally the data stream is received by another set of Time Slice Processor computers where the whole detector data is assembled in fixed length time series, analysed and stored for offline use. These operations will be supervised by a Maximum Integration Data Acquisition System (MIDAS) developed in the Paul Scherrer Institute in Switzerland and TRIUMF laboratory in Canada.
Offline Computing
With the increasing amount of optimized and specialized hardware such as GPUs, ML cores, etc. HEP applications face the opportunity and the challenge of being enabled to take advantage of these resources, which are becoming more widely available on scientific computing sites. The Heterogenous Frameworks project aims at evaluating new methods and tools for the support of both heterogeneous computational nodes and and multi-node workloads. Based on the experience from the parallel frameworks of the LHC experiments and their ad-hoc support for heterogeneous resources, this project investigates newer libraries and languages that have been developed after the move to parallel frameworks about a decade ago.
This paper will summarize the scope of the problem being tackled, the state of the art of heterogeneous libraries, and the benchmark infrastructure used for the R&D activities. We will as well present some of the tooling developed to extract the benchmark scenarios from existing LHC experiment workflows. First results of using both newer C++ and Julia libraries for parallel execution will be shown.
The large increase in luminosity expected from Run 4 of the LHC presents the ATLAS experiment with a new scale of computing challenge, and we can no longer restrict our computing to CPUs in a High Throughput Computing paradigm. We must make full use of the High Performance Computing resources available to us, exploiting accelerators and making efficient use of large jobs over many nodes.
Here we show our current developments in introducing these capabilities to Athena, ATLAS’s general software framework. We will show how we have used MPI to distribute processing over multiple nodes, and how this can be used to run real ATLAS jobs from the Grid on an HPC. We will also show how we have integrated a first-class capability to offload work to an accelerator without blocking the CPU, by making use of suspendable lightweight threads, and an example of how this capability can be used in a real workload.
To achieve better computational efficiency and exploit a wider range of computing resources, the CMS software framework (CMSSW) has been extended to offload part of the physics reconstruction to NVIDIA GPUs. To support additional back-ends, as well to avoid the need to write, validate and maintain a separate implementation of the reconstruction algorithms for each back-end, CMS has adopted the Alpaka performance portability library.
Alpaka (Abstraction Library for Parallel Kernel Acceleration) is a header-only C++ library that provides performance portability across different back-ends, abstracting the underlying levels of parallelism. It supports serial and parallel execution on CPUs, and extremely parallel execution on NVIDIA, AMD and Intel GPUs.
This contribution will show how Alpaka is used in the CMS software to develop and maintain a single code base; to use different toolchains to build the code for each supported back-end, and link them into a single application; to seamlessly select the best back-end at runtime, and implement portable reconstruction algorithms that run efficiently on CPUs and GPUs from different vendors. It will describe the validation and deployment of the Alpaka-based implementation in the CMS High Level Trigger, and highlight how it achieves near-native performance.
As the Large Hadron Collider progresses through Run 3, the LHCb experiment has made significant strides in upgrading its offline analysis framework and associated tools to efficiently handle the increasing volumes of data generated. Numerous specialised algorithms have been developed for offline analysis, with a central innovation being FunTuple--a newly developed component designed to effectively compute and store offline data. Built upon the robust Gaudi functional framework, FunTuple merges a user-friendly Python interface with a flexible templated design. This modern architecture supports a wide range of data types, including both reconstructed and simulated events, facilitating processing of event-level and decay-level information. Crucially, FunTuple is primed for future enhancements to integrate new event models, optimising vectorised data processing across heterogeneous resources.
A pivotal feature of FunTuple is its capability to align trigger-computed observables with those analysed offline, crucial for maintaining data integrity across LHCb analyses. This alignment is achieved through Throughput Oriented (ThOr) functors, specifically crafted to meet the high throughput demands of the trigger system. Moreover, FunTuple offers comprehensive customisation options, enabling users to define and store tailored observables within ROOT files in anticipation of future increases in data volumes. FunTuple has undergone rigorous testing, including numerous unit tests and pytest evaluations. In 2024, it is undergoing a comprehensive stress test by hundreds of analysts to validate its reliability in managing and validating the quality of data recorded by LHCb.
This presentation will delve into the design, user interface, and integration of FunTuple alongside other analysis components, showcasing their efficiency and reliability through detailed performance metrics in managing large-scale data.
We summarize the status of the Deep Underground Neutrino Experiment (DUNE) software and computing development. The DUNE Collaboration has been successfully operating the DUNE prototype detectors at both Fermilab and CERN, and testing offline computing services, software, and infrastructure using the data collected. We give an overview of results from end-to-end testing of systems needed to acquire, catalog, reconstruct, simulate and analyze the beam data from ProtoDUNE Horizontal Drift (PDHD) and Near Detector 2x2 Demonstrator, and cosmic data from ProtoDUNE Vertical Drift (PDVD). These tests included reconstruction and simulation of data from all prototype detector runs utilizing a variety of distributed computing and HPC resources. The results of these studies help define the development path of DUNE core software and computing to support the physics goals of precision measurements of neutrino oscillation parameters, detection of astrophysical neutrinos, measurement of neutrino interaction properties and searches for physics beyond the Standard Model. The data from the full DUNE far and near detectors, expected in 2029 and 2031 respectively, will present significant challenges in terms of data product memory management, optimized use of parallel processing for reconstruction and simulation, and management of large individual trigger data volumes. DUNE will present plans for future development to accommodate the requirements of the larger DUNE far and near detectors, and the timeline for future data challenges leading to data taking at the end of the decade.
Since the mid-2010s, the ALICE experiment at CERN has seen significant changes in its software, especially with the introduction of the Online-Offline (O²) computing system during Long Shutdown 2. This evolution required continuous adaptation of the Quality Control (QC) framework responsible for online Data Quality Monitoring (DQM) and offline Quality Assurance (QA).
After a general overview of the system, this talk delves into the evolving user requirements that shaped the QC framework from its initial prototyping phase to its current state. We will explore the changing landscape of performance needs and feature demands, highlighting which initial requirements persisted, which emerged later, and which features ultimately proved unnecessary.
Additionally, we will trace the framework's development in relation to other software components within the ALICE ecosystem, offering valuable insights and lessons learned throughout the process. Finally, we will also discuss the challenges encountered in balancing development team resources with the evolving project scope.
Simulation and analysis tools
The ATLAS Fast Chain represents a significant advancement in streamlining Monte Carlo (MC) production efficiency, specifically for the High-Luminosity Large Hadron Collider (HL-LHC). This project aims to simplify the production of Analysis Object Data (AODs) and potentially Derived Analysis Object Data (DAODs) from generated events with a single transform, facilitating rapid reproduction of the entire MC dataset multiple times per year. By eliminating intermediate formats and optimizing CPU utilization, the Fast Chain offers substantial savings in disk space while staying within the CPU budget by employing fast simulation methodologies instead of full MC campaigns. Central to the success of the Fast Chain is the seamless integration of fast simulation and reconstruction techniques. Leveraging AtlFast3 methodologies for efficient calorimeter shower simulation and employing Fast Track Simulation (FATRAS) for charged particles in the Inner Detector, the project aims at accelerated processing without compromising accuracy. Notably, muon simulations rely on Geant4 due to minimal CPU overhead. Pileup effects are incorporated through MC overlay, with potential future integration of data overlay. Reconstruction speed optimization focuses on Inner Detector track reconstruction. Strategies such as dedicated reconstruction configurations and track overlay from pre-mixed pileup datasets are being explored. In summary, the ATLAS Fast Chain project demonstrates a paradigm shift in MC production methodologies, offering a scalable and efficient solution tailored to the demands of the HL-LHC era. This abstract provides an overview of the project's objectives, methodologies, and ongoing developments, showcasing its potential to revolutionize MC production within the ATLAS experiment.
Simulation of physics processes and detector response is a vital part of high energy physics research but also representing a large fraction of computing cost. Generative machine learning is successfully complementing full (standard, Geant4-based) simulation as part of fast simulation setups improving the performance compared to classical approaches.
A lot of attention has been given to calorimeters being the slowest part of the full simulation, but their speed becomes comparable with silicon semiconductor detectors when fast simulation is used. This makes silicon detectors the next candidate to make faster, especially with the growing number of channels in future detectors.
This work studies the use of transformer architectures for fast silicon tracking detector simulation. The OpenDataDetector is used as a benchmark detector. Physics performance is estimated comparing reconstructed tracks using the ACTS tracking framework between full simulation and machine learning one.
Celeritas is a rapidly developing GPU-enabled detector simulation code aimed at accelerating the most computationally intensive problems in high energy physics. This presentation will highlight exciting new performance results for complex subdetectors from the CMS and ATLAS experiments using EM secondaries from hadronic interactions. The performance will be compared on both Nvidia and AMD GPUs as well as multicore CPUs, made possible by a new native Celeritas geometry representation of Geant4 geometry objects. This new surface-based geometry, ORANGE, provides a robust and efficient navigation engine fundamentally different from existing detector simulation models. Finally, we introduce two new physics capabilities to Celeritas, optical photon tracking and extended EM models, that demonstrate the code's extensibility and promise potential applications beyond LHC detectors.
An important alternative for boosting the throughput of simulation applications is to take advantage of accelerator hardware, by making general particle transport simulation for high-energy physics (HEP) single-instruction-multiple-thread (SIMT) friendly. This challenge is not yet resolved due to difficulties in mapping the complexity of Geant4 components and workflow to the massive parallelism features exposed by graphics processing units (GPU). The AdePT project is one of the R&D initiatives tackling this limitation and exploring GPUs as potential accelerators for offloading part of the CPU simulation workload. Our main target is the implementation of a complete electromagnetic shower transport engine working on the GPU. A first development phase, allowed us to verify our GPU prototype against the Geant4 simulation for both simplified and complex setups, and to test different Geant4 integration strategies. We have simplified the integration procedure of AdePT as an external library in both standalone applications and experimental frameworks through standard Geant4 mechanisms. The project's current main focus is to provide solutions for the main performance bottlenecks identified so far: inefficient geometry modeling for the GPUs, and a suboptimal CPU-GPU scheduling strategy. We will present the most recent results and conclusions of our work, focusing on the hybrid Geant4-AdePT use case.
The demands for Monte-Carlo simulation are drastically increasing with the high-luminosity upgrade of the Large Hadron Collider, and expected to exceed the currently available compute resources. At the same time, modern high-performance computing has adopted powerful hardware accelerators, particularly GPUs. AdePT is one of the projects aiming to address the demanding computational needs by leveraging these heterogeneous compute architectures. While AdePT has successfully ported realistic detector simulations to GPUs using the VecGeom library, the complexity of geometry modeling emerged as a bottleneck. Thread divergence and high register usage were impeding the GPU performance. Therefore, a new, GPU-friendly surface-based model has been introduced in the VecGeom library that decomposes the divergent code of the 3D primitive solids into simpler and more balanced surface algorithms. In this work, we present the latest performance results, in particular on complex setups like the CMS Phase-2 geometry. Additionally, we explore techniques such as mixed precision and bounding volume hierarchies to further accelerate simulations.
Opticks is an open source project that accelerates optical photon simulation
by integrating NVIDIA GPU ray tracing, accessed via the NVIDIA OptiX API, with
Geant4 toolkit based simulations.
Optical photon simulation times of 14 seconds per 100 million photons
have been measured within a fully analytic JUNO GPU geometry
auto-translated from the Geant4 geometry when using a single NVIDIA GPU from
the first RTX generation.
Optical physics processes of scattering, absorption, scintillator reemission
and boundary processes are implemented in CUDA based on Geant4. Wavelength-dependent material and surface
properties as well as inverse cumulative distribution functions for reemission
are interleaved into GPU textures providing fast interpolated property lookup
or wavelength generation. In this work we describe the application of Opticks
to JUNO simulation including new Opticks features that improve performance for
complex CSG shapes and torus solids.
Collaborative software and maintainability
The LHCb Software Framework Gaudi has been developed in C++ since 1998. Over the years it evolved following the changes in the C++ established best practices and the evolution of the C++ standard, even reaching the point of enabling the development of multi-threaded applications.
In the past few years there has been several announcements and debates over the so called C++ successor languages and safe alternatives to C++, with Rust leading the way as an example of safe and performing language that can replace C and C++ in a number of cases.
This paper explores some ways Rust can be used to extend the Software Framework Gaudi, focusing on how one can leverage on the Rust-C++ interoperability efforts driven by the community. We show how to invoke Rust code from C++ and vice versa, and how Gaudi components could be written completely in Rust. We can use the experience gained in the exercise to evaluate possible integration with other languages or technologies, like WASM.
Recently, interest in measuring and improving the energy (and carbon) efficiency of computation in HEP, and elsewhere, has grown significantly. Measurements have been, and continue to be, made of the efficiency of various computational architectures in standardised benchmarks... but those benchmarks tend to compare only implementations in single programming languages. Similarly, comparisons of the efficiency of various languages tend to focus on a single architecture, although it is the case that some abstractions in a given language can match specific architectural choices (in, say, memory ordering strictness) better than others.
The existence of the JetReconstruction.jl project, implementing a subset of the FastJet C++ code's functionality in performant Julia, allows us to usefully compare how the relative efficiencies of implementations in the two languages are influenced by the architecture they are executed on.
We report on the results of comparing benchmarks on these codes, and others, on x86 and various aarch64 implementations, amongst others.
ROOT is a software toolkit at the core of LHC experiments and HENP collaborations worldwide, widely used by the community and in continuous development with it. The package is available through many channels that cater different types of users with different needs. This ranges from software releases on the LCG stacks provided via CVMFS for all HENP users to benefit, to pre-built binaries available on the three major platforms (Linux, MacOS, Windows), to more specialised packaging systems such as Homebrew, Snap, Anaconda. The last example is one of the main systems to distribute software to a Python user base, particularly beneficial for complex environments with real-world scientific applications in mind such as those found in HENP. Nonetheless, the standard Python implementation defaults to using pip as a package installer. This technology, together with the Python Package Index (PyPI), distributes many Python packages and has the advantage of providing a lightweight path to downstream development of a package with some upstream Python dependencies. This contribution highlights the steps required towards making pip install ROOT possible, demonstrating its availability as an early-stage release, and discussing some of the unique challenges of delivering a highly-performant multi-language software via the standard Python packaging system.
In the vast landscape of CERN's internal documentation, finding and accessing relevant detailed information remains a complex and time-consuming task. To address this challenge, the AccGPT project proposes the development of an intelligent chatbot leveraging Natural Language Processing (NLP) technologies. The primary objective is to harness open-source Large Language Models (LLMs) to create a purpose-built chatbot for text knowledge retrieval, with the potential to serve as an assistant for code development and other features in the future.
This initiative was driven by the growing demand at CERN for access to LLMs, not only for building AI Chatbots but also for various other use cases, including Transcription and Translation as a Service (TTaaS), CDS and Zenodo Information Categorization, HR selection processes, and many others. Providing easy and efficient access to LLMs is crucial for the adoption of Generative AI across numerous processes at CERN.
A promising first prototype has already been developed in the realm of knowledge retrieval. It demonstrates a sufficient understanding of user inquiries and provides comprehensive responses utilizing a Retrieval Augmented Generation (RAG) pipeline. However, there is room for improvement to further increase the precision of the responses, which can be achieved by enhancing the retrieval pipeline, considering more powerful and larger LLMs, or fine-tuning the LLMs with more relevant scientific data.
The user interface design and overall user experience of the current prototype chatbot are being iteratively improved, and preparations are underway to make AccGPT available to the community for testing. Automated data scraping and preprocessing pipelines are also being developed to update the chatbot's knowledge base fully autonomously.
The LHCb collaboration continues to primarily utilize the Run 1 and Run 2 legacy datasets well into Run 3. As the operational focus shifts from the legacy data to the live Run 3 samples, it is vital that a sustainable and efficient system is in place to allow analysts to continue to profit from the legacy datasets. The LHCb Stripping project is the user-facing offline data-processing stage that allows analysts to select their physics candidates of interest simply using a Python-configurable architecture. After physics selections have been made and validated, the full legacy datasets are then reprocessed in small time windows known as Stripping campaigns.
Stripping campaigns at LHCb are characterized by a short development window with a large portion of collaborators, often junior researchers, directly developing a wide variety of physics selections; the most recent campaign dealt with over 900 physics selections. Modern organizational tools, such as GitLab Milestones, are used to track all of the developments and ensure the tight schedule is adhered to by all developers across the physics working groups. Additionally, continuous integration is implemented within GitLab to run functional tests of the physics selections, monitoring rates and timing of the different algorithms to ensure operational conformity. Outside of these large campaigns the project is also subject to nightly builds, ensuring the maintainability of the software when parallel developments are happening elsewhere.
I will be presenting the history of the design, implementation, testing, and release of the production version of a C++-based software for the Gas Gain Stabilization System (GGSS) used in the TRT detector at the ATLAS experiment. This system operates 24/7 in the CERN Point1 environment under the control of the Detector Control System (DCS) and plays a crucial role in delivering reliable data during the LHC’s stable beams.
The uniqueness of this software lies in its initial release around 2004, followed by subsequent refactoring, improvements, and implementation for the Run1 period of the LHC in 2008. Another significant change occurred during Long Shutdown 1 when the operating system transitioned from Windows to Linux for Run2 in 2015. More recently, there have been frequent updates and upgrades to the operating system and external libraries.
My aim is to present the evolution of the software, highlighting changes introduced from an external perspective due to shifts in the environment or requirements. Additionally, I’ll discuss the evolution of the C++ standard, compiler changes, security considerations, and modifications to the build and test environment. During the conference, I will focus on the most compelling and significant milestones, as well as key aspects relevant to the lifecycle of this software.
Computing Infrastructure
A robust computing infrastructure is essential for the success of scientific collaborations. However, smaller or newly founded collaborations often lack the resources to establish and maintain such an infrastructure, resulting in a fragmented analysis environment with varying solutions for different members. This fragmentation can lead to inefficiencies, hinder reproducibility, and create challenges for the collaboration.
We present an analysis facility for the DARWIN (DARk matter WImp search with liquid xenon) observatory, a new experiment that is currently in its R&D phase. The facility is designed to be lightweight with minimal administrative overhead while providing a common entry point for all DARWIN collaboration members. The setup serves as a blueprint for other collaborations, that want to provide a common analysis facility for their members. Grid computing and storage resources are integrated into the facility, allowing for distributed computing and a common entry point for storage. The authentication and authorization infrastructure for all services is token-based, using an Indigo IAM instance.
This talk will discuss the architecture of the facility, its provided services, first experiences of the DARWIN collaboration, and how it can serve as a sustainable blueprint for other collaborations.
BaBar stopped data taking in 2008 but its data is still analyzed by the collaboration. In 2021 a new computing system outside of the SLAC National Accelerator Laboratory was developed and major changes were needed to keep the ability to analyze the data by the collaboration, while the user facing front ends all needed to stay the same. The new computing system was put in production in 2022 and we will describe its unique infrastructure, based on cloud compute in Victoria, Canada, data storage at GridKa, Germany, streaming data access, as well as the possibility to analyze any data from anywhere. We will show advantages of the current system and how to run an old and outdated OS in current infrastructures, complications we faced when developing the system, as well as our experience in running and using it for about 2 years. It may be of interest to other groups and experiments when planing data preservation with the ability to continue to analyze the data, even decades after data taking has stopped.
Although wireless IoT devices are omnipresent in our homes and workplaces, their use in particle accelerators is still uncommon. Although the advantages of movable sensors communicating over wireless networks are obvious, the harsh radiation environment of a particle accelerator has been an obstacle to the use of such sensitive devices. Recently, though, CERN has developed a radiation-hard LoRaWAN based platform that can be adapted to support multiple sensors.
We report here on this platform, the deployment of an LPWAN network based on LoRaWAN technology in the underground areas at CERN, the infrastructure and tools developed to support device integration and data collection, and, finally, on some of the positive benefits that have been delivered through the use of these sensors in CERN’s accelerator complex.
The modern data centers provide the efficient Information Technologies (IT) infrastructure needed to deliver resources,
services, monitoring systems and collected data in a timely fashion. At the same time, data centres have been continuously
evolving, foreseeing large increase of resources and adapting to cover multifaced niches.
The CNAF group at INFN (National Institute for Nuclear Physics) has implemented a Big Data Platform (BDP)
infrastructure, designed for the collection and the indexing of log reports from CNAF facilities.
The infrastructure is an ongoing project at CNAF and it is at service of the Italian groups working in high energy physics
experiments. Within this framework, the first data pipeline was established for the ATLAS experiment, using input from the
ATLAS Distributed Computing system PanDa.
This pipeline focuses on the ATLAS computational job data processed by the Italian INFN Tier-1 computing farm. The system
has been operational and effective for several years, marking our initiative as the first to integrate job information
directly with the infrastructure. Following the finalization of data transmission, our objective is to conduct an analysis
and surveillance of the PanDA Jobs data. This will involve examining the performance metrics of the machines and identifying
the log errors that lead to job failures.
DESY operates multiple dCache storage instances for multiple communities. As each community has different workflows and workloads, their dCache installations range from very large instances with more than 100 PB of data, to instances with up to billions of files or instances with significant LAN and WAN I/O.
To successful operate all instances and quickly identify issues and performance bottlenecks, DESY IT relies for monitoring heavily on dCache own storage events. Each atomic operation in the distributed storage instances trigger a storage event with details to the corresponding transfer or service status change.
These events are collected and parsed through an Apache Kafka event streaming bus. From the Kafka event stream, the events are aggregated in an Elastic Search+Lucene based database and search engine for on the fly operational diagnostics and analytics. Beyond day to day operations, an on demand Apache Spark cluster on top the National Analysis Facility at DESY is used for in detail analyses of operational data to extract information over a wide time span and number of storage events. In a similar fashion, all dCache logging messages are also processed through Kafka stream allowing to employ a passive monitoring waiting for specific signature to raise an alarm. In the future ML and AI algorithms for predictive maintenance are in the development pipeline. Furthermore, additional matrices are collecting from the dCache pools themselves and also pushed to Kafka to generate an almost complete picture of the dCache instances.
In this talk, we present our aggregation and analyses pipelines and workflows and how they are enabling DESY IT to scale out dCache storages for heterogeneous user groups and use cases.
Queen Mary University of London (QMUL) has recently finished refurbishing its data centre that house our computing cluster supporting the WLCG project. After 20 years of operation the original data centre had significant cooling issues and increases in energy prices have all driven the need for refurbishment amid growing awareness of climate change.In addition there is a need to increase the capacity (from 150KW) to cope with the expected increased needs to the high luminosity LHC and new astronomy projects such as the LSST and SKA observatories.
A summary of the project is presented covering the project time line and solutions implemented (in row cooling, hot aisle containment, heat pumps and dry air coolers). Experiences and lessons learnt in the design, building and use of the data centre ( covering choices in power supply, rack density, storage space, floor type, lighting, monitoring, etc…) are discussed. Effects of budget constraints and project rescoping due to inflation are also discussed.
First data from the energy use and heat recovery are presented and estimates of the energy and carbon saving over time are given.
Collaboration, Reinterpretation, Outreach and Education
The Science and Technology Facilities Council (STFC), part of UK Research and Innovation (UKRI), has a rich tradition of fostering public engagement and outreach, as part of its strategic aim to showcase and celebrate STFC science, technology, and staff, both within its National Laboratories and throughout the broader community.
As part of its wider programme, STFC organised two large scale public engagement open weeks in 2023 and 2024. These events, held at the Sci-Tech Daresbury campus in the North of England and the Harwell Campus in the South of England, home to STFC's largest National Laboratories, collectively welcomed over 17,500 participants.
These open weeks provided an unparalleled opportunity for the public to intimately engage with groundbreaking science and technology. Attendees were immersed in hands-on activities, demonstrations, and enlightening talks spanning various disciplines and catering to all age groups. They also had the unique opportunity to explore the state-of-the-art facilities on site, and talk with the people who work here.
STFC's Scientific Computing Department (SCD) took the lead in orchestrating and delivering computing outreach initiatives during both open weeks. This paper details STFC's approach to organizing these open weeks, how the open weeks were structured, SCD's planning process for contributing to the events, and delves into the specifics of SCD's impactful contributions. By sharing these insights, this paper aims to offer valuable lessons for the effective execution of large-scale public engagement initiatives within the scientific community.
Since 1983 the Italian groups collaborating with Fermilab (US) have been running a 2-month summer training program for Master students. While in the first year the program involved only 4 physics students, in the following years it was extended to engineering students. Many students have extended their collaboration with Fermilab with their Master Thesis and PhD.
The program has involved almost 600 Italian students from more than 20 Italian universities. Each intern is supervised by a Fermilab Mentor responsible for the training program. Training programs spanned from Tevatron, CMS, Muon (g-2), Mu2e and SBN and DUNE design and data analysis, development of particle detectors, design of electronic and accelerator components, development of infrastructures and software for tera-data handling, quantum computing and research on superconductive elements and accelerating cavities.
In 2015 the University of Pisa included the program within its own educational programs. Summer Students are enrolled at the University of Pisa for the duration of the internship and at the end of the internship they write summary reports on their achievements. After positive evaluation by a University of Pisa Examining Board, interns are acknowledged 6 ECTS credits for their Diploma Supplement. In the years 2020 and 2021 the program was canceled due to the sanitary emergency but in 2022 it was restarted and allowed a cohort of 21 students in 2022, and a cohort of 27 students in 2023 to be trained for nine weeks at Fermilab. We are now organizing the 2024 program.
The Remote^3 (Remote Cubed) project is an STFC Public Engagement Leadership Fellowship funded activity, organised in collaboration between the University of Edinburgh (UoE), and STFC’s Public Engagement Team, Scientific Computing Department, and Boulby Underground Laboratory – part of STFC Particle Physics.
Remote^3 works with school audiences to challenge teams of young people to design, build, and program their own LEGO Mindstorms “Mars Rover”, which will be tested at the Boulby Underground Laboratory’s Mars Yard, 1.1 km underground. Teams, with the assistance of mentors from UoE and STFC, will design their rover to complete various space-exploration themed challenges – ranging from taking a panoramic environment scan to navigating the Mars Yard landscape looking for LEGO brick samples. The project aims to engage with audiences who do not usually interact with STFC Public Engagement, such as more remote locations or areas of higher deprivation and give them the opportunity to work hands on with engineering and computing, whilst learning from and interacting with real scientists and engineers.
Since its inception in 2019, Remote^3 has flourished in a wide variety of different environments and through multiple mediums, from entirely virtual during the lockdowns of 2020-21, deep underground, in schools and storytelling at libraries, and in tents in fields at festivals.
This year Remote^3 is building on the lessons learnt through this varied programme to deliver a series of engagement activities in conjunction with STFC’s Rutherford Appleton Laboratory Public Open Week, which has an expected audience of 20,000 people.
Virtual Visits have been an integral component of the ATLAS Education and Outreach programme since their inception in 2010. Over the years, collaboration members have hosted visits for tens of thousands of visitors located all over the globe. In 2024, alone there have already been 59 visits through the month of May. Visitors in classrooms, festivals, events or even at home have a unique opportunity to engage with scientists located either underground in the ATLAS experimental cavern or in front of the control room, to learn about the goals and achievements of the collaboration. As part of the renovation of the ATLAS Visitor Centre at LHC Point 1, a new installation was constructed to facilitate Virtual Visits during the running of LHC. We present the overall programme, the new installation and discuss recent initiatives to expand our reach, including Open Visits on Zoom, Facebook, YouTube and TikTok Live.
If a physicist needs to ask for help on some software, where should they go? For a specific software package, there may be a preferred website, such as the ROOT Forum or a GitHub/GitLab Issues page, but how would they find this out? What about problems that cross package boundaries? What if they haven't found a tool that would solve their problem yet?
HEP-Help (hep-help.org) is intended as a first-stop helpline for questions about particle physics software. It is not intended to replace established venues, but redirect users to the best place to ask their questions, and possibly help them frame their questions in better ways, such as distinguishing usage questions from bug reports and constructing minimal reproducers.
This project has two parts: one technological and one social. The technical aspect involves collating existing documentation, tutorials, and forum archives to produce a dataset to train an LLM as a first responder. The social aspect involves building a community of part-time responders, people who take shifts (help-a-thons!) to correct or follow up on the LLM's initial suggestions. This community includes tutorial trainers, developers of particle physics software, and experienced users, all of whom are already invested in helping new users and stand to benefit from a more organized support system.
Large Language Models (LLMs) have emerged as a transformative tool in society and are steadily working their way into scientific workflows. Despite their known tendency to hallucinate, rendering them perhaps unsuitable for direct scientific pipelines, LLMs excel in text-related tasks, offering a unique solution to manage the overwhelming volume of information presented at large conferences such as ACAT, ICHEP, and CHEP. This poster presents an innovative open-source application that harnesses the capabilities of an LLM to rank conference abstracts based on a user’s specified interests. By providing a list of interests to the LLM, it can sift through a multitude of abstracts, identifying those most relevant to the user, effectively helping to tailor the conference experience. The LLM, in this context, serves an assistant role, aiding conference attendees in navigating the deluge of information typical of large conferences. The poster will detail the workings of this application, provide prompts to optimize its use, and discuss potential future directions for this type of application.
Place: AGH University main building A0, Mickiewicza 30 Av., Krakow
The route from the main venue is here:
https://www.google.com/maps/d/edit?mid=1lzudzN5SpFXrPZnD1y5GEpd18xuZY6s&usp=sharing
Quantum computers have reached a stage where they can perform complex calculations on around 100 qubits - referred to as Quantum Utility Era.
They are being utilized in industries such as materials science, condensed matter, and particle physics for problem exploration beyond the capabilities of classical computers. In this talk, we will highlight the progress in both IBM quantum hardware and software that allow exploring opportunities not only for large-scale applications utilizing error-mitigation, but also pave the way toward future error corrected systems within the next decade.
This year CERN celebrates its 70th Anniversary, and the 60th anniversary of Bell's theorem, a result that arguably had the single strongest impact on modern foundations of quantum physics, both at the conceptual and methodological level, as well as at the level of its applications in information theory and technology.
CERN has started its second phase of the Quantum Technology Initiative with a 5-year-term plan aligned with the CERN research and collaboration objectives. This effort is designed to build specific capacity and technology platforms and support a longer-term strategy to use quantum technology at CERN and in HEP in the future. After a preliminary introduction about the promise of quantum computing, we will discuss main research directions and results from theoretical foundations of quantum machine learning algorithms to application in several areas of HEP.
Michele Grossi, PhD https://michele-grossi.web.cern.ch
As CERN approaches the launch of the High Luminosity-LHC Large Hadron Collider (HL-LHC) by the decade’s end, the computational demands of traditional simulations have become untenably high. Projections show millions of CPU-years required to create simulated datasets - with a substantial fraction of CPU time devoted to calorimetric simulations. This presents unique opportunities for breakthroughs in computational physics. We show how Quantum-assisted Generative AI can be used for the purpose of creating synthetic, realistically scaled calorimetry dataset. The model is constructed by combining D-Wave’s Quantum Annealer processor with a Deep Learning architecture, increasing the timing performance with respect to first principles simulations and Deep Learning models alone, while maintaining current state-of-the-art data quality.
Meeting point: in front of the venue, the Auditorium Maximum of Jagiellonian University - Krupnicza 33 Street.
Recent Large Language Models like ChatGPT show impressive capabilities, e.g. in the automated generation of text and computer code. These new techniques will have long-term consequences, including for scientific research in fundamental physics. In this talk I present the highlights of the first Large Language Model Symposium (LIPS) which took place in Hamburg earlier this year. I will focus on high energy physics and will also give an outlook towards future developments and applications.
A diverse panel that will discuss the potential impact of the progress in the fields of Quantum Computing and the latest generation of Machine Learning, like LLMs. On the panel are experts from QC, LLM, ML in HEP, Theoretical Physics and large scale computing in HEP. The discussion will be moderated by Liz Sexton Kennedy from the Fermi National Accelerator Laboratory.
To submit questions for the panel, go to https://onlinequestions.org/, and use the code 1514461.
Data and Metadata Organization, Management and Access
The CERN Tape Archive (CTA) scheduling system implements the workflow and lifecycle of Archive, Retrieve and Repack requests. The transient metadata for queued requests is stored in the Scheduler backend store (Scheduler DB). In our previous work, we presented the CTA Scheduler together with an objectstore-based implementation of the Scheduler DB. Now with four years of experience in production, the strengths and limitations of this implementation are better understood. While the objectstore-based implementation is highly efficient for FIFO queueing operations (archive/retrieve), non-FIFO operations (delete, priority queues) require some workarounds. The objectstore backend implementation imposes constraints on how the CTA Scheduler code can be modified and is an additional software dependency and technology for developers to learn. This paper discusses an alternate Scheduler DB implementation, based on relational database technology. We include a status report and roadmap.
The latest tape hardware technologies (LTO-9, IBM TS1170) impose new constraints on the management of data archived to tape. In the past, new drives could read the previous one or even two generations of media, but this is no longer the case. This means that repacking older media to new media must be carried out on a more agressive schedule than in the past. An additional challenge is the large capacity of the newer media. A 50 TB tape can contain a vast number of files, whose metadata must be tracked during repacking. Repacking an entire tape also requires a significant amount of disk storage. At CERN Tier-0, these challenges have created new operational problems to solve, in particular contention for resources between physics archival and repack operations. This contribution details these problems and describes the various approaches we have taken to mitigate and solve them. We include a roadmap for future repack developments.
Storing the ever-increasing amount of data generated by LHC experiments is still inconceivable without making use of the cost effective, though inherently complex, tape technology. GridKa tape storage system used to rely on IBM Spectrum Protect (SP). Due to a variety of limitations and to meet the even higher requirements of HL-LHC project, GridKa decided to switch from SP to High Performance Storage System (HPSS).
Even though HPSS is a highly scalable and performant tape management software, it required special adjustments to fulfill all GridKa requirements. Based on the experience gained with the former tape system, the implementation team developed specific stress scenarios. Running these tests and interpreting their results allowed a successful adaptation of HPSS and made it the core component of GridKa tape storage system.
To increase the performance the architecture of the system was reshaped and the stored data has been collocated in a more appropriate, tape-oriented way to match the requirements of every single experiment and HPSS demands. In total 70 PB of data and 40 million files were migrated from the legacy to the new tape system at GridKa.
This contribution presents the internal architecture of the new tape storage system, the implementation and migration process, the encountered issues, the achieved results and ongoing work on open items.
The High Luminosity upgrade to the LHC (HL-LHC) is expected to generate scientific data on the scale of multiple exabytes. To tackle this unprecedented data storage challenge, the ATLAS experiment initiated the Data Carousel project in 2018. Data Carousel is a tape-driven workflow in which bulk production campaigns with input data resident on tape are executed by staging and promptly processing a sliding window to disk buffer such that only a small fraction of the input files are pinned on disk at any one time. Put in ATLAS production before Run3, Data Carousel continues to be our focus for seeking new opportunities in disk space savings, and enhancing tape usage throughout the ATLAS Distributed Computing (ADC) environment. These efforts are highlighted by two recent ATLAS HL-LHC demonstrator projects: data-on-demand and tape smart writing. We will discuss the recent studies and outcomes from these projects, along with various related improvements across the ATLAS distributed computing software. The research was conducted together with site experts at CERN and Tier-1 centers.
The Vera Rubin Observatory is a very ambitious project. Using the world’s largest ground-based telescope, it will take two panoramic sweeps of the visible sky every three nights using a 3.2 Giga-pixel camera. The observation products will generate 15 PB of new data each year for 10 years. Accounting for reprocessing and related data products the total amount of critical data will reach several hundred PB. Because the camera consists of 201 CCD panels, the majority of the data products will consist of relatively small files in the low megabyte range, impacting data transfer performance. Yet, all of this data needs to be backed up in offline storage and still be easily retrievable not only for groups of files but also for individual files. This paper describes how SLAC is building a Rucio-centric specialized Tape Remote Storage Element (TRSE) that automatically creates a copy of a Rucio dataset as a single indexed file avoiding transferring many small files. This not only allows high-speed transfer of the data to tape for backup and dataset restoral, but also simple retrieval of individual dataset members in order to restore lost files. We describe the design and implementation of the TRSE and how it relates to current data management practices. We also present performance characteristics that make backups of extremely large scale data collections practical.
Due to the increasing volume of physics data being produced, the LHC experiments are making more active use of archival storage. Constraints on available disk storage have motivated the evolution towards the "data carousel" and similar models. Datasets on tape are recalled multiple times for reprocessing and analysis, and this trend is expected to accelerate during the Hi-Lumi era (LHC Run-4 and beyond).
Currently, storage endpoints are optimised for efficient archival, but it is becoming increasingly important to optimise for efficient retrieval. This problem has two dimensions. To reduce unnecessary tape mounts, the spread of each dataset - the number of tapes containing files which will be recalled at the same time - should be minimised. To reduce seek times, files from the same dataset should be physically colocated on the tape. The Archive Metadata specification is an agreed format for experiments to provide scheduling and colocation hints to storage endpoints to achieve these goals.
This contribution describes the motivation, the review process with the various stakeholders and the constraints that led to the Archive Metadata proposal. We present the implementation and deployment in the CERN Tape Archive and our preliminary experiences of consuming Archive Metadata at WLCG Tier-0.
Online and real-time computing
Ensuring the quality of data in large HEP experiments such as CMS at the LHC is crucial for producing reliable physics outcomes. The CMS protocols for Data Quality Monitoring (DQM) are based on the analysis of a standardized set of histograms offering a condensed snapshot of the detector's condition. Besides the required personpower, the method has a limited time granularity, potentially hiding temporary anomalies. Unsupervised machine learning models such as auto encoders and convolutional neural networks have been recently deployed for anomaly detection with per-lumisection granularity. Nevertheless, given the diversity of detector technologies, geometries and physics signals characterizing each subdetector, different tools are developed in parallel and maintained by the sub detector experts. In this contribution, we discuss the development of an automated DQM for the online monitoring of the CMS Muon system, offering a flexible tool for the different muon subsystems based on deep learning models trained on occupancy maps. The potential flexibility and extensibility to different detectors, as well as the effort towards the integration of per-lumisection monitoring in the DQM workflow will be discussed.
Hydra is an advanced framework designed for training and managing AI models for near real time data quality monitoring at Jefferson Lab. Deployed in all four experimental halls, Hydra has analyzed over 2 million images and has extended its capabilities to offline monitoring and validation. Hydra utilizes computer vision to continually analyze sets of images of monitoring plots generated 24/7 during experiments. Generally, these sets of images are produced at a rate and quantity that is exceedingly difficult for shift crews to effectively monitor. Significant effort has been devoted to enhancing Hydra's user interface, to ensure that it provides clear, actionable insights for shift workers and other users. Gradient Weighted Class Activation Maps (GradCAM) provide added interpretability, allowing users to visualize important regions of the image for classification. Hydra has been containerized to enable the creation of portable demos and seamless integration with container-based technologies such as Kubernetes and Docker. With the user interface enhancements and containerization, Hydra can be rapidly deployed for new use cases and experiments. This talk will describe the Hydra framework, its user interface and experience, and the challenges inherent in its design and deployment.
The first level of the trigger system of the LHCb experiment (HLT1) reconstructs and selects events in real-time at the LHC bunch crossing rate in software using GPUs. It must carefully balance a broad physics programme that extends from kaon physics up to the electroweak scale. An automated procedure to determine selection criteria is adopted that maximises the physics output of the entirety of this programme while satisfying constraints from the higher-level components of the trigger system, which cap the output rate of HLT1 to around 1MHz. In this talk, the method by which this optimisation is achieved will be described in detail, which uses a variant of the ADAM algorithm popular in machine learning tools, customised in order to solve discrete minimisation problems. The impact of this optimisation on the first data taken by the LHCb experiment in its nominal Run 3 configuration will also be shown.
The architecture of the existing ALICE Run 3 on-line real time visualization solution was designed for easy modification of the visualization method used. In addition to the existing visualization based on the desktop application, a version using browser-based visualization has been prepared. In this case, the visualization is computed and displayed on the user's computer. There is no need to install any software on the user's computer. The overall visualization architecture used allows for a smooth switch to a new version of visualization: for a transition period both solutions (traditional desktop and web) can be used simultaneously.
ALICE visualization requires loading information about the displayed tracks (which may be several dozen thousand). This type of visualizations differs from visualizations typically used in computer graphics, where high efficiency of motion representation is achieved by modifying transformations describing the motion of already loaded models. In event visualization, the description of the tracks (models) changes with each view. Achieving high display performance requires the use of a number of optimization solutions.
The data downloaded by the web application is already pre-processed and prepared to be loaded to the graphics card, thanks to which the calculations in the browser are significantly simplified and the performance of the browser visualization is comparable to the visualization in the desktop application.
When creating a new visualization, a component approach to building a web application was used: individual components are responsible for various functions (e.g. data retrieval, different visualizations, interaction with the user). This construction of blocks allows for easy rearrangement by replacing or adding new components. The solution testing process is therefore significantly simplified because each component can be tested independently.
The LHCb experiment at CERN has undergone a comprehensive upgrade. In particular, its trigger system has been completely redesigned into a hybrid-architecture, software-only system that delivers ten times more interesting signals per unit time than its predecessor. This increased efficiency - as well as the growing diversity of signals physicists want to analyse - makes conforming to crucial operational targets on bandwidth and storage capacity ever more challenging. To address this, a comprehensive, automated testing framework has been developed that emulates the entire LHCb trigger and offline-processing software stack on simulated and real collision data. Scheduled both nightly and on-demand by software testers during development, these tests measure the online- and offline-processing's key operational performance metrics (such as rate and bandwidth), for each of the system's 3500 distinct physics selection algorithms, and their cumulative totals. The results are automatically delivered via concise summaries - to GitLab merge requests and instant messaging channels - that further link to an extensive dashboard of per-algorithm information. The dashboard and pages therein (categorised by physics working group) facilitate exploratory data analysis and test-driven trigger development by 100s of physicists, whilst the concise summaries enable efficient, data-driven decision-making by management and software maintainers. Altogether, this novel and performant bandwidth testing framework has been helping LHCb build an operationally-viable trigger and data-processing system whilst maintaining the efficiency to satisfy its physics goals.
Offline Computing
The imminent high-luminosity era of the LHC will pose unprecedented challenges to the CMS detector. To meet these challenges, the CMS detector will undergo several upgrades, including replacing the current endcap calorimeters with a novel High-Granularity Calorimeter (HGCAL). A dedicated reconstruction framework, The Iterative Clustering (TICL), is being developed within the CMS Software (CMSSW). This new framework is designed to fully exploit the high spatial resolution and precise timing information provided by HGCAL, as well as the information from other subdetectors (e.g., Tracker and Mip-Timing-Detector). Its reconstruction capabilities aim to provide the final global event interpretation while mitigating the effects of the dense pile-up environment. The TICL framework, crafted with heterogeneous computing in mind, is a unique solution to the computing challenges of the HL-LHC phase. Data structures and algorithms have been developed for massively parallel architectures using the Alpaka performance portability library. The framework reconstructs particle candidates starting from the hundreds of thousands of energy deposits left in the calorimeter. Dedicated clustering algorithms have been developed to retain the physics information while reducing the problem complexity by order of magnitudes. Pattern recognition algorithms aim to reconstruct particle showers in the 3-dimensional space, striving for high efficiency and cluster purity, keeping the pile-up contamination as low as possible. The high-purity requirements, together with detector inhomogeneity, lead to fragmented 3D clusters. An additional linking step is available to recover the fragmentation. In this step, several algorithms are adopted to target different types of particle shower reconstruction. A SuperClustering linking plugin has been developed for electron and photon reconstruction, while a geometrical linking is used to target the hadron reconstruction. The final charged candidates are built by linking Tracks with the HGCAL 3D clusters, exploiting timing information from both HGCAL and MTD. This presentation will introduce the TICL framework. Its physics and computational performance will be highlighted, showcasing the approach adopted to face the challenges of HL-LHC.
We present an ML-based end-to-end algorithm for adaptive reconstruction in different FCC detectors. The algorithm takes detector hits from different subdetectors as input and reconstructs higher-level objects. For this, it exploits a geometric graph neural network, trained with object condensation, a graph segmentation technique. We apply this approach to study the performance of pattern recognition in the IDEA detector using hits from the pixel vertex detector and the drift chamber. We also build particle candidates from detector hits and tracks in the CLD detector. Our algorithm outperforms current baselines in efficiency and energy reconstruction and allows pattern recognition in the IDEA detector. This approach is easily adaptable to new geometries and therefore opens the door to reconstruction performance-aware detector optimization.
Particle identification (PID) is crucial in particle physics experiments. A promising breakthrough in PID involves cluster counting, which quantifies primary ionizations along a particle’s trajectory in a drift chamber (DC), rather than relying on traditional dE/dx measurements. However, a significant challenge in cluster counting lies in developing an efficient reconstruction algorithm to recover cluster signals from DC cell waveforms.
In PID, machine learning algorithms have emerged as the state-of-the-art. For simulated samples, an updated supervised model based on LSTM and DGCNN achieves a remarkable 10% improvement in separating K from $\pi$ compared to traditional methods. For test beam data samples collected at CERN, due to label scarcity and data/MC discrepancy, a semi-supervised domain adaptation model, which exploits Optimal Transport to transfer information between simulation and real data domains, is developed. The model is validated using pseudo data and further applied to real data. The performance is superior to the traditional methods and maintains consistent across varying track lengths.
There are two related papers that have been submitted to journals: 2402.16270 and 2402.16493. The previous one about the transfer learning has been accepted by the Computer Physics Communications (https://doi.org/10.1016/j.cpc.2024.109208).
We present an end-to-end reconstruction algorithm for highly granular calorimeters that includes track information to aid the reconstruction of charged particles. The algorithm starts from calorimeter hits and reconstructed tracks, and outputs a coordinate transformation in which all shower objects are well separated from each other, and in which clustering becomes trivial. Shower properties such as particle ID and energy are predicted from representative points within showers. This is achieved using an extended version of the object condensation loss, a graph segmentation technique that allows the clustering of a variable number of showers in every event while simultaneously performing regression and classification tasks. The backbone is an architecture based on a newly-developed translation-equivariant version of GravNet layers. These dynamically build learnable graphs from input data to exchange information along their edges. The model is trained on data from a simulated detector that matches the complexity of the CMS high-granularity calorimeter (HGCAL).
In the recent years, high energy physics discoveries have been driven by the increasing of detector volume and/or granularity. This evolution gives access to bigger statistics and data samples, but can make it hard to process results with current methods and algorithms. Graph neural networks, particularly graph convolution networks, have been shown to be powerful tools to address these challenges. These methods however raise some difficulties with their computing resource needs. In particular, representing physics events as graphs is a tricky problem that demands a good balance between resource consumption and graph quality, which can greatly affects the accuracy of the model.
We propose a graph convolution network pipeline architecture to perform classification and regression tasks on calorimeter events and discuss its performances. It is designed for resource constrained environments, and in particular to efficiently represent calorimeter events as graphs, allowing up to a quadratic improvement in complexity with satisfying accuracy. Finally, we discuss possible applications to other high energy physics detectors.
Simulation and analysis tools
In this work we present the Graph-based Full Event Interpretation (GraFEI), a machine learning model based on graph neural networks to inclusively reconstruct events in the Belle II experiment.
Belle II is well suited to perform measurements of $B$ meson decays involving invisible particles (e.g. neutrinos) in the final state. The kinematical properties of such particles can be deduced from the energy-momentum imbalance obtained after reconstructing the companion $B$ meson produced in the event. This task is performed by reconstructing it either from all the particles in an event but the signal tracks, or using the Full Event Interpretation, an algorithm based on Boosted Decision Trees and limited to specific, hard-coded decay processes. A recent example involving the use of the aforementioned techniques is the search for the $B^+ \to K^+ \nu \bar \nu$ decay, that provided an evidence for this process at about 3 standard deviations.
The GraFEI model is trained to predict the structure of the decay chain by exploiting the information from the detected final state particles only, without making use of any prior assumptions about the underlying event. By retaining only signal-like decay topologies, the model considerably reduces the amount of background while keeping a relatively high signal efficiency. The performances of the model when applied to the search for $B^+ \to K^+ \nu \bar \nu$ are presented. The implementation of the model in the Belle II Analysis Software Framework is discussed.
In analyses conducted at Belle II, it is often beneficial to reconstruct the entire decay chain of both B mesons produced in an electron-positron collision event using the information gathered from detectors. The currently used reconstruction algorithm, starting from the final state particles, consists of multiple stages that necessitate manual configurations and suffers from low efficiency and a high number of wrongly reconstructed candidates.
Within this project, we are developing a software with the goal of automatically reconstructing B decays at Belle II with both high efficiency and accuracy. The trained models should be capable of accommodating rare decays with very small branching ratios, or even those that are unseen during the training phase.
To ensure optimal performance, the project is divided into the steps embedding of particles, particle reconstruction, and link prediction. Drawing inspiration from recent advancements in computer science, transformers and hyperbolic embedding are employed as fundamental components, with metric learning serving as the primary training technique.
Subatomic particle track reconstruction (tracking) is a vital task in High-Energy Physics experiments. Tracking, in its current form, is exceptionally computationally challenging. Fielded solutions, relying on traditional algorithms, do not scale linearly and pose a major limitation for the HL-LHC era. Machine Learning (ML) assisted solutions are a promising answer.
Current ML model design practice is predominantly ad hoc. We aim for a methodology for automated search of model designs, consisting of complexity reduced descriptions of the main problem, forming a complexity spectrum. As the main pillar of such a method, we provide the REDuced VIrtual Detector (REDVID) as a complexity-aware detector model and particle collision event simulator. Through a multitude of configurable dimensions, REDVID is capable of simulations throughout the complexity spectrum. REDVID can also act as a simulation-in-the-loop, to both generate synthetic data efficiently and to simplify the challenge of ML model design evaluation. With REDVID, starting from the simplistic end of the complexity spectrum, lesser designs can be eliminated in a systematic fashion, early on. REDVID is not bound by real detector geometries and can be considered for simulations involving arbitrary detector designs.
As a simulation and a generative tool for ML-assisted solution design, REDVID is highly flexible, reusable and open-source. Reference data sets generated with REDVID are publicly available. Data generated using REDVID has enabled rapid development of multiple novel ML model designs, which is currently ongoing.
Direct photons are unique probes to study and characterize the quark-gluon plasma (QGP) as they leave the collision medium mostly unscathed. Measurements at top Large Hadron Collider (LHC) energies at low pT reveal a very small thermal photon signal accompanied by considerable systematic uncertainties. Reduction of such uncertainties, which arise from the π0 and η measurements, as well as the photon identification, is crucial for the comparison of the results with the theoretical calculations that are available.
To address these challenges, a novel approach employing machine learning (ML) techniques has been implemented for the classification of photons and neutral mesons. An open-source set of frameworks comprising hipe4ml, scikit-learn, and ONNX packages is chosen for training, validation,and testing the model on a part of Run2 Pb–Pb data at √sNN = 5.02 TeV collision energy.
In this talk, the performance of the novel approach in comparison to the standard cut-based analysis is presented. Initial findings employing gradient-boosted decision trees demonstrate a substantial enhancement in photon purity while preserving efficiency levels comparable to those of the standard cut-based method. Strategies for addressing highly imbalanced data sets, including techniques like feature reduction during training and the implementation of scaled penalty factors to enhance discrimination between signal and background are also addressed. Finally, the feasibility of incorporating such ML methods into the main workflow of direct photon analysis is also presented.
Particle flow reconstruction at colliders combines various detector subsystems (typically the calorimeter and tracker) to provide a combined event interpretation that utilizes the strength of each detector. The accurate association of redundant measurements of the same particle between detectors is the key challenge in this technique. This contribution describes recent progress in the ATLAS experiment towards utilizing machine-learning to improve particle flow in the ATLAS detector. In particular, point-cloud techniques are utilized to associate measurements from the same particle, leading to reduced confusion compared to baseline techniques. Next steps towards further testing and implementation will be discussed.
Accurate modeling of backgrounds for the development of analyses requires large enough simulated samples of background data. When searching for rare processes, a large fraction of these expensively produced samples is discarded by the analysis criteria that try to isolate the rare events. At the Belle II experiment, the event generation stage takes only a small fraction of the computational cost of the whole simulation chain, motivating filters for the simulation at this stage. Deep neural network architectures based on graph neural networks have been proven useful to predict approximately which events will be kept after the filter, even in cases where there is no simple correlation between generator and reconstruction level quantities. However, training these models requires large training data sets, which are hard to obtain for filters with very low efficiencies. In this presentation we show how a generic model, pre-trained on filters with high efficiencies can be fine-tuned to also predict filters where only little training data is available. This also opens opportunities for online learning during the simulation process where no separate training step is required.
Collaborative software and maintainability
Given the recent slowdown of the Moore’s Law and increasing awareness of the need for sustainable and edge computing, physicists and software developers can no longer just rely on computer hardware becoming faster and faster or moving processing to the cloud to meet the ever-increasing computing demands of their research (e.g. the data rate increase in HL-LHC). However, algorithmic optimisations alone are also starting to be insufficient, so novel computing paradigms spanning both software and hardware appear. Adapting existing and new software to them may be difficult though, especially for large and complex applications. This is where profiling can help bridge the gap, but finding a suitable profiler is challenging when a low overhead, wide architectural support, and reliability are important.
As a response to the above problem, AdaptivePerf was developed. It is an open-source, architecture-portable, and low-overhead profiling tool with custom-patched Linux perf as its main foundation, currently available on GitHub. Thanks to the extensive research and modifications, AdaptivePerf improves the main shortcomings of perf such as incomplete stack traces. It profiles how threads and processes are created within a program and what code segments within each thread/process should be considered on- or off-CPU bottlenecks, in terms of both consumed time and other hardware metrics like cache misses. If a user-friendly visualisation is needed, AdaptivePerf can present results as a timeline with the process tree, where corresponding non-time-ordered and time-ordered flame graphs can be browsed along with functions spawning new threads/processes.
The tool has already been shown to work on x86-64 and RISC-V and is designed in the context of the SYCLOPS EU project, which CERN is part of and where solutions for heterogeneous architectures are developed, e.g. custom RISC-V cores tailored to a specific problem, RISC-V support for SYCL, and SYCL-accelerated algorithms in ROOT. In this presentation, we will talk about the profiler, its place within the project, and how it can be used for software-hardware co-design for HEP.
The software framework of the Large Hadron Collider Beauty (LHCb) experiment, Gaudi, heavily relies on the ROOT framework and its I/O subsystems for data persistence mechanisms. Gaudi internally leverages the ROOT TTree data format, as it is currently used in production by LHC experiments. However, with the introduction and scaling of multi-threaded capabilities within Gaudi, the limitations of TTree as a data storage backend have become increasingly apparent, marking it as a non-negligible bottleneck in data processing workflows.
The following work introduces a comprehensive two-part enhancement to Gaudi to address this challenge. An initial focus is given to optimizing the current n-tuple writing infrastructure to be thread-safe within the constraints of the existing TTree backend, thus maintaining compatibility for users and downstream applications. This phase is then followed by the migration of the n-tuple storage backend from TTree to RNTuple, ROOT's next-generation I/O subsystem for physics data storage. This migration aims at leveraging the thread-safe, asynchronous capabilities of the new data format, thus making Gaudi fit to handle the requirements of HL-LHC computing and beyond.
Keywords: LHCb; Gaudi; ROOT; TTree; RNTuple; thread-safety
A data quality assurance (QA) framework is being developed for the CBM experiment. It provides flexible tools for monitoring of reference quantity distributions for different detector subsystems and data reconstruction algorithms. This helps to identify software malfunctions and calibration status, to prepare a setup for the data taking and to prepare data for the production. A modular structure of the QA framework allows to keep independent QA units for different steps of the data reconstruction.
Since the offline and the online scenarios of data reconstruction need to meet different requirements, the QA framework is implemented differently for those two regimes. In the offline scenario, the data QA software is based on the FairRoot framework and is used to track the effects on data in the continuous development of the reconstruction algorithms as well as to check the data quality on the production stage. The QA software for the online reconstruction scenario utilizes the standard and boost C++ libraries and provides a real-time monitoring of detector and algorithm performance. This was successfully applied to the data taking at the mini-CBM experiment in May 2024.
CHEP Track: 6 - Collaborative software and maintainability
The LHCb high-level trigger applications consists of components that run reconstruction algorithms and perform physics object selections, scaling from hundreds to tens of thousands depending on the selection stage. The configuration of the components, the data flow and the control flow are implemented in Python. The resulting application configuration is condensed in the basic form of a list of components with their properties and values.
It is often required to change configuration without deploying new binaries. Moreover, it is essential to be able to reproduce a given production configuration and to be able query it after it has been used. For these reasons, the basic form of the trigger configuration is captured and stored in a Git database.
This contribution is describing the infrastructure around generating and validating the configurations. The process is based on GitLab pipelines that are triggered on user defined specifications and run several steps ranging from basic checks to performance validation using dedicated runners. Upon merging, the configuration database is deployed on CVMFS. The process as implemented ensures consistency and reproducibility across all selection stages.
This project also aims to take advantage of the query-able nature of the configurations by creating an API that allows probing a single configuration in detail. This is further used to create human-readable summaries and to track changes across configurations to help analysts understand the selections used to collect their datasets.
At the core of CERN's mission lies a profound dedication to open science; a principle that has fueled decades of ground-breaking collaborations and discoveries. This presentation introduces an ambitious initiative: a comprehensive catalogue of CERN's open-source projects, purveyed by CERN’s own OSPO. The mission? To spotlight every flag-bearing and nascent project under the CERN umbrella, making them accessible and known to the world.
This catalogue is a testament to CERN's commitment to open science and a tool to highlight all the pros of open source, foster collaboration, and stimulate innovation across the global scientific community. By curating this catalogue, the OSPO aims to not only showcase the breadth and depth of CERN's contributions to open-source software, but also to pave the way for engagement with researchers, external developers, and different institutions.
Discover how we're making open-source projects at CERN visible and why this matters for the future of scientific research. From technical challenges and solutions, to the strategic importance of open source in pushing HE(N)P discoveries forward, the journey so far has been filled with insights and stories that echo the essence that pushes for innovation at CERN. This is not just about showcasing projects; it's about building bridges in the open-source community and contributing to a legacy of open science.
Computing Infrastructure
The ePIC collaboration is working towards the realization of the first detector at the upcoming Electron-Ion Collider. As part of our computing strategy, we have settled on containers for the distribution of our modular software stacks using spack as the package manager. Based on abstract definitions of multiple mutually consistent software environments, we build dedicated containers on each commit of every pull request for the software projects under our purview. This is only possible through judicious caching from container layers, over downloaded artifacts and binary builds, down to individual compiled files. These containers are subsequently used for our benchmark and validation workflows. Our container build infrastructure runs with redundancy between GitHub and self-hosted GitLab resources, and can take advantage of cloud-based resources in periods of peak demand. In this talk, I will discuss our experiences with newer features of spack, including storing build products as OCI layers and inheritance of previously concretized environments for software stack layering.
The economies of scale realised by institutional and commercial cloud providers make such resources increasingly attractive for grid computing. We describe an implementation of this approach which has been deployed for
Australia's ATLAS and Belle II grid sites.
The sites are built entirely with Virtual Machines (VM) orchestrated by an OpenStack [1] instance. The Storage Element (SE) utilises an xrootd-s3 gateway [2][3] with back-end storage provided through an S3-compatible object store from a commercial provider. The provisioning arrangements required the deployment of some site-specific helper modules to ensure all SE interfacing requirements could be met. OpenStack hosts the xrootd redirector and proxy servers in separate VMs.
The Compute Element (CE) comprises virtual machines (VM) within the Openstack instance. Jobs are submitted and managed by HTCondor [4]. A CloudScheduler [5][6] instance is used to coordinate the number of active OpenStack VMs and ensure that VMs run only when there are jobs to run.
Automated configuration of the individual VMs associated with the grid sites is managed using Ansible [7]. This approach was chosen due to its low overheads and the simplicity of deployment.
Performance metrics of the resulting grid sites will be presented to illustrate the viability of this cost-effective approach to resource provisioning for grid computing.
[1] OpenStack: https://www.openstack.org/
[2] Xrootd: https://xrootd.slac.stanford.edu/
[3] Andrew Hanushevsky and Wei Yang: "Xrootd S3 Gateway for WLCG Storage", 26th International Conference on Computing in High Energy & Nuclear Physics (CHEP 2023), https://doi.org/10.1051/epjconf/202429501057
[4] HTCondor: https://htcondor.org/htcondor/overview/
[5] CloudScheduler: https://github.com/hep-gc/cloudscheduler
[6] Randall Sobie, F. Berghaus, K. Casteels, C. Driemel, M. Ebert, F. F. Galindo, C. Leavett-Brown, D. MacDonell, M. Paterson, R. Seuster, S. Tolkamp, J. Weldon: "cloudScheduler a VM provisioning system for a distributed compute cloud", 24th International Conference on Computing in High-Energy and Nuclear Physics (CHEP 2019), https://doi.org/10.1051/epjconf/202024507031
[7] Ansible: https://www.ansible.com/
A large fraction of computing workloads in high-energy and nuclear physics is executed using software containers. For physics analysis use, such container images often have sizes of several gigabytes. Executing a large number of such jobs in parallel on different compute nodes efficiently, demands the availability and use of caching mechanisms and image loading techniques to prevent network saturation and significantly reduce startup time. Using the industry-standard containerd container runtime for pulling and running containers, enables the use of various so-called snapshotter plugins that “lazily” load container images. We present a quantitative comparison of the performance of the CVMFS, SOCI, and Stargz snapshotter plugins. Furthermore, we also evaluate the user-friendliness of such approaches and discuss how such seamlessly containerised workloads contribute to the reusability and reproducibility of physics analyses.
In recent years, the CMS experiment has expanded the usage of HPC systems for data processing and simulation activities. These resources significantly extend the conventional pledged Grid compute capacity. Within the EuroHPC program, CMS applied for a "Benchmark Access" grant at VEGA in Slovenia, an HPC centre that is being used very successfully by the ATLAS experiment. For CMS, VEGA was integrated transparently as a sub-site extension to the Italian Tier-1 site at CNAF. In that first approach, only CPU resources were used, while all storage access was handled via CNAF through the network. Extending Grid sites with HPC resources was an established concept for CMS, however, in this project, HPC resources located in a different country from the Grid site were first integrated. CMS used the allocation primarily to validate a recent CMSSW release regarding its readiness for GPU usage. Former developments in the CMS workload management system that allow the targeting of GPU resources in the distributed infrastructure turned out to be instrumental and jobs could be submitted like any other release validation workflow. The presentation will detail aspects of the actual integration, some required tuning to achieve reasonable GPU utilisation, and an assessment of operational parameters like error rates compared to traditional Grid sites.
The Italian National Institute for Nuclear Physics (INFN) has recently developed a national cloud platform to enhance access to distributed computing and storage resources for scientific researchers. A critical aspect of this initiative is the INFN Cloud Dashboard, a user-friendly web portal that allows users to request high-level services on demand, such as Jupyter Hub, Kubernetes, and Spark clusters.
The platform is based on INDIGO-PaaS middleware, which integrates a TOSCA-based orchestration system. This system supports a lightweight federation of cloud sites and automates resource scheduling for optimal resource allocation.
Through the internal INFN DataCloud project and European initiatives like interTwin, INFN is undertaking a comprehensive overhaul of its PaaS system to adapt to evolving technologies and replace outdated software components. To further improve the orchestration system, INFN is exploring the use of artificial intelligence to enhance deployment scheduling.
Additionally, the dashboard, serving as a user interface for orchestrating and deploying services, has recently undergone significant renovations to boost usability and security. This contribution aims to highlight key advancements in the PaaS orchestration system designed to offer a reliable, scalable, and user-friendly environment for the computational needs of the scientific community.
Norwegian contributions to the WLCG consist of computing and storage resources in Bergen and Oslo for the ALICE and ATLAS experiments. The increasing scale and complexity of Grid site infrastructure and operation require integration of national WLCG resources into bigger shared installations. Traditional HPC resources often come with restrictions with respect to software, administration, and accessibility. Furthermore, expensive HPC infrastructure like fast interconnects is hardly used by grid workload.
As a cost-efficient solution, the Norwegian Grid resources are operated as two platforms within NREC, the Norwegian Research and Education Cloud, which is a cloud computing service operated by the Universities of Oslo and Bergen. It aims to provide easily accessible computing and storage infrastructure for national academic and scientific applications.
By using cloud technology instead of traditional HPC resources, WLCG installations benefit from a high degree of accessibility, flexibility, and scalability while the service provider ensures reliable and secure operation of infrastructure and network.
Orchestration of the virtual instances is based on the Infrastructure-as-a-service paradigm and implemented as declarative configuration files in Terraform. All custom host configuration, software deployment and cluster configuration are implemented as YAML code and deployed using Ansible.
This concept allows for the delivery of high-quality WLCG services with key features such as: fixed and opportunistic computing resources; ARC and JAliEn grid middleware; Slurm and HTCondor backend; CEPH disk storage integrated into Neic NDGF dCache; integrated tape storage; monitoring and alerting based on Prometheus/Grafana ecosystem; fully controlled setup by site admin; scalable extension; quick failover and recovery.
This presentation describes the capabilities of the Norwegian Research and Education Cloud and the strategy for provisioning of Grid computing and storage using the IaaS approach. Details on cluster management and monitoring as a service, flexible cluster orchestration, scalability and performance studies will be highlighted in the presentation.
Collaboration, Reinterpretation, Outreach and Education
CERN openlab is a unique resource within CERN that works to establish strategic collaborations with industry, fuel technological innovation and expose novel technologies to the scientific community.
ICT innovation is needed to deal with the unprecedented levels of data volume and complexity generated by the High Luminosity LHC. The current CERN openlab Phase VIII is designed to tackle these challenges on a number of fronts, including, but not limited to: heterogeneous computing, platforms, and infrastructures; novel storage, compression, and data management solutions; emerging low-latency interconnect and link protocols; and the exploitation of artificial intelligence algorithms across a multitude of domains, including edge devices for real-time event selection and triggering. The evaluation and adoption of these technologies are being accelerated by ongoing collaborations between industrial leaders in the relevant fields and the scientific community at CERN. The work of ongoing focussed projects in these areas will be summarised, and results demonstrating their impact will be shown. Incubator projects on emerging technologies such as digital twins and generative AI will be presented, as well as the next steps in these R&D efforts.
GlideinWMS is a workload manager provisioning resources for many experiments including CMS and DUNE. The software is distributed both as native packages and specialized production containers. Following an approach used in other communities like web development
we built our workspaces, system-like containers to ease development and testing.
Developers can change the source tree or check out a different branch and quickly reconfigure the services to see the effect of their changes.
In this paper, we'll talk about what differentiates workspaces from other containers.
We'll describe our base system composed of three containers. A one-node cluster including a compute element and a batch system. A GlideinWMS Factory controlling pilot jobs. And a scheduler and Frontend, to submit jobs and provision resources. Additional containers can be used for optional components. This system can easily run on a laptop and we'll share our evaluation of different container runtimes, with an eye for ease of use and performance.
Finally, we'll talk about our experience as developers and with students.
The GlideinWMS workspaces are easily integrated with IDEs like VS Code, simplifying debugging and allowing development and testing of the system also when offline.
They simplified the training and onboarding of new team members and Summer interns.
And they were useful in workshops where students could have first-hand experience with the mechanisms and components that, in production, run millions of jobs.
Virtual Reality (VR) applications play an important role in HEP Outreach & Education. They make it possible to organize virtual tours of the experimental infrastructure by virtually interacting with detector facilities, describing their purpose and functionalities. However, nowadays VR applications require expensive hardware, like the Oculus headset or MS Hololense, and powerful computers. As a result, this reduces the reach of VR application implementation and makes their benefits questionable. An important improvement to VR development is thus to facilitate the usage of inexpensive hardware, like Google cardboard and phones with average computational power.
Requirements to use inexpensive hardware and achieve quality and performance close to the advanced hardware bring challenges to the VR application developers. One of these challenges concerns the geometry of the 3D VR scenes. Geometry defines the quality of the 3D scenes and at the same time causes big loads on the GPU. Therefore, development methods of the geometry make it possible to find a good balance between the quality and performance of the VR applications.
The paper describes methods of the simplification of the "as-built" geometry descriptions; ways to reduce the number of facets to meet the GPU limitations in performance, and ensure the smooth movement in the VR scenes.
Data Preservation (DP) is a mandatory specification for any present and future experimental facility and it is a cost-effective way of doing fundamental research by exploiting unique data sets in the light of the ever increasing theoretical understanding. When properly taken into account, DP leads to a significant increase in the scientific output (10% typically) for a minimal investment overhead (0.1%). DP relies on and stimulates cutting-edge technology developments and is strongly linked to Open Science and FAIR data paradigms. A recently released report (Eur.Phys.J.C 83 (2023) 9, 795 | 2302.03583 [hep-ex] ) summarizes the status of data preservation in high energy physics from a perspective of more than ten years of experience with a structured effort at international level (DPHEP).
With the onset of ever more data collected by the experiments at the LHC and the increasing complexity of the analysis workflows themselves, there is a need to ensure the scalability of a physics data analysis. Logical parts of an analysis should be well separated - the analysis should be modularized. Where possible, these different parts should be maintained and reused for other analyses or reinterpretation of the same analysis.
Also, having an analysis prepared in such a way helps to ensure its reproducibility and preservation in the context of good data and analysis code management practices following the FAIR principles. In this talk, a few different topics on analysis modularization are discussed. An analysis on searches for pentaquarks within the LHCb experiment at CERN is used as an example.
Collaborative software development for particle physics experiments demands rigorous code review processes to ensure maintainability, reliability, and efficiency. This work explores the integration of Large Language Models (LLMs) into the code review process, with a focus on utilizing both commercial and open models. We present a comprehensive code review workflow that incorporates LLMs, integrating various enhancements such as multi-agent capabilities and reflection. Furthermore, tools are employed to facilitate the verification of suggested code changes before presentation in the review. By harnessing the capabilities of LLMs, the review process can uncover faults and identify improvements that traditional automated analysis tools may overlook. This integration shows promise for improving code quality, reducing errors, and fostering collaboration among developers in the field of particle physics software development.
The sheer volume of data generated by LHC experiments presents a computational challenge, necessitating robust infrastructure for storage, processing, and analysis. The Worldwide LHC Computing Grid (WLCG) addresses this challenge by integrating global computing resources into a cohesive entity. To cope with changes in the infrastructure and increased demands, the compute model needs to be adapted. Simulations of different compute models present a feasible approach for evaluating different design candidates. However, running these simulations incurs a trade-off between accuracy and scalability. For example, while the simulator DCSim can provide accurate results, it falls short on scalability when increasing the size of the simulated platform. Generative Machine Learning as a surrogate is successfully used to overcome these limitations in other domains that exhibit similar trade-offs between scalability and accuracy, such as the simulation of detectors.
In our work, we evaluate the usage of three different machine learning models as surrogate models for the simulation of distributed computing systems and assess their ability to generalize to unseen jobs and platforms. We show that those models can predict the simulated platforms' main observables derived from the execution traces of compute jobs with approximate accuracy. Potential for further improving the predictions lies in using other machine learning models and different encodings of the platform-specific information to achieve better generalizability for unseen platforms.
In the ATLAS analysis model, users must interact with specialized algorithms to perform a variety of tasks on their physics objects including calibration, identification, and obtaining systematic uncertainties for simulated events. These algorithms have a wide variety of configurations, and often must be applied in specific orders. A user-friendly configuration mechanism has been developed with the goal of improving the user experience from the perspective of both ease-of-use and stability. Users can now configure necessary algorithms via a YAML file, enabled by a physics-oriented python configuration. The configuration mechanism and training will be discussed.
We explore applications of quantum graph neural network(QGNN) on physics and non-physics data set. Based on a single quantum circuit architecture, we perform node, edge, and graph-level prediction tasks. Our main example is particle trajectory reconstruction starting from a set of detector data. Along with this, we expand our analysis on artificial helical trajectory data set. Finally, we will check how our quantum algorithm applies for non-physics data set as well by looking at Fingerprint data set in MUTAG, and AIDS data set, which collects molecular compounds graphs, foucisng on graph-level task.
The ATLAS experiment involves over 6000 active members, including students, physicists, engineers, and researchers, and more than 2500 members are authors. This dynamic CERN environment brings up some challenges, such as managing the qualification status of each author. The Qualification system, developed by the Glance team, aims to automate the processes required for monitoring the progress of ATLAS members as they work to achieve author status. Recently, ATLAS modified the policy governing authorship qualification, and updates were necessary to put the changes into effect.
The system’s code was originally developed on top of an outdated framework. In order to ease the transition to the new ATLAS authorship qualification policy, the code was updated to a Hexagonal architecture based on Domain Driven Design philosophy. The access to the database has shifted from ORM - Object Relational Mapper - to SQL repositories to align with the team’s development stack. The system's quality is ensured with automatic tests as part of an effective refactoring process transparent for the end user. This refactoring strategy enhances our system to meet both previously unaddressed and new requirements, to improve code maintainability, and to increase flexibility to accommodate possible future changes in the qualification policy.
The software of the ATLAS experiment at the CERN LHC accelerator contains a number of tools to analyze (validate, summarize, peek into etc.) all its official data formats recorded in ROOT files. These tools - mainly written in the Python programming language - handle the ROOT TTree which is currently the main storage object format of ROOT files. However, the ROOT project has developed an alternative to TTree, called RNTuple. The new storage format offers significant improvements and ATLAS plans to adopt it in LHC Run 4. Work is ongoing to enhance the tools in order to handle the RNTuple storage format in addition to TTree in a transparent for the user way. The work is aided by modern and detailed APIs provided by RNTuple. We will present the progress made and lessons learnt.
The ATLAS Tile Calorimeter (TileCal) is the central hadronic calorimeter of the ATLAS detector at the Large Hadron Collider at CERN. It plays an important role in the reconstruction of jets, hadronically decaying tau leptons and missing transverse energy, and also provides information to the dedicated calorimeter trigger. The TileCal readout is segmented into nearly 10000 channels that are calibrated using the dedicated calibration systems such as laser, charge injection, integrator and Cesium source.
Data quality assurance is paramount, with collision and calibration data subject to rigorous scrutiny. Automated checks are performed on predefined histograms, and the results are summarized on dedicated web pages. Operators use a suite of tools to further inspect the data and identify any issues or irregularities. The TileCal conditions data, including calibration constants and channel statuses, are therefore regularly updated in databases. These databases are used for data reprocessing and are also crucial for maintenance work during the technical stops.
In this talk, we will discuss the software tools used for data quality monitoring, emphasizing recent advancements and our pursuit of consolidating multiple tools into a more streamlined web application. Our overarching goal is to optimize the efficiency of the shifters responsible for monitoring data quality while simultaneously simplifying the entire process.
The distributed computing of the ATLAS experiment at the Large Hadron Collider (LHC) utilizes computing resources provided by the Czech national High Performance Computing (HPC) center, IT4Innovations. This is done through ARC-CEs deployed at the Czech Tier2 site, praguelcg2. Over the years, this system has undergone continuous evolution, marked by recent enhancements aimed at improving resource utilization efficiency.
One key enhancement involves the implementation of the HyperQueue meta-scheduler. It enables a division of whole-node jobs into several smaller, albeit longer, jobs, thereby enhancing CPU efficiency. Additionally, the integration of cvmfsexec enables access to the distributed CVMFS filesystem on compute nodes without requiring any special configurations, thereby substantially simplifying software distribution and broadening the range of tasks eligible for execution on the HPC. Another notable change was the migration of the batch system from PBSpro to Slurm.
The data processing and analyzing is one of the main challenges at HEP experiments, normally one physics result can take more than 3 years to be conducted. To accelerate the physics analysis and drive new physics discovery, the rapidly developing Large Language Model (LLM) is the most promising approach, it have demonstrated astonishing capabilities in recognition and generation of text while most parts of physics analysis can be benefitted. In this talk we will discuss the construction of a dedicated intelligent agent, an AI assistant at BESIII based on LLM, the potential usage to boost hadron spectroscopy study, and the future plan towards a AI scientist.
The huge volume of data generated by scientific facilities such as EuXFEL or LHC places immense strain on the data management infrastructure within laboratories. This includes poorly shareable resources of archival storage, typically, tape libraries. Maximising the efficiency of these tape resources necessitates a deep integration between hardware and software components.
CERN's Tape Archive (CTA) is an open-source storage management system developed by CERN to handle LHC data on tape. Although the primary target of CTA is CERN Tier-0, the Data Management Group considers CTA as the compelling alternative to commercial Hierarchical Storage Management (HSM) systems.
dCache, with its adaptable tape interface allows connectivity to any tape system. Collaborating closely with the CERN Tape Archive team, we have been working on the seamless integration of CTA into the dCache ecosystem.
This work shows the design, current progress, and initial deployment experiences of the dCache-CTA integration at DESY.
Monitoring the status of a high throughput computing cluster running computationally intensive production jobs is a crucial yet challenging system administration task due to the complexity of such systems. To this end, we train autoencoders using the Linux kernel CPU metrics of the cluster. Additionally, we explore assisting these models with graph neural networks to share information across threads within a compute node. The models are compared in terms of their ability to: 1) Produce a compressed latent representation that captures the salient features of the input, 2) Detect anomalous activity, and 3) Make distinction between different kinds of jobs run at Jefferson Lab. The goal is to have a robust encoder whose compressed embeddings are used for several downstream tasks. We extend this study further by deploying these models in a human-in-the-loop production-based setting for the anomaly detection task and discuss the associated implementation aspects such as continual learning and the criterion to generate alarms. This study represents a first step in the endeavor towards building self-supervised large-scale foundation models for computing centers.
Coprocessors, especially GPUs, will be a vital ingredient of data production workflows at the HL-LHC. At CMS, the GPU-as-a-service approach for production workflows is implemented by the SONIC project (Services for Optimized Network Inference on Coprocessors). SONIC provides a mechanism for outsourcing computationally demanding algorithms, such as neural network inference, to remote servers, where requests from multiple clients are intelligently distributed across multiple GPUs by a load-balancing service. This talk highlights the recent progress in deploying SONIC at selected U.S. CMS Tier-2 data centers. Using realistic CMS Run3 data processing workflows, such as those containing transformer-based algorithms, we demonstrate how SONIC is integrated into the production-like environment to enable accelerated inference offloading. We will present developments from both the client and server sides, including production job and data center configurations for NVIDIA and AMD GPUs. We will also present performance scaling benchmarks and discuss the challenges of operating SONIC in CMS production, such as server discovery, GPU saturation, fallback server logic, etc.
The event builder in the Data Acquisition System (DAQ) of the CMS experiment at the CERN Large Hadron Collider (LHC) is responsible for assembling events at a rate of 100 kHz during the current LHC run 3, and 750 kHz for the upcoming High Luminosity LHC, scheduled to start in 2029. Both the current and future DAQ architectures leverage on state-of-the-art network technologies, employing Ethernet switches capable of supporting RoCE protocols. The DAQ Front-end hardware is custom-designed, utilizing a reduced TCP/IP protocol implemented in FPGA for reliable data transport between custom electronics and commercial computing hardware.
An alternative architecture for the event builder, known as the File-based Event Builder (FEVB), is under evaluation. The FEVB comprises two separate systems: the Super-Fragment Builder (SFB) and the Builder File-based Filter Farm (BF3).
A super-fragment consists of the event data read by one or more Front-End Drivers and corresponding to the same L1 accept, and the SFB constructs multiple super-fragments corresponding to the number of Read-Unit (RU) machines in the DAQ system, storing them in local RAM disks. Subsequently, the BF3 accesses super-fragments from all RU machines via the Network File System (NFS) over Ethernet and builds complete events within the High Level Trigger process.
This paper describes the first prototype of the FEVB and presents preliminary performance results obtained within the DAQ system for LHC Run 3.
The LHCb Experiment employs GPU cards in its first level trigger system to enhance computing efficiency, achieving a data rate of 40Tb/s from the detector. GPUs were selected for their computational power, parallel processing capabilities, and adaptability.
However, trigger tasks necessitate extensive combinatorial and bitwise operations, ideally suited for FPGA implementation. Yet, FPGA adoption for compute acceleration is hindered by steep learning curves and very different programming paradigms with respect to GPUs and CPUs. In the last few years,interest in high level synthesis has grown because of the possibility of developing FPGA gateware in higher-level languages.
This study assesses the Intel® oneAPI FPGA Toolkit, which aims to simplify the development of FPGA-accelerated workloads by offering a GPU-like programming framework. We detail the integration of a portion of the current pixel clustering algorithm into oneAPI, address common implementation challenges, and compare it against CPU, GPU, and RTL implementations.
Our findings showcase promising outcomes for this emerging technology, potentially facilitating the repurposing of FPGAs in the data acquisition system as compute accelerators during idle data-taking periods.
Computing Centers always look for new server systems that can reduce operational costs, especially power consumption, and provide higher performance.
ARM-CPUs promise higher energy efficiency than x86-CPUs.
Therefore, the WLCG Tier1 center GridKa will partially use worker nodes with ARM-CPUs and has already carried out various power consumption and performance tests based on the HEPScore23 benchmark.
Various system settings, such as maximum CPU frequency, were studied to determine the best performance and highest energy efficiency of the ARM-CPU systems.
GridKa will provide the HEP community with several ARM-CPU worker nodes in their batch farm.
We present the results of these benchmarks on systems with ARM-CPUs compared to benchmarks of current x86-CPU worker nodes at GridKa and the status of provisioning ARM-CPU worker nodes to the community.
Dirac, a versatile grid middleware framework, is pivotal in managing computational tasks and workflows across a spectrum of scientific research domains including high energy physics and astrophysics. Historically, Dirac has employed specialized descriptive languages that, while effective, have introduced significant complexities and barriers to workflow interoperability and reproducibility. These challenges have become particularly pressing in light of the reproducibility crisis - an ongoing and pervasive issue that surfaced prominently in the early 2010s, marked by difficulties in replicating scientific results across different studies.
In response to these challenges, the integration of the Common Workflow Language (CWL) into Dirac represents a transformative development. CWL is a specification dedicated to the unambiguous definition and execution of computational workflows, facilitating their shareability and reusability across diverse computing environments. Its adoption within Dirac aims to standardize the description of computational tasks, thereby enhancing both reproducibility and interoperability.
By streamlining the interface for defining computational tasks within Dirac, we enable researchers to effortlessly transition workflows from local to grid-scale environments and foster compatibility with a broader ecosystem of scientific tools. This integration promises not only to mitigate the challenges posed by the reproducibility crisis but also to significantly lower the threshold for engaging with complex computational infrastructures, thus accelerating scientific discovery and innovation across multiple disciplines.
CERN has a huge demand for computing services. To accommodate this requests, a highly-scalable and highly-dense infrastructure is necessary.
To accomplish this, CERN adopted Kubernetes, an open-source container orchestration platform that automates the deployment, scaling, and management of containerized applications.
This session will discuss the strategies and tooling used to simplify the use of Kubernetes, in particular:
- one-click deployment of any application from a git repository
- zero-config creation of CD pipelines
- specialized managed clusters for common use cases
- dashboards to manage deployments across different clusters
In this study, we introduce the JIRIAF (JLAB Integrated Research Infrastructure Across Facilities) system, an innovative prototype of an operational, flexible, and widely distributed computing cluster, leveraging readily available resources from Department of Energy (DOE) computing facilities. JIRIAF employs a customized Kubernetes orchestration system designed to integrate geographically dispersed resources into a unified, elastic distributed cluster. This system operates without the need for additional infrastructure investments by resource providers. Notably, JIRIAF has demonstrated a capability to process data streams at rates up to 100 Gbps, facilitating real-time data-stream processing across vast distances.
Furthermore, we developed a digital representation of workflows using a Bayesian probability graph model. This model utilizes a standard joint probability distribution to represent various probabilities associated with the digital state, including relevant quantities and potential rewards, all derived from observed actions and data. The determination of these quantities and rewards employs queueing theory, focusing on two critical metrics: the rate of workflow input and the processing rate. Our results confirm the efficacy of the JIRIAF digital twin in managing and orchestrating highly distributed workflows, showcasing its potential to significantly enhance computational resource utilization and process efficiency in complex environments.
In the realm of high-energy physics research, the demand for computational
power continues to increase, particularly in online applications such as Event
Filter. Innovations in performance enhancement are sought after, leading to
exploration in integrating FPGA accelerators within existing software
frameworks like Athena, extensively employed in the ATLAS experiment at CERN.
This presentation delves into the intricacies of this integration, focusing on
the system-level challenges posed by the simultaneous utilization of FPGA
resources by multiple Athena algorithms in the heterogeneous computing
environment explored for the TDAQ Phase II upgrade.
Central to this discussion is the notion of shared state management,
particularly concerning the loading of FPGA bitstreams. As multiple algorithms
contend for access to the same FPGA, efficient management of the FPGA's state
becomes crucial to ensure optimal performance and resource utilization. This
work addresses this challenge, presenting insights and strategies for
orchestrating FPGA resource sharing within the Athena framework.
While still a work in progress, this contribution provides valuable insights
into the ongoing efforts to seamlessly integrate FPGA accelerators into complex
research environments, paving the way for enhanced computational capabilities.
This study explores possible enhancements in analysis speed, WAN bandwidth efficiency, and data storage management through an innovative data access strategy. The proposed model introduces specialized "delivery" services for data preprocessing, which include filtering and reformatting tasks executed on dedicated hardware located alongside the data repositories at the CERN Tier-0 or at Tier-1 or Tier-2 facilities. Positioned near the source storage, these services are crucial for limiting redundant data transfers and focus on sending only vital data to distant analysis sites, aiming to optimize network and storage use at those sites. Within the scope of the NSF-funded FABRIC Across Borders (FAB) initiative, we assess this model using an "in-network, edge" computing cluster at CERN, outfitted with substantial processing capabilities (CPU, GPU, and advanced network interfaces). This edge computing cluster features dedicated network peering arrangements that link CERN Tier-0, the FABRIC experimental network, and an analysis center at the University of Chicago, creating a solid foundation for our research.
Central to our infrastructure is ServiceX, an R&D software project under the Data Organization, Management, and Access (DOMA) group of the Institute for Research and Innovation in Software for High Energy Physics (IRIS-HEP). ServiceX is a scalable filtering and reformatting service, designed to operate within a Kubernetes environment and deliver output to an S3 object store at an analysis facility. Our study assesses the impact of server-side delivery services in augmenting the existing HEP computing model, particularly evaluating their possible integration within the broader WAN infrastructure. This model could empower Tier-1 and Tier-2 centers to become efficient data distribution nodes, enabling a more cost-effective way to disseminate data to analysis sites and object stores, thereby improving data access and efficiency. This research is experimental and serves as a demonstrator of the capabilities and improvements that such integrated computing models could offer in the HL-LHC era.
The ATLAS Metadata Interface (AMI) ecosystem has been developed within the context of ATLAS, one of the largest scientific collaborations. AMI is a mature, generic, metadata-oriented ecosystem that has been maintained for over 23 years. This paper briefly describes the main applications of the ecosystem within the experiment, including metadata aggregation for millions of datasets and billions of files, searching for datasets by metadata criteria, and metadata definition for data processing jobs (AMI-tags). The current architecture of the underlying databases will be outlined, in addition to the ongoing developments for preparations for Run 4. Optimizations based on advanced partitioning will also be described, enabling all datasets to be migrated into a new single catalog.
CERN IT has offered a Kubernetes service since 2016, expanding to incorporate multiple other technologies from the cloud native ecosystem over time. Currently the service runs over 500 clusters and thousands of nodes serving use cases from different sectors in the organization.
In 2021 the ATS sector showed interest in looking at a similar setup for their container orchestration effort. A collaboration was started with an initial proof of concept running the CERN IT service inside the control room datacenter, including use cases from multiple teams in the sector. Following a successful initiative that ran over a year, a second phase was launched to bring the service to production.
In this paper we describe the existing CERN IT service and the major changes and improvements that were required to serve accelerator control use cases. We highlight the changes due to running in an isolated, air-gapped network environment, as well as the additional integrations regarding identity, storage and datacenter infrastructure. Finally we detail results from an extensive effort for failure scenario evaluation to comply with the expected service levels, as well as plans for extending the existing infrastructure to new use cases.
To operate ATLAS ITk system tests and later the final detector, a graphical operation and configuration system is needed. For this a flexible and scalable framework based on distributed microservices has been introduced. Different microservices are responsible for configuration or operation of all parts of the readout chain.
The configuration database microservice provides the configuration files needed to configure the hardware components of the readout chain and perform scans using the DAQ software. It saves the connectivity information and configuration files for the operation of the system in so called runkeys. These runkeys are stored in a flexible, tree-based data structure. This flexible structure allows the storage of specialized runkeys made up of different objects for each of the ITk subdetectors within the same database.
It is investigated whether a single-instance database is sufficient to efficiently serve these files to the subdetectors or if a distributed system of local ConfigDB caches is needed. These caches would each provide only a subset of the runkeys depending on the elements of the readout chain that the specific cache serves.
The ALICE Collaboration aims to precisely measure heavy-flavour (HF) hadron production in high-energy proton-proton and heavy-ion collisions since it can provide valuable tests of perturbative quantum chromodynamics models and insights into hadronization mechanisms. Measurements of the Ξ$_c^+$ and Λ$_c^+$ production decaying in a proton (p) and charged π and K mesons are remarkable examples of investigation in the HF sector. Like in other ALICE analyses, a quite novel approach based on Boosted Decision Tree (BDT) classifiers has been adopted to discriminate the signal yields from the background processes. Especially for Ξ$_c^+$ → pπK process, the Machine Learning (ML)-based approach is required and particularly challenging due to its large combinatorial background, small branching ratio, and short O(100 µm) decay length of Ξ$_c^+$ baryon. FAIR, a European project synergic to the ALICE experiment, aims to set up an open-source, user-friendly and interactive pytorch-based environment external to the official ALICE framework to perform BDT-based multivariate analyses. The FAIR benchmark imports different ML packages (XGBoost, Sklearn and Ray) to prepare the data and configure the BDT models in Jupyter Notebooks. Currently, the training is performed on a preliminary dataset with limited statistics using a partitioned shared GPU available through an Apache Mesos cluster at the ReCaS-Bari datacenter. In the future, when a larger dataset will be available, we intend to leverage a GPU-powered Kubernetes cluster for processing large-scale applications, including ML tool training. This contribution will present a performance comparison of the investigated BDT architectures trained with simulated signal events and background Run 3 data provided by ALICE.
The OMS data warehouse (DWH) constitutes the foundation of the Online Monitoring System (OMS) architecture within the CMS experiment at CERN, responsible for the storage and manipulation of non-event data within ORACLE databases. Leveraging on PL/SQL code, the DWH orchestrates the aggregation and modification of data from several sources, inheriting and revamping code from the previous project known as Web Based Monitoring to meet evolving requirements. The main goals of the DWH restructuring were: the modernization of inherited PL/SQL code, necessitating the creation of new aggregation tables and the implementation of enhancements such as standardized naming conventions; improved development workflows; and continuous integration strategies. DWH is composed of multiple Oracle schemas and integrates external PL/SQL libraries, in particular the CERN Beams Common4Oracle library, which consolidates common functionalities from various CERN Beams department databases into a unified codebase for widespread application. This article delves into the architecture and development strategies employed within the OMS data warehouse, underscoring its role in facilitating efficient data aggregation and management within the OMS project in the CMS experiment at CERN.
The Super Tau-Charm Facility (STCF) is the new generation $e^+$$e^−$ collider aimed at studying tau-charm physics. The particle identification (PID), as one of the most fundamental tools for various physics research in STCF experiment, is crucial for achieving various physics goals of STCF. In the recent decades, machine learning (ML) has emerged as a powerful alternative for particle identification in HEP experiments. ML algorithms, such as neural networks and boosted decision trees, have shown superior performance in handling complex and multi-dimensional data, making them well-suited for integrating particle identification information from multiple sub-detector systems. In this work, we present a powerful PID software based on ML techniques, including a global PID algorithm for charged particles combining information from all sub-detectors, as well as a deep CNN discriminating neutral particles based on calorimeter responses. The preliminary results show the PID models has achieved excellent PID performance, greatly boosting the physics potential of STCF.
The PATOF project builds on work at MAMI particle physics experiment A4. A4 produced a stream of valuable data for many years which already released scientific output of high quality and still provides a solid basis for future publications. The A4 data set consists of 100 TB and 300 million files of different types (Vague context because of hierarchical folder structure and file format with minimal metadata provided  .).
.).
In PATOF we would like to build a “FAIR Metadata Factory 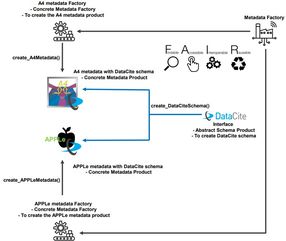 ”, i.e. a process to create a naturally evolved metadata schema that can be used across research fields. The first focus will be on creating machine-readable XML files containing metadata from the logbook and other sources and to further enrich them
”, i.e. a process to create a naturally evolved metadata schema that can be used across research fields. The first focus will be on creating machine-readable XML files containing metadata from the logbook and other sources and to further enrich them  .
.
In PATOF, we intend to conclude the work on A4 data, to extract the lessons learned there in the form of a cookbook that can capture the methodology for making individual experiment-specific metadata schemas FAIR, and to apply it to four other experiments: The ALPS II axion and dark matter search experiment at DESY. The PRIMA experiment at MAMI in Mainz for measuring the pion transition form factor. The upcoming nuclear physics experiment P2 at MESA in Mainz. Finally, the LUXE experiment at DESY planned to start in 2026. The focus of PATOF is on making these data fully publicly available.
The objectives of the project are i) a FAIR Metadata Factory (i.e. a cookbook of (meta)data management recommendations), and ii) the FAIRification of data from concrete experiments. Both aspects are inherently open in nature so that everybody can profit from PATOF results. The cookbook is expected to be further enhanced with contributions from other experiments even after PATOF (“living cookbook”).
Developments in microprocessor technology have confirmed the trend towards higher core counts and decreased amount of memory per core, resulting in major improvements in power efficiency for a given level of performance. Core counts have increased significantly over the past five years for the x86_64 architecture, which is dominating in the LHC computing environment, and the higher core density is not only a feature of large HPC systems, but is also readily available on commodity hardware preferentially used at Grid sites. The baseline multi-core workloads are however still largely based on 8-cores. The job are sized accordingly in terms of number of events processed. The new multi-threaded AthenaMT framework has been introduced for ATLAS data processing and simulation for Run-3 in order to address the performance limitations of the classic single-threaded Athena when run in parallel in multi-core jobs. In this work, the performance of some ATLAS workloads is investigated when scaling up core counts up to whole node where possible and at different job sizes with the aim of providing input to software developers.
CMS has deployed a number of different GPU algorithms at the High-Level Trigger (HLT) in Run 3. As the code base for GPU algorithms continues to grow, the burden for developing and maintaining separate implementations for GPU and CPU becomes increasingly challenging. To mitigate this, CMS has adopted the Alpaka (Abstraction Library for Parallel Kernel Acceleration) library as the performance portability solution to provide a single-code base for parallel execution on both GPUs and CPUs in CMS software (CMSSW).
A direct CUDA version of HCAL energy reconstruction, called Minimization At Hcal, Iteratively (MAHI), has been deployed at the HLT in the 2022-2023 data taking period. This contribution will describe how the CUDA version is converted into a portable implementation using the Alpaka library. We will discuss the porting experience from CUDA to Alpaka, the validation process and the performance of the Alpaka version in CPU and GPU.
Efficient, ideally fully automated, software package building is essential in the computing supply chain of the CERN experiments. With Koji, a very popular package software building system used in the upstream Enterprise Linux communities, CERN IT provides a service to build software and images for the Linux OSes we support. Due to the criticality of the service and the limitations in Koji's built-in monitoring, the CERN Linux team implemented new functionality to allow integration with Prometheus, an open-source monitoring system and time-series database. This contribution will give an overview of Koji and its integration with Prometheus and Grafana, explain the challenges we tackled during the development of the integration, and how we're benefiting from these new metrics to improve the quality of the service.
TechWeekStorage24 was introduced by CERN IT Storage and Data Management group as a new “Center of Excellence” community networking format: a co-located series of events on Open Source Data Technologies, bringing together a wide range of communities, far beyond High Energy Physics and highlighting the wider technology impact of IT solutions born in HEP.
Combining the annual CS3 conference, CERN Storage Day, EOS and CTA Workshops created week-long opportunity for connection, collaboration and discussion on storage services, open source software-defined storage and data management technology, data policies & trends, innovative applications, collaboration platforms, digital sovereignty, FAIR and Open Science, Security and Privacy of Data and more.
This new event format is also environmentally more sustainable: participants from locations such as Brazil, US, China, Japan, Korea had an opportunity to attend multiple related events within a single trip.
https://techweekstorage.web.cern.ch
Over time, the idea of exploiting voluntary computing resources as additional capacity for experiments at the LHC has given rise to individual initiatives such as the CMS@Home project. With a starting point of R&D prototypes and projects such as "jobs in the Vacuum" and SETI@Home, the experiments have tried integrating these resources into their data production frameworks transparently to the computing infrastructure. Many of these efforts were subsequently rolled into the umbrella LHC@Home project. The use of virtual machines instantiated on volunteer resources, with images created and managed by the experiment according to its needs, provided the opportunity to implement this integration, and virtualization enabled CMS code from a Linux environment to also run on Windows and Macintosh systems, realizing a distributed and heterogeneous computing environment. A prototype of CMS@Home integrated with the CMS workload management CRAB3 was proposed in 2015, demonstrating the possibility of using BOINC as "manager" of volunteer resources and adapting the "vacuum" concept with the HTCondor Glidein system to get CMS pilots and jobs to execute on volunteers' computers. Since then, the integration of volunteer machines with the CMS workload management WMAgent, the official service dedicated to data production, has been seriously considered. The characteristics of volunteer resources regarding bandwidth capacity, connection behavior, and CPU and RAM capacities make them suitable for low-priority workflows with low I/O demands. The poster describes how the configuration of volunteer resources has evolved to keep pace with the development of the CMS computing infrastructure, including using tokens for resource authentication, exploiting regular expressions to accept workflows, manual glideins to initiate pilots, and other implementation details to achieve successful workflows. Currently volunteers are able to execute task chains also of multicore jobs and, despite their limitations, are contributing to CMS computing capacity with around 600 cores daily.
With an electron-positron collider operating at center-of-mass-energy 2∼7 GeV and a peak luminosity above 0.5 × 10^35 cm^−2 s^−1, the STCF physics program will provide an unique platform for in-depth studies of hadron structure and non-perturbative strong interaction, as well as probing physics beyond the Standard Model at the τ-Charm sector succeeding the present Being Electron-Positron Collider II (BEPCII). To fulfill the physics targets and to further maximize the physics potential at the STCF, not only the particles that decay immediately upon production but also the long-lived particles, e.g. the lambda baryon, which may decay within or outside the inner tracker hence leaving very limited number of hits at the inner tracker, should be reconstructed with good efficiency.
A Common Tracking Software (ACTS) provides a set of performant track reconstruction tools which are agnostic to the details of the detection technologies and magnetic field configuration. Due to its excellent performance, ACTS has been used as a tracking toolkit by various experiments such as ATLAS, sPHENIX, FASER etc. Preliminary results of using ACTS seeding and Combinatorial Kalman Filter algorithms for STCF have been obtained. However, it's found that the tracking performance of ACTS seeding for long-lived particles at STCF is far from satisfactory, due to the fact that the STCF inner tracker has only three layers. Therefore, improving the tracking performance of ACTS for long-lived particles at STCF by combining the global track finding algorithm Hough Transform and the local track following algorithm CKF has been investigated.
In this talk, we will present the tracking performance of ACTS for STCF, which has a tracking system with a three-layer inner tracker and a drift chamber. Improvement of the tracking performance for long-lived particles at STCF using a combined global Hough Transform and the Combinatorial Kalman Filter will be highlighted.
The HEP-RC group at UVic used Dynafed intensively to create federated storage clusters for Belle-II and ATLAS; which was used by worker nodes deployed on clouds around the world. Since the end of the DPM development also means the end of the development for Dynafed, xrootd was tested with S3 as backend to replace Dynafed. We will show similarities as well as major differences between the two systems as well as results of tests we run on both, for data transfers, checksum calculations as well as clustering of different endpoints. This may help other to efficiently make use of S3 storage as a WLCG site SE.
Large Language Models (LLMs) are undergoing a period of rapid updates and changes, with state-of-art model frequently being replaced. WEhen applying LLMs to a specific scientific field it is challenging to acquire unique domain knowledge while keeping th emodel ifself advanced. To address this challenge, a sophisticated large language model system named Xiwu has been developed, allowing switching the most advanced foundation models flexibly and quickly. In this talk, we will discuss one of the best practices of applying LLMs in HEP including some seed fission tools which can collect and clean the HEP dataset quickly, a just-in-time learning system based on vector store technology, and an on-the-fly fine-tuning system. The results show that Xiwu can smoothly switch different models such as LLaMa, Vicuna, chatGLM and Grok-1, and the trained Xiwu model is significantly outperformed the benchmark model on the HEP knowledge in question-and-answering and code generation.
Data and Metadata Organization, Management and Access
The dCache project provides open-source software deployed internationally
to satisfy ever-more demanding storage requirements. Its multifaceted
approach provides an integrated way of supporting different use-cases
with the same storage, from high throughput data ingest, data sharing
over wide area networks, efficient access from HPC clusters, and long
term data persistence on tertiary storage. Although dCache
was originally developed for HEP experiments, today it is used by
various scientific communities, including astrophysics, biomed, and
life science, each with its specific requirements. To match the
requirements of these new communities and keep up with the scaling
demands of existing experiments, dCache evolution is a permanent
ongoing process. With this contribution, we would like to highlight
the recent developments in dCache regarding integration with CERN
Tape Archive (CTA), advanced metadata handling, token-based
authorization support, bulk API for QoS transitions, RESTAPI to
control interaction with the tape system, and future development
directions.
After the deprecation of the open-source Globus Toolkit used for GridFTP transfers, the WLCG community has shifted its focus to the HTTP protocol. The WebDAV protocol extends HTTP to create, move, copy and delete resources on web servers. StoRM WebDAV provides data storage access and management through the WebDAV protocol over a POSIX file system. Mainly designed to be used by the WLCG community, StoRM WebDAV supports authentication through X.509 certificates, VOMS proxies and JWT tokens. Moreover, Third-Party Copies (an extension of the WebDAV COPY verb to support copies between data centers) are supported.
With the aim of improving data transfer performance, this contribution describes the changes made to StoRM WebDAV in order to delegate file transfers to the external reverse proxy NGINX, decoupling them from the internal Java implementation. To even more simplify the StoRM WebDAV codebase, also the validation of VOMS proxies and JWT tokens is delegated to NGINX, augmented with specific modules developed by us. Even with this solution, authorization is still enforced by StoRM WebDAV.
Following the effort of the WLCG community to have better metrics about data flows, this contribution also describes the work done in order to support SciTags, an initiative promoting identification of the science domains and their high-level activities at the network level.
Managing the data deluge generated by large-scale scientific collaborations is a challenge. The Rucio Data Management platform is an open-source framework engineered to orchestrate the storage, distribution, and management of massive data volumes across a globally distributed computing infrastructure. Rucio meets the requirements of high-energy physics, astrophysics, genomics, and beyond, pioneering new ways to facilitate research at the exabyte-scale.
This presentation introduces Rucio, highlighting its key features and strategic roadmap that underscore its flexibility towards diverse scientific domains, deep diving into concrete operational experience from various EU projects (ESCAPE, DaFab, InterTwin).
A special emphasis will be placed on the contributions of the CERN IT department, whose active engagement with the Rucio project has increased recently and catalysed significant contributions to the core software. This collaboration has not only enhanced Rucio’s capabilities but also solidified its role in LHC experiments such as ATLAS and CMS, and provided a path forward for SMEs (Small and Medium experiments) to benefit from a converged data management platform.
The data movement manager (DMM) is a prototype interface between the CERN developed data management software Rucio and the software defined networking (SDN) service SENSE by ESNet. It allows for SDN enabled high energy physics data flows using the existing worldwide LHC computing grid infrastructure. In addition to the key feature of DMM, namely transfer-priority based bandwidth allocation for optimal network usage; it also allows for the identification of the exact cause of underperforming flows using end-to-end monitoring of the data flows by having access to host (network interface) level throughput metrics and transfer-tool (FTS) data transfer job level metrics. This paper describes the design and implementation of DMM.
The Large Hadron Collider (LHC) experiments rely heavily on the XRootD software suite for data transfer and streaming across the Worldwide LHC Computing Grid (WLCG) both within sites (LAN) and across sites (WAN). While XRootD offers extensive monitoring data, there's no single, unified monitoring tool for all experiments. This becomes increasingly critical as network usage grows, and with the High-Luminosity LHC (HL-LHC) demanding even higher bandwidths.
The "Shoveler" system addresses this challenge by providing a platform to collect and visualize XRootD traffic data from all four LHC experiments, separated by type, direction and locality of the traffic. This contribution explores the Shoveler plus Collector architecture, its current deployment status at WLCG sites, and validates its collected information by comparing it with data from individual experiment monitoring frameworks.
The WLCG community, with the main LHC experiments at the forefront, is moving away from x509 certificates, replacing the Authentication and Authorization layer with OAuth2 tokens. FTS, as a middleware and core component of the WLCG, plays a crucial role in the transition from x509 proxy certificates to tokens. The paper will present in-detail the FTS token design and how this will serve the needs of the community, WLCG and non-WLCG alike. Finally, a chapter will also report on performance measurements and lessons learned during the DataChallenge 2024
Online and real-time computing
A new algorithm, called "Downstream", has been developed and implemented at LHCb, which is able to reconstruct and select very displaced vertices in real time at the first level of the trigger (HLT1). It makes use of the Upstream Tracker (UT) and the Scintillator Fiber detector (SciFI) of LHCb and it is executed on GPUs inside the Allen framework. In addition to an optimized strategy, it utilizes a Neural Network (NN) implementation to increase the track efficiency and reduce the ghost rates, with very high throughput and limited time budget. Besides serving to reconstruct Ks and Lambda vertices to calibrate and align the detectors, the Downstream algorithm and the associated two-track vertexing will largely increase the LHCb physics potential for detecting long-lived particles during the Run3.
The event reconstruction in the CBM experiment is challenging.
There will be no simple hardware trigger due to the novel concepts of free-streaming data and self-triggered front-end electronics.
Thus, there is no a priori association of signals to physical events.
CBM will operate at interaction rates of 10 MHz, unprecedented for heavy ion experiments.
At this rate, collisions overlap in time and are to be resolved in software by reconstruction algorithms.
These complications made the speed and quality of the data reconstruction crucial.
The core of the track reconstruction is the Cellular Automaton (CA) based algorithm used for the Silicon Tracking System (STS).
It digests free-streaming data both online and offline, taking large time slices of the hit measurements as input with non-a priori-defined physical collisions.
The data is reconstructed in time portions by applying a nonmerging sliding window algorithm, which achieves almost constant
time per event regardless of the time slice size.
The algorithm was successfully applied to run online for the mini-CBM experiment during the March 2024 data-taking campaign.
In this presentation, we introduce BuSca, a prototype algorithm designed for real-time particle searches, leveraging the enhanced parallelization capabilities of the new LHCb trigger scheme implemented on GPUs. BuSca is focused on downstream reconstructed tracks, detected exclusively by the UT and SciFi detectors. By projecting physics candidates onto 2D histograms of flight distance and mass hypotheses at a remarkable 30 MHz rate, BuSca identifies hot spots indicative of potential candidates of new particles, thereby providing strategic guidance for the development of new trigger lines. Additionally, BuSca offers an Armenteros-Podolanski representation, providing insights into the mass hypotheses of the decay products associated with the new particle. The performance of BuSca, including the outcomes of its initial prototype on simulated data, will be elucidated in this talk.
Online reconstruction is key for monitoring purposes and real time analysis in High Energy and Nuclear Physics (HEP) experiments. A necessary component of reconstruction algorithms is particle identification (PID) that combines information left by a particle passing through several detector components to identify the particle’s type. Of particular interest to electro-production Nuclear Physics experiments such as CLAS12 is electron identification which is used to trigger data recording. A machine-learning approach was developed for CLAS12 to reconstruct and identify electrons by combining raw signals at the data acquisition level from several detector components. This approach achieves a high electron identification purity whilst retaining a 99.95% efficiency. The machine learning tools are capable of running at high rates exceeding the data acquisition rates and will allow electron reconstruction in real-time. This framework can then be expanded to other particle types. This work enhances online analyses and monitoring at CLAS12. Improved electron identification in the trigger also contributes to the reduction in recorded data volumes and improves data processing times. This approach to triggering will be employed when transitioning to higher luminosity experiments at CLAS12 where the data volume will increase significantly.
Ahead of Run 3 of the LHC, the trigger of the LHCb experiment was redesigned. The L0 hardware stage present in Runs 1 and 2 was removed, with detector readout at 30 MHz passing directly into the first stage of the software-based High Level Trigger (HLT), run on GPUs. Additionally, the second stage of the upgraded HLT makes extensive use of the Turbo event model, wherein only those candidates required for a trigger decision are saved. As the LHCb detector records only events selected by the trigger system, an absolute trigger efficiency cannot be evaluated. The TISTOS method provides a solution to this by evaluating the signal trigger efficiency on a trigger-selected sub-sample independent of signal. Events can be classified as having triggered on signal (TOS), triggered independent of signal (TIS), or both (TISTOS). Efficiencies are then calculated by a tag-and-probe approach, in which TIS and TISTOS events are used as tag and probe, respectively. This approach was applied successfully in Runs 1 and 2; however, in saving only candidates required for trigger decision, all such candidates are TOS by default. The TISTOS method has thus been specified in terms of the stage of selection below each stage of interest to define meaningful efficiencies. This contribution presents the development and performance of the TISTOS method for the upgraded trigger and event model, and an overview of the HLT trigger efficiencies evaluated in 2024 LHCb proton-proton collision data.
The evergrowing amounts of data produced by the high energy physics experiments create a need for fast and efficient track reconstruction algorithms. When storing all incoming information is not feasible, online algorithms need to provide reconstruction quality similar to their offline counterparts. To achieve it, novel techniques need to be introduced, utilizing acceleration offered by the highly parallel hardware platforms, like GPUs. Artificial Neural Networks are a natural candidate here, thanks to their good pattern recognition abilities, non-iterative execution, and easy implementation on hardware accelerators.
The MUonE experimenting, searching for the signs of New Physics in the sector of anomalous magnetic moment of a muon, is investigating the use of the machine learning techniques in data processing. Works related to the ML-based track reconstruction will be presented. The first attempt used deep multilayer perceptron network to predict parameters of the tracks in the detector. Neural network was used as the base of the algorithm that proved to be as accurate as the classical approach but substituting the tedious step of iterative CPU-based pattern recognition. Further works included implementation of the Graph Neural Network for classification of track segment candidates.
Offline Computing
Developments of the new Level-1 Trigger at CMS for the High-Luminosity Operation of the LHC are in full swing. The Global Trigger, the final stage of this new Level-1 Trigger pipeline, is foreseen to evaluate a menu of over 1000 cut-based algorithms, each of which targeting a specific physics signature or acceptance region. Automating the task of tailoring individual algorithms to specific physics regions would be a significant time saver while ensuring flexibility to adapt swiftly to evolving run conditions. This task essentially resembles a multi-objective optimization problem, where the goal is to strike a balance between the trigger rate and the trigger efficiency of the desired physics region.
We present the idea of leveraging achievement scalarization, a technique to turn the two objective functions into a scalar function with a minimum closest to a reference point chosen by a decision maker. An iterative gradient descent approach can then be employed to minimize this function, each iteration slightly modifying the cut parameters in the direction of descent. The decision maker in this context can be a single person designing parts of the menu or a collective group like CERN's data performance group agreeing on specific goals for upcoming data-taking sessions.
Preliminary results of using this procedure in targeting B meson decays have demonstrated promising outcomes. Ongoing efforts involve exploring alternative minimization techniques like evolutionary algorithms and extending the method to other physics signatures.
Searching for anomalous data is especially important in rare event searches like that of the LUX-ZEPLIN (LZ) experiment's hunt for dark matter. While LZ's data processing provides analyzer-friendly features for all data, searching for anomalous data after minimal reconstruction allows one to find anomalies which may not have been captured by reconstructed features and allows us to avoid any reconstruction errors. Autoencoders can be used to probe for anomalous light-detecting PMT waveforms resulting from ionization signals (S2) and have found unresolved S2s resulting from multiple scatter interactions. In addition to comparing results to waveform-shape template-fitting methods, these techniques can be extended by applying them to PMT waveforms from prompt scintillation light (S1) and S2 heatmaps which capture positional information. Results from such methods are discussed and compared to known anomalies.
The upcoming upgrades of LHC experiments and next-generation FCC (Future Circular Collider) machines will again change the definition of big data for the HEP environment. The ability to effectively analyse and interpret complex, interconnected data structures will be vital. This presentation will delve into the innovative realm of Graph Neural Networks (GNNs). This powerful tool extends traditional deep learning techniques to handle graph-structured data and may provide new and fast algorithms for track reconstruction in both the 3D and 4D domains.
Projecting challenging task of track reconstruction, especially challenging in harsh hadronic environment, into non-Euclidean domain of GNNs may leverage the intrinsic structure of graph data to extract addition crucial features and patterns that are either difficult or impossible for traditional statistical or intelligent reconstruction algorithms.
We present our initial studies using various GNN models implemented within the ACTS (A Common Tracking Software Project) framework. In our studies, we created a telescope detector that resembles an LHCb silicon vertex locator and used toy-generated data with truth information. Using such simulated setup, we were able to successfully train several GDN models to perform track reconstruction tasks. Based on these initial results, we performed preliminary studies to obtain efficiencies and resolutions for selected kinematical variables.
Our preliminary studies are very promising and show significant potential for using GDNs models as track reconstruction engines for future LHC upgrades and beyond.
The BESIII at the BEPCII electron-positron accelerator, which is located at IHEP, Beijing, China, is an experiment for the studies of hadron physics and $\tau$-charm physics with the highest accuracy achieved until now. It has collected several world's largest $e^+e^-$ samples in $\tau$-charm region. Anomaly detection on BESIII detectors is an important segment of improving data quality, enhancing data acquisition efficiency and monitoring detectors' status. An offline unsupervised autoencoder-based anomaly detection method is applied on CsI(Tl) electromagnetic calorimeter (EMC). This method checks over histograms generated by each crystal using Jensen-Shannon Distance as loss function. Comparing to traditional method, this method is able to provide more accurate anomaly information with less manpower consuming.
During LHC High-Luminosity phase, the LHCb RICH detector will face challenges due to increased particle multiplicity and high occupancy. Introducing sub-100ps time information becomes crucial for maintaining excellent particle identification (PID) performance. The LHCb RICH collaboration plans to anticipate the introduction of timing through an enhancement program during the third LHC Long Shutdown. In the RICH detector, Cherenkov photons from a track arrive nearly simultaneously at the detector plane, allowing precise hit time prediction. The RICH reconstruction algorithm computes track and photon time-of-flight and estimates where photons are expected on the photodetector plane. Determining the primary vertex time (PV T$_0$) is crucial in predicting the time of arrival of photons on the photodetector plane. Adding time information allows applying a software time gate around the predicted time per track to enhance signal-to-background ratio and PID performance. This contribution describes how to estimate the PV T$_0$ using RICH information only, a novel approach for LHCb. The proposed algorithm computes a reconstructed PV time for every photon from hit time and tracking information. The PV T$_0$ is extracted by averaging this reconstructed time for all photons belonging to the PV. The challenge lies in correctly associate photons to their PV, which is a two-step process: PV-track and track-photon associations, both presenting inefficiencies. Results compare the estimated PV time resolution with Monte Carlo simulations. This contribution aims to describe the integration of fast-timing in the RICH detector, illustrating the impact of the PV time estimation method on PID performance.
Distributed Computing
Since 2017, the Worldwide LHC Computing Grid (WLCG) has been working towards enabling token-based authentication and authorization throughout its entire middleware stack.
Taking guidance from the WLCG Token Transition Timeline, published in 2022, substantial progress has been achieved not only in making middleware compatible with the use of tokens, but also in understanding the limitations of the WLCG Common JWT Profiles, first published in 2019. Significant scalability experience has been gained from Data Challenge 2024, during which millions of files were transferred with only tokens used as credentials.
Besides describing the state of affairs in the transition to tokens, revisions to the WLCG token profile, and the evolving roadmaps, this contribution also covers the corresponding transition from VOMS-Admin to INDIGO-IAM services, with continuing improvements in terms of functionality as well as deployment.
Created in 2023, the Token Trust and Traceability Working Group (TTT) was formed in order to answer questions of policy and best practice with the ongoing move from X.509 and VOMS proxy certificates to token-based solutions as the primary authorisation and authentication method in grid environments. With a remit to act in an investigatory and advisory capacity alongside other working groups in the token space, the TTT is composed of a broad variety of stakeholders to provide a breadth of experience and viewpoints. The requirements of grid sites, users, identity providers and virtual organisations to be able to trace workflows remain largely the same in a token paradigm as when using X.509 certificates, while tokens provide a new set of challenges, requiring a rethink and restructure of the policies and processes that were defined with just X.509 and VOMS in mind.
After providing an overview of the current status of the token trust landscape we will detail the initial findings, future plans and recommendations to be made by the TTT. This will include best practice for sites and identity providers, suggestions for token development, and methodologies for tracing token usage by system administrators within common grid middleware stacks.
Within the LHC community, a momentous transition has been occurring in authorization. For nearly 20 years, services within the Worldwide LHC Computing Grid (WLCG) have authorized based on mapping an identity, derived from an X.509 credential, or a group/role derived from a VOMS extension issued by the experiment. A fundamental shift is occurring to capabilities: the credential, a bearer token, asserts the authorizations of the bearer, not the identity.
By the HL-LHC era, the CMS experiment plans for the transition to tokens, based on the WLCG Common JSON Web Token profile, to be complete. Services in the technology architecture include the INDIGO Identity and Access Management server to issue tokens; a HashiCorp Vault server to store and refresh access tokens for users and jobs; a managed token bastion server to push credentials to the HTCondor CredMon service; and HTCondor to maintain valid tokens in long-running batch jobs. We will describe the transition plans of the experiment, current status, configuration of the central authorization server, lessons learned in commissioning token-based access with sites, and operational experience using tokens for both job submissions and file transfers.
Fermilab is the first High Energy Physics institution to transition from X.509 user certificates to authentication tokens in production systems. All of the experiments that Fermilab hosts are now using JSON Web Token (JWT) access tokens in their grid jobs. Many software components have been either updated or created for this transition, and most of the software is available to others as open source. The tokens are defined using the WLCG Common JWT Profile. Token attributes for all the tokens are stored in the Fermilab FERRY system which generates the configuration for the CILogon token issuer. High security-value refresh tokens are stored in Hashicorp Vault configured by htvault-config, and JWT access tokens are requested by the htgettoken client through its integration with HTCondor. The Fermilab job submission system jobsub was redesigned to be a lightweight wrapper around HTCondor. For automated job submissions a managed tokens service was created to reduce duplication of effort and knowledge of how to securely keep tokens active. The existing Fermilab file transfer tool ifdh was updated to work seamlessly with tokens, as well as the Fermilab POMS (Production Operations Management System) which is used to manage automatic job submission and the RCDS (Rapid Code Distribution System) which is used to distribute analysis code via the CernVM FileSystem. The dCache storage system was reconfigured to accept tokens for authentication in place of X.509 proxy certificates. As some services and sites have not yet implemented token support, proxy certificates are still sent with jobs for backwards compatibility but some experiments are beginning to transition to stop using them. There have been some glitches and learning curve issues but in general the system has been performing well and is being improved as operational problems are addressed.
INDIGO IAM (Identity and Access Management) is a comprehensive service that enables organizations to manage and control access to their resources and systems effectively. It implements a standard OAuth2 Authorization Service and OpenID Connect Provider and it has been chosen as the AAI solution by the WLCG community for the transition from VOMS proxy-based authorization to JSON web tokens.
This contribution describes the recent updates introduced by the latest IAM releases and the current roadmap for its evolution. In the near future, a primary focus is on avoiding to store access tokens in the database, to enhance the performance of both token issuance and token deletion. Another important milestone is the integration of a Multi-Factor Authentication mechanism. Additionally, substantial effort will be dedicated to migrating from outdated frameworks, such as MITREid Connect and AngularJS, to more stable and robust solutions based on Spring Security and React respectively. As a consequence, a new dashboard is also being developed, aligned with the latest advances in User Interface design.
This abstract highlights the progress made in the development roadmap described above, not forgetting the general auditing and performance improvements introduced with the latest releases or planned, such as the use of Open Policy Agent to re-implement the internal mechanism of the Scope Policy API.
X.509 certificates and VOMS proxies are still widely used by various scientific communities for authentication and authorization (authN/Z) in Grid Storage and Computing Elements. Although this has contributed to improve the scientific collaboration worldwide, X.509 authN/Z comes with some interoperability issues with modern Cloud-based tools and services.
The Grid computing communities have decided to migrate to token-based authentication, a new web technology that has proved to be flexible and secure.
The model being recently adopted by the communities is based on industrial standards such as OAuth2 and OpenID-Connect and exploits JSON Web Tokens (JWT): a compact way to securely transmit information as JSON objects.
JWT are usually short-lived and provide fine-grained authorization, based on "scopes", to perform specific actions.
These scopes are embedded into the token and are specified during the request procedure so they last only until token expiration time. Scopes can be requested based on user groups and permission thus providing the possibility of restricting a group to perform only a subset of actions.
These characteristics make up to a more secure alternative to X.509 proxies.
Being largely used in industries, JWTs are also easily integrated in services not specifically developed for the scientific community, such as calendars, Sync and Share services, collaborative software development platforms, and more.
As such, JWTs suit the many heterogeneous demands of Grid communities and some of them already started the transition in 2022.
In the Italian WLCG Tier-1, located in Bologna and managed by INFN - CNAF, several computing resources are hosted and made available to scientific collaborations in the fields of High-Energy Physics, Astroparticle Physics, Gravitational Waves, Nuclear Physics and many others.
Although LHC experiments at CERN are the main users of CNAF resources, many other communities and experiments are being supported in their computing activities.
While the main LHC experiments have already planned their own transition from X.509 to token-based authN/Z, many medium/small-sized collaborations struggle to put effort into it.
The Tier-1 User Support unit has the duty of guiding users towards efficient and modern computing techniques and workflows involving data and computing resources access.
As such, the User Support group is playing a central role in preparing documentation, tools and services to ease the transition from X.509 to JWTs.
The foreseen support strategy and the related tools will be presented. Future workflow plans in view of the complete transition will also be presented.
Simulation and analysis tools
As we are approaching the high-luminosity era of the LHC, the computational requirements of the ATLAS experiment are expected to increase significantly in the coming years. In particular, the simulation of MC events is immensely computationally demanding, and their limited availability is one of the major sources of systematic uncertainties in many physics analyses. The main bottleneck in the detector simulation is the detailed simulation of electromagnetic and hadronic showers in the ATLAS calorimeter system using Geant4.
In order to increase the MC statistics and to leverage the available CPU resources for LHC Run 3, the ATLAS collaboration has recently put into production a refined and significantly improved version of its state-of-the-art fast simulation tool AtlFast3. AtlFast3 uses classical parametric and machine learning based approaches such as Generative Adversarial Networks (GANs) for the fast simulation of LHC events in the ATLAS detector.
This talk will present the newly improved version of AtlFast3 that is currently in production for the simulation of Run 3 samples. In addition, ideas and plans for the future of fast simulation in ATLAS will also be discussed.
Detector simulation is a key component of physics analysis and related activities in CMS. In the upcoming High Luminosity LHC era, simulation will be required to use a smaller fraction of computing in order to satisfy resource constraints. At the same time, CMS will be upgraded with the new High Granularity Calorimeter (HGCal), which requires significantly more resources to simulate than the existing CMS calorimeters. This computing challenge motivates the use of generative machine learning models as surrogates to replace full physics-based simulation. We study the application of state-of-the-art diffusion models to simulate particle showers in the CMS HGCal. We will discuss methods to overcome the challenges posed by the high-dimensional, irregular geometry of the HGCal. The quality of the showers produced by the diffusion model will be assessed by comparison to the full GEANT4-based simulation. The increase in simulation throughput will be quantified and methods to accelerate the diffusion model inference will also be discussed.
In the realm of low-energy nuclear physics experiments, the Active Target Time Projection Chamber (AT-TPC) can be advantageous for studying nuclear reaction kinematics, such as the alpha cluster decay of $^{12}C$, by tracking the reaction products produced in the active gas medium of the TPC. The tracking capability of the TPC is strongly influenced by the homogeneity of the electric field applied across its drift medium, which is affected by the space charge produced by low-energy projectiles and reaction products in the active gas medium through the ionization process. In this work, we implemented a mathematical model based on a hydrodynamic approach to simulate the space charge effect caused by the alpha beam on the TPC performance using the platform of a commercial Finite Element Method (FEM) package available in COMSOL Multiphysics. This novel approach is computationally less expensive compared to the particle model. The primary ionization caused by the alpha particles was simulated using Geant4, and the electron transport parameters for the active gas were obtained from MAGBOLTZ. The effect of space charge on the applied electric field and the angular resolution of the TPC with beam currents ranging from a few pA to 20 pA have been reported. The same model was also utilized to simulate the temporal evolution of an alpha track in two different active gas mediums, $He+CO_2$ and He+$C_{4}H_{10}$, in the volumetric ratios of 90:10 and 93:7, respectively. Different readout geometries of the TPC were studied to find the optimum strip width and number of strips at the TPC end cap to properly resolve the alpha particle tracks. A tracking algorithm had been developed to distinguish between the multiple tracks between scattered events and the $^{12}C$ breakup. We are designing a 64 channel Micromegas based prototype TPC on the basis of the simulation results.
In high energy physics, fast simulation techniques based on machine learning could play a crucial role in generating sufficiently large simulated samples. Transitioning from a prototype to a fully deployed model usable in a full scale production is a very challenging task.
In this talk, we introduce the most recent advances in the implementation of fast simulation for calorimeter showers in the LHCb simulation framework based on Generative AI. We use a novel component in Gaussino to streamline the incorporation of generic machine learning models. It leverages on the use of fast simulation hooks from Geant4 and machine learning backends such as PyTorch and ONNXRuntime.
Using this infrastructure the first implementation of selected ML models is trained and validated on the LHCb calorimeters. We will show a Variational Autoencoder (VAE) equipped with a custom sampling mechanism, as well as a transformer-based diffusion model (DiT). Both are compatible with the setup used in the CaloChallenge initiative, a collaborative effort aimed at training generic models for calorimeter shower simulation. We will share insights gained from the validation of these models on dedicated physics samples, including how to cope with handling and versioning multiple ML models in production in a distributed environment.
The event simulation is a key element for data analysis at present and future particle accelerators. We show [1] that novel machine learning algorithms, specifically Normalizing Flows and Flow Matching, can be effectively used to perform accurate simulations with several orders of magnitude of speed-up compared to traditional approaches when only analysis level information is needed. In such a case it is indeed feasible to skip the whole simulation chain and directly simulate analysis observables from generator information (end-to-end simulation). We simulate jets features to compare discrete and continuous Normalizing Flows models. The models are validated across a variety of metrics to select the best ones. We discuss the scaling of performance with the increase in training data, as well as the generalization power of these models on physical processes different from the training one. We investigate sampling multiple times from the same inputs, a procedure we call oversampling, and we show that it can effectively reduce the statistical uncertainties of a sample. This class of ML algorithms is found to be highly expressive and useful for the task of simulation. Their speed and accuracy, coupled with the stability of the training procedure, make them a compelling tool for the needs of current and future experiments.
[1] arXiv:2402.13684
Fast simulation of the energy depositions in high-granular detectors is needed for future collider experiments with ever increasing luminosities. Generative machine learning (ML) models have been shown to speed up and augment the traditional simulation chain. Many previous efforts were limited to models relying on fixed regular grid-like geometries leading to artifacts when applied to highly granular calorimeters with realistic cell layouts. We present CaloClouds III, a novel point cloud diffusion model that allows for high-speed generation of realistic electromagnetic showers due to the distillation into a consistency model. The model is conditioned on incident energy and impact angles and implemented into a realistic DD4hep based simulation model of the ILD detector concept for a future Higgs factory. This is done with the DDFastShowerML library which has been developed to allow for easy integration of generative fast simulation models into any DD4hep based detector model. With this it is possible to benchmark the performance of a generative ML model using fully reconstructed physics events by comparing them against the same events simulated with Geant4, thereby ultimately judging the fitness of the model for application in an experiment’s Monte Carlo.
Collaborative software and maintainability
The Key4hep software stack enables studies for future collider projects. It provides a full software suite for doing event generation, detector simulation as well as reconstruction and analysis. In the Key4hep stack, over 500 packages are built using the spack package manager and deployed via the cvmfs software distribution system. In this contribution, we explain the current setup for building nightly builds and stable releases that are made every few months or as needed. These builds are made available to users, who have access to a full and consistent software stack via a simple setup script. Different operating systems and compilers are supported and some utilities are provided to make development on top of the Key4hep builds easier. Both the benefits of the community-driven approach followed in spack and the issues found along the way are discussed.
The Spack package manager has been widely adopted in the supercomputing community as a means of providing consistently built on-demand software for the platform of interest. Members of the high-energy and nuclear physics (HENP) community, in turn, have recognized Spack’s strengths, used it for their own projects, and even become active Spack developers to better support HENP needs. Code development in a Spack context, however, can be challenging as the provision of external software via Spack must integrate with the developed packages’ build systems. Spack’s own development features can be used for this task, but they tend to be inefficient and cumbersome.
We present a solution pursued at Fermilab called MPD (multi-package development). MPD aims to facilitate the development of multiple Spack-based packages in concert without the overhead of Spack’s own development facilities. In addition, MPD allows physicists to create multiple development projects with an interface that insulates users from the many commands required to use Spack well.
The ePIC collaboration is working towards realizing the primary detector for the upcoming Electron-Ion Collider (EIC). As ePIC approaches critical decision milestones and moves towards future operation, software plays a critical role in systematically evaluating detector performance and laying the groundwork for achieving the scientific goals of the EIC project. The scope and schedule of the project require a balanced approach between near-term priorities, such as preparing the Technical Design Report, and long-term objectives for the future construction, commissioning, and operational phases. ePIC leverages an agile development process with high-level milestones to ensure continuous real-world testing of the software through monthly production campaigns and CI-driven benchmarks. The ePIC software stack embraces cutting-edge, sustainable community software tools and avoids the "not invented here" syndrome by building on top of well-supported and actively developed frameworks like the key4HEP stack (DD4hep, PODIO, EDM4hep) and ACTS. This collaborative development approach fosters an elevated standard of quality based on lessons learned by the nuclear physics and high energy physics communities. This talk will explore our setup for a collaborative development process and how it integrates with our vision for Software & Computing in the future ePIC experiment.
The ePIC collaboration is realizing the first experiment of the future Electron-Ion Collider (EIC) at the Brookhaven National Laboratory that will allow for a precision study of the nucleon and the nucleus at the scale of sea quarks and gluons through the study of electron-proton/ion collisions. This talk will discuss the current workflow in place for running centralized simulation campaigns for ePIC on the Open Science Grid infrastructure. This involves monthly releases of ePIC software and container deployments to CVMFS, generation of input datasets in HepMC format according to collaboration-defined policy, using Snakemake in CI/CD for validation and benchmarking, and submitting jobs to the Open Science Grid condor scheduler for opportunistic running on available resources. File transfers utilize XrootD, and RUCIO is used for data management. The workflow is being continuously refined to improve daily throughput (currently ~50-100k core hours per day) and minimize job failures. Since May 2023, monthly simulation campaigns employing the workflow have cumulatively used over ~10 million core hours on the Open Science Grid and produced over ~280 TB of simulation data. The campaigns incorporate simulations for the broad science program of the EIC and are actively used for the detector and physics studies in preparation of the Technical Design Review.
Considering CERN's prosperous environment, developing groundbreaking research in physics and pushing technology's barriers, CERN members participate in many talks and conferences every year. However, given that the ATLAS experiment has around 6000 members and more than one could be qualified to present the same talk, the experiment developed metrics to prioritize them.
Currently, ATLAS is organized in a tree structure with 260 groups and subgroups, called activities. Each of these activities has responsible members such as the conveners or sub-conveners, project leaders, and activity coordinators. Because of the tree structure mentioned, the member’s nomination will work its way up the branches, providing the upper levels with input from the lower ones. Previously, this process was not automated and happened through the exchange of CSVs, not providing these conveners and coordinators with the big picture of the nominations' priorities and reasons.
To improve this process, two systems were developed by the ATLAS Glance team: Activities and SCAB Nominations. The Activities interface provides a user-friendly view to manage the activities tree structure, the coordinators of each activity, and their allowed actions in the nomination process. The SCAB Nominations interface automates the nomination process of the ATLAS Speakers Committee Advisory Board, allowing all the coordinators to give their nominees priorities, and justify them in comments. These two systems contribute to a more holistic process for selecting collaboration members to present at a specific conference. This presentation delves into their specifications.
CERN has a very dynamic environment and faces challenges such as information centralization, communication between the experiments’ working groups, and the continuity of workflows. The solution found for those challenges is automation and, therefore, the Glance project, an essential management software tool for all four large LHC experiments. Its main purpose is to develop and maintain web-based automated solutions that are easy to learn and use and allow collaboration members to perform their tasks quickly.
The ATLAS Management Glance team is a subset of the Glance team focused on attending to the software requests of the ATLAS Spokesperson and deputies. The team maintains 11 systems that allow the management of ATLAS members, appointments, analyses, speaker nomination, and selection, among other tasks. Historically, each Glance developer would be an expert in the requirements of one or more systems, but their product management was inefficient, lacking the mapping of the product vision, goals, business rules, personas, and metrics. Also, the team's roadmap lacked predictability since it had no planned timeline.
In September 2023, the ATLAS Management Glance team adopted the Product Owner role concentrated in one single person recommended (or possibly “required”) by the Scrum Guide. This presentation dives into the challenges faced by the Glance Team Product Owner in establishing a strategy for effective product management and roadmap planning and key takeaways from that process.
Computing Infrastructure
The German university-based Tier-2 centres successfully contributed a significant fraction of the computing power required for Runs 1-3 of the LHC. But for the upcoming Run 4, with its increased need for both storage and computing power for the various HEP computing tasks, a transition to a new model becomes a necessity. In this context, the German community under the FIDIUM project is making interdisciplinary resources of the National High Performance Computing (NHR) usable within the WLCG and centralising mass storage at the Helmholtz centres.
The Goettingen campus hosts both a WLCG Tier-2 site, GoeGrid, and the HPC cluster Emmy that is part of the National High-Performance Computing (NHR) center NHR-Nord@Göttingen. The integration is done by virtually extending the GoeGrid batch system with containers, turning the HPC nodes into virtual worker nodes with their own partitionable job scheduling in order to run GoeGrid HEP jobs for the ATLAS collaboration. Submission and management of these containers are automated using COBalD (the Opportunistic Balancing Daemon) and TARDIS (The Transparent Adaptive Resource Dynamic Integration System). Data are provided via the GoeGrid mass storage for which a dedicated network connection has been established. Continuous production of ATLAS jobs is currently being tested in a one-year pilot phase. The setup, experience, performance tests and outlook are presented.
In a geo-distributed computing infrastructure with heterogeneous resources (HPC and HTC and possibly cloud), a key to unlock an efficient and user-friendly access to the resources is being able to offload each specific task to the best suited location. One of the most critical problems involve the logistics of wide-area with multi stage workflows back and forth multiple resource providers.
We envision a model where such a challenge can be addressed enabling a "transparent offloading” of containerized payloads using the Kubernetes API primitives creating a common cloud-native interface to access any number of external hardware machines and type of backends. Thus we created the interLink project, an open source extension to the concept of Virtual-Kubelet with a design that aims for a common abstraction over heterogeneous and distributed backends.
interLink is developed by INFN in the context of interTwin, an EU funded project that aims to build a digital-twin platform (Digital Twin Engine) for sciences, and the ICSC National Research Centre for High Performance Computing, Big Data and Quantum Computing in Italy. In this talk we first provide a comprehensive overview of the key features and the technical implementation. We showcase our major case studies such as the scale out of an analysis facility, and the distribution of ML training processes. We focus on the impacts of being able to seamlessly exploit world-class EuroHPC supercomputers with such a technology.
The MareNostrum 5 (MN5) is the new 750k-core general-purpose cluster recently deployed at the Barcelona Supercomputing Center (BSC). MN5 presents new opportunities for the execution of CMS data processing and simulation tasks but suffers from the same stringent network connectivity limitations as its predecessor, MN4. The innovative solutions implemented to navigate these constraints and effectively leverage the resources within the CMS distributed computing environment need to be revisited. First, the new worker nodes have increased their processor core count, and are thus capable of handling larger multicore CPU-bound CMS simulation tasks. Furthermore, the provisioning of larger disk storage capacity for MN5 broadens the spectrum of CMS workload types that can be accommodated at BSC. This storage space could, for example, be used to temporarily host large datasets required as input for CMS tasks, such as the pile-up samples, usually accessed by proton collision simulation jobs at runtime from remote grid sites’ storages. These tasks were previously unsuitable for execution, given the connectivity limitations from BSC to remote storages. Enhanced network bandwidth between MN5 and the Port d’Informació Cientifica (PIC) can also facilitate the expansion of BSC capabilities by provisioning input for CMS data processing tasks at BSC, thus expanding the role of this resource in the CMS computing landscape. This contribution will provide an overview of the commissioning efforts and the results of the subsequent exploitation of MN5 for CMS, showcasing the new transformative capacities introduced by the MN5 cluster.
The CMS experiment's operational infrastructure hinges significantly on the CMSWEB cluster, which serves as the cornerstone for hosting a multitude of services critical to the data taking and analysis. Operating on Kubernetes ("k8s") technology, this cluster powers over two dozen distinct web services, including but not limited to DBS, DAS, CRAB, WMarchive, and WMCore.
In this talk, we propose and develop an application which is specifically tailored to the task of anomaly detection within this ecosystem of services. The core approach involves harnessing the capabilities of machine/deep learning methods, alongside a comprehensive exploration of various service parameters, to identify irregularities and potential threats effectively. The application is designed with the goal that continually monitors these services for any deviations from their expected behavior. Leveraging diverse machine/deep learning techniques and scrutinizing service-specific parameters, the application will be equipped to discern anomalies and aberrations that might signify security breaches or performance issues. Once an anomaly is detected, the system will not only record this event but will also promptly generate alerts. These alerts will be intelligently routed to the relevant service developers or administrators responsible for maintaining the affected components. This proactive alerting mechanism ensures that any emerging issues are swiftly addressed, minimizing potential disruptions and fortifying the overall reliability of the CMSWEB cluster and its critical services.
The efficient utilization of multi-purpose HPC resources for High Energy Physics applications is increasingly important, in particularly with regard to the upcoming changes in the German HEP computing infrastructure.
In preparation for the future, we are developing and testing an XRootD-based caching and buffering approach for workflow and efficiency optimizations to exploit the full potential of such resources despite the challenges and potential limitations associated with them.
With this contribution, we want to present a first prototype of our approach, deployed for optimizing the utilization of HoreKa, our local HPC cluster at KIT, that is opportunistically integrated into GridKa, the German Tier-1 center.
This includes first experiences and additional benefits for the operation of such sites that come with the additional monitoring capabilities of our setup.
Meeting point: in front of the venue, the Auditorium Maximum of Jagiellonian University - Krupnicza 33 Street.
Meeting point: in front of the venue, the Auditorium Maximum of Jagiellonian University - Krupnicza 33 Street.
The Dirac interware has long served as a vital resource for user communities seeking access to distributed computing resources. Originating within the LHCb collaboration around 2000, Dirac has undergone significant evolution. A pivotal moment occurred in 2008 with a major refactoring, resulting in the development of the experiment-agnostic core Dirac, which paved the way for customizable extensions like LHCbDirac and BelleDirac, among others.
Despite its efficacy in meeting experiment-specific requirements, Dirac has accrued technical debt over its 15-year history. Installation management remains intricate, with significant entry barriers and a reliance on bespoke infrastructure. Additionally, the software development process lacks alignment with contemporary standards, impeding the onboarding process for new developers. Notably, integral components such as the network protocol and authentication mechanisms are proprietary and pose challenges for seamless integration with external applications.
In response to these challenges, the Dirac consortium has embarked on the development of DiracX. Drawing upon two decades of experience and battle-tested technological frameworks, DiracX heralds a new era in distributed computing solutions. This contribution describes technical decisions, roadmap and timelines for the development of DiracX.
This article presents an overview of the architecture underpinning DiracX, shedding light on the technological decisions guiding its development. Recognizing the criticality of maintaining a continuously operational Dirac system for numerous user communities, we delve into the intricacies of the migration process from Dirac to DiracX.
The ATLAS Google Project was established as part of an ongoing evaluation of the use of commercial clouds by the ATLAS Collaboration, in anticipation of the potential future adoption of such resources by WLCG grid sites to fulfil or complement their computing pledges. Seamless integration of Google cloud resources into the worldwide ATLAS distributed computing infrastructure was achieved at large scale and for an extended period of time, and hence cloud resources are shown to be an effective mechanism to provide additional, flexible computing capacity to ATLAS. For the first time a Total Cost of Ownership analysis has been performed, to identify the dominant cost drivers and explore effective mechanisms for cost control. Network usage significantly impacts the costs of certain ATLAS workflows, underscoring the importance of implementing such mechanisms. Resource bursting has been successfully demonstrated, whilst exposing the true cost of this type of activity. A follow-up to the project is underway to investigate methods for improving the integration of cloud resources in data-intensive distributed computing environments and reducing costs related to network connectivity, which represents the primary expense when extensively utilising cloud resources.
The metadata schema for experimental nuclear physics project aims to facilitate data management and data publication under the FAIR principles in the experimental Nuclear Physics communities, by developing a cross-domain metadata schema and generator, tailored for diverse datasets, with the possibility of integration with other, similar fields of research (i.e. Astro and Particle physics).
Our project focuses on creating a standardized, adaptable framework that enhances data Findability, Accessibility, Interoperability, and Reusability (FAIR principles). By creating a comprehensive and adaptable metadata schema, the project ensures scalable integration of both machine and human-readable metadata, thereby improving the efficiency of data discovery and utilization.
A pivotal component of the project is its nodal, multi-layered schema structure, allowing metadata enrichment from multiple domains while maintaining essential overlaps for enhanced versatility. This comprehensive approach supports the unification of data standards across various research institutions, promoting interoperability and collaboration on a European scale. Our efforts also extend to the development of a user-friendly frontend generator, designed not only to facilitate metadata input but also to allow users to specify field-specific attributes, customize generic names to suit their needs, and export schemas in various formats such as JSON and XML, adhering to different nomenclatures.
The project involves world-class RIs and ESFRIs, and leverages synergies from existing Open Science initiatives like EOSC, ESCAPE, EURO-LABS, and PUNCH4NFDI. In this contribution, we will present an overview of the project, detailing the development steps, key features of the metadata schema, and the functionality of the frontend generator.
For several years, the ROOT team is developing the new RNTuple I/O subsystem in preparation of the next generation of collider experiments. Both HL-LHC and DUNE are expected to start data taking by the end of this decade. They pose unprecedented challenges to event data I/O in terms of data rates, event sizes and event complexity. At the same time, the I/O landscape is getting more diverse. HPC cluster file systems and object stores, NVMe disk cache layers in analysis facilities, and S3 storage on cloud resources are mixing with traditional XRootD-managed spinning disk pools.
The ROOT team will finalize a first production version of the RNTuple binary format by the end of the year. After this point, ROOT will provide backwards compatibility for RNTuple data. This contribution provides an overview of the RNTuple feature set, the related R&D activities, and the long-term vision for RNTuple. We report on performance, interface design, tooling, robustness, integration with experiment frameworks, and validation results as well as recent R&D on parallel reading and writing and exploitation of modern hardware and storage systems. We will give an outlook on possible future features after a first production release.
Collaboratively, the IT and EP departments have launched a formal project within the Research and Computing sector to evaluate the novel data format for physics analysis data utilized in LHC experiments and other fields. This aspect of the project focuses on verifying the scalability of the storage back-end EOS during the migration from TTree to RNTuple, utilizing replicated and erasure coded profiles.
During Run-3 the Large Hadron Collider (LHC) experiments are transferring up to 10PB of data daily across the Worldwide LHC Computing Grid (WLCG) sites. However, following the transition from Run-3 to Run-4, data volumes are expected to increase tenfold. The WLCG Data Challenge aims to address this significant scaling challenge through a series of rigorous test events.
The primary objective of the 2024 Data Challenge (DC24) was to achieve 25% of the anticipated bulk transfer rate required for Run-4. Six experiments participated: the four LHC experiments—ATLAS, CMS, LHCb, and ALICE—as well as Belle II and DUNE. These experiments utilize the same networks, many of the same sites and the data management tools, that will be employed in Run-4. Additionally, DC24 aimed to test new technologies such as token-based authorization and advanced network monitoring tools.
The direct benefits of DC24 included identifying bottlenecks within the centralized data management systems of each experiment, gaining experience with significantly higher data transfer rates, and fostering significant collaboration among experiments and stakeholders. These stakeholders encompassed site administrators, storage technology providers, network experts, and middleware tool developers, all contributing to the preparedness for the demands of Run-4.
Back in the late 1990’s when planning for LHC computing started in earnest, arranging network connections to transfer the huge LHC data volumes between participating sites was seen as a problem. Today, 30 years later, the LHC data volumes are even larger, WLCG traffic has switched from a hierarchical to a mesh model and yet almost nobody worries about the network.
Some people still do worry, however. Even if LHC data transfers still account for over 50% of NREN traffic, other data-intensive experiments are coming on stream and network engineers worry about managing the overall traffic efficiently.
We present here the challenges likely to be keeping network engineers busy in the coming decade: how to monitor traffic from different communities, how to avoid congestion over transoceanic links; how to smooth traffic flows to maximise throughput, hand-over of large flows at interconnection points; cyber security and more.
Data and Metadata Organization, Management and Access
The CMS experiment manages a large-scale data infrastructure, currently handling over 200 PB of disk and 500 PB of tape storage and transferring more than 1 PB of data per day on average between various WLCG sites. Utilizing Rucio for high-level data management, FTS for data transfers, and a variety of storage and network technologies at the sites, CMS confronts inevitable challenges due to the system’s growing scale and evolving nature. Key challenges include managing transfer and storage failures, optimizing data distribution across different storages based on production and analysis needs, implementing necessary technology upgrades and migrations, and efficiently handling user requests. The data management team has established comprehensive monitoring to supervise this system and has successfully addressed many of these challenges. The team’s efforts aim to ensure data availability and protection, minimize failures and manual interventions, maximize transfer throughput and resource utilization, and provide reliable user support. This paper details the operational experience of CMS with its data management system in recent years, focusing on the encountered challenges, the effective strategies employed to overcome them and the ongoing challenges as we prepare for future demands.
The Deep Underground Neutrino Experiment (DUNE) is scheduled to start running in 2029, expected to record 30 PB/year of raw data. To handle this large-scale data, DUNE has adopted and deployed Rucio, the next-generation Data Replica service originally designed by the ATLAS collaboration, as an essential component of its Distributed Data Management system.
DUNE's use of Rucio has demanded the addition of various features to the Rucio code base, both specific functionality for DUNE alone, and more general functionality that is crucial for DUNE whilst being potentially useful for other experiments. As part of our development work, we have introduced a "policy package" system allowing experiment-specific code to be maintained separately from the core Rucio code, as well as creating a DUNE policy package containing algorithms such as logical to physical filename translation, and special permission checks. We have also developed other features such as improved object store support, and customisable replica sorting. A DUNE-specific test suite that will run on GitHub Actions is currently under development.
Recently, DUNE has deployed new internal monitoring to Rucio, enabling us to extract more useful information from core Rucio servers, and daemons such as transmogrifier, reaper, etc. Additionally, DUNE has implemented monitoring for Rucio transfer and deletion activities which are sent to a Message Queue via Rucio Hermes daemon. Information such as data location, accounting, and storage summary is extracted from the Rucio internal database and dumped into Elasticsearch for visualisation. The visualisation platforms utilised are based at Fermilab and Edinburgh. This monitoring is crucial for the ongoing DUNE data transfers and management development.
The File Transfer Service (FTS) is a bulk data mover responsible for queuing, scheduling, dispatching and retrying file transfer requests, making it a critical infrastructure component for many experiments. FTS is primarily used by the LHC experiments, namely ATLAS, CMS and LHCb, but is also used by some non-LHC experiments, including both AMS and DUNE. FTS is as an essential part in the data movement pipeline for these experiments and is responsible for moving their data across the world via the worldwide LHC computing Grid (WLCG).
The Square Kilometre Array (SKA) is a multi-purpose radio telescope that will play a major role in answering key questions in modern astrophysics and cosmology. The SKA will have a survey speed a hundred times that of current radio telescopes and its capabilities will allow transformational experiments to be conducted in a wide variety of science areas. Whilst the headquarters for this project is located at Jodrell Bank in the UK, the main telescope sites are located in South Africa and Australia. The two telescope sites will produce approximately 700 PB of data per year, which will need to be moved to one of the SKA regional centres located in member countries around the world to be stored, before being accessed by scientists. It is evident that there will be several similarities between the computing requirements for the LHC and SKA experiments, in particular the challenges posed by moving large quantities of data around a global network.
In this talk, we will discuss the usage of FTS by SKA and its ability to enable long-range data transfer across the developing SKA regional centre network of sites. We will also discuss some alterations to the FTS service ran at STFC to better support SKA, most notably the migration to token based authentication away from X509 certificates.
Modern physics experiments are often led by large collaborations including scientists and institutions from different parts of the world. To cope with the ever increasing computing and storage demands, computing resources are nowadays offered as part of a distributed infrastructure. Einstein Telescope (ET) is a future third-generation interferometer for gravitational wave (GW) detection, and is currently in the process of defining a computing model to sustain ET physics goals. A critical challenge for present and future experiments is an efficient and reliable data distribution and access system. Rucio is a framework for data management, access and distribution. It was originally developed by the ATLAS experiment and has been adopted by several collaborations within the high energy physics domain (CMS, Belle II, Dune) and outside (ESCAPE, SKA, CTA). In the GW community Rucio is used by the second-generation interferometers LIGO and Virgo, and is currently being evaluated for ET. ET will observe a volume of the Universe about one thousand times larger than LIGO and Virgo, and this will reflect on a larger data acquisition rate. In this contribution, we briefly describe Rucio usage in current GW experiments, and outline the on-going R&D activities for integration of Rucio within the ET computing infrastructure, which include the setup of an ET Data Lake based on Rucio for future Mock Data Challenges. We discuss the customization of Rucio features for the GW community: in particular we describe the implementation of RucioFS, a POSIX-like filesystem view to provide the user with a more familiar structure of the Rucio data catalogue, and the integration of the ET Data Lake with mock Data Lakes belonging to other experiments within the astrophysics and GW communities. This is a critical feature for astronomers and GW data analysts since they often require access to open data from other experiments for sky localisation and multi-messenger analysis.
The set of sky images recorded nightly by the camera mounted on the telescope of the Vera C. Rubin Observatory will be processed in facilities located on three continents. Data acquisition will happen in Cerro Pachón in the Andes mountains in Chile where the observatory is located. A first copy of the raw image data set is stored at the summit site of the observatory and immediately transferred through dedicated network links to the archive site and US Data Facility hosted at SLAC National Laboratory in California, USA. After an embargo period of a few days, the full image set is copied to the UK and French Data Facilities where a third copy is located.
During its 10 years in operation starting late 2025, annual processing campaigns across all images taken to date will be jointly performed by the three facilities, involving sophisticated algorithms to extract the physical properties of the celestial objects and producing science-ready images and catalogs. Data products resulting from the processing campaigns at each facility will be sent to SLAC and combined to create a consistent Data Release which is served to the scientific community for its science studies via Data Access Centers in the US and Chile and Independent Data Access Centers elsewhere.
In this contribution we present an overall view of how we leverage the tools selected for managing the movement of data among the Rubin processing and serving facilities, including Rucio and FTS3. We will also present the tools we developed to integrate Rucio’s data model and Rubin’s Data Butler, the software abstraction layer that mediates all access to storage by the pipeline tasks which implement the science algorithms.
The Belle II raw data transfer system is responsible for transferring raw data from the Belle II detector to the local KEK computing centre, and from there to the GRID. The Belle II experiment recently completed its first Long Shutdown period - during this time many upgrades were made to the detector and tools used to handle and analyse the data. The Belle II data acquisition (DAQ) systems received significant improvements, necessitating changes in the processing steps for raw data. Furthermore, experience gained during Run 1 identified areas where the scalability of the system could be improved to better handle the expected increase in data rates in future years.
To address these issues, extensive upgrades were made to the raw data transfer system, including: utilisation of the DIRAC framework for all data transfers; a change in the protocol used to communicate with the DAQ systems; and retirement of the previously used file format conversion component of the system. This talk will describe these changes and improvements in detail, and give an overview of the current state of the Belle II raw data transfer system.
Online and real-time computing
The Mu3e experiment at the Paul-Scherrer-Institute will be searching for the charged lepton flavor violating decay $\mu^+ \rightarrow e^+e^-e^+$. To reach its ultimate sensitivity to branching ratios in the order of $10^{-16}$, an excellent momentum resolution for the reconstructed electrons is required, which in turn necessitates precise detector alignment. To compensate for weak modes in the main alignment strategy based on electrons and positrons from muon decays, the exploitation of cosmic ray muons is proposed.
The trajectories of cosmic ray muons are so different from the decays of stopped muons in the experiment that they cannot be reconstructed using the same method in the online filter farm. For this reason and in view of their comparatively rare occurrence, a special cosmic muon trigger is being developed. A study on the application of graph neural networks to classify events and to identify cosmic muon tracks will be presented.
The increasing complexity and data volume of Nuclear Physics experiments require significant computing resources to process data from experimental setups. The entire experimental data set has to be processed to extract sub-samples for physics analysis. The advancements in Artificial Intelligence and Machine Learning fields provide tools and procedures that can significantly enhance the throughput of data processing and significantly reduce the computational resources needed to process and categorize the experimental data in the raw data stream. In CLAS12 machine learning methods are developed to perform track reconstruction in real-time, allowing the identification of physics reactions from the raw data stream with the rates exceeding the data acquisition rates. In this paper, we present the Neural Network-driven track reconstruction that allows event classification and physics analysis in real time. We present a complete physics analysis of the data processed in the online.
The reconstruction of charged particle trajectories in tracking detectors is crucial for analyzing experimental data in high-energy and nuclear physics. Processing of the vast amount of data generated by modern experiments requires computationally efficient solutions to save time and resources. In response, we introduce TrackNET, a recurrent neural network specifically designed for track recognition in pixel and strip-based particle detectors. TrackNET acts as a scalable alternative to the Kalman filter, exemplifying local tracking methods by independently processing each track-candidate. We rigorously tested TrackNET using the TrackML dataset and simulated data from the straw tracker of the SPD experiment at JINR, Dubna. Our results demonstrate significant improvements in processing speed and accuracy. The paper concludes with a comprehensive analysis of TrackNET's performance and a discussion on its limitations and potential enhancements.
Tracking charged particles resulting from collisions in the presence of strong magnetic field is an important and challenging problem. Reconstructing the tracks from the hits created by those generated particles on the detector layers via ionization energy deposits is traditionally achieved through Kalman filters that scale worse than linearly as the number of hits grow. To improve efficiency there is a need for developing new tracking methods. Machine Learning (ML) has been leveraged in several science applications for both speedups and improved results. To this line, a class of ML algorithms called Graph Neural Networks (GNNs) are explored for charged particle tracking. Each event in the particle tracking data naturally imposes itself as a graph structure with the event hits represented as graph nodes while track segments are represented as a subset of the graph edges that need to be correctly classified by the ML algorithm. We compare three different approaches for tracking at GlueX experiment at Jefferson Lab, namely traditional track finding, GPU-based GNN, and FPGA-based GNN. The comparison is held in terms of inference time and performance results. Beside presenting data processing, graph construction, and the used GNN model, we provide insight into resolving the missing hits issue for GNN training and evaluation. We show that the GNN model can achieve significant speedup by processing multiple events in batches which exploits the high parallel computation capability of GPUs. We present results on real GlueX data in addition to the collective results of the simulation data.
The ALICE Time Projection Chamber (TPC) is the detector with the highest data rate of the ALICE experiment at CERN and is the central detector for tracking and particle identification. Efficient online computing such as clusterization and tracking are mainly performed on GPU's with throughputs of approximately 900 GB/s. Clusterization itself has a well known background with a variety of algorithms in the field of machine learning. This work investigates a neural network approach to cluster rejection and regression on a topological basis. Central to its task are the center-of-gravity, sigma and total charge estimation as well as rejection of clusters in the TPC readout. Additionally, a momentum vector estimate is made from the 3D input across readout rows in combination with reconstructed tracks which can benefit track seeding. Performance studies on inference speed as well as model architectures and physics performance on Monte-Carlo data can be presented, showing that tracking performance can be maintained while rejecting 5-10% of raw clusters with a O(30%) reduced fake-rate for clusterization itself compared to the current GPU clusterizer.
Polarized cryo-targets and polarized photon beams are widely used in experiments at Jefferson Lab. Traditional methods for maintaining the optimal polarization involve manual adjustments throughout data taking-- an approach that is prone to inconsistency and human error. Implementing machine learning-based control systems can improve the stability of the polarization without relying on human intervention. The cryo-target polarization is influenced by temperature, microwave energy, the distribution of paramagnetic radicals, as well as operational conditions including the radiation dose. Diamond radiators are used to generate linearly polarized photons from a primary electron beam. The energy spectrum of these photons can drift over time due to changes in the primary electron beam conditions and diamond degradation. As a first step towards automating the continuous optimization and control processes, uncertainty aware surrogate models have been developed to predict the polarization based on historical data. This talk will provide an overview of the use cases and models developed, highlighting the collaboration between data scientists and physicists at Jefferson Lab.
Offline Computing
Jet reconstruction remains a critical task in the analysis of data from HEP colliders. We describe in this paper a new, highly performant, Julia package for jet reconstruction, JetReconstruction.jl, which integrates into the growing ecosystem of Julia packages for HEP. With this package users can run sequential reconstruction algoritms for jets, In particular, for LHC events, the Anti-$\mathrm{k_T}$, Cambridge/Aachen and Inclusive $\mathrm{k_T}$ algorithms can be used. For FCCee studies the use of alternative algorithms such as the generalised ee-$\mathrm{k_T}$ and Durham are also supported.
The full reconstruction history is made available, allowing inclusive and exclusive jets to be retrieved. The package also provides the means to visualise the reconstruction.
The implementation of the package in Julia is discussed, with an emphasis on the features of the language that allow for an easy to work with, ergonomic, code implementation, that achieves high-performance. Julia's ecosystem offers the possibility to vectorise code, using single-instruction-multiple-data processing, in way that is transparent for the developer and more flexible than optimization done via C and C++ compilers. Thanks to this feature, the performance of JetReconstuction.jl is better than the current Fastjet C++ implementation in jet clustering for p-p events produced at the LHC.
Finally, an example of an FCCee analysis using JetReconstruction.jl is shown.
Key4hep, a software framework and stack for future accelerators, integrates all the steps in the typical offline pipeline: generation, simulation, reconstruction and analysis. The different components of Key4hep use a common event data model, called EDM4hep. For reconstruction, Key4hep leverages Gaudi, a proven framework already in use by several experiments at the LHC, to orchestrate configuration and execution of reconstruction algorithms.
In this contribution, a brief overview of Gaudi is given. The specific developments built to make Gaudi work seamlessly with EDM4hep (and therefore in Key4hep) are explained, as well as other improvements requested by the Key4hep community. The list of developments includes a new IO service to run algorithms that read or write EDM4hep files in multithreading in a thread-safe way and a possibility to easily switch the EDM4hep I/O to the new ROOT RNTuple format for reading or writing. We show that both native (algorithms that use EDM4hep as input and output) and non-native algorithms from the ILC community can run together in Key4hep, picking up on knowledge and software developed over many years. A few examples of algorithms that have been created or ported to Key4hep recently are given, featuring the usage of Key4hep-specific features.
LUX-ZEPLIN (LZ) is a dark matter direct detection experiment using a dual-phase xenon time projection chamber with a 7-ton active volume. In 2022, LZ collaboration published a world leading limit on WIMP dark matter interactions with nucleons. The success of the LZ experiment hinges both on the resilient design of its hardware and software infrastructures. This talk will give an overview of the offline software infrastructure of the LZ experiment, which includes the automated movement of the data and real time processing at NERSC, using its foremost HPC machine, Perlmutter. Additionally, I will talk about the monitoring tools and web services that enable the management, and operation of LZ’s data workflow and cataloging.
ACTS is an experiment independent toolkit for track reconstruction, which is designed from the ground up for thread-safety and high performance. It is built to accommodate different experiment deployment scenarios, and also serves as community platform for research and development of new approaches and algorithms.
A fundamental component of ACTS is the geometry library. It models a simplified representation of a detector, compared to simulation geometries. It drives the numerical track extrapolation, provides crucial inputs to track finding and fitting algorithms, and is connected to many other geometry libraries in the ecosystem, shipping with multiple plugins.
ACTS’ geometry library is historically optimized for symmetric, collider-like detectors and most suitable for arrangements of silicon sensors. An effort has been underway for some amount of time to rewrite large parts of the geometry code.
The goal is to be more flexible to accommodate other detector approaches and simplify the building process, while providing easy conversion to a GPU-optimized geometry for use with the detray library. Another goal is to allow for a more systematic way to write geometry plugins.
Finally, the navigation logic is delegated to detector regions, so that it can be easily extended for unconventional environments.
This contribution reports on the result of this rewrite, discusses lessons learned from the project and how they were incorporated into a robust geometry modeling solution in ACTS that will be key going forward.
To increase the automation to convert Computer-Aided-Design detector components as well as entire detector systems into simulatable ROOT geometries, TGeoArbN, a ROOT compatible geometry class, was implemented allowing the use of triangle meshes in VMC-based simulation. To improve simulation speed a partitioning structure in form of an Octree can be utilized. TGeoArbN in combination with a CADToROOT-Converter (based on [1]) allowed e.g. for a high level of automation for the conversion of the forward endcap geometry of the PANDA electromagnetic calorimeter.
The aim of the talk is to give an overview on TGeoArbN and the modified CADToROOT-Converter version.
[1] T. Stockmanns, "STEP-to-ROOT – from CAD to Monte Carlo Simulation",
Journal of Physics: Conference Series 396 (2012) 022050,
url: https://doi.org/10.1088/1742-6596/396/2/022050
Distributed Computing
The CMS computing infrastructure spread globally over 150 WLCG sites forms a intricate ecosystem of computing resources, software and services. In 2024, the production computing cores breached half a million mark and storage capacity is at 250 PetaBytes on disk and 1.20 ExaBytes on Tape. To monitor these resources in real time, CMS working closely with CERN IT has developed a multifaceted monitoring system providing real time insights using about 100 production dashboards.
In preparation of Run3, the CMS monitoring infrastructure underwent significant evolution to broaden the scope of monitored applications and services while enhancing sustainability and ease of operation. Leveraging open-source solutions, provided either by the CERN IT department or managed internally, monitoring applications have transitioned from bespoke solutions to standardized data flow and visualization services. Notably, monitoring applications for distributed workload management and data handling have migrated to utilize technologies like OpenSearch, VictoriaMetrics, InfluxDB, and HDFS, with access facilitated through programmatic APIs, Apache Spark, or Sqoop jobs, and visualization primarily via Grafana.
The majority of CMS monitoring applications are now deployed on Kubernetes clusters based microservices architecture. This contribution unveils the comprehensive stack of CMS monitoring services, showcasing how the integration of common technologies enables versatile monitoring applications and addresses the computation demands of LHC Run 3. Additionally, it explores the incorporation of analytics into the monitoring framework, demonstrating how these insights contribute to the operational efficiency and scientific output of the CMS experiment.
JAliEn, the ALICE experiment's Grid middleware, utilizes whole-node scheduling to maximize resource utilization from participating sites. This approach offers flexibility in resource allocation and partitioning, allowing for customized configurations that adapt to the evolving needs of the experiment. This scheduling model is gaining traction among Grid sites due to its initial performance benefits. Additionally, understanding common execution patterns for different workloads allows for more efficient scheduling and resource allocation strategies.
However, managing the entire set of resources on a node requires careful orchestration. JAliEn employs custom mechanisms to dynamically allocate idle resources to running workloads, ensuring overall resource usage stays within the node's capacity.
This paper evaluates the experiences of the first sites using whole-node scheduling. It highlights its suitability for accommodating jobs with varying resource demands, particularly those with high memory requirements.
Job pilots in the ALICE Grid have become increasingly tasked with how to best manage the resources given to each job slot. With the emergence of more complex and multicore oriented workflows, this has since become an increasingly challenging process, as users often request arbitrary resources, in particular CPU and memory. This is further exacerbated by often having several user payloads running in parallel in the same slot, and with useful management utilities generally needing elevated privileges to function.
To alleviate resource management within each given job slot, the ALICE Grid has begun utilising novel features introduced in later Linux kernels, such as Cgroups v2, to provide means for fine-grained resource controls. By allowing specific controllers to be delegated down a Cgroup hierarchy, it enables users to access and tune these resource controls as needed - unprivileged. When further used in conjunction with the ALICE job pilot, it enables each job slot to be subpartitioned. In turn, allowing the pilot to act as its own local resource management system in its given slot - with a full “box-in” of each subjob to its own subset of the given resources.
This contribution describes the updated ALICE job pilot and its management and delegation process. Specifically, how it utilises kernel features to create individual resource groups for its jobs, while accommodating for the variety of configurations and computing elements used across participating sites - enabling these features to be used across the ALICE Grid.
The Unified Experiment Monitoring (UEM) is the project in WLCG with the objective to harmonise the WLCG job accounting reports across the LHC experiments, in order to provide aggregated reports of the compute capacity used by WLCG along time. This accounting overview of all LHC experiments is vital for the strategy planning of WLCG and therefore it finds the strong support of the LHC Committee (LHCC). However, creating common overviews is challenging, due to the different internals of each experiment monitoring system and also due to the long time scale of the reports to cover at least a decade of data. These monitoring systems evolved largely independently over time, implying that the UEM project has to design and implement different approaches to couple the multiple data sources within the CERN IT monitoring tools which will be used. Last but not least, the different terminologies have to be aligned into a useful and coherent set. This contribution will drive the audience through the motivations of the project, the challenges faced, the design adopted to overcome them, and the presentation of the state of the art.
The risk of cyber attack against members of the research and education sector remains persistently high, with several recent high visibility incidents including a well-reported ransomware attack against the British Library. As reported previously, we must work collaboratively to defend our community against such attacks, notably through the active use of threat intelligence shared with trusted partners both within and beyond our sector.
We discuss the development of capabilities to defend sites across the WLCG and other research and education infrastructures, with a particular focus on sites other than Tier1s which may have fewer resources available to implement full-scale security operations processes. These capabilities include a discussion of the pDNSSOC software which enables a lightweight and flexible means to correlate DNS logs with threat intelligence, and an examination of the use of Endpoint Detection and Response (EDR) tools in a high throughput context.
This report will include an important addition to the work of the Security Operations Centre Working Group; while this group had previously focused primarily on the technology stacks appropriate for use in deploying fine-grained security monitoring services, the people and processes involved with such capabilities are equally important.
Defending as a community requires a strategy that brings people, processes and technology together. We suggest approaches to support organisations and their computing facilities to defend against a wide range of threat actors. While a robust technology stack plays a significant role, it must be guided and managed by processes that make their cybersecurity strategy fit their environment.
GlideinWMS has been one of the first middleware in the WLCG community to transition from X.509 to support also tokens. The first step was to get from the prototype in 2019 to using tokens in production in 2022. This paper will present the challenges introduced by the wider adoption of tokens and the evolution plans for securing the pilot infrastructure of GlideinWMS and supporting the new requirements.
In the last couple of years, the GlideinWMS team supported the migration to tokens of experiments and resources. Inadequate support in the current infrastructure, more stringent requirements, and the higher spatial and temporal granularity forced GlideinWMS to revisit once more how credentials are generated, used, and propagated.
The new credential modules have been designed to be used in multiple systems (GWMS, HC) and use a model where credentials have type, purpose, and different flows.
Credentials are dynamically generated in order to customize the duration and limit the scope to the targeted resource. This allows to enforce the least privilege principle. Finally, we also considered adding credential storage, renewal, and invalidation mechanisms within the GlideinWMS infrastructure to serve better the experiments' needs.
Simulation and analysis tools
Non perturbative QED is used to predict beam backgrounds at the interaction point of colliders, in calculations of Schwinger pair creation and in precision QED tests with ultra-intense lasers. In order to predict these phenomena, custom built monte carlo event generators based on a suitable non perturbative theory have to be developed. One such suitable theory uses the Furry Interaction Picture, in which a background field is taken into account non perturbatively at Lagrangian level. This theory is precise, but the transition probabilities are in general, complicated. This poses a challenge for the monte carlo which struggles to implement the theory computatively. The monte carlo must in addition taken into acount the behaviour of the background field at every space-time point at which an event is generated. We introduce here just such a monte carlo package, called IPstrong, and the techniques implemented to deal with the specific challenges outlined above.
The effort to speed up the Madgraph5_aMC@NLO generator by exploiting CPU vectorization and GPUs, which started at the beginning of 2020, is expected to deliver the first production release of the code for QCD leading-order (LO) processes in 2024. To achieve this goal, many additional tests, fixes and improvements have been carried out by the development team in recent months, both to carry out its internal workplan and to respond to the feedback from the LHC experiments about the current and required functionalities of the software. Several new physics processes, including both Standard Model and Beyond Standard Model calculations, have been tested and extensively debugged. Support for AMD GPUs via native HIP has been added to the CUDA/C++ baseline implementation of the code; work is in progress to also add support for Intel GPUs to this CUDA/C++ plugin, based on the parallel SYCL implementation developed in the past. The user interface and packaging of the software, and the usability challenges coming from the large number of events that must be generated in parallel on a GPU, have also been an active area of development. In this contribution, we will report on these activities and on the status of the LO software at the time of the CHEP2024 conference. The status and outlook for one of the main further directions of our development effort, notably the support of next-to-leading-order (NLO) processes, is described in a separate contribution to this conference.
As the quality of experimental measurements increases, so does the need for Monte Carlo-generated simulated events — both with respect to total amount, and to their precision. In perturbative methods this involves the evaluation of higher order corrections to the leading order (LO) scattering amplitudes, including real emissions and loop corrections. Although experimental uncertainties today are larger than those of simulations, at the High Luminosity LHC experimental precision is expected to increase above the theoretical one for events generated below next-to-leading order (NLO) precision. As forecasted hardware resources do not meet CPU requirements for these simulation needs, speeding up NLO event generation is a necessity for particle physics research.
In recent years, collaborators across Europe and the United States have been working on CPU vectorisation of LO event generation within the MadGraph5_aMC@NLO framework, as well as porting it to GPUs, to major success. Recently, development has also started on vectorising NLO event generation. Due to the more complicated nature of NLO amplitudes this development faces several difficulties not accounted for in LO development. Nevertheless, this development seems promising, and a status report as well as the latest results will be presented in this contribution.
Quantum computers may revolutionize event generation for collider physics by allowing calculation of scattering amplitudes from full quantum simulation of field theories. Although rapid progress is being made in understanding how best to encode quantum fields onto the states of quantum registers, most formulations are lattice-based and would require an impractically large number of qubits when applied to scattering events at colliders with a wide momentum dynamic range. In this regard, the single-particle digitization approach of Barata et al. (Phys. Rev. A 103) is highly attractive for its qubit efficiency and strong association with scattering. Since the original work established the digitization scheme on the scalar phi4 theory, we explore its extensions to fermion fields and other types of interactions. We then implement small-scale scattering simulations on both real quantum computers and a statevector calculator run on HPCs. A possible roadmap toward realizing the ultimate goal of performing collider event generation from quantum computers will be discussed.
The generation of large event samples with Monte Carlo Event Generators is expected to be a computational bottleneck for precision phenomenology at the HL-LHC and beyond. This is due in part to the computational cost incurred by negative weights in 'matched' calculations combining NLO perturbative QCD with a parton shower: for the same target uncertainty, a larger sample must be generated.
We summarise two approaches taken to tackle this problem in Herwig: the development of the KrkNLO matching method, which uses a redefinition of the PDF factorisation scheme to guarantee positive weights by construction, and the restructuring of the Matchbox module to reduce the fraction of negative weights for MC@NLO matching.
The generation of Monte Carlo events is a crucial step for all particle collider experiments. Accurately simulating the hard scattering processes is the foundation for subsequent steps, such as QCD parton showering, hadronization, and detector simulations. A major challenge in event generation is the efficient sampling of the phase spaces of hard scattering processes due to the potentially large number and complexity of Feynman diagrams and their interference and divergence structures.
In this presentation, we address the challenges of efficient Monte Carlo event generation and demonstrate improvements that can be achieved through the application of advanced sampling techniques. We highlight that using the algorithms implemented in BAT.jl for sampling the phase spaces given by Sherpa offers great flexibility in the choice of sampling algorithms and has the potential to significantly enhance the efficiency of event generation.
By interfacing BAT.jl, a package designed for Bayesian analyses that offers a collection of modern sampling algorithms, with the Sherpa event generator, we aim to improve the efficiency of phase space exploration and Monte Carlo event generation. We combine the physics-informed multi-channel sampling approach of Sherpa with advanced sampling techniques such as Markov Chain Monte Carlo (MCMC) and Nested Sampling. Additionally, we investigate the potential of novel machine learning-enhanced sampling methods to optimize phase space mappings and accelerate the event generation process. The current prototype interface between Sherpa and BAT.jl features a modular design that offers full flexibility in selecting target processes and provides detailed control over the sampling algorithms. It also allows for a simple integration of innovative sampling techniques such as normalizing flow-enhanced MCMC.
Simulation and analysis tools
Within the ROOT/TMVA project, we have developed a tool called SOFIE, that takes externally trained deep learning models in ONNX format or Keras and PyTorch native formats and generates C++ code that can be easily included and invoked for fast inference of the model. The code has a minimal dependency and can be easily integrated into the data processing and analysis workflows of the HEP experiments.
This study presents a comprehensive benchmark analysis of SOFIE and prominent machine learning frameworks for model evaluation such as PyTorch, TensorFlow XLA and ONNXRunTime. Our research focuses on evaluating the performance of these tools in the context of HEP, with an emphasis on their application with typical models used, such as Graph Neural Netwarks for jet tagging and Variation auro-encoder and GAN for fast simulation. We assess the tools based on several key parameters, including computational speed, memory usage, scalability, and ease of integration with existing HEP software ecosystems. Through this comparative study, we aim to provide insights that can guide the HEP community in selecting the most suitable framework for their specific needs.
The HIBEAM-NNBAR experiment at the European Spallation Source is a multidisciplinary two-stage program of experiments that includes high-sensitivity searches for neutron oscillations, searches for sterile neutrons, searches for axions, as well as the search for exotic decays of the neutron. The computing framework of the collaboration includes diverse software, from particle generators to Monte Carlo transport codes, which are uniquely interfaced together. Significant advances have been made in computing and simulation for HIBEAM-NNBAR, particularly with machine learning applications and with the introduction of fast parametric simulations in Geant4. A summary of the simulation steps of the experiment, including beamline, cosmic veto system, as well as detector simulations and estimation of the background processes, will be presented.
The ROOT software framework is widely used in HENP for storage, processing, analysis and visualization of large datasets. With the large increase in usage of ML for experiment workflows, especially lately in the last steps of the analysis pipeline, the matter of exposing ROOT data ergonomically to ML models becomes ever more pressing. This contribution presents the advancements in an experimental component of ROOT that exposes datasets in batches ready for the training phase. This feature avoids the need for intermediate data conversion and can further streamline existing workflows, facilitating direct access of external ML tools to the ROOT input data in particular for the case when it does not fit in memory. The goal is to keep the footprint of using this feature minimal, in fact it represents just an extra line of code in user application. The contribution demonstrates such usage in various examples using different ML training models, also evaluating the performance with key metrics.
With the large data volume increase expected for HL-LHC and the even more complex computing challenges set by future colliders, the need for more elaborate data access patterns will become more pressing. ROOT’s next-generation data format and I/O subsystem, RNTuple, is designed to address those challenges, currently already showing a clear improvement in storage and I/O efficiency with respect to its predecessor, TTree. These improvements provide a solid baseline to introduce extensions that directly target common HENP workflow features not easily achievable before. Notably, many workflows benefit from the ability to join and concatenate data sets during application runtime, with the aim to reduce overall storage requirements and improve application ergonomics. The successful implementation of such compositions requires taking several factors into careful consideration, especially for large data sets that do not fit in memory. These factors include the transparent handling of (in)compatibility between different data sets, the rules that determine how data set compositions are processed, and their effects on runtime performance. In this contribution, we will present the ongoing work to support advanced composition of RNTuple data sets. We will discuss the main design considerations through a selection of concrete workflow use cases, the interfaces and internal machinery that enable the compositions, and an initial set of performance evaluation results.
Uproot is a Python library for ROOT I/O that uses NumPy and Awkward Array to represent and perform computations on bulk data. However, Uproot uses pure Python to navigate through ROOT's data structures to find the bulk data, which can be a performance issue in metadata-intensive I/O: (a) many small files, (b) many small TBaskets, and/or (c) low compression overhead. Worse, these performance issues can't be alleviated by multithreading because Python imposes a thread-lock between each instruction on its virtual machine, infamously known as the Global Interpreter Lock (GIL).
Python 3.13, released this month, introduces a fundamental new feature: a single Python process can run multiple interpreters, each in its own thread, each with its own (thread-local!) GIL. Subinterpreters are an intermediate choice between share-everything threads and share-nothing processes. Subinterpreters can only share Python objects through FIFO Queues (or, equivalently, Channels), and not by reference. However, they can freely operate on shared array data. Similar solutions can be cobbled together with multiple Python processes, using multiprocessing.Queue and multiprocessing.SharedMemory, but these rely on POSIX pipes and shared memory, depend on ulimit settings, and are much slower than subinterpreter communication.
In this talk, I'll show how Uproot takes advantage of subinterpreters to improve scaling for metadata-intensive I/O.
Representing HEP and astrophysics data as graphs (i.e. networks of related entities) is becoming increasingly popular. These graphs are not only useful for structuring data storage but are also increasingly utilized within various machine learning frameworks.
However, despite their rising popularity, numerous unused opportunities exist, particularly concerning the utilization of graph algorithms and intuitive visualization techniques.
This presentation will introduce a comprehensive graph framework designed for handling the HEP and astronomical data. The framework supports the storage, manipulation and analyses of the graph data, facilitating the use of elementary graph algorithms. Additionally, it enables the export of graph data to specialized external toolkit for more sophisticated processing and analysis.
An integral feature of the presented framework is its highly interactive, web-based graphical front-end. This interface provides users with deep insights into the graph structures of their data, enabling interactive analysis and multi-faceted visualization of graph properties. It also offers integration capabilities with other related frameworks.
The practical application of this framework will be demonstrated through its use in analyzing relationships between astronomical alerts, specifically from the Zwicky Transient Facility (ZTF) and the Rubin Observatory. By leveraging the collective properties and relationships within these data, the framework facilitates comprehensive analyses and provides recommendations based on object similarities and neighborhood characteristics. This approach paves the way for novel insights and methodologies in approach to data.
Computing Infrastructure
According to the estimated data rates, it is predicted that 800 TB raw experimental data will be produced per day from 14 beamlines at the first stage of the High-Energy Photon Source (HEPS) in China, and the data volume will be even greater with the completion of over 90 beamlines at the second stage in the future. Therefore, designing a high-performance, scalable network architecture plays a crucial role in the efficient output of scientific tasks. We designed a RoCE-based network framework for science workloads in HEPS data center, which provides high-performance network connectivity between HPES Data Acquisition system(DAQ) and HEPS data center, as well as the compute and storage system within the HEPS data center. The test results show that the performance of the RoCE-based network framework of the HEPS data center can be comparable to that of the IB-based network framework,and is better than the TCP/IP-based network framework.
In a DAQ system a large fraction of CPU resources is engaged in networking rather than in data processing. The common network stacks that take care of network traffic usually manipulate data through several copies performing expensive operations. Thus, when the CPU is asked to handle networking, the main drawbacks are throughput reduction and latency increase due to the overhead added to the data transmission process. Networking with zero-copy can be achieved by adding a Remote Direct Memory Access (RDMA) layer to the network stack and making dedicated hardware take care of the burden of the stack handling. Considering the ever-growing demand of larger bandwidth for big data systems, many works point in the direction of implementing network stacks on custom hardware. FPGAs are the natural target for reducing time to market and keeping a low entry-barrier. In this work implementation of RDMA directly on the front-end electronics is explored, in this way it is possible to free part of the computing farm's CPU resources. RDMA over Converged Ethernet (RoCE) is the industry-standard Ethernet-based RDMA solution with a multi-vendor ecosystem, making it the natural choice. This work focuses on the hardware implementation of a stripped-down version of RoCEv2 implementing only the transmitter part of the protocol, enabling its deployment in small FPGA such as the rad-hard parts used in the detector front-end. Preliminary results of resource usage, latency and throughput will be shown.
The data reduction stage is a major bottleneck in processing data from the Large Hadron Collider (LHC) at CERN, which generates hundreds of petabytes annually for fundamental particle physics research. Here, scientists must refine petabytes into only gigabytes of relevant information for analysis. This data filtering process is limited by slow network speeds when fetching data from globally dispersed storage facilities, which leads to thousands of wasted CPU hours waiting for data to arrive.
We demonstrate a near-data computing model that optimizes data access and enhances performance by filtering LHC data close to its storage before transmission over the slow network. This model is designed to be implemented with minimal change in the existing data layout and seamless integration with the underlying storage infrastructure, ensuring compatibility and ease of adoption for current systems.
We achieve this by deploying Data Processing Units (DPUs) within the storage cluster. Our model leverages DPU's high-bandwidth connections to perform fast data retrieval and filtering near storage, significantly improving overall data processing speeds and freeing up compute node CPUs for more important tasks. Additionally, it streamlines the workflow by removing coding complexities and making programming accessible for end users. We demonstrate that our model significantly outperforms current methods using real physics data and a realistic data reduction workflow.
With the large dataset expected from 2029 onwards by the HL-LHC at CERN, the ATLAS experiment is reaching the limits of the current data processing model in terms of traditional CPU resources based on x86_64 architectures and an extensive program for software upgrades towards the HL-LHC has been set up. The ARM CPU architecture is becoming a competitive and energy efficient alternative. Accelerators like GPUs are available in any recent HPC. In the past years ATLAS has successfully ported its full data processing and simulation software framework Athena to ARM and has invested significant effort in porting parts of the reconstruction and simulation algorithms to GPUs.
We report on the successful usage of the ATLAS experiment offline and online software framework Athena on ARM and GPUs through the PanDA workflow management system at various WLCG sites. Furthermore we report on performance optimizations of the builds for ARM CPUs and the GPU integration efforts. We will discuss performance comparisons of different ARM and x86 architectures on WLCG resources and Cloud compute providers like GCP and AWS using ATLAS productions workflows as used in the HepScore23 benchmark suite.
GPUs and accelerators are changing traditional High Energy Physics (HEP) deployments while also being the key to enable efficient machine learning. The challenge remains to improve overall efficiency and sharing opportunities of what are currently expensive and scarce resources.
In this paper we describe the common patterns of GPU usage in HEP, including spiky requirements with low overall usage for interactive access, as well as more predictable but potentially bursty workloads including distributed machine learning. We then explore the multiple mechanisms to share and partition GPUs, covering time slicing, virtualization, physical partitioning (MIG) and MPS for Nvidia devices.
We conclude with the results of an extensive set of benchmarks for multiple representative HEP use cases, including traditional GPU usage as well as machine learning. We highlight the limitations of each option and the use cases where they fit best. Finally, we cover the deployment aspects and the different options available targeting a centralized GPU pool that can significantly push the overall GPU usage efficiency.
The Glance project provides software solutions for managing high-energy physics collaborations' data and workflow. It was started in 2003 and operates in the ALICE, AMBER, ATLAS, CMS, and LHCb CERN experiments on top of CERN common infrastructure. The project develops Web applications using PHP and Vue.js, running on CENTOS virtual machines hosted on the CERN OpenStack private cloud. These virtual machines are built via Puppet for installing and configuring core software while tailoring them to meet each experiment's requirements in a collaborative approach under the Glance Project. This approach minimizes redundant work across experiments while allowing cooperation when responding to operations incidents. In the scenario of the CENTOS 7 end-of-life, the Glance project has chosen to migrate to RHEL9 while undergoing a major upgrade of PHP from (7.3 or 7.4 to 8.2) across the experiments. This presentation will expose the technical and organizational challenges the Glance project faces on common dependencies upgrades from the perspective of the ATLAS Glance team.
GlideinWMS, a widely utilized workload management system in high-energy physics (HEP) research, serves as the backbone for efficient job provisioning across distributed computing resources. It is utilized by various experiments and organizations, including CMS, OSG, Dune, and FIFE, to create HTCondor pools as large as 600k cores. In particular, a shared factory service historically deployed at UCSD has been configured to interface with more than 500 routes to compute clusters.
As part of our team's initiative to modernize infrastructure and enhance scalability, we undertook the migration of the glideinWMS factory service into the Kubernetes environment. Leveraging the flexibility and orchestration capabilities of Kubernetes, we successfully deployed the factory service within the OSG Tiger Kubernetes cluster. The major benefits Kubernetes gives us is it streamlines the management and monitoring of the factory infrastructure, and improves fault tolerance through its resilient deployment strategies.
Through this case study, we aim to share insights, challenges, and best practices encountered during the migration process. Our experience underscores the benefits of embracing containerization and Kubernetes orchestration for HEP computing infrastructure, paving the way for scalability and resilience in distributed computing environments.
The Super Tau-Charm Facility (STCF) is a proposed electron-positron collider in China, designed to achieve a peak luminosity exceeding $\rm 0.5 \times 10^{35} \ cm^{-2} s^{-1}$ and a center-of-mass energy ranging from 2 to 7 GeV. To meet the particle identification (PID) requirements essential for the physics goals of the STCF experiment, a dedicated PID system is proposed to identify $\rm \pi/K$ at momenta up to 2 GeV/c. This system comprises a Ring Imaging Cherenkov (RICH) detector for the barrel region and a time-of-flight detector using internally reflected Cherenkov light (DTOF) for the endcap region. In this report, we introduce likelihood analysis methods to evaluate the PID performance of both the RICH and DTOF detectors within the STCF offline software framework. These methods utilize photon 2D hit maps, with 2D spatial positions for the RICH and time-position patterns for the DTOF, to distinguish particles. Furthermore, we present two distinct analytical approaches tailored for each detector, facilitating the rapid extraction of photon hit patterns for comprehensive likelihood analysis.
One of the most significant challenges in tracking reconstruction is the reduction of "ghost tracks," which are composed of false hit combinations in the detectors. When tracking reconstruction is performed in real-time at 30 MHz, it introduces the difficulty of meeting high efficiency and throughput requirements. A single-layer feed-forward neural network (NN) has been developed and trained to address this challenge. The simplicity of the NN allows for parallel evaluation of many track candidates to filter ghost tracks using CUDA within the Allen framework. This capability enables us to run this type of NN at the first level of the trigger (HLT1) in the LHCb experiment. This neural network approach is already utilized in several HLT1 algorithms and is becoming an essential tool for Run 3. Details of the implementation and performance of this strategy will be presented in this talk.
The Italian National Institute for Nuclear Physics (INFN) has recently launched the INFN Cloud initiative, aimed at providing a federated Cloud infrastructure and a dynamic portfolio of services to scientific communities supported by the Institute. The federative middleware of INFN Cloud is based on the INDIGO PaaS orchestration system, consisting of interconnected open-source microservices. Among these, the INDIGO PaaS Orchestrator receives high-level deployment requests in the form of TOSCA templates and coordinates the process of creating deployments on the IaaS platforms made available by the federated providers.
Through internal projects like INFN DataCloud and European initiatives such as interTwin and AI4EOSC, INFN is working to improve the orchestration system by integrating artificial intelligence to optimize deployment scheduling. This contribution outlines the preparatory work to identify the key features and their sources (e.g., databases, logs, monitoring tools), followed by the data preprocessing necessary for in-depth analysis of different AI techniques. The first implemented approach involves the design of two models: one for the deployment success/failure classification and another for the deployment time regression. The combination of the output of the two models trained on recent and sliding time windows aims to define the ordered list of providers that the orchestrator can use for deployment submission.
An alternative solution for an AI-based Orchestrator could involve a Reinforcement Learning approach, in which an agent is trained as if it has to win a game and learns which provider is best suited to user demand.
The future Compressed Baryonic Matter experiment (CBM), which is currently being planned and will be realised at the Facility for Antiproton and Ion Research (FAIR), is dedicated to the investigation of heavy-ion collisions at high interaction rates. For this purpose, a track-based software alignment is necessary to determine the precise detector component positions with sufficient accuracy. This information is crucial as it enables adequate utilisation of the high intrinsic accuracy of the sensors.
The alignment parameters to be determined are typically translations and rotations of individual sensors in relation to their intended nominal positions. They are usually determined by minimising a $\chi^2$ function of a set of high quality reconstructed tracks.
To complement the available alignment tools, an additional approach is being developed that is based on brute-force $\chi^2$ minimisation. On the one hand, this approach should allow different parameters to be treated individually and, on the other hand, it opens up the possibility of integrating different types of constraints into the minimisation, such as inequality and non-linear constraints.
This contribution presents the latest developments in the application of brute-force alignment within the CBM project. The question of how the results of optical detector measurements, which usually precede software alignment, can be taken into account in this procedure is also addressed.
This work is supported by BMBF (05P21RFFC1).
The Alpha Magnetic Spectrometer (AMS) is a particle physics experiment installed and operating aboard the International Space Station (ISS) from May 2011 and expected to last through 2030 and beyond. Data reconstruction and Monte-Carlo simulation are two major production activities in AMS offline computing, and templates are defined as a collection of data cards to describe different reconstruction and simulation tasks and to provide necessary input parameters. This paper presents how we use the Continuous Integration mechanism in GitLab to better manage the production datasets and templates, including syntax checking, functionality testing, performance testing, and the integration with existing production statistics monitoring system. The system also uses the pipeline schedules to periodically check the completing status of the production tasks and send warning messages to the administrators if the production progress is not as expected.
The LUX-ZEPLIN (LZ) experiment is a world-leading direct dark matter detection experiment, implementing a dual-phase Xe Time Projection Chamber (TPC) design. The success of the experiment necessitates an in-depth characterization of the pertinent backgrounds, which in turn implies a heavy simulations burden. In this talk, I will present the infrastructure that was developed to allocate and manage the simulations workload on Perlmutter, NERSC’s most recent HPC facility. The pipeline includes a system to automatically generate production configurations based on requests from the simulations team, along with utilites to monitor job progress and success. A RabbitMQ queue is used to coordinate job dispatchement amongst a selection of workers running on specially allocated compute nodes, allowing for fine-grained control over the use of computational resources available.
The Belle II experiment relies on a distributed computing infrastructure spanning 19 countries and over 50 sites. It is expected to generate approximately 40TB/day of raw data in 2027, necessitating distribution from the High Energy Accelerator Research Organization (KEK) in Japan to six Data Centers across the USA, Europe, and Canada. Establishing a high-quality network has been a priority since 2012 to address the challenge of transferring data across long distances in high-latency environments. This effort has included joining LHCONE and conducting periodic Data Challenges to assess network performance following significant changes in infrastructure or experiment schedules.
In February 2024 Belle II joined the WLCG Data Challenge, performed together with LHC experiments with the goal to test network performance under stress, particularly due to the anticipated increase in traffic from the experiments with the High Luminosity LHC program at CERN.
In this work, we will present a comprehensive overview of the tests conducted by Belle II. We will start with the test design, define the goals, and outline the preliminary steps taken. We will then describe the working environment, the tests performed, and the tools employed. Furthermore, we will discuss the results achieved in detail. Finally, we will outline the future steps for subsequent tests.
In anticipation of the High Luminosity-LHC era, there's a critical need to oversee software readiness for upcoming growth in network traffic for production and user data analysis access. This paper looks into software and hardware required improvements in US-CMS Tier-2 sites to be able sustain and meet the projected 400 Gbps bandwidth demands, while tackling the challenge posed by varying latencies between sites. Specifically, our study focuses on identifying the performance of XRootD HTTP third-party copies across multiple 400 Gbps links and exploring different host and transfer configurations.
Our approach involves systematic testing with variations in the number of origins per cluster and CPU, Memory allocations for each origin. By replicating real network conditions and creating network "loops" that traverse multiple switches across the wide area network, we are able to replicate authentic network conditions.
Managing and orchestrating complex data processing pipelines require advanced systems capable of handling diverse and collaborative components, such as data acquisition, streaming, aggregation, event identification, distribution, detector calibration, processing, analytics, and archiving. This paper introduces a data processing workflow description and orchestration system designed to facilitate the coordination and operation of these components using both centralized orchestration and decentralized choreography approaches. Our system employs a decentralized actor-based model used in the data acquisition system and data stream processing framework at Jefferson Lab (JLAB) to create component-specific configurations for the effective choreography of component actors. Simultaneously, the centralized orchestration provides global control and management of the entire data processing pipeline from acquisition to final processing. Our system's core is an ontology language developed explicitly for serializing data processing pipeline descriptions. A user-friendly graphical interface also enables seamless data pipeline composition and real-time monitoring. This integrated approach ensures efficient deployment, management, and orchestration of data processing workflows, ensuring robustness and flexibility in handling complex scientific data workflows.
The Cling C++ interpreter has transformed language bindings by enabling incremental compilation at runtime. This allows Python to interact with C++ on demand and lazily construct bindings between the two. The emergence of Clang-REPL as a potential alternative to Cling within the LLVM compiler framework highlights the need for a unified framework for interactive C++ technologies.
We present CppInterOp, a C++ Interoperability library, which leverages Cling and LLVM's Clang-REPL, to provide a minimalist and backward-compatible API facilitating seamless language interoperability. This provides downstream interactive C++ tools with the compiler as a service by embedding Clang and LLVM as libraries in their codebases. By enabling dynamic Python interactions with static C++ codebases, CppInterOp enhances computational efficiency and rapid development in high-energy physics. The library offers primitives enabling cppyy(PyROOT), an automatic, run-time, Python-C++ bindings generator. We also demonstrate CppInterOp's utility in diverse computing environments through its adoption as the runtime engine for xeus-cpp, a Jupyter kernel designed for C++.
CppInterOp is a general-purpose library inspired by the developments in the ROOT framework which pushed the frontiers of interactive C++. It aims to extend this approach and serve as an integral component of ROOT, enhancing both speed and resilience. This talk introduces CppInterOp to the HEP community and showcases how it optimizes cross-language execution and computational tasks in high-energy physics, making it a valuable tool for researchers and developers.
The processing tasks of an event-processing workflow in high-energy and nuclear physics (HENP) can typically be represented as a directed acyclic graph formed according to the data flow—i.e. the data dependencies among algorithms executed as part of the workflow. With this representation, an HENP framework can optimally execute a workflow, exploiting the parallelism inherent among independent tasks. Despite such a natural description of a workflow, most HENP frameworks do not make use of technologies that provide concurrent execution of graph-based tasking structures.
In this talk, we describe Fermilab efforts to adopt a graph-based technology (specifically Intel’s oneTBB flow graph) for meeting the framework needs of its experiments, notably DUNE. Building on the Meld project as presented at CHEP2023, we demonstrate that all common processing idioms supported by current frameworks can naturally be supported by oneTBB’s data-flow technology, optimally leveraging the concurrent capabilities of the machine. In addition, we discuss collaborative efforts between Fermilab and the Intel oneTBB development team, who is considering improvements to the flow-graph technology to better support HENP use cases.
The High Energy Photon Source (HEPS) in China will become one of the world's fourth-generation synchrotron light sources with the lowest emittance and highest brightness. The 14 beamlines for the phase I of HEPS will produces about 300PB/year raw data, posing significant challenges in data storage, data access, and data exchange. In order to balance the cost-effectiveness of storage devices and realize the high reliability of data storage, a three-tier storage is designed for storing experimental data, including beamline storage, central storage, and tape. Raw data and processed data are stored on the beamline storage for a maximum of 7 days, on the central storage for a maximum of 90 days, and only the raw data are archived to tape for long-term storage with two copies. Of course, this data storage policy could be adjusted according to the actual data volume and funding situation of HEPS. The beamline storage utilizes a distributed all-flash SSD array to achieve high data input/output speeds. The central storage utilizes a distributed high-density HDD array to achieve medium to high-speed data IO. The tape storage complies with the LTO9 standard.
In addition, we have conducted some personalized optimizations based on the requirements of the HEPS project, such as adapting the Lustre file system to the Roce network protocol, and mapping permissions for users from AD domain control and LDAP domain control.
In neutron scattering experiments, the complexity of data analysis and the demand for computational resources have significantly increased. To address these challenges, we have developed a remote desktop system for neutron scattering data analysis based on the Openstack platform. This system leverages WebRTC technology to build a push-pull streaming service system, which includes the development of modules for screen capture, stream transmission, and GPU-based screen rendering. By integrating and optimizing these technical modules, we have realized an interactive web-based remote desktop tailored for neutron scattering users.
Firstly, we set up a virtualized environment on Openstack to provide flexible resource management and high availability. Utilizing WebRTC technology, we achieved efficient screen capture and transmission, ensuring real-time and smooth remote desktop operations. Furthermore, the GPU-based screen rendering module significantly enhances the performance of image processing and display, meeting the high computational demands of neutron scattering data analysis.
The final implementation of this system not only provides an efficient, interactive remote data analysis platform but also significantly improves the efficiency of neutron scattering data analysis. Users can perform real-time data processing and analysis through a web interface without the need for local high-performance computing devices. This innovative solution offers new possibilities for neutron scattering data analysis and lays a solid foundation for future scientific research.
The CBM experiment at FAIR-SIS100 will investigate strongly interacting matter at high baryon density and moderate temperature. One of proposed key observable is the measurement of the low mass vector mesons(LMVMs), which can be detected via their di-lepton decay channel. As the decayed leptons leave the dense and hot fireball without further interactions, they can provide unscathed information about the fireball, produced in energetic nuclear collisions.
We report, simulation results for the reconstruction of di-muon continuum spectra for AuAu 8AGeV central collisions using machine learning(ML) techniques for selection of muon track candidates. The results from various ML models have been compared with the traditional selection cuts for omega($\omega$), eta($\eta$), phi($\phi$), rho($\rho$)mesons and full di-muon cocktail spectra.
We have attempted to reconstruct LMVM ($\omega, \eta, \phi, \rho$) in the event by event mode using standard reconstruction software. Background of central Au-Au collisions at 8 AGeV was generated using UrQMD event generator, whereas for LMVMs signals PLUTO event generator was used. Single LMVM decaying into $\mu^+$ + $\mu^- $ was embedded into each background event. The particles are then transported through the experimental setup including upgraded Muon Chamber(MuCh) setup, using the GEANT3 transport engine. Various ML algorithms like Gradient boosted decision trees (BDTG), KNN, MLP, HMatrix etc. from the TMVA class have been employed for the present study.
Based on the the simulation results, improvement in di-muon performance is reported. For comparable S/B ratio, the pair reconstruction efficiency and significance is observed to be increased subtantially for $\omega, \eta, \phi$ mesons using ML techniques.
How does one take a workload, consisting of millions or billions of tasks, and group it into tens of thousands of jobs? Partitioning the workload into a workflow of long-running jobs minimizes the use of scheduler resources; however, smaller, more fine-grained jobs allow more efficient use of computing resources. When the runtime of a task averages a minute or less, severe scaling challenges due to scheduling overhead can surface. Employing jobs that run for several hours, each with a large input file comprising a bundle of tasks, is effective in ideal situations. However, given the heterogeneity of available distributed resources and limited control of task-job matching, runtimes can vary widely.
The Event Workflow Management System (EWMS) augments HTCondor to solve this issue. EWMS implements a pilot-based paradigm where each worker, running inside an HTCondor execution point, connects to a message broker and executes many individual fine-grained tasks. This adaptive design increases task throughput while incorporating additional fail-safe features. In addition, EWMS manages workflow scheduling, enables real-time worker scaling, and exports a public-facing interface for user accessibility. Here, we outline the EWMS technique, detail science driver workflows from the IceCube experiment, and provide system usage metrics.
The EvtGen generator, an essential tool for the simulation of heavy-flavour hadron decays, has recently gone through a modernisation campaign aiming to implement thread safety. A first iteration of this concluded with an adaptation of the core software, where we identified possibilities for future developments to further exploit the capabilities of multi-threaded processing. However, the current main limitations stem from external dependencies that are not yet thread safe, such as the simulation of final state radiation (FSR). Along with thread safety, we have recently implemented alternatives for FSR simulation which open new possibilities for systematic studies.
Online reconstruction of charged particle tracks is one of the most computationally intensive tasks within current and future filter farms of large HEP experiments, requiring clever algorithms and appropriate hardware choices for its acceleration. The General Triplet Track Fit is a novel track-fitting algorithm that offers great potential for speed-up by processing triplets of hits independently. FPGAs, with their inherent parallelism, power efficiency and reconfigurability, are becoming increasingly attractive as co-processors for large data centres, such as the filter farms, to meet the challenges of increasing throughput and computational complexity.
We present an FPGA implementation of the General Triplet Track Fit suitable for future use in heterogeneous online farms. The algorithm is implemented on AMD FPGAs using high-level synthesis. We discuss algorithmic optimisation strategies to exploit the full potential of the device.
In response to increasing data challenges, CMS has adopted the use of GPU offloading at the High-Level Trigger (HLT). However, GPU acceleration is often hardware specific, and increases the maintenance burden on software development. The Alpaka (Abstraction Library for Parallel Kernel Acceleration) portability library offers a solution to this issue, and has been implemented into the CMS software (CMSSW) for use online at HLT.
A portion of the final-state particle candidate reconstruction algorithm, Particle Flow, has been ported to Alpaka and deployed at HLT for 2024 data taking. The formation of hadronic Particle Flow clusters represented a target for increased performance through parallel operation. We will discuss the port of hadronic Particle Flow clustering to Alpaka, and the validation of physics and performance at HLT.
An Artificial Intelligence (AI) model will spend “90% of its lifetime in inference.” To fully utilize coprocessors, such as FPGAs or GPUs, for AI inference requires O(10) CPU cores to feed to work to the coprocessors. Traditional data analysis pipelines will not be able to effectively and efficiently use the coprocessors to their full potential. To allow for distributed access to coprocessors for AI inference workloads, the LHC’s Compact Muon Solenoid (CMS) experiment has developed the concept of Services for Optimized Network Inference on Coprocessors (SONIC) using NVIDIA’s Triton Inference Servers. We have extended this concept for the IceCube Neutrino Observatory by deploying NVIDIA’s Triton Inference Servers in local and external Kubernetes clusters, integrating an NVIDIA Triton Client with IceCube’s data analysis framework, and deploying an OAuth2-based HTTP authentication service in front of the Triton Inference Servers. We will describe the setup and our experience adding this to IceCube’s offline processing system.
We describe the justIN workflow management system developed by DUNE to address its unique requirements and constraints. The DUNE experiment will start running in 2029, recording 30 PB/year of raw data from the detectors, with typical readouts at the scale of gigabytes, but with regular supernova candidate readouts of several hundred terabytes. DUNE benefits from the rich heritage of neutrino experiments at Fermilab, including the use of the SAM system to manage data, metadata, and processing campaigns. Due to the increase in scale required for DUNE, SAM's metadata database has been replaced by a new system, MetaCat, and its data management role is now taken up by Rucio. A new workflow system, justIN, has been developed since 2021 to replace the remaining functionality of SAM, and to tie together MetaCat, Rucio, and the GlideInWMS job management system to allow data processing campaigns involving hundreds of thousands of files and jobs using CPU and storage on four continents. Crucial to the design of justIN is an evolution of SAM's just-in-time philosophy, in which running jobs ask the central service for the optimal file to process next given their location. This model and the SAM interface are directly supported by the liquid argon data processing application used by DUNE, and justIN's design allows us to continue to support both. justIN goes a step further by assigning the workflows themselves to running GlideInWMS pilot jobs based on the locations of unprocessed files in active workflows at that time. This architecture allows the system to rapidly respond to problems such as downtimes, and to the sudden appearance of higher priority tasks such as processing supernova candidates.
The High Luminosity phase of the LHC (HL-LHC) will offer a greatly increased number of events for more precise standard model measurements and BSM searches. To cope with the harsh environment created by numerous simultaneous proton-proton collisions, the CMS Collaboration has begun construction of a new endcap calorimeter, the High-Granularity Calorimeters (HGCAL). As part of this project, a new reconstruction framework, TICL, is being developed, aiming to exploit the possibilities of heterogeneous computing, and employing machine learning elements.
While TICL has shown impressive results for particle shower reconstruction in HGCAL, the proposed calorimeters’ high granularity can be used to track muons. Precise tracking of externally identified muons through the calorimeter allows them to be used for the crucial task of following the evolving inter-cell relative response, and calibrating it, in order to maintain good energy resolution.
In this contribution, we propose to integrate a Kalman Filter into the TICL framework for dedicated muon reconstruction. Furthermore, we present a comprehensive performance evaluation of the algorithm under various conditions akin to those at the HL-LHC. Finally, we discuss the capabilities and limitations of the Kalman Filter as a tool for inter-cell calibration.
On behalf of JUNO collaboration.
The Jiangmen Underground Neutrino Observatory (JUNO), located in Southern China, is a neutrino experiment aiming to determine the neutrino mass ordering (NMO) and precisely measure neutrino oscillation parameters. JUNO is expected to operate over 20-30 years, generating approximately 2PB of raw data annually. Offline Data Processing Workflow involves data transfer, reconstruction, grid computing, and long-term data preservation. Keep Up Production (KUP) pipeline addresses the need for a pipeline-driven approach to handle the intricate and interdependent steps of raw data processing without human intervention. The message-driven architecture decouples subsystems of pipeline and allows subsystems to process data in an asynchronous manner, which means that each processing step can be performed independently. KUP will automatically create and submit the reconstruction job. It uses YMAL files as job templates, which provides flexibility, allowing for easy modification and adjustment of the template without the need to modify the system's code. KUP also provides the real-time tracking and monitoring feature of job running status. It enhances job stability and reliability, minimizing the impact of job failures.
In CMS, data access and management is organized around the data-tier model: a static definition of what subset of event information is available in a particular dataset, realized as a collection of files. In previous works, we have proposed a novel data management model that obviates the need for data tiers by exploding files into individual event data product objects. We present here a study of the fraction of event data products per data-tier actively read by CMS users as collected by CRAB3, to estimate the storage savings CMS could realize by adopting such a model.
To study and search for increasingly rare physics processes at the LHC, a staggering amount of data needs to be analyzed with progressively complex methods. Analyses involving tens of billions of recorded and simulated events, multiple machine learning algorithms for different purposes, and an amount of 100 or more systematic variations are no longer uncommon. These conditions impose a complex data flow on an analysis workflow and render its steering and bookkeeping a serious challenge. For this purpose, a toolkit for columnar HEP analysis, called columnflow, has been developed. It is written in Python, experiment agnostic in its core, and supports any flat file format, such as ROOT-based trees or Parquet files. Leveraging on the vast Python ecosystem, vectorization and convenient physics objects representation can be achieved through NumPy, awkward arrays and other libraries. Based upon the Luigi Analysis Workflow (law) package, columnflow provides full analysis automation over arbitrary, distributed computing resources. Despite the end-to-end nature, this approach allows for persistent, intermediate outputs for purposes of debugging, caching, and exchange with collaborators. Job submission to various batch systems, such as HTCondor, Slurm, or CMS-CRAB, is natively supported. Remote files can be seamlessly accessed via various protocols using either the Grid File Access Library (GFAL2) or the fsspec file system interface. In addition, a sandboxing mechanism can encapsulate the execution of parts of a workflow into dedicated environments, supporting subshells, virtual environments, and containers. This contribution introduces the key components of columnflow and highlights the benefits of a fully automated workflow for complex and large-scale HEP analyses.
High energy physics experiments are making increasing use of GPUs and GPU dominated High Performance Computer facilities. Both the software and hardware of these systems are rapidly evolving, creating challenges for experiments to make informed decisions as to where they wish to devote resources. In its first phase, the High Energy Physics Center for Computational Excellence (HEP-CCE) produced portable versions of a number of heterogeneous HEP mini-apps, such as p2r, FastCaloSim, Patatrack and the WireCell Toolkit, that exercise a broad range of GPU characteristics, enabling cross platform and facility benchmarking and evaluation. However, these mini-apps still require a significant amount of manual intervention to deploy on a new facility.
We present our work in developing turn-key deployments of these mini-apps, where by means of containerization and automated configuration and build techniques such as spack, we are able to quickly test new hardware, software, environments and entire facilities with minimal user intervention, and then track performance metrics over time.
Uproot can read ROOT files directly in pure Python but cannot (yet) compute expressions in ROOT’s TTreeFormula expression language. Despite its popularity, this language has only one implementation and no formal specification. In a package called “formulate,” we defined the language’s syntax in standard BNF and parse it with Lark, a fast and modern parsing toolkit in Python. With formulate, users can now convert ROOT TTreeFormula expressions into NumExpr and Awkward Array manipulations.
In this contribution, we describe BNF notation and the Look Ahead Left to Right (LALR) parsing algorithm, which scales linearly with expression length. We also present the challenges with interpreting TTreeFormula expressions as a functional language; some function-like forms can’t be expressed as true functions. We also describe the design of the abstract syntax tree that facilitates conversion between the three languages. The formulate package has zero package dependencies, so we are adding it as one of Uproot's dependencies so that Uproot will be able to use TTreeFormula expressions, whether they are hand-written or embedded in a ROOT file as TTree aliases.
The DUNE experiment will produce vast amounts of metadata, which describe the data coming from the read-out of the primary DUNE detectors. Various databases will collect the metadata from different sources. The conditions data, which is the subset of all the metadata that is accessed during the offline reconstruction and analysis, will be stored in a dedicated database. ProtoDUNE at CERN is the largest DUNE far detector prototype, and as such serves to prove database solutions and schemas for DUNE.
The ProtoDUNE Run Conditions Database is a PostgreSQL relational database that stores the conditions metadata coming from sources such as: DAQ, Slow Control, and Beam databases. This contribution will summarize the Run Conditions Database infrastructure which consists of a python rest API users' interface, a C++ interface, an Art interface (which is the framework used for the offline LArTPC data processing), and a plug in to the new data catalog (MetaCat). We will present how the conditions data, coming from the slow controls database, is retrieved, studied, and stored in a convenient format.
As a WLCG prototype T1 site, IHEP's network performance directly impacts the site's reliability. The current primary method for measuring network performance is implemented through Perfsonar, which actively measures performance metrics such as bandwidth, connection status, one-way and two-way latency, packet loss rate, and jitter between IHEP and other sites. However, there is a lack of relatively efficient network performance issue detection capabilities, posing significant challenges for network operations personnel when addressing network performance problems. This paper proposes a machine learning-based network anomaly detection algorithm, utilizing performance metric data obtained from both Perfsonar and third-party network monitoring tools. By integrating network protocol analysis and network traffic analysis techniques, the algorithm achieves network communication anomaly detection and alerting, Ultimately, this enhances the ability to detect network performance issues, helping network operations personnel to provide a more efficient network environment more effectively and quickly.
The Compressed Baryonic Matter experiment (CBM) at FAIR is designed to explore the QCD phase diagram at high baryon densities with interaction rates up to 10 MHz using triggerless free-streaming data acquisition. For the overall PID, the CBM Ring Imaging Cherenkov detector (RICH) contributes by identifying electrons from lowest momenta up to 10 GeV/c, with a pion suppression of > 100. The RICH reconstruction combines a local Cherenkov ring finding with a ring-track matching of found rings and extrapolated tracks from the Silicon Tracking System (STS).
The existing conventional algorithms were revised and optimized, and alternative machine learning approaches were investigated. Methods based on CNN/GNN architectures were developed for ring finding, noise suppression and ring-track matching while taking into account the latency and data format (space and time, i.e. 3+1) constraints of the triggerless free-streaming readout. The methods were tested and validated on simulations taking into account the time data stream and on data from the prototype mini-RICH (mRICH) in the mini-CBM (mCBM) experiment, which shares the same free-streaming readout concept as the future CBM experiment.
Research groups at scientific institutions have an increasing demand for computing and storage resources. The national High-Performance Computing (HPC) systems usually have a high threshold to come in and cloud solutions could be challenging and demand a high learning curve.
Here we introduce the Scientific NREC Cluster (SNC), which leverages the Norwegian Research and Education Cloud (NREC). NREC operates on an Infrastructure-as-a-Service (IaaS) model, offering users full control over host administration, installation, and upgrade options for provided virtual instances. The SNC project aims to bridge the gap between the foundational NREC infrastructure and user requirements, providing easy access to flexible cluster resources and storage while maintaining elevated levels of security and flexibility. Nevertheless, the solution is built from the data-centric point of view, where it gives easy access to the campus storage.
SNC offers a SLURM queueing system with the following functionalities: access to the central, shared and secure storage solution; centralized user authentication from the campus Active Directory; provisioning based on NREC's Infrastructure-as-a-Service policy; monitoring solution with the Prometheus/Grafana ecosystem, including both metrics and log messages of the actual user jobs; access to the scientific software stack EESSI - European Environment for Scientific Software Installations.
As an initial release, SNC has been launched as a compact solution tailored for research groups at the University of Bergen. Examples of user stories, usability, and scaling studies will be highlighted in the presentation.
The proposal to create a multi-Tev Muon Collider presents an unprecedented opportunity for advancing high energy physics research and offers the possibility to accurately measure the Higgs couplings with other Standard Model particles and search for new physics at TeV scale.
This demands for accurate full event reconstruction and particle identification. However, this is complicated by the beam induced background (BIB), originating from the decays of the muons of the beam, that represents one of the major challenges for the experiment design and that poses potential limitations on the detector performances and requirements on radiation hardness. The discrimination of signal showers from the BIB requires high granularity, superb energy resolution and precise timing. The calorimeter should thus provide 5D measurement (3D position, time and energy).
To address these challenges, an innovative hadronic calorimeter has been designed that utilizes Micro Pattern Gas Detectors (MPGDs) as active layers. MPGDs are ideal for high radiation environments and offer high granularity for precise spatial measurements. The response of such MPGD-based HCAL to the incoming particles is studied and presented in this contribution with Monte Carlo simulations performed using GEANT4, comparing the performance of a digital and semi-digital readout and considering the energy resolution as a figure of merit.
This contribution details the design and optimization of the MPGD-based hadronic calorimeter, and shows a comparison of the simulated performance with preliminary experimental data. This project is endorsed by the International Muon Collider Collaboration.
The CERN Single Sign On (SSO) hosting infrastructure underwent a major reconstruction in 2023 in an effort to increase service reliability and operational efficiency.
This session will outline how the Cloud Native Computing Foundation (CNCF) tools facilitate that, with particular attention to the key decisions, difficulties, and architectural concerns for this critical IT service
CloudVeneto is a distributed private cloud, which harmonizes the resources of two INFN units and the University of Padua. Tailored to meet the specialized scientific computing needs of user communities within these organizations, it promotes collaboration and enhances innovation. CloudVeneto basically implements an OpenStack based IaaS (Infrastructure-as-a-Service) cloud. However users are also provided with some higher level services, such as the CloudVeneto Container-as-a-Service (CaaS).
Unlike the user-managed Kubernetes-as-a-Service (KaaS) model, CaaS offers a fully managed orchestration platform, eliminating administrative overhead for users. CloudVeneto has developed a CaaS solution designed to provide a secure, multi-tenant Kubernetes platform, where users deploy application containers to our service without the burden of administrative tasks. Our solution features a centrally managed Kubernetes control plane, allowing users to create and customize nodes on demand using CloudVeneto resources within their projects. These nodes, deployed as Virtual Machines, integrate seamlessly into the cluster, giving users the flexibility to maintain node privacy or share them within their OpenStack projects, while delegating deployment and monitoring tasks to CaaS. By implementing CaaS, CloudVeneto meets the diverse requirements of the user community, including those of Quantum, ISOLPHARM and SPES, underlining its adaptability within the CloudVeneto ecosystem. Furthermore, we were able to successfully demonstrate that it is possible to offload part of the workload submitted to a remote external Kubernetes cluster to the CloudVeneto CaaS service using the interLink-sidecar solution implemented in the context of the EU interTwin project, effectively extending the Virtual Kubelet concept.
For nearly five decades, Data Centre Operators have provided critical support to the CERN Meyrin Data Centre, from its infancy, until spring 2024. However, advancements in Data Centre technology and resilience built into IT services have rendered the Console Service obsolete.
In the early days of the Meyrin Data Centre, day to day operations relied heavily on the expertise and manual operations of Console Operators. A crucial function of the Console operator was the manual management of the massive tape libraries used for data storage. More recently, operators have been ensuring the uptime of Data Centre equipment, responding to local power incidents, and coordinating response to incidents in the data centre.
In this talk we’ll cover the principles that underpin the decision for terminating the service, a view into the gradual wind down of the service and the transfer of critical functions to operations teams at CERN.
In low-energy nuclear physics experiments, an Active Target Time Projection Chamber (AT-TPC) [1] can be advantageous for studying nuclear reaction kinematics. The α-cluster decay of $^{12}C$ is one such reaction requiring careful investigation due to its vital role in producing heavy elements through astrophysical processes [2]. The breakup mechanism of the Hoyle state, a highly α-clustered state at 7.65 MeV in $^{12}C$, has long been an important case of study using different experimental techniques to investigate its decaying branch ratio. The direct decay of the Hoyle state into three α-particles and the sequential decay via the $^8Be$ ground state into three α-particles can be identified by tracking the α-particles and measuring their energies, which can be accomplished with AT-TPC.
In this work, a numerical model using Hough transformation and neural network models for track separation and classification has been developed for identifying the breakup of Hoyle state $^{12}C$ into three α-particles from the background scattering events in the active volume. The reaction kinematics of the decay of $^{12}C$ have been determined using low-energy non-relativistic scattering of α-particles on $^{12}C$. The event tracks in the active gas medium of the AT-TPC have been generated through primary ionization created by the α-particles produced in the aforementioned reaction. This has been carried out using the Geant4 [3] simulation framework. The three α-tracks have then been individually separated from the others and the background (uniform random noise generated) using the Hough transformation. Each α-track has been fitted with a CrystalBall function to extract the features useful for training the Artificial Neural Network (ANN) model. A Convolutional Neural Network (CNN) model has also been developed to identify all possible scattering events of $^4He$ and $^{12}C$ in the lab frame which are labeled as background events. These events have been further labeled by binary and multi-class classification models, which have been trained using simulated data. For this purpose, a fully connected ANN and CNN with hidden layers have been implemented using the high-level deep learning library Keras, written in Python [4]. The model has been tested on the events generated using simulation. Thus, it has been possible to precisely classify the Hoyle state α-particles from background events. This model can also be beneficial as an automated analysis framework for tagging and separating events from experimental data.
[1] D. Suzuki et al., NIM A 691(2012) 39–54
[2] M. Freer, Reports on Progress in Physics 70, 2149 (2007)
[3] GEANT4 collaboration, GEANT4: A Simulation toolkit 2003 NIM A 506 (2003) 250-303
[4] F. Chollet et al., Keras, https://keras.io, 2015.
We present the new user-sharing feature of the REANA reproducible analysis platform. The researchers are allowed to share their selected workflow runs, job logs, and output files with colleagues. The analyst retains the full read-write access to the workflow and may opt for granting individual read-only access to colleagues for a possibly-limited period of time. The workflow sharing feature was developed to answer the needs of physics teams using REANA computational workflow platform and is available for all supported CWL, Serial, Snakemake, and Yadage workflow systems. The feature is available in the REANA command-line client and on the REANA web interface. The contribution describes the main use cases, presents the architecture and the implementation details, as well as comments on the challenges of supporting a variety of external Identity and Access Management systems holding user information for customising REANA deployments.
Data and Metadata Organization, Management and Access
Since the start of LHC in 2008, the ATLAS experiment has relied on ROOT to provide storage technology for all its processed event data. Internally, ROOT files are organized around TTree structures that are capable of storing complex C++ objects. The capabilities of TTrees developed over the years and are now offering support for advanced concepts like polymorphism, schema evolution and user defined collections and ATLAS makes use of these features to handle its EDM. But some original TTrees concepts, like the POSIX file model and sequential writing, remain unchanged since the beginning and could be an obstacle to achieving the performance required for High Luminosity LHC.
With the HL-LHC performance goals in mind, the ROOT project developed a new storage format - the RNTuple. RNTuple, with its accompanying user API, is now in the final development stage and is planned to be production-ready at the end of 2024. Soon after that the TTree will become a legacy format.
ATLAS intends to have its main Event processing framework Athena ready to use RNTuple in the production environment as early as possible. The work on adopting RNTuple as another ROOT storage technology in Athena started already in 2021 and is now nearly complete. Although the initial goal was to focus on derived-AOD products (PHYS and PHYSLITE), with a little added effort all ATLAS data products: RDO, HITS, ESD, AOD and DAOD can be now stored in RNTuple format and transparently read back.
In this paper we will describe the current state of RNTuple adoption in the Athena framework and explain the ATLAS EDM requirements that had to be met on the ROOT side to successfully integrate both environments. We will demonstrate the ability to run standard ATLAS production workflows, based on RNTuple as the Event data storage technology, and point out key advantages of the new format.
ROOT is planning to move from TTree to RNTuple as the data storage format for HL-LHC in order to, for example, speed up the IO, make the files smaller, and have a modern C++ API. Initially, RNTuple was not planned to support the same set of C++ data structures as TTree supports. CMS has explored the necessary transformations in its standard persistent data types to switch to RNTuple. Many challenges were encountered as alternative data structures were explored. This contribution will discuss the challenges uncovered and how collaboration with the ROOT team allowed them to be overcome. The solution to the challenges allows progressive changes to the CMS data types rather than requiring a sudden change to all data types to be stored in RNTuple. Once the solution was achieved, storage performance comparisons using the CMS data types were possible between RNTuple and TTree. This contribution will also present the results of those comparisons.
Although caching-based efforts [1] have been in place in the LHC infrastructure in the US, we show that integrating intelligent prefetching and targeted dataset placement into the underlying caching strategy can improve job efficiency further. Newer experiments and experiment upgrades such as HL-LHC and DUNE are expected to produce 10x the amount of data than currently being produced. This means that the available network, storage and compute resources must be utilized efficiently. Additionally, newer generations of DAQs are moving towards streaming readout systems, navigating away from the traditional triggered systems. These newer DAQ systems offer continuous/real-time data calibration, reconstruction and storage by offloading to remote sites results [2, 3]. These observations imply that the available network, storage and compute resources must be used efficiently.
The benefits in CPU efficiency and job turnaround times from colocating the datasets near computation are well-known, especially using dedicated or opportunistic cache storages using XCache or dCache systems [4]. Our prior work using the data transfer logs collected from the OSG dashboard revealed two major observations. First, there is a correlation between transfer time and the choice of storage site. The choice of source site, in case of storage redundancy, was found to be more important in transfer time than the actual file size (the dataset consists of many files). Second, there is not only a popularity skew in the remote files accessed by the jobs, but also files that are part of the same dataset are read more than others in that dataset.

File size vs. Transfer Time for data chunks with markers colored
by the Data Source. The data in the figures are collected over 24-hour
period in 2019. There are two clearly demarcated groups of transfer
time values. Mid-Top left in figures show Group 1, a group of transfer
with low transfer times. For this group, the files are served by a
single data source (identified by dark yellow color). The second
group, Group 2 (see the bottom group of data points) consists of
smaller file sizes, and they show a wide distribution of transfer
times.

File size vs. Time of the Day plot of a single day from March
of 2020 on the OSG. Left-side plot spans a single day in the March of
2020 and the right-side is a 2.5-hour snapshot of the same day. Each
star represents a single file transfer. The color of the star
represents a unique source from where the file was transferred from.
Using our analysis of the experiment and data pipelines, and the data access patterns in the US HEP environment, we present intelligent Machine Learning (ML)-based approaches to reduce the latency and improve job efficiency. We incorporate our prefetching and data placement techniques into a simulator by extending the WRENCH [5] simulator to reflect the experiment and data workflows typical in the US HEP infrastructure. The simulator is designed to reflect the US HEP environment (data, storage and computation workflows, and infrastructure). Simulators have long had an established history in planning and development of HEP infrastructure like WLCG (MONARC simulator) [6]. Simulations make it feasible to compare different network, storage and compute settings without building real testbeds for each setting. We present the proof-of-concept of our simulator with tight agreements to the real-world behavior of the experiments in US, specifically those belonging to LHC (CMS etc.) and DUNE.
REFERENCES
1. Fajardo, Edgar, Derek Weitzel, Mats Rynge, Marian Zvada, John Hicks, Mat Selmeci, Brian Lin et al. "Creating a content delivery network for general science on the internet backbone using XCaches." In EPJ Web of Conferences, vol. 245, p. 04041. EDP Sciences, 2020.
2. Lawrence D. Streaming Readout and Remote Compute. Thomas Jefferson National Accelerator Facility (TJNAF), Newport News, VA (United States); 2023 May 1.
3. Suiu, Alice-Florenţa. "EPN2EOS Data Transfer System." PhD diss., University POLITEHNICA of Bucharest, 2023.
4. Acosta-Silva C, Casals J, Peris AD, Molina JF, Hernández JM, Pérez CM, Dengra CP, Yzquierdo AP, Rodríguez FJ. A case study of content delivery networks for the CMS ex-periment.
5. Casanova, Henri, Suraj Pandey, James Oeth, Ryan Tanaka, Frédéric Suter, and Rafael Ferreira Da Silva. "Wrench: A framework for simulating workflow management systems." In 2018 IEEE/ACM Workflows in Support of Large-Scale Science (WORKS), pp. 74-85. IEEE, 2018.
6. Iosif C. Legrand and Harvey B. Newman. “The MONARC Toolset for Simulating Large Network-Distributed Processing Systems”. Proceedings of the 32nd Conference on Winter Simulation. WSC ’00. Orlando, Florida: Society for Computer Simulation International, 2000, pp. 1794–1801. ISBN: 0780365828.
The High-Luminosity upgrade of the Large Hadron Collider (HL-LHC) will increase luminosity and the number of events by an order of magnitude, demanding more concurrent processing. Event processing is trivially parallel, but metadata handling is more complex and breaks that parallelism. However, correct and reliable in-file metadata is crucial for all workflows of the experiment, enabling tasks such as job configuration, decoding trigger information, and keeping track of event selection. Therefore, ATLAS is enhancing its current in-file metadata system to support metadata creation and propagation in more robust ways. This talk presents developments in the areas of the evolution of storage technology for metadata and the redesign of metadata tools.
Firstly, we delve into the investigation of storage technologies tailored for in-file metadata payload, exploring advancements in the ROOT framework, used for storing data collected by the ATLAS experiment. Not only will this work allow ATLAS to utilize modern storage containers (such as RNTuple) for event and metadata, but the goal is to enhance performance and enable seamless handling of metadata. We also discuss whether a challenging process of merging metadata objects could be performed generically, e.g. using RNTuple features.
Furthermore, we introduce a novel approach to metadata tools by developing dual-mode functionality. Such tools, offering both creation and propagation capabilities, improve maintainability and facilitate handling in workflows making use of shared I/O functionality. This work also enables investigation of metadata propagation outside of event processing.
The ATLAS Metadata Interface (AMI) is a comprehensive ecosystem designed for metadata aggregation, transformation, and cataloging. With over 20 years of feedback in the LHC context, it is particularly well-suited for scientific experiments that generate large volumes of data.
This presentation explains, in a general manner, why managing metadata is essential regardless of the experiment's scale. It then presents the different AMI ecosystem's components and their main functionalities, particularly the Web interfaces for searching data based on metadata criteria. Finally, it discusses the deployment of a functional demo, its subsequent scaling up, and how to integrate it into a data production system.
Large international collaborations in the field of Nuclear and Subnuclear Physics have been leading the implementation of FAIR principles for managing research data. These principles are essential when dealing with large volumes of data over extended periods and involving scientists from multiple countries. Recently, smaller communities and individual experiments have also started adopting these principles.
Many universities and research institutions are creating teams of Data Stewards in order to promote the implementation of FAIR principles (such as writing good Data Management Plans), particularly for smaller research units.
This contribution outlines the strategy adopted by the Italian National Institute for Nuclear Physics (INFN) to define the Data Steward profile and make its role suitable for the organization. This initiative is also linked to the Skills4EOSC project, which aims at establishing a network of competence centers for training European researchers and developing new professional roles for managing scientific data.
Online and real-time computing
ALICE is the dedicated heavy ion experiment at the LHC at CERN and records lead-lead collisions at a rate of up to 50 kHz.
The detector with the highest data rate of up to 3.4 TB/s is the TPC.
ALICE performs the full online TPC processing corresponding to more than 95% of the total workload on GPUs, and when there is no beam in the LHC, the online computing farm's GPUs are used to speed up the offline processing.
After the deployment of the first version of the online TPC processing needed for data taking, ALICE has implemented many improvements to its GPU processing framework.
These include a run time compilation mode applying on the fly optimizations, improvements to parallelize / speed up the GPU compilation, debugging modes to guarantee reproducible and deterministic results in concurrent reconstruction, and framework features to leverage common components in the code of different detectors.
The talk will give an overview of the ALICE experience with GPUs in online and offline processing and present the latest GPU processing framework features.
ATLAS is one of the two general-purpose experiments at the Large Hadron
Collider (LHC), aiming to detect a wide variety of physics processes. Its
trigger system plays a key role in selecting the events that are detected,
filtering them down from the 40 MHz bunch crossing rate to the 1 kHz rate at
which they are committed to storage. The ATLAS trigger works in two stages,
Level- 1 and the High-Level Trigger (HLT), with the first being a
hardware-based coarse filtering applied using custom electronics and FPGAs, and
the second relying on offline-like algorithms implemented fully in software,
running on a farm of commodity CPUs. The LHC will undergo the High-Luminosity
Upgrade soon (scheduled to be finished by 2029), which represents an additional
challenge for the ATLAS trigger. The increased pile-up leads to events that are
typically more complex and thus more computationally demanding to reconstruct,
and a broad-ranging suite of upgrades to the ATLAS detector itself also
encompasses increasing the input and output rates of the High Level Trigger by
a factor of 10. As such, both the processing power required to handle a single
event and the overall number of events that will need to be processed will
increase, placing greater pressure on the trigger farm. One possibility of
answering these increased computational demands in a cost- and energy-effective
way is the use of hardware accelerators, in particular leveraging the massive
parallelism and general computational capabilities offered by GPUs for problems
that are suited to their mode of operation.
Among the algorithms being assessed for GPU acceleration, Topological
Clustering, the main and most computationally demanding stage of calorimeter
reconstruction, has reached the significant milestone of 100% agreement with
the CPU algorithm and maximum speed-ups in excess of a factor of 10. This is
achieved through a more GPU-friendly variant of the algorithm, dubbed
Topo-Automaton Clustering. A significant bottleneck remains in the time taken
to convert between the data representation used within the GPU and the
equivalent CPU data structures, which can be up to two thirds of the total
execution time of the algorithm. This contribution will describe the
development, optimization and integration of Topo- Automaton Clustering with
the ATLAS trigger, including the latest benchmarks and ongoing efforts to
develop an EDM framework that could allow for a general description of
GPU-friendly data structures in order to alleviate the main bottleneck.
In preparation for the High Luminosity LHC (HL-LHC) run, the CMS collaboration is working on an ambitious upgrade project for the first stage of its online selection system: the Level-1 Trigger. The upgraded system will use powerful field-programmable gate arrays (FPGA) processors connected by a high-bandwidth network of optical fibers. The new system will access highly granular calorimeter information and online tracking: their combination for identifying physics objects is a key asset to cope with the harsh HL-LHC environment without compromising physics acceptance. The track matching is particularly relevant for identifying calorimeter deposits originating from electron particles. Traditional identification techniques rely on several independent selection stages applied to the calorimeter and track primitives, followed by an angular matching procedure. A new machine learning approach is presented, combining track and calorimeter information into a single identification and matching step. The new algorithm leverages new technologies for running fast inference on FPGA.
The talk will report on the system design, the implementation in firmware, and the performance obtained on simulated events.
The General Triplet Track Fit (GTTF) is a generalization of the Multiple Scattering Triplet Fit [NIMA 844 (2017) 135] to additionally take hit uncertainties into account. This makes it suitable for use in collider experiments, where the position uncertainties of hits dominate for high momentum tracks. Since the GTTF is based on triplets of hits that can be processed independently, the fit is particularly suitable for acceleration with parallel hardware such as GPUs, and can therefore be used for fast track fitting in online reconstruction. The performance of the track fit and its acceleration is studied using the OpenDataDetector in traccc, a demonstrator tracking chain designed for hardware accelerators under the umbrella of the ACTS track reconstruction framework, and the results will be presented.
The CBM experiment is expected to run with a data rate exceeding 500 GB/s even after averaging. At this rate storing raw detector data is not feasible and an efficient online reconstruction is instead required. GPUs have become essential for HPC workloads. The higher memory bandwidth and parallelism of GPUs can provide significant speedups over traditional CPU applications. These properties also make them a promising target for the planned online processing in CBM.
We present an online hit finder for the STS detector capable of running on GPUs. It consists of four steps using STS digis (timestamped detector messages) as input. Digis first are sorted by sensor and then for each sensor, they are sorted by channel and their timestamp. Neighboring digis are combined into clusters. Finally, after time sorting clusters on each sensor are combined into hits.
Each of those steps is trivially parallel across STS sensors or even sensor sides. To fully utilize GPU hardware, we modify the algorithms to be parallel on digi or cluster level. This includes a custom implementation of parallel merge sort allowing full parallelism within GPU blocks.
Our implementation achieves a speedup of 24 on mCBM data compared to the same code on a single CPU core. The exact achieved throughput will be shown and discussed during the presentation.
This work is supported by BMBF (05P21RFFC1).
The PANDA experiment has been designed to incorporate software triggers and online data processing. Although PANDA may not surpass the largest experiments in terms of raw data rates, designing and developing the processing pipeline and software platform for this purpose is still a challenge. Given the uncertain timeline for PANDA and the constantly evolving landscape of computing hardware, our attention is directed towards ensuring the future-proofness of the solutions we develop.
The PandaR2 is a concept for a framework handling online data processing in heterogeneous and distributed HPC environments. It utilizes the SYCL programming model as the primary technology for parallelization and offloading. Being a new and standalone entity, PandaR2 also interfaces with the PANDA's original ROOT-based simulation and analysis framework - PandaRoot, connecting the best of both worlds.
This contribution aims to present an overview of the PandaR2 SYCL-centric architecture. We will share experiences with SYCL during the codebase design process, particularly highlighting its portability across various hardware platforms and compilers. Additionally, we will showcase the performance results of the initial algorithms implemented in PandaR2, focusing on the performance portability of SYCL code and comparison with native programming models for accelerators, such as CUDA or HIP.
Offline Computing
Electrons are one of the key particles that are detected by the CMS experiment and are reconstructed using the CMS software (CMSSW). Reconstructing electrons in CMSSW is a computational intensive task that is split into several steps, seeding being the most time consuming one. During the electron seeding process, the collection of tracker hits (seeds) is significantly reduced by selecting only seeds that are compatible with a hypothesized electron trajectory. This contribution will describe the process of redesigning the electron seeding algorithm in a parallelizable way that will exploit the massive parallelism that GPUs can offer. The new algorithm code base is implemented using the Alpaka library, a performance portability library that allows having a single code base for execution on different types of hardware.
GPUs are expected to be a key solution to the data challenges posed by track reconstruction in future high energy physics experiments. traccc, an R&D project within the ACTS track reconstruction toolkit, aims to demonstrate tracking algorithms in GPU programming models including CUDA and SYCL without loss of physical accuracy such as tracking efficiency and fitted parameter resolution. We discuss the current status and demonstrate the performance of the full track reconstruction chain with GPUs for the first time. The physical and computational performance are studied using events simulated in the Open Data Detector, which is an open-source tracking geometry. The benchmark result shows that a GPU is faster than a CPU for pp collision events with pileups higher than 140, corresponding to the data size of the HL-LHC. We also explore its potential as an experimental-independent toolkit for other high energy physics experiments such as ATLAS and CEPC.
The Circular Electron Positron Collider (CEPC) is a future experiment mainly designed to precisely measure the Higgs boson’s properties and search for new physics beyond the Standard Model. In the design of the CEPC detector, the VerTeX detector (VTX) is the innermost tracker playing a dominant role in determining the vertexes of a collision event. The VTX detector is also responsible for providing seeds for the track following algorithms to find tracks in the outer trackers. TRACCC is one of the R&D lines aiming for developing the demonstrator for a full tracking chain for accelerators within the ACTS project.
This contribution will present the implementation of the seeding algorithm for the VTX detector based on TRACCC in the CEPC software (CEPCSW) environment. The integration of TRACCC into the CEPCSW, which is using Gaudi as the underlying framework and employing DD4hep as detector description tool and EDM4hep as the event data model, will be introduced. The CEPC VTX detector has three layers and both sides of each layer are mounted with silicon pixel sensors. To accommodate this specific detector structure, the default seeding algorithm in TRACCC, which creates three-space-points seeds, has been extended for six space points case. This contribution will also describe the solution of using one common memory for both EDM4hep and VecMem to avoid the overhead from data copy. For all the above work, both physics performance and computing performance are measured and will be presented.
During Run 3, ALICE has enhanced its data processing and reconstruction chain by integrating GPUs, a leap forward in utilising high-performance computing at the LHC.
The initial 'synchronous' phase engages GPUs to reconstruct and compress data from the TPC detector. Subsequently, the 'asynchronous' phase partially frees GPU resources, allowing further offloading of additional reconstruction tasks to enhance efficiency. Notably, ITS tracking has been ported as an independent module for two major GPU platforms.
This presentation will detail the integration of ITS GPU tracking within the existing framework, aiming to develop a unified GPU-based reconstruction pipeline.
This pipeline minimises memory transfer latency by coordinating various simultaneous processing stages.
Performance metrics of the integrated system will be discussed, highlighting the technical strategies and outcomes of this implementation.
Distributed Computing
The WLCG infrastructure is quickly evolving thanks to technology evolution in all areas of LHC computing: storage, network, alternative processor architectures, new authentication & authorization mechanisms, etc. This evolution also has to address challenges like the seamless integration of HPC and cloud resources, the significant rise of energy costs, licensing issues and support changes. WLCG Operations Coordination serves to organize parts of this evolution in close collaboration with the stakeholders: LHC experiments, sites, EGI and OSG infrastructure providers and middleware projects. This contribution describes how WLCG Operations Coordination helps ensure the smooth functioning of the WLCG infrastructure during Run 3 addressing the challenges described above and its preparation for the High-Luminosity LHC phase.
This paper presents a comprehensive analysis of the implementation and performance enhancements of the new job optimizer service within the JAliEn (Java ALICE environment) middleware framework developed for the ALICE grid. The job optimizer service aims to efficiently split large-scale computational tasks into smaller grid jobs, thereby optimizing resource utilization and throughput of the grid by ensuring more grid resources are able to match with grid jobs. New functionalities for users of the grid are described, while also delving into back-end changes that have improved the job optimizer service.
Through testing and evaluation in a production environment, significant improvements in database performance, faster job splitting, and better scalability have been observed when doing comparative analysis against the legacy job optimization service. Further potential improvements in the future will also be explored.
This paper will also provide a look into the technical intricacies of the new job optimizer service, highlighting functionalities, implementation strategies, and integration within the existing JAliEn framework. Furthermore, insights into the lessons learned and challenges encountered during the implementation phase, deployment, and operationalization of the job optimizer service will be discussed.
HammerCloud (HC) is a framework for testing and benchmarking resources of the world wide LHC computing grid (WLCG). It tests the computing resources and the various components of distributed systems with workloads that can range from very simple functional tests to full-chain experiment workflows. This contribution concentrates on the ATLAS implementation, which makes extensive use of HC for monitoring global resources, and additionally, has implemented a mechanism to automatically exclude resources if certain critical tests fail. The auto-exclusion mechanism makes it possible to save resources by avoiding sending computationally intensive jobs to non-functioning clusters.
However, in some cases central errors of the distributed computing system lead to massive exclusions of otherwise well-functioning resources. A new feature improves the recovery after such mass-exclusion events. For the auto-exclusion mechanism to be effective and save resources, test jobs need to be sent at a sufficient frequency. This in turn also uses resources. In this contribution, we give an estimate of the total balance of resources of the auto-exclusion system and explore possible optimisations.
Individual services and scripts have been reorganised as part of a general overhaul including containerisation and the web interface has been given a facelift after more than 10 years of operation. This contribution summarises the work needed to get HC ready for the next decade.
In April 2023 HEPScore23, the new benchmark based on HEP specific applications, was adopted by WLCG, replacing HEP-SPEC06. As part of the transition to the new benchmark, the CPU core power published by the sites needed to be compared with the effective power observed while running ATLAS workloads. One aim was to verify the conversion rate between the scores of the old and the new benchmark. The other objective was to understand how the HEPScore performs when run on multi-core job slots, so exactly like the computing sites are being used in the production environment. Our study leverages the HammerCloud infrastructure and the PanDA Workload Management System to collect a large benchmark statistic across 136 computing sites using an enhanced HEP Benchmark Suite. It allows us to collect not only performance metrics, but, thanks to plugins, it also collects information such as machine load, memory usage and other user-defined metrics during the execution and stores it in an OpenSearch database. These extensive tests allow for an in-depth analysis of the actual, versus declared computing capabilities of these sites. The results provide valuable insights into the real-world performance of computing resources pledged to ATLAS, identifying areas for improvement while spotlighting sites that underperform or exceed expectations. Moreover, this helps to ensure efficient operational practices across sites. The collected metrics allowed us to detect and fix configuration issues and therefore improve the experienced performance.
In early 2024, ATLAS undertook an architectural review to evaluate the functionalities of its current components within the workflow and workload management ecosystem. Pivotal to the review was the assessment of the Production and Distributed Analysis (PanDA) system, which plays a vital role in the overall infrastructure.
The review findings indicated that while the current system shows no apparent signs of scalability limitations or critical defects, several issues still require attention. These include areas for improvement, such as cleaning the historical accumulation of code over nearly two decades of continuous operation in ATLAS, further organizing development activities, maximizing the utilization of continuous integration and testing frameworks, bolstering efforts toward cross-experimental outreach, spreading greater awareness of workflows at the core level, expanding support for complex workflows, implementing a more advanced algorithm for workload distribution, optimizing tape and network resource usage, refining interface design, enhancing transparency to showcase system dynamism, ensuring allocation of key developers to R&D projects with clear long-term visions for integration and operation, and accommodating the growing diversity of resources.
In this presentation, we will first highlight the issues identified in the review, exploring their historical and cultural roots. We will then outline the recommendations derived from the review, and present the solutions developed to address these challenges and pave the way to sustainably support multiple experiments.
Efficient utilization of vast amounts of distributed compute resources is a key element in the success of the scientific programs of the LHC experiments. The CMS Submission Infrastructure is the main computing resource provisioning system for CMS workflows, including data processing, simulation and analysis. Resources geographically distributed across numerous institutions, including Grid, HPC and cloud providers, are joined into a set of federated resource pools, supervised by HTCondor and GlideinWMS services. The CMS Submission Infrastructure team is responsible for acquiring and managing this aggregated computing power, with a total capacity of about 500k CPU cores, and assigning it to CMS workloads according to their requirements and the priorities defined by the collaboration.
The scheduling strategies implemented for this purpose need to be flexible enough to support a number of concurrent workload types, taking into account the availability of resources from diverse providers, as well as the evolving resource requirements of the processing campaigns that the system needs to manage concurrently and consecutively. This complex system needs to be optimized in order to maximize the resource utilization efficiency, thus harnessing the full potential of our distributed compute resources.
This contribution will describe the systematic investigation by the CMS Submission Infrastructure team aimed at identifying, classifying, and minimizing inefficiencies in the use of the CMS distributed resources resulting from our workload management and scheduling algorithms. Additionally, our presentation will include certain strategies devised and implemented to compensate for other sources of inefficiency, thereby optimizing resource utilization and enhancing the overall CMS computational throughput.
Simulation and analysis tools
Model fitting using likelihoods is a crucial part of many analyses in HEP.
zfit started over five years ago with the goal of providing this capability within the Python analysis ecosystem by offering a variety of advanced features and high performance tailored to the needs of HEP.
After numerous iterations with users and a continuous development, zfit reached a maturity stage with a stable core and feature set.
In this talk, we will highlight the latest developments. We will discuss its comprehensive feature set, which includes binned and unbinned fits, advanced model building and the ability to create custom models and a variety of available minimizers. Additionally, the talk will cover current and future backend strategies, leveraging TensorFlow and JAX, to deliver state-of-the-art performance on both CPUs and GPUs through extensive optimizations. Furthermore, we will explore the seamless integration of zfit into the broader Python HEP ecosystem, primarily with Scikit-HEP libraries, and its capability to serialize likelihoods in a human-readable format.
NIFTy[1], a probabilistic programming framework developed for astrophysics,
has recently been adapted to be used in partial wave analyses (PWA) at the
COMPASS [2] experiment located in CERN. A non-parametric model, described
as a correlated field, is used to characterize kinematically-smooth complex-
binned amplitudes. Parametric models, like a Breit-Wigner distribution, can
also be mixed in. This method is being investigated for use in the GlueX ex-
periment located in Jefferson Lab.
I will introduce iftpwa[3], a flexible model-building framework that can
construct and interfere both parametric and non-parametric amplitudes. A
single configuration file is used to build a model and describe the optimiza-
tion procedure resulting in a variationally approximated posterior distribution.
This framework is designed to be modular which provides an avenue for inter-
collaboration use and development.
References
[1] G. Edenhofer, P. Frank, J. Roth, R. H. Leike, M. Guerdi, L. I. Scheel-Platz,
M. Guardiani, V. Eberle, M. Westerkamp, and T. A. Enßlin. Re-Envisioning
Numerical Information Field Theory (NIFTy.re): A Library for Gaussian
Processes and Variational Inference, 2024.
[2] F. M. Kaspar, J. Beckers, and J. Knollm ̈uller. Progress in the Partial-Wave
Analysis Methods at COMPASS. EPJ Web Conf., 291:02014, 2024.
[3] F. M. Kasper and L. Ng. iftpwa, 2024. Github Repository.
With the growing datasets of HE(N)P experiments, statistical analysis becomes more computationally demanding, requiring improvements in existing statistical analysis algorithms and software. One way forward is to use Machine Learning (ML) techniques to approximate the otherwise untractable likelihood ratios. Likelihood fits in HEP are often done with RooFit, a C++ framework for statistical modelling that is part of ROOT. This contribution demonstrates how learned likelihood ratios can be used in RooFit analyses, showcasing new RooFit features that were developed for that purpose. Since ML models are often created with Python libraries, this necessitated new RooFit pythonizations, e.g. for using Python functions as RooFit functions in general. Some of these pythonizations were only possible by a major PyROOT upgrade that was undertaken this year. Therefore, this contribution will also summarize the new PyROOT features, resulting in a presentation that will promote both new RooFit and PyROOT features for the benefit of the users of the most recent ROOT versions.
The Bayesian Analysis Toolkit in Julia (BAT.jl) is an open source software package that provides user-friendly tooling to tackle statistical problems encountered in Bayesian (an not just Bayesian) inference.
BAT.jl succeeds the very successful BAT-C++ (over 500 citations) using modern Julia language. We chose Julia because of its high performance, native automatic differentiation, support for parallel CPU/GPU computing and state-of-the-art package management. BAT.jl is developed in cooperation with the Julia HEP community and is also the basis for the prototype Julia implementation of the HEP Statistics Serialization Standard (HS3), opening a path for direct compatibility with RooFit, HistFactory and pyHF models. EFTFitter is based on BAT.jl as well.
BAT.jl is intended both for quick-and-easy inference but also for use cases that cannot easily be expressed in a domain-specific language (like STAN) or that are computationally costly or require interfacing with existing C/FORTRAN models. A recent application has been inference of parton PDFs from HERA data, combining BAT.jl in Julia with the FORTRAN QCDNUM package.
BAT.jl provides a range of posterior sampling algorithms like Metropolis-MCMC, HMC, MGVI and nested sampling under a common API, as well as methods for evidence estimation, with added tooling for quick plotting, reporting and exporting results.
Recently, we have added more concepts from measure theory, building on BATs capability of using pre-computed normalizing flows to transform problems into spaces optimized for each given algorithm. We also have preliminary support for machine-learned normalizing flows as additional posterior-transform and -approximation tools.
Neural Simulation-Based Inference (NSBI) is a powerful class of machine learning (ML)-based methods for statistical inference that naturally handle high dimensional parameter estimation without the need to bin data into low-dimensional summary histograms. Such methods are promising for a range of measurements at the Large Hadron Collider, where no single observable may be optimal to scan over the entire theoretical phase space under consideration, or where binning data into histograms could result in a loss of sensitivity. This work develops an NSBI framework that, for the first time, allows NSBI to be applied to a full-scale LHC analysis, by successfully incorporating a large number of systematic uncertainties, quantifying the uncertainty coming from finite training statistics, developing a method to construct confidence intervals, and demonstrating a series of intermediate diagnostic checks that can be performed to validate the robustness of the method. As an example, the power and feasibility of the method are demonstrated for an off-shell Higgs boson couplings measurement in the four lepton decay channel, using simulated samples. The proposed method is a generalisation of the standard statistical framework at the LHC, and can benefit a large number of physics analyses. This work serves as a blueprint for measurements at the LHC using NSBI.
JUNO (Jiangmen Underground Neutrino Observatory) is a neutrino experiment being built in South China. Its primary goals are to resolve the order of the neutrino mass eigenstates and to precisely measure the oscillation parameters $\sin^2\theta_{12}$, $\Delta m^2_{21}$, and $\Delta m^2_{31 (32)}$ by observing the oscillation pattern of electron antineutrinos produced in eight reactor cores of two commercial nuclear power plants at a distance of 52.5 km. A crucual stage in the data analysis is to fit the observed spectrum to the expected one under different oscillation scenarios taking into account realistic detector response, backgrounds, and all relevant uncertainties. This task becomes computationally challenging when a full Monte Carlo simulation of the detector is directly used to predict the detector response instead of otherwise used empirical models. It is proposed using a neural network to precisely predict the detector spectrum as a function of oscillation parameters and a set of detector response parameters. This approach drastically reduces computation time and makes it possible to fit a spectrum within one second. The contribution presents the details, performance, and limitations of the method.
Computing Infrastructure
The ATLAS Collaboration operates a large, distributed computing infrastructure: almost 1M cores of computing and almost 1 EB of data are distributed over about 100 computing sites worldwide. These resources contribute significantly to the total carbon footprint of the experiment, and they are expected to grow by a large factor as a part of the experimental upgrades for the HL-LHC at the end of the decade. This contribution describes various efforts to understand, monitor, and reduce the carbon footprint of the distributed computing of the experiment. This includes efforts to construct a full life-cycle assessment (LCA) model for the carbon impact of ATLAS distributed computing, all with the goal of making recommendations for sites to reduce their carbon footprint for the HL-LHC.
As UKRI moves towards a NetZero Digital Research Infrastructure [1] an understanding of how carbon costs of computing infrastructures can be allocated to individual scientific payloads will be required. The IRIS community [2] forms a multi-site heterogenous infrastructure so is a good testing ground to develop carbon allocation models with wide applicability.
The IRISCAST Project [3,4] developed methods to measure carbon costs for a facility. Building on that work the IRIS Carbon Mapping Project [5] has developed models to allocate carbon costs to individual payloads. These models were developed with a learning by doing approach and have been applied to both batch and cloud resources. We present our key findings, lessons learned, and recommendations.
[1] http://doi.org/10.5281/zenodo.8199984
[2] https://iris.ac.uk
[3] http://doi.org/10.5281/zenodo.7692451
[4] http://doi.org/10.1051/epjconf/202429507029
[5] http://doi.org/10.5281/zenodo.10966001
The Glasgow ScotGrid facility is now a truly heterogeneous site, with over 4k ARM cores representing 20% of our compute nodes, which has enabled large-scale testing by the experiments and more detailed investigations of performance in a production environment. We present here a number of updates and new results related to our efforts to optimise power efficiency for High Energy Physics (HEP) research.
We will show updated benchmark results, including a new figure-of-merit designed to characterise the power usage during the execution of the HEPScore benchmark. Previously, community measurements have used either the average or maximum power, neither of which is a good estimator. We expand our HEP-Score/Watt comparison to include additional machines such as Ampere Altra Q80 and M80, NVidia Grace, and the most recent AMD EPYC chips. We also introduce a Frequency Scan methodology to better characterize performance/watt trade-offs, potentially informing strategies like frequency scaling during peak hours to optimize power efficiency.
In addition, we present a comparison of single-socket versus dual-socket performance, revealing consistent findings that dual-socket configurations exhibit performance degradation compared to two single-socket machines, though of varying magnitudes. Leveraging HEPScore jobs and the 'taskset' command to target specific core configurations, we explore performance variations across core groups within the same socket or across dual sockets. Preliminary results show that same-CPU cores have better performance, confirming the importance of workload optimization strategies, such as fine-tuning the job scheduler to prioritize same-socket core utilization.
Our findings contribute to advancing heterogeneous computing strategies and power efficiency optimizations in HEP, paving the way toward more sustainable hardware solutions.
In pursuit of energy-efficient solutions for computing in High Energy Physics (HEP) we have extended our investigations of non-x86 architectures beyond the ARM platforms that we have previously studied. In this work, we have taken a first look at the RISC-V architecture for HEP workloads, leveraging advancements in both hardware and software maturity.
We introduce the Pioneer Milk-V, a 64-core RISC-V machine running Fedora Linux, as our new testbed, available at ScotGrid Glasgow (UK) and INFN Bologna (Italy). Despite this early stage of RISC-V adoption in HEP, significant progress has been made in software compatibility. Standard frameworks such as ROOT, Geant4, CVMFS, and XRootD can be successfully built and run on the RISC-V platform, showcasing the evolving ecosystem. Additionally, efforts are underway to port CMSSW, promising further integration of HEP experiment software.
In this first study, we assess performance and power efficiency, and we leverage various benchmarking tools to compare the RISC-V system with existing ARM and x86 architectures. Although it is not yet possible to run the HEPScore suite, we have conducted ROOT tests and benchmarks, along with DB12 and HS06 benchmarks, demonstrating promising performance-per-watt on the RISC-V platform.
These early results suggest that RISC-V architecture holds potential for advancing energy-efficient computing in HEP, offering decent performance and significantly better power efficiency, while contributing to an increasingly heterogeneous computing landscape.
At INFN-T1 we recently acquired some ARM nodes: initially they were given to LHC experiments to test workflow and submission pipelines. After some time, they were given as standard CPU resources, since the stability both of the nodes and of the code was production quality ready.
In this presentation we will describe all the activities that were necessary to enable users to run on ARM and will give some figures on performance, compared to x86 counterpart. In the end we will try to describe our point of view for the possible massive adoption of this architecture in Tier1 data centers.
The research and education community relies on a robust network to access the vast amounts of data generated by scientific experiments. The underlying infrastructure connects a few hundred sites worldwide, requiring reliable and efficient transfers of increasingly large datasets. These activities demand proactive methods in network management, where potentially severe issues could be predicted and circumvented before they can impact data exchanges. Our ongoing research focuses on leveraging deep learning (DL) methodologies, particularly Transformer-based model, to analyze network paths, and explore interconnectivity across networks with the goal to predict key performance metrics.
A key challenge in network topology modeling is handling missing or uncertain path segments. To address this, we incorporate confidence-aware learning in our Transformer model. This approach enables a more effective representation of network paths, leading to improved model performance.
In this work, we present our experimental findings, discuss the challenges associated with incomplete network paths, and compare the performance of our model against baseline models. Our results demonstrate the potential of Transformer-based models in refining network analysis and pave the way to more robust topology-based anomaly detection methods.
Analysis facilities and interactive computing
Experiment analysis frameworks, physics data formats and expectations of scientists at the LHC have been evolving towards interactive analysis with short turnaround times. Several sites in the community have reacted by setting up dedicated Analysis Facilities, providing tools and interfaces to computing and storage resources suitable for interactive analysis. It is expected that this demand will increase towards the HL-LHC era and will be only met by scaling out to allow interactive processing of large datasets.
CERN IT launched a Pilot of an Analysis Facility based on established, proven services such as SWAN, HTCondor and EOS. This facilitates the access to massive resources by enabling the use of HTCondor managed resources from SWAN, offering parallel execution via frameworks such as ROOT RDataFrame and Coffea and their Dask backends.
In this contribution we will discuss the architecture of the Pilot Analysis Facility at CERN, giving the rationale for the decisions. For deciding on the next steps the evaluation of the impact of different resource allocation strategies at the CERN HTCondor pool is critical. One especially interesting strategy consists in combining a set of dedicated resources for interactive analysis with the use of the general resources that are subject to experiment quotas. We will put a special focus on the feedback we received from the early testers from the experiments.
The National Analysis Facility at DESY has been in production for nearly 15 years. Over various stages of development, experiences gained in continuous operations have continuously been feed and integrated back into the evolving NAF. As a "living" infrastructure, one fundamental constituent of the NAF is the close contact between NAF users, NAF admins and storage admins & developers. Since the NAF is used by a wide field of physics groups and users with different levels of expertise, the social component has shown to be more crucial for the operations and success of the NAF as large scale tool for science compared to plain technology.
While the NAF's focus has been on HEP communities and their workflows, the NAF itself is part of the more comprehensive Interdisciplinary Data and Analysis Facility (IDAF) at DESY. ((As an example beyond HEP for emerging user communities from light particle or photon physics,)) the ALPS II experiment has chosen the NAF as their reconstruction and analysis infrastructure. The Any Light Particle Search II (ALPS II) experiment itself is a light-shining-through-a-wall (LSW) experiment based at DESY in Hamburg, Germany, that will search for axions and axion-like particles down to the coupling of the axion to two photons for masses below 0.1meV. With an eager but limited team, ALPS is focused on the physics exploitation with little overhead available for generic computing tasks.
While the computational needs of the ALPS experiment are on a smaller scale than, e.g., the LHC experiments, unspecific data processing tasks like managing computing, storage and data management for online data taking, long term storage, and analyses still need to be handled. Utilizing the experiences from experiment data handling and processing, ALPS II and DESY IT collaborate to offload generic tasks from the scientists and establish a blueprint for other experiments as well. Eyeing for their scientists needs, the ALPS team and DESY IT have been collaborating in establishing modern tools and approaches like concentrating on CI/CD pipelines and flexible storage access methods.
On the administrative side, with a broadening user community an increased focus on security has become paramount. Since an Analysis Facility presents a large attack surface due to the large number of users with varying experiences and backgrounds, hardening an AF has to be one of the core design and operations aims. In addition to the user support view, we will present as well hardening measures taken over the past two years and our future plans for keeping the NAF secure.
The anticipated surge in data volumes generated by the LHC in the coming years, especially during the High-Luminosity LHC phase, will reshape how physicists conduct their analysis. This necessitates a shift in programming paradigms and techniques for the final stages of analysis. As a result, there's a growing recognition within the community of the need for new computing infrastructures tailored to these evolving demands. To meet this need, the recently established Analysis Facility at the CIEMAT institute is already providing crucial support to the local analysis community. This contribution will describe the diverse resources and functionalities provided by the new facility, its expansion to complementary resources also available at CIEMAT, as well as the important feedback gained from the operational experience by the users.
We explore the adoption of cloud-native tools and principles to forge flexible and scalable infrastructures, aimed at supporting analysis frameworks being developed for the ATLAS experiment in the High Luminosity Large Hadron Collider (HL-LHC) era. The project culminated in the creation of a federated platform, integrating Kubernetes clusters from various providers such as Tier-2 centers, Tier-3 centers, and from the IRIS-HEP Scalable Systems Laboratory, a National Science Foundation project. A unified interface was provided to streamline the management and scaling of containerized applications. Enhanced system scalability was achieved through integration with analysis facilities, enabling spillover of Jupyter/Binder notebooks and Dask workers to Tier-2 resources. We investigated flexible deployment options for a "stretched" (over the wide area network) cluster pattern, including a centralized "lights out management" model, remote administration of Kubernetes services, and a fully autonomous site-managed cluster approach, to accommodate varied operational and security requirements. The platform demonstrated its efficacy in multi-cluster demonstrators for low-latency analyses and advanced workflows with tools such as Coffea, ServiceX, Uproot and Dask, and RDataFrame, illustrating its ability to support various processing frameworks. The project also resulted in a robust user training infrastructure for ATLAS software and computing on-boarding events.
This work is going to show the Spanish Tier-1 and Tier-2s contribution to the computing of the ATLAS experiment at the LHC during the Run3 period. The Tier-1 and Tier-2 GRID infrastructures, encompassing data storage, processing, and involvement in software development and computing tasks for the experiment, will undergo updates to enhance efficiency and visibility within the experiment.
The fundamental objective of this work is, on one hand, to provide data processing services in a stable manner for 24 hours a day every day of the year with a reliability greater than 95% in the conditions that the experiment needs and, on the other hand, to undertake the resolution of the problems posed by Run3 in which we are fully involved. The potential time interval of validity of this contribution covers a large part of Run3 and the beginning of the Long Shutdown 3 (LS3), namely the period 2022-2026. Central to our efforts is to engage actively with the various challenges inherent in research and development, in preparation for the upcoming, more intricate phase represented by the High-Luminosity LHC (HL-LHC).
We generate billions of simulated events annually for different physics processes. We capitalize on National High Performance Computers like the MareNostrum, part of the Supercomputing Spanish Network. We employ Data Lakes, a versatile paradigm for storing vast amounts of data crucial for the experiment's physics analyses. We belong to the core of GRID centers sufficiently reliable to house critical data and provide a first level of support to local ATLAS physicists.
A new activity in this work is the development and implementation of what we call the “Facility for Interactive Distributed Analysis”. This initiative aims to facilitate data analysis work for physicists at Spanish centers (IFIC, UAM, and IFAE) by orchestrating the distributed nature of initial analysis phases with subsequent interactive phases involving reduced data files. The ultimate goal is to produce publishable physics results or contributions tailored for workshops and conferences.
The ATLAS Tier-1 and Tier-2 sites in Spain have contributed and will continue to contribute significantly to research and development in computing. These efforts include the evaluation of various models aimed at enhancing computing performance and data storage capacity to meet the demands of the LHC High Luminosity era.
The analysis of data collected by the ATLAS and CMS experiments at CERN, ahead of the next phase of high-luminosity at the LHC, requires a flexible and dynamic access to big amounts of data, as well as an environment capable of dynamically accessing distributed resources. An interactive high throughput platform, based on a parallel and geographically distributed back-end, has been developed in the framework of the “HPC, Big Data e Quantum Computing Research Centre” Italian National Center (ICSC), providing experiment-agnostic resources. Starting from container technology and orchestrated via Kubernetes, the platform provides analysis tools via Jupyter interface and Dask scheduling system, masking complexity for frontend users and rendering cloud resources flexibly.
An overview of the technologies involved and the results on benchmark use cases will be provided, with suitable metrics to evaluate preliminary performance of the workflow. The comparison between the legacy analysis workflows and the interactive and distributed approach will be provided based on several metrics from event throughput to resource consumption. The use cases include the search for direct pair production of supersymmetric particles and for dark matter in events with two opposite-charge leptons, jets and missing transverse momentum using data collected by the ATLAS detector in Run-2 (JHEP 04 (2021) 165), and searches for rare flavor decays at the CMS experiment in Run-3 using large datasets collected by high-rate dimuon triggers.
The Jiangmen Underground Neutrino Observatory (JUNO) in southern China has set its primary goals as determining the neutrino mass ordering and precisely measuring oscillation parameters. JUNO plans to start data-taking in late 2024, with an expected event rate of approximately 1 kHz at full operation. This translates to around 60 MB of byte-stream raw data being produced every second, resulting in a 2 PB data per year. To address the challenges posed by this massive amount of data, JUNO is conducting data challenges on its distributed computing infrastructure. The data challenges aim to achieve several objectives, including understanding the offline requirements, accurately estimating the necessary resources, identifying potential bottlenecks within the involved systems, and improving overall performance. The ultimate goal is to demonstrate the effectiveness of the JUNO computing model and ensure the smooth operation of the entire data processing chain, encompassing raw data transfer, simulation, reconstruction, and analysis. Furthermore, the data challenges seek to verify the availability and effectiveness of monitoring systems for each activity.
High-Luminosity LHC will provide an unprecedented amount of experimental data. The improvement in experimental precision needs to be matched with an increase of accuracy in the theoretical predictions, stressing our compute capability.
In this talk, I will focus on the current and future precision needed by LHC experiments and how those needs are supplied by Event Generators. I will focus on how computationally intensive these computations are. And finally, describe the various software development efforts underway (or in progress) to tackle such challenges, both in the direction of AI development and better usage of GPUs.
In this contribution, we’ll review the status of the ROOT project towards the end of LHC Run 3.
We'll review its structure, available effort and management strategy, allowing to push innovation while guaranteeing long term support.
In particular, we'll describe how ROOT became a veritable community effort attracting contributions not only from the ROOT team, but from collaborators at labs, universities and the private sector thanks to its open source philosophy.
We'll review the main features of the 2025 data taking release 6.32 as well as the forthcoming development release.
We'll also discuss the evolution of ROOT towards the HL-LHC era, in its 7th release cycle.
Historically, DESY has been a HEP site with its on-site accelerators DESY, PETRA, DORIS, and HERA. Since the end of the HERA data taking, a strategic shift has taken place at DESY towards supporting Research with Photons with user facilities at the Hamburg site in addition to the continuing support for Particle Physics. Since then some of the existing HEP accelerators have been redesigned to serve as synchrotron and free electron laser research facilities for Photon Science.
The shift in user communities also required considerable changes to the way computing is provided. DESY not only manages the data taking, storing and archival but also fulfils the role of the user analysis facility as well as providing all necessary auxiliary community tools.
Instead of a few large collaborations with core computing experts, each data taking beam-time is managed by a small group of (often less than ten) scientists. These range from material sciences, over chemistry to biology. As the each group is only present on site for their data taking, each following group starts from scratch with expertise and experience not being persistent as in larger HEP experiments. Similar to the HEP experiments, the data are only accessible to the individual beam-time scientists, but on a much larger scale compared to HEP experiments as DESY has to support all beam-times and assure that the access rights are handled sufficiently. After an embargo period the data are to be made public.
In our talk we introduce our current commitments for our HEP communities and the setup for Photon Science from detector to archival and how existing tools and workflows from DESY's HEP past have been utilised and where new solutions had to be found. Looking into the future, we present our vision for a consolidated computing approach for all our communities from the LHC experiments, to local on-site Particle Physics experiments and Photon Science.
We present first results from a new simulation of the WLCG Glasgow Tier-2 site, designed to investigate the potential for reducing our carbon footprint by reducing the CPU clock frequency across the site in response to a higher-than-normal fossil-fuel component in the local power supply. The simulation uses real (but historical) data for the UK power-mix, together with measurements of power consumption made at Glasgow on a variety of machines, and is designed to provide a tool to inform future procurements and the operation of sites. The output of the simulation, combined with considerations of embedded carbon, can also be used to inform and optimise the policy for replacing older hardware with more energy efficient devices. The rate of transition to more energy efficient hardware must be balanced against the embedded carbon in the manufacture of new machines, and frequency modulation must be balanced against both the loss of site throughput and the accounting of embedded carbon. Frequency modulation can also be used to reduce power requirements to address short-term supply issues, irrespective of the carbon content.
Decades of advancements in computing hardware technologies have enabled HEP experiments to achieve their scientific objectives, facilitated by meticulous planning and collaboration among all stakeholders. However, the path to HL-LHC demands a continuously improving alignment between our ever increasing needs and the available computing and storage resources, not matched by any increase in financial resources. Consequently, it is crucial to closely monitor hardware technology trends and understand how these advancements can best meet our requirements, particularly when making infrastructure investments. In this contribution, we will provide an overview of the current state-of-the-art technologies and their anticipated evolution in the short to medium term, focusing on their relevance to the data centers supporting HEP.
Additionally, we will discuss how our community contributes to technology tracking and how computing sites and experimental collaborations can profit from it.
Data and Metadata Organization, Management and Access
The surge in data volumes from large scientific collaborations, like the Large Hadron Collider (LHC), poses challenges and opportunities for High Energy Physics (HEP). With annual data projected to grow thirty-fold by 2028, efficient data management is paramount. The HEP community heavily relies on wide-area networks for global data distribution, often resulting in redundant long-distance transfers. This work studies how regional data caches [1] mitigate network congestion and enhance application performance, using millions of access records from regional caches in Southern California, Chicago, and Boston, serving the LHC’s CMS experiment [2]. Our analysis demonstrates the potential of in-network caching to revolutionize large-scale scientific data dissemination.
We analyzed the cache utilization trends, see examples in Figure 1, and identified distinct patterns from the three deployments. Our exploration further employed machine learning models for predicting data access patterns within regional data caches. These findings offer insights crucial for resource usage estimation, including storage cache and network requirements, and can inform improvements in application workflow performance within regional data cache systems. Figure 2 shows the sample prediction result of the hourly cache utilization for SoCal Cache. While the predictions capture volume spikes, they may not precisely match the heights.
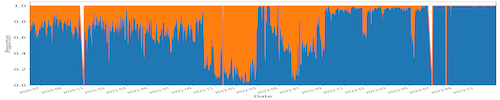
Fig. 1(a). SoCal Cache (capacity 2PB) from June 2020 to Dec. 2023, with 29.48 million data access requests where 23.8PB were read from this cache (i.e., cache hits) and 11.8PB from remote locations (i.e., cache misses). On average, 66.9% of requested data was served from this cache.
Fig. 1(b). Chicago Cache (capacity 340TB) from Oct. 2022 to Dec. 2023, with 5.7 million data access requests where 11.0PB were read from this cache (i.e., hits) and 13.2PB from remote locations (i.e., misses). On average, 45.5% of the requested data was served from this cache.
Fig. 1(c). Boston Cache (capacity 170TB) from Aug. 2023 to Dec. 2023, with 27.7 million data access requests where 5.0PB were read from this cache (i.e., hits) and 76.0PB from remote locations (i.e., misses). On average, 6.1% of the requested data was served from this cache.
Fig. 1. Fraction (by data volume) of cache hits (blue) and cache misses (orange) every day for three different in-network cache installations

Fig. 2. Hourly cache hit volume from SoCal Cache, showing actual measurements (blue bars), training predictions (orange bars), and testing predictions (red bars).
In this study, we present a detailed analysis of cache utilization trends across the SoCal, Chicago, and Boston regional caches serving the LHC CMS experiment. Our investigation reveals distinct patterns in cache usage unique to each region, highlighting the need for tailored approaches in cache design. Our exploration of neural network models were demonstrated to provide accurate predictions of cache usage trends, these models could be used anticipate future needs for storage and network resources. By understanding and leveraging these insights, we could significantly enhance the efficiency of resource allocation and optimize application workflow performance.
REFERENCES
[1] E. Fajardo, D. Weitzel, M. Rynge, M. Zvada, J. Hicks, M. Selmeci, B. Lin, P. Paschos, B. Bockelman, A. Hanushevsky, F. W¨urthwein, and I. Sfiligoi, "Creating a content delivery network for general science on the internet backbone using XCaches," EPJ Web of Conferences, vol. 245, p. 04041, 2020. [Online]. Available: https://doi.org/10.1051/epjconf/202024504041
[2] C. Sim, K. Wu, A. Sim, I. Monga, C. Guok, D. Hazen, F. Wurthwein, D. Davila, H. Newman, and J. Balcas, "Predicting resource utilization trends with southern california petabyte scale cache," in 26th International Conference on Computing in High Energy & Nuclear Physics (CHEP2023), 2023.
The Large Hadron Collider (LHC) at CERN in Geneva is preparing for a major upgrade that will improve both its accelerator and particle detectors. This strategic move comes in anticipation of a tenfold increase in proton-proton collisions, expected to kick off by 2029 in the upcoming high-luminosity phase. The backbone of this evolution is the World-Wide LHC Computing Grid, crucial for handling the flood of data from these collisions. Therefore, expanding and adapting it is vital to meet the demands of the new phase, all while working within a tight budget. Many research and development projects are in progress to keep future resources manageable and cost-effective in managing the growing data. One area of focus is Content Delivery Network (CDN) techniques, which promise data access and resource use optimization, improving task performance by caching input data close to users. A comprehensive study has been conducted to assess how beneficial it would be to implement data caching for the Compact Muon Solenoid (CMS) experiment. This study, with a focus on Spanish computing facilities, shows that user analysis tasks are the ones that can benefit the most from CDN techniques. As a result, a data cache has been introduced in the region to understand these benefits better. In this contribution, we analyze remote data access from users in Spanish CMS sites to figure out the best size and network connectivity requirements for a data cache serving the whole Spanish region. Exploration of machine learning techniques, along with comparisons to traditional LRU mechanisms, allow for the identification and preservation of frequently accessed datasets within the cache. This approach aims to optimize storage usage efficiently, while prioritizing accessibility to the most popular data.
Scientific experiments and computations, especially in High Energy Physics, are generating and accumulating data at an unprecedented rate. Effectively managing this vast volume of data while ensuring efficient data analysis poses a significant challenge for data centers, which must integrate various storage technologies. This paper proposes addressing this challenge by designing a multi-tiered storage model that employs diverse storage technologies tailored to different data needs, thereby addressing data classification, placement, and migration.
While users and administrators manually optimize storage by migrating data based on simple rules derived from human knowledge, decisions, and basic usage statistics, evaluating the placement of data in different storage classes with I/O-intensive workloads remains a complex task. To overcome this challenge and address existing limitations, we have developed a precise data popularity prediction model utilizing state-of-the-art AI/ML techniques. This model is crafted from the analysis of ATLAS data and access patterns. It enables us to migrate infrequently accessed data to more economical storage media, such as tape drives, while storing frequently accessed data on faster yet costlier storage media like HDD or SSD. This strategic approach ensures data is placed optimally into the appropriate storage classes, thereby maximizing storage capacity while minimizing data access latency for end-users. Additionally, we provide insights and explore potential implementations of an autonomous multi-tiered storage system on the storage infrastructure at BNL, leveraging dCache technology. Furthermore, we will discuss the outcomes and compare different implementation strategies.
This paper presents a novel approach to enhance the analysis of ATLAS Detector Control System (DCS) data at CERN. Traditional storage in Oracle databases, optimized for WinCC archiver operations, is challenged by the need for extensive analysis across long timeframes and multiple devices, alongside correlating conditions data. We introduce techniques to improve troubleshooting and analysis of ATLAS New Small Wheel (NSW) DAQ links, including data migration to Apache Parquet for efficient storage, and leveraging Big Data technologies like Apache Spark and Apache Hadoop for analysis. Employing Jupyter notebooks on the SWAN service, combined with Spark, Pandas, and the extensive Python ecosystem in general, facilitated a highly efficient analysis workflow. This approach was well-received by NSW experts, allowing them to rapidly gain proficiency and execute advanced analyses within a notably brief period.
Over the past years, the ROOT team has been developing a new I/O format called RNTuple to store data from experiments at CERN's Large Hadron Collider. RNTuple is designed to improve ROOT's existing TTree I/O subsystem by improving I/O speed and introducing a more efficient binary data format. It can be stored in both ROOT files and object stores, and it's optimized for modern storage hardware like NVMe SSDs.
The ATLAS experiment plans to use RNTuple as its primary storage container in the upcoming HL-LHC.
There's been significant progress in integrating RNTuple into the ATLAS event processing framework, and now all production ATLAS data output formats support it. Performance studies with open-source data have shown substantial improvements in space resource usage. The reported study examines the I/O throughput and disk-space savings achieved with RNTuple for various ATLAS data output formats, including RDO, ESD, AOD, and various DAOD. These measurements will have an important impact on the computing resource needs of the ATLAS experiment for HL-LHC operation.
Online and real-time computing
For the HL-LHC upgrade of the ATLAS TDAQ system, a heterogeneous computing farm
deploying GPUs and/or FPGAs is under study, together with the use of modern
machine learning algorithms such as Graph Neural Networks (GNNs). We present a
study on the reconstruction of tracks in the ATLAS Inner Tracker using GNNs on
FPGAs for the Event Filter system. We explore each of the steps in a GNN-based
tracking pipeline: graph construction, edge classification using an interaction
network, and segmentation of the graph into track candidates. We investigate
optimizations of the GNN approach that aim to minimize FPGA resources
utilization and maximize throughput while retaining high track reconstruction
efficiency and low fake rates required for the ATLAS Event Filter tracking
system. These studies include model hyperparameter tuning, model pruning and
quantization-aware training, and sequential processing of sub-graphs across the
detector.
Abstract: The LHCb collaboration is planning an upgrade (LHCb "Upgrade-II") to collect data at an increased instantaneous luminosity (a factor of 7.5 larger than the current one). LHCb relies on a complete real-time reconstruction of all collision events at LHC-Point 8, which will have to cope with both the luminosity increase and the introduction of correspondingly more granular and complex detectors.
After an intensive R&D programme, LHCb proposed to build an FPGA-based system to reconstruct tracks in the SciFi detector during Run 4, as an intermediate step towards a system that could be extended to other tracking detectors. Based on an extremely parallel architecture, the so-called 'artificial retina', this system has an $O(n)$ complexity, which is a crucial feature for high luminosity scenarios.
In this talk we describe why this system scales linearly with luminosity and how much it can accelerate the LHCb High Level Trigger in Run 4.
We present the preparation, deployment, and testing of an autoencoder trained for unbiased detection of new physics signatures in the CMS experiment Global Trigger (GT) test crate FPGAs during LHC Run 3. The GT makes the final decision whether to readout or discard the data from each LHC collision, which occur at a rate of 40 MHz, within a 50 ns latency. The Neural Network makes a prediction for each event within these constraints, which can be used to select anomalous events for further analysis. The GT test crate is a copy of the main GT system, receiving the same input data, but whose output is not used to trigger the readout of CMS, providing a platform for thorough testing of new trigger algorithms on live data, but without interrupting data taking. We describe the methodology to achieve ultra low latency anomaly detection, and present the integration of the DNN into the GT test crate, as well as the monitoring, testing, and validation of the algorithm during proton collisions.
For the upcoming HL-LHC upgrade of the ATLAS experiment, the deployment of GPU
or FPGA co-processors within the online Event Filter system is being studied as
a measure to increase throughput and save power. End-to-end track
reconstruction pipelines are currently being developed using commercially
available FPGA accelerator cards. These utilize FPGA base partitions, drivers
and runtime tools supplied by the manufacturer to reduce design effort.
Algorithms are implemented both in hardware description language (HDL) and
high-level synthesis (HLS), and integrated as kernels into an OpenCL host
software interfacing with the ATLAS main software framework Athena. This
contribution summarizes the algorithmic developments, the integration workflow
and status.
This work presents FPGA-RICH, an FPGA-based online partial particle identification system for the NA62 experiment utilizing AI techniques. Integrated between the readout of the Ring Imaging Cherenkov detector (RICH) and the low-level trigger processor (L0TP+) , FPGA-RICH implements a fast pipeline to process in real-time the RICH raw hit data stream, producing trigger-primitives containing elaborate physics information, such as the number of charged particles in a physics event, that the L0TP+ can use to improve trigger decision efficiency.
The system is deployed on a single FPGA device and uses both classical online processing methods and a compact Neural Network algorithm to achieve efficient event classification while managing NA62’s challenging throughput requirements (≈ 10 MHz). The streaming pipeline guarantees low latency (~ 1 μs), comparable to the other NA62 sub-detectors that send trigger-primitives to the L0TP+, allowing seamless integration in the existing TDAQ setup as a new detector running in parallel with the RICH.
The system development leverages High Level Synthesis (HLS) programming language and the open-source hls4ml software-hardware codesign workflow for fast, flexible and relatively simple reprogramming, debugging and feature enhancements.
Currently integrated in parasitic mode in the experiment TDAQ, we will present and discuss our experience with the system’s design and deployment along with the results obtained during the 2024 data taking.
The work highlights the strength and maturity of modern computing solutions, programming paradigms and machine learning algorithms even within the challenging context of modern HEP experiments’ online data acquisition and analysis.
Particle detectors at accelerators generate large amount of data, requiring analysis to derive insights. Collisions lead to signal pile up, where multiple particles produce signals in the same detector sensors, complicating individual signal identification. This contribution describes the implementation of a deep learning algorithm on a Versal ACAP device for improved processing via parallelization and concurrency. Connected to a host computer via PCIe, this system aims for enhanced speed and energy efficiency over CPUs and GPUs. In the contribution, we will describe in detail the data processing and the hardware, firmware and software components of the signal reconstruction of the Tile Calorimeter (TileCal) of the ATLAS detector which will be running in real time in the HL-LHC era. The contribution presents the implementation of the deep learning algorithm on Versal ACAP device, as well as the system for transferring data in an efficient way. In addition, the system integration tests and results from the tests with beam performed at CERN will be presented.
Offline Computing
Efficient and precise track reconstruction is critical for the results of the Compact Muon Solenoid (CMS) experiment. The current CMS track reconstruction algorithm is a multi-step procedure based on the combinatorial Kalman filter as well as a Cellular Automaton technique to create track seeds. Multiple parameters regulate the reconstruction steps, populating a large phase space of possible solutions. The fine-tuning of these parameters is necessary to ensure an optimal reconstruction. The CMS tracker featured robust performance and efficient tracking in Run 3 condition, however, the High Lumi environment is expected to be much more demanding. The upgrade will lead to higher rates and pile-up that require further improvement in all the reconstruction processes, with more complex algorithms featuring additional parameters. Alternative techniques to help the experts in properly tuning these environments are thus being investigated.
This report presents an original tool based on the established Particle Swarm heuristic optimization algorithm (PSO) to perform parameter tuning of the pixel track reconstruction software currently employed in the CMS experiment. The software enables multi-objective optimization against tracking efficiency and fake rate, resulting in the individuation of a Pareto front of valid parameters’ sets for reconstruction.
The algorithm has been tested at the end of the data-taking period of 2023 on the pixel track reconstruction algorithm with excellent results. The parameters obtained with the optimization resulted in comparable reconstruction efficiency for both phase 1 data and phase 2 simulations, with a 50\% improvement in fake rates, especially for low transverse momentum of the particles.
Further research and development can explore the application of this tool to other aspects of the CMS reconstruction process. Additionally, investigating the integration of this tool within the existing CMS framework can streamline the optimization workflow for future data-taking periods.
Track reconstruction, a.k.a., tracking, is a crucial part of High Energy Physics experiments. Traditional methods for the task, relying on Kalman Filters, scale poorly with detector occupancy. In the context of the upcoming High Luminosity-LHC, solutions based on Machine Learning (ML) and deep learning are very appealing. We investigate the feasibility of training multiple ML architectures to infer track-defining parameters from detector signals, for the application of offline reconstruction. We study and compare three Transformer model designs, as well as a U-Net model design. Firstly, we consider an autoregressive Transformer with the original encoder-decoder architecture, reconstructing a particle's trajectory given a few initial hits. Secondly, we employ an encoder-only model with the purpose of regressing track parameter values for each hit in an event, followed by a clustering step. Next, an encoder-only model design as a classifier is considered, producing class labels for each hit in an event, given pre-defined bins within the track parameter-space. Lastly, similar to the third Transformer design, a U-Net model for pixel classification into pre-defined classes is evaluated.
The models are benchmarked for physics performance and inference speed on methodically simplified datasets, generated by the recently developed simulation framework, REDuced VIrtual Detector (REDVID). Our second batch of simplified datasets are derived from the TrackML dataset. Our preliminary results show promise for the application of such deep learning techniques on more realistic data for tracking, as well as efficient elimination of solutions.
In view of the High-Luminosity LHC era the ATLAS experiment is carrying out an upgrade campaign which foresees the installation of a new all-silicon Inner Tracker (ITk) and the modernization of the reconstruction software.
Track reconstruction will be pushed to its limits by the increased number of proton-proton collisions per bunch-crossing and the granularity of the ITk detector. In order to remain within CPU budgets while retaining high physics performance, the ATLAS Collaboration plans to use ACTS, an experiment-independent toolkit for track reconstruction. The migration to ACTS involves the redesign of the track reconstruction components as well as the ATLAS Event Data Model (EDM), resulting in a thread-safe and maintainable software.
In this contribution, the current status of the ACTS integration for the ATLAS ITk track reconstruction is presented, with emphasis on the improvements of the track reconstruction software and the implementation of the ATLAS EDM.
The Super Tau-Charm Facility (STCF) proposed in China is an electron-positron collider designed to operate in a center-of-mass energy range from 2 to 7 GeV with peak luminosity above $0.5 × 10^{35}$cm$^{-2}s^{-1}$. The STCF will provide a unique platform for studies of hadron physics, strong interactions and searches for new physics beyond the Standard Model in the tau-charm region. To fulfill the physics goals of the STCF experiment, good performance of reconstruction of charged tracks with momentum down to 50 MeV is required. The tracking system of the STCF detector consists of an inner tracker (ITK) with several independent layers and a large cylindrical drift chamber (main drift chamber, MDC). A track reconstruction software framework has been developed for the baseline STCF detector design. A global track finding algorithm based on Hough Transform, which handles the hits from the ITK and MDC together, hence less sensitive to missing local hits, has been implemented and optimized in this framework. The tracking toolkit of A Common Tracking Software (ACTS) is also explored for tracking in the STCF detector, where the Combinatorial Kalman Filter (CKF) implemented in ACTS is used to find the tracks based on the track seeds composed of ITK hits. In addition, innovative machine learning techniques have been explored to use in track reconstruction in the STCF tracking detectors. Different tracking methods and techniques have been compared to achieve good overall track reconstruction performance for the STCF experiment. In this contribution, we present the tracking system of the STCF detector and development and implementation of afore-mentioned various tracking algorithms in the STCF offline software and the simulated tracking performance.
The upgrade of the CMS apparatus for the HL-LHC will provide unprecedented timing measurement capabilities, in particular for charged particles through the Mip Timing Detector (MTD). One of the main goals of this upgrade is to compensate the deterioration of primary vertex reconstruction induced by the increased pileup of proton-proton collisions by separating clusters of tracks not only in space but also in time.
This contribution discusses the ongoing algorithmic developments to optimally exploit such new information, going beyond the initial studies at the time of the detector proposal, both from the physics and computational performance point of view. Different possible approaches are evaluated, comparing improvements of traditional methods and innovative techniques.
Mu2e will search for the neutrinoless coherent $\mu^-\rightarrow e^-$ conversion in the field of an Al nucleus, a Charged Lepton Flavor Violation (CLFV) process. The experiment is expected to start in 2026 and will improve the current limit by 4 orders of magnitude.
Mu2e consists of a straw-tube tracker and crystal calorimeter in a 1T B field complemented by a plastic scintillation counter veto to suppress cosmic ray backgrounds. The tracker geometry, composed of 36 tracking planes equally spaced with straws transverse to the beamline, makes track reconstruction a quite unique problem.
The first step of track reconstruction is hit clustering, in space and time. Pattern recognition is performed for each time cluster to identity hit combinations compatible with a 3D helix and remove background hits. Track fitting acts on the hit combinations to determine precision track parameters. The existing algorithms are robust and efficient for the topologies of interest for the principal physics analyses. However, we developed pattern recognition algorithms to improve track reconstruction of multi-particle events which are important for background estimates through data-driven procedures.
Distributed Computing
The Square Kilometre Array (SKA) is set to be the largest and most sensitive radio telescope in the world. As construction advances, the managing and processing of data on an exabyte scale becomes a paramount challenge to enable the SKA science community to process and analyse their data. To address this, the SKA Regional Centre Network (SRCNet) has been established to provide the necessary computational and storage resources, and to facilitate access to SKA data for the global scientific community, providing a science archive for public data engagement.
SRCNet v0.1 marks the prototype deployment phase of this architecture, scheduled for early 2025, and is a critical step in the roadmap towards achieving full operational capability of SRCNet. This report outlines the specific requirements for SRCNet v0.1, including major architectural components and a review of the Distributed Data Management (DDM) software selection process, which includes tooling originally developed for the HEP Community, namely: Rucio, FTS, and perfSONAR and Storage Endpoint technologies. The primary goals of SRCNet v0.1 are presented, including topics of authentication and authorisation and interactive data access, and the planned data challenge campaigns.
The Cherenkov Telescope Array Observatory (CTAO) is the next-generation instrument in the very-high energy gamma ray astronomy domain. It will consist of tens of Cherenkov telescopes deployed in 2 CTAO array sites at La Palma (Spain) and Paranal (ESO, Chile) respectively. Currently under construction, CTAO will start operations in the coming years for a duration of about 30 years. During operations CTAO is expected to produce about 2 PB of raw data per year plus 5-20 PB of Monte Carlo data as well as very high processing needs of the order of hundreds of millions of CPU HS06 hours per year. These computing resources will be distributed across the 4 official CTAO Data Centers. To handle these simulations and data processing, we have developed a production system prototype based on the DIRAC interware. We will present the current status of this prototype, the underlying infrastructure and the used technologies, as well as recent developments regarding workflows interface and failure management, along with future perspectives.
The Einstein Telescope is the proposed European next-generation ground-based gravitational-wave observatory, that is planned to have a vastly increased sensitivity with respect to current observatories, particularly in the lower frequencies. This will result in the detection of far more transient events, which will stay in-band for much longer, such that there will nearly always be at least one transient signal within the detector sensitivity. Besides the technological challenges that an underground, cryogenic instrument poses, many current data analyses cannot be trivially scaled without the required computing power growing beyond reasonably available resources. Furthermore, the detection and characterisation of events needs to be carried out with the minimum possible latency to guarantee the timely distribution of public alerts for multimessenger science follow-up. The Einstein Telescope Collaboration is carrying out a series of Mock Data Challenges with the aim, besides developing scientific algorithms and techniques, to test and evaluate the technological components that will form the ET distributed computing infrastructure. The strategy is to iteratively evolve the tools available to manage data and workloads and get early feedback from the scientific user community, possibly on different, competing implementations offering the same functionalities. We will discuss the preliminary outcomes of the first Mock Data Challenge and plans for subsequent ones, and on the status of the preparation of the Einstein Telescope Computing Model in general.
The DUNE experiment will start running in 2029 and record 30 PB/year of raw waveforms from Liquid Argon TPCs and photon detectors. The size of individual readouts can range from 100 MB to a typical 8 GB full readout of the detector to extended readouts of up to several 100 TB from supernova candidates. These data then need to be cataloged, stored and then distributed for processing worldwide. This large massive amount of data and heterogeneous computing environment necessitates powerful and robust distributed computing infrastructure. In the process of building up that infrastructure, DUNE’s production system has recently undergone an overhaul, in which it has integrated 1) a new workflow management system (justIN) 2) a new data catalog (MetaCat) and 3) a state-of- the-art data management system (Rucio). Simulations of DUNE’s Far Detector and its prototypes ProtoDUNE-HD (PDHD) and ProtoDUNE-VD, as well as data from PDHD serve as the first tests of this infrastructure.
After several years of focused work, preparation for Data Release Production (DRP) of the Vera C. Rubin Observatory’s Legacy Survey of Space and Time (LSST) at multiple data facilities is taking its shape. Rubin Observatory DRP features both complex, long workflows with many short jobs, and fewer long jobs with sometimes unpredictably large memory usage. Both of them create scaling issues that need to be addressed in order to meet the annual processing timeline.
This paper summarizes the infrastructure and services deployed at Rubin data facilities to support multi-site data processing. Rubin selected PanDA (Production and Distributed Analysis) to orchestrate its complex workflow and to manage its distributed workload. We address the interface between workflow/workload management system and Rubin’s campaign management system, as well as the associated analytics platform, and the interface to the observatory’s data management system.
Rubin has already exercised this infrastructure to process data from other observatories as well as simulated data. The experience of those processing campaigns is summarized in this paper. Finally, this paper outlines future plans, including providing the campaign management team a higher level view on ongoing campaigns and analyzing finished campaigns as well as using PanDA to support end users' need for batch processing from within a “hybrid” cloud approach to data hosting.
The High Energy cosmic-Radiation Detection (HERD) facility is an under construction space astronomy and particle astrophysics experiment in collaboration between China and Italy, and will run on the China Space Station for more than 10 years since 2027. HERD is designed to search for dark matter with unprecedented sensitivity, investigate the century-old mystery of the origin of cosmic rays, conduct high-sensitivity surveys and monitoring of high-energy gamma rays, and explore new methods of pulsar navigation.
Once operational, HERD experiment is expected to generate and distribute more than 90 PB of data over a span of 10 years. To share the data and computing resource for data processing and analysis, a distributed computing system based on grid computing technology is developed with the supports of computing and storage sites in China and Italy.
HERD distributed computing infrastructure (DCI) integrates a distributed computing system managing data processing jobs based on DIRAC and dHTC, a distributed data management system distributing raw and produced data based on Rucio, and other grid computing middleware including IAM, FTS3, etc. Furthermore, HERD DCI is designed to deeply involved with HERD Offline Software (HERDOS) and data production workflow, providing grid computing services without normal and production users being aware of it.
Simulation and analysis tools
For high-energy physics experiments, the generation of Monte Carlo events, and in particular the simulation of the detector response, is a very computationally intensive process. In many cases, the primary bottleneck in detector simulation is the detailed simulation of the electromagnetic and hadronic showers in the calorimeter system. For the ATLAS experiment, about 80% of the total CPU usage for detector simulation is devoted to the simulation of the secondary particles produced in the calorimeter system.
To make best use of the available resources, ATLAS is currently using its state-of-the-art fast simulation tool AtlFast3, which uses classical parametric and ML-based solutions for shower generation. AtlFast3 is deployed in a heterogeneous simulation infrastructure known as the Integrated Simulation Framework (ISF), which was originally developed over a decade ago, and is becoming increasingly difficult to maintain by the collaboration. In an effort to greatly simplify its simulation infrastructure for Run 4 and beyond, the collaboration is in the process of phasing out ISF and implementing its fast simulation library directly as a Geant4 fast simulation model.
In addition, efforts have started to develop a fully experiment-independent library for fast calorimeter simulation, providing a universal interface for the lateral and longitudinal parameterisation of calorimeter shower development, as well as for ML-based approaches to shower generation.
This talk will give an overview of the current and future (fast) simulation infrastructure in ATLAS. The new experiment-independent library for fast calorimeter simulation will be presented and its use for other experiments will be motivated and discussed.
Gaussino is an experiment-independent simulation package built upon the Gaudi software framework. It provides generic core components and interfaces for a complete HEP simulation application: event generation, detector simulation, geometry, monitoring and output of the simulated data. This makes it suitable for use as a standalone application for early prototyping, testbeam setups etc as well as a toolkit with which to build a dedicated simulation application for a full-scale experiment.
In this talk we give an overview of recent developments in Gaussino.
The generator phase is adapted to seperate the handling of the hard scattering from the parton shower and hadronisation. This allows easier integration of Matrix Elements generators, like MadGraph or Powheg with the general purpose generators like Pythia. A new interface for specifying generic generator-level cuts at configuration time is also introduced.
A new dedicated component for machine-learning based fast simulations that facilitates the integration of fast simulation hooks in Geant4 with machine learning frameworks, all based on Gaudi’s scheduling and data processing tools.
Support for selectively offloading electromagnetic particle transport to GPUs is investigated. The toolbox for customisation, verification, visualisation and debugging of the geometry is extended.
The user configuration is made more robust and flexible.
We will provide examples in the use of the new features in the context of the LHCb Simulation.
Reconfigurable detector for the measurement of spatial radiation dose distribution for applications in the preparation of individual patient treatment plans [1] was a research and development project aimed at improving radiation dose distribution measurement techniques for therapeutic applications. The main idea behind the initiative was to change the current radiation dose distribution measurement methods used in preparing individual plans for radiotherapy. To this end, a prototype of a fully three-dimensional filled with 3D-printed plastic scintillators [2] was designed and built to measure the spatial distribution of radiation dose in real time for treatment planning.
In parallel with the construction of the phantom, software tools for dose simulation and data analysis are being developed. The Monte Carlo simulations developed for the Dose-3D project were a crucial part of its success. These simulations were used to create data reflecting the apparatus used in the test beam on our simulation platform called G4RT. This simulation data was instrumental in optimizing the Dose-3D detector cell and ensuring the proper calibration of the prototype phantom. It was also used in the design and planning of the test beam, taking into account the effects of beam reflection from the therapeutic table and beam absorption at depth in phantom.
From the software architecture point of view our work presents a novel approach leveraging the Geant4 toolkit. Unlike existing software solutions that are predominantly designed for standard geometries or applications, our proposed toolkit offers unparalleled flexibility, enabling researchers and practitioners to rapidly implement and model custom geometries configurations and experimental scenarios with precision. Additionally, it details the modifications made to the instance of the G4IAEAphspReader library that we use.
[1] M. Kopeć, et al. A reconfigurable detector for measuring the spatial distribution of radiation dose for applications in the preparation of individual patient treatment plans. Nuclear Inst. and Methods in Physics Research, A 1048 (2023) 167937
[2] D. Kulig, et al. Comparison of cell casted and 3D-printed plastic scintillators for dosimetry applications Radiation Protection Dosimetry, Volume 199, Issue 15-16, October 2023, Pages 1824–1828,
The Jiangmen Underground Neutrino Observatory (JUNO) is a multi-purpose experiment under construction in southern China. JUNO is designed to determine the mass ordering of neutrinos and precisely measure neutrino oscillation parameters by detecting reactor neutrinos from the Yangjiang and Taishan Nuclear Power Plants. Atmospheric neutrinos, solar neutrinos, geo-neutrinos, supernova burst neutrinos and DSNB(Diffuse Supernova Neutrino Background), nucleon decay can also be studied with JUNO. The main detector of JUNO is a 20,000-ton liquid scintillator detector. The JUNO detector simulation software is a key component of the JUNO offline software (JUNOSW), developed based on the SNiPER framework. Due to the large size of the detector and broad range of energies of interest, detector simulation poses challenges in terms of CPU time and memory consumption. With computing nodes gradually incorporating multiple integrated CPU cores, traditional single-threaded computing models may result in significant memory usage and inefficient system resource utilization. Implementing multithreading processing on many-core architectures can significantly improve system resource utilization efficiency. This report will introduce the design and implementation status of multi-threaded detector simulation in JUNOSW.
The common and shared event data model EDM4hep is a core part of the Key4hep project. It is the component that is used to not only exchange data between the different software pieces, but it also serves as a common language for all the components that belong to Key4hep. Since it is such a central piece, EDM4hep has to offer an efficient implementation. On the other hand, EDM4hep has to be flexible enough in order to allow for new developments in detector technology and reconstruction. In order to meet these challenges EDM4hep is using the podio EDM toolkit to generate its implementation from a high level description.
In this talk we give an overview of EDM4hep emphasizing the most recent
developments that were tackled on the way to a first stable release. We use this opportunity to also highlight the latest developments in the podio toolkit that were required by the latest EDM4hep features. These include the introduction of type erased interface types, and a new generic RDataSource to support the full data model API in RDataFrame.
The software description of the ATLAS detector is based on the GeoModel toolkit, developed in-house for the ATLAS experiment but released and maintained as a separate package with few dependencies. A compact SQLite-based exchange format permits the sharing of geometrical information between applications including visualization, clash detection, material inventory, database browsing, and lightweight full simulation. ATLAS simulation, reconstruction, and other elements of standard ATLAS offline workflows are now being adapted to ingest the geometry files which are prepared using platform independent modular geometry plugin code. This represents a major transformation of the ATLAS detector description software, impacting even the development procedures, for which new roles have been invented. During these integration activities, both the GeoModel geometry kernel and the GeoModel toolkit have seen improvements, including volume calculation, material blending, helper classes for simpler memory management, and and a richer collection of supported geometrical objects. This talk reports on these activities.
Computing Infrastructure
Research has become dependent on processing power and storage, with one crucial aspect being data sharing. The Open Science Data Federation (OSDF) project aims to create a scientific global data distribution network, expanding on the StashCache project to add new data origins and caches, access methods, monitoring, and accounting mechanisms. OSDF does not develop any new software, relying on the XrootD and Pelican projects, instead. Nevertheless, it is vital for OSDF to understand the XrootD limits under various configuration options, including transfer rate limits, proper buffer configuration and storage type effect. We have thus executed a set of benchmarks with the goal of creating a set of recommendations to share with the XrootD and Pelican teams. In this work we describe the tests and the results performed using hosts on the National Research Platform (NRP). The tests cover a wide range of file sizes and parallel streams, and use clients located at various distances from the server host. We also used several standalone clients (wget, curl, pelican) and the native HTCondor file transfer mechanisms.
CERN's state-of-the-art Prévessin Data Centre (PDC) is now operational, complementing CERN's Meyrin Data Centre Tier-0 facility to provide additional and sustainable computing power to meet the needs of High-Luminosity LHC in 2029 (expected to be ten times greater than today). In 2019, it was decided to tender the design and construction of a new, modern, energy-efficient (PUE of ≤ 1.15) Data Centre with a total of 12 MW IT capacity spread across six IT rooms. As it stands, two out of six IT rooms are production ready with a combined 4MW of IT capacity, with the remaining to be commissioned in two phases over the next ten years.
To begin, we will guide you through the commissioning of the Data Centre, with explanations of the various steps taken to equip the IT rooms. We will outline the acceptance process and the comprehensive trial operation tests which ensured a smooth transition into O&M (Operations and Maintenance) mode. O&M will be handled by Service Provider, Equans, in a collaborative partnership with the CERN IT department. This approach is the first of its kind at CERN and in this talk we’ll delve into how the contract was established.
We will finish by providing an overview of our progress in the first operational year with a look forward to scalable growth through the phased deployment of the remaining four IT rooms that will meet the anticipated need for physics computing into Run4.
We present our unique approach to host the Canadian share of the Belle-II raw data and the computing infrastructure needed to process the raw data. We will describe the details of the storage system which is a disk-only storage solution based on xrootd and ZFS, as well as TSM for backup purpose. We will also detail the compute that involves starting specialized Virtual Machine (VMs) to process the raw data. We will discuss the merits of our approach as well as the issues observed during deployment and commissioning.
Large-scale scientific collaborations like ATLAS, Belle II, CMS, DUNE, and others involve hundreds of research institutes and thousands of researchers spread across the globe. These experiments generate petabytes of data, with volumes soon expected to reach exabytes. Consequently, there is a growing need for computation, including structured data processing from raw data to consumer-ready derived data, extensive Monte Carlo simulation campaigns, and a wide range of end-user analysis. To manage these computational and storage demands, centralized workflow and data management systems are implemented. However, decisions regarding data placement and payload allocation are often made disjointly and via heuristic means. A significant obstacle in adopting more effective heuristic or AI-driven solutions is the absence of a quick and reliable introspective dynamic model to evaluate and refine alternative approaches.
In this study, we aim to develop such an interactive system using real-world data. By examining job execution records from the PanDA workflow management system, we have pinpointed key performance indicators such as queuing time, error rate, and the extent of remote data access. The dataset includes six months of activity. Additionally, we are creating a generative AI model to simulate time series of payloads, which incorporate visible features like category, event count, and submitting group, as well as hidden features like the total computational load—derived from existing PanDA records and computing site capabilities. These hidden features, which are not visible to job allocators, whether heuristic or AI-driven, influence factors such as queuing times and data movement.
The PUNCH4NFDI consortium, funded by the German Research Foundation for an initial period of five years, gathers various physics communities - particle, astro-, astroparticle, hadron and nuclear physics - from different institutions embedded in the National Research Data Infrastructure initiative. The overall goal of PUNCH4NFDI is the establishment and support of FAIR data management solutions for all users of the participating communities.
The federated compute and storage infrastructures made available to the PUNCH4NFDI consortium, Compute4PUNCH and Storage4PUNCH, will be presented. These infrastructures, comprising a variety of heterogeneous compute and storage systems provided by the participating institutions, are managed by an HTCondor overlay batch system and COBalD/TARDIS metaschedulers. The TARDIS manager dynamically integrates the various compute resources into one overlay batch system based on HTCondor, while the COBalD workload balancer optimizes the distribution of the tasks to be performed. The standardized access to the federated compute and storage resources is managed by a token-based authentication and authorization infrastructure. The refreshment of short-lived access tokens is automated in a transparent monitoring and renewal mechanism making use of the HTCondor credential manager in combination with the MyToken service. Login nodes are defining single entry points to the federation, while a virtualized and scalable software environments provisioning is ensured by the use of containers and the CERN Virtual Machine File System.
The latest developments of Compute4PUNCH and Storage4PUNCH will be presented, including the newly developed automated token management using HTCondor and Mytoken. In addition, the integration of Compute4PUNCH as a compute backend into the REANA reproducible analysis platform developed at CERN, with an instance hosted
and managed by the PUNCH4NFDI consortium, will be shown.
We are moving INFN-T1 data center to a new location. In this presentation we will describe all the steps taken to complete the task without decreasing the general availability of the site and of all the services provided.
We will also briefly describe the new features of our new data center compared to the current one.
Analysis facilities and interactive computing
Scientific computing relies heavily on powerful tools like Julia and Python. While Python has long been the preferred choice in High Energy Physics (HEP) data analysis, there’s a growing interest in migrating legacy software to Julia. We explore language interoperability, focusing on how Awkward Array data structures can connect Julia and Python. We discuss memory management, data buffer copies, and dependency handling, highlighting performance gains from invoking Julia from Python and vice versa. Particularly, we look into distributed array-oriented calculations involving large-scale HEP data and a unique role of Awkward Array in these workflows. We examine the advantages and challenges of achieving interoperability between Julia and Python in scientific computing.
During the ESCAPE project, the pillars of a pilot analysis facility were built following a bottom-up approach, in collaboration with all the partners of the project. As a result, the CERN Virtual Research Environment (VRE) initiative proposed a workspace that facilitates the access to the data in the ESCAPE Data Lake, a large scale data management system defined by Rucio, along with the interactive analysis that jupyter notebooks enable. The VRE also provisions a variety of scientific software stacks via CVMFS, and can be connected to local data processing resources through REANA. The latter is an open source software, developed within the CERN IT department, that provides a framework focussed on the reanalysis and reproducibility of scientific results. The CERN VRE has deployed an instance of REANA, allowing users to make use of the platform functionalities together with the rest of the services in the analysis facility.
Having a single interface that integrates different services with the underlying infrastructure certainly eases the user experience. Furthermore, in line with the ESCAPE Open Collaboration, the development of open source tools that can be reused in different physics communities with similar analysis strategies would lay the foundation of common lifecycle analysis practices. Therefore, in order to foster accessibility, as well as interactively and reproducibility to more complex infrastructure services, the development of user-friendly middleware should be prioritized.
This contribution focuses on the connection of REANA to the CERN VRE's interface through a Jupyter extension. The development of this extension makes it possible to use the VRE as a single workspace to enhance the lifecycle of a research analysis: from discovery and data access, through interactive analysis and offload to computing resources, to reproducibility of results.
The ROOT framework provides various implementations of graphics engines tailored for different platforms, along with specialized support of batch mode. Over time, as technology evolves and new versions of X11 or Cocoa are released, maintaining the functionality of correspondent ROOT components becomes increasingly challenging. The TWebCanvas class in ROOT represents an attempt to unify all these flavors together and provide a single implementation for all supported platforms – based on web technologies. The presentation will explore the utilization of the latest JavaScript ROOT v7, which offers comprehensive support for all ROOT classes, ensuring seamless integration and enhanced functionality across various platforms. Additionally, the presentation will discuss the implementation of HMAC-based authentication to bolster security for server-client communication, ensuring data integrity and confidentiality in web-based interactions. Furthermore, the presentation will showcase efforts in automating the testing of web graphics functionality, streamlining the development process and ensuring the reliability and robustness of the ROOT Web GUI.
Over the last few years, an increasing number of sites have started to offer access to GPU accelerator cards but in many places they remain underutilised. The experiment collaborations are gradually increasing the fraction of their code that can exploit GPUs, driven in many case by developments of specific reconstruction algorithms to exploit the HLT farms when data is not being taken. However, there is no wide-spread usage of GPUs on the Grid and no mechanism, yet, to pledge GPU resources. Whilst the experiments gradually make progress porting their production code, and external projects such as Celeritas and AdePT tackle key common tasks such as the acceleration of E/M calorimeter simulation as a plug-in for GEANT, there is no easy way for smaller groups or individual developers to develop GPU usage in a way that is easily transferred to the Grid environment. Currently, a user typically develops code on a local GPU in an interactive manner but there is significant overhead in subsequently containerising this work and moving it to the Grid environment. Indeed, many user jobs are not big enough to benefit from this last step and many sites must then maintain GPUs that are not integrated with the Grid infrastructure.
We have developed a proof-of-principle solution to enable interactive user access to Grid GPUs, enabling the initial development to take place on-Grid. This will ensure the development and production environments are identical and enable sites to move more GPUs to the Grid. An interactive development environment has been implemented with interactive HTCondor jobs and Apptainer containers. GPUs are split into MIG instances to allow for simultaneous multi-user utilisation. Users can install packages on the fly, giving them control over package versions as well as use what’s available on CVMFS. Once development is done the sandbox container can be made imputable and submitted to either the local batch style GPU que or sent to the rest of the GPUs available on the Grid. The nature of interactive development means many hurdles had to be overcome such as: User authentication, security considerations, data replication to other sites, as well as management tools to allowing users to keep track of their environments and jobs. We will report for the first time on the current status of this project.
The success and adoption of machine learning (ML) approaches to solving HEP problems has been widespread and fast. As useful a tool as ML has been to the field, the growing number of applications, larger datasets, and increasing complexity of models creates a demand for both more capable hardware infrastructure and cleaner methods of reproducibilty and deployment. We have developed a prototype ML Training facility (MLTF) with the goal of meeting these demands. The proof-of-concept MLTF is based at ACCRE, Vanderbilt's computing cluster, with sufficient GPU storage and networking to efficiently test very large models.The software component of MLTF is developed with an eye on reproducibility and portability. We adapt MLflow as an end-to-end ML solution for its capabilities as a user-friendly job submission interface; as a tracking server for model and run details, arbitrary metrics logging, and system diagnostics logging; and as an inference server.
Machine Learning (ML) is driving a revolution in the way scientists design, develop, and deploy data-intensive software. However, the adoption of ML presents new challenges for the computing infrastructure, particularly in terms of provisioning and orchestrating access to hardware accelerators for development, testing, and production.
The INFN-funded project AI_INFN ("Artificial Intelligence at INFN") aims at fostering the adoption of ML techniques within INFN use cases by providing support on multiple aspects, including the provision of AI-tailored computing resources. It leverages cloud-native solutions in the context of INFN Cloud, to share hardware accelerators as effectively as possible, ensuring the diversity of the Institute’s research activities is not compromised.
In this contribution, we provide an update on the commissioning of a Kubernetes platform designed to ease the development of GPU-powered data analysis workflows and their scalability on heterogeneous, distributed computing resources, possibly federated as Virtual Kubelets with the interLink provider.
Finally we showcase the deployment of the training and validation infrastructure for the flash-simulation pipeline of the LHCb experiment, known as Lamarr, providing a practical example of how our infrastructure supports complex ML workflows in high-energy physics.
The ATLAS Collaboration consists of around 6000 members from over 100 different countries. Regional, age and gender demographics of the collaboration are presented, including the time evolution over the lifetime of the experiment. In particular, the relative fraction of women is discussed, including their share of contributions, recognition and positions of responsibility, including showing how these depend on other demographic measures.
The official data collection for the RUN3 of the Large Hadron Collider (LHC) at CERN in Geneva commenced on July 5, 2022, following approximately three and a half years of maintenance, upgrades, and commissioning. Among the many enhancements to ALICE (A Large Ion Collider Experiment) is the new Fast Interaction Trigger (FIT) detector. Constant improvements to FIT's hardware, firmware, and software will enable progressively better performance. Between November 2024 and March 2025, during the Year-End Technical Stop (YETS), an update to the communication path between the Front-End Electronics (FEE) and the Detector Control System (DCS) is planned. This update will introduce a new approach based on the ALFRED (ALICE Low-Level Front-End Device) software, supported by the central DCS ALICE system. To address the challenge of integrating custom electronics with distributed control systems, this paper describes a novel extension of the Front-End Device (FRED) framework, which can interface bespoke electronics with standard SCADA (Supervisory Control and Data Acquisition) systems using IPbus. This framework can be applied to all detectors utilizing IPbus communication.
The Precision Proton Spectrometer (PPS) is a near-beam spectrometer that utilizes timing and
tracking detectors to measure scattered protons surviving collisions at the CMS interaction
point (IP). It is installed on both sides of CMS, approximately 200 meters from the IP, within
mechanical structures called Roman Pots. These special beam pockets enable the detectors to
approach the LHC beam within a few millimeters of its center. Due to the challenging
environment, PPS detectors require frequent calibrations and close monitoring.
This talk will introduce an automation software framework designed to streamline the
calibration process, reducing the time users spend on these tasks, facilitating their
implementation, and enhancing the monitoring of their execution and results. Developed
alongside other CMS subsystems, the framework supports multi-stage calibrations that
leverage CERN's distributed computing resources to run containerized tasks. Industry-grade
tools such as Jenkins, InfluxDB, and Grafana are employed for monitoring the calibration
execution and storing results, which can further be processed to identify anomalies in the data
quality.
Cloud computing technologies are becoming increasingly important to provide a variety of services able to serve different communities' needs. This is the case of the DARE project (Digital Lifelong Prevention), a four-year initiative, co-financed by the Italian Ministry of University and Research as part of the National Plan of Complementary Investments to the PNRR. The project aims to develop prevention and digital health in Italy through the complete valorization of the health data chain, including data relevant to health. Within DARE, INFN the Italian National Institute for Nuclear Physics (INFN) is leading the technology scouting and integration.
In particular, we present the activities aimed at using ANSYS software, moving from a local batch solution to a cloud-enabled platform. As a result, we deployed a microservices-based environment using the solutions and services made available within INFN Cloud, the Cloud infrastructure of INFN, adopting consolidated technologies like Kubernetes and CEPH and integrating services like Nextflow to improve the interoperability of the presented solution.
In such respect, Kubernetes offers a dynamic and adaptable system for launching and overseeing containerized applications, making it an excellent option for handling intricate workloads within the Cloud environment. CEPH offers a distributed storage environment and the possibility to provide persistent storage for Kubernetes as well as Object storage that can be made available to services and users to store their outcome and analyze their data. Similarly, Nextflow, a tool for managing workflows, was selected for its ability to seamlessly incorporate different software packages and systems for environment management. Additionally, it streamlines the process of creating and implementing computational pipelines that handle large amounts of data.
The objective of the current activity is to identify benefits and explore potential enhancements through the use of a cloud-based approach. Additionally, due to handling patient information and being subject to GDPR regulations, the workflow must be carried out within a secure infrastructure. Having worked on projects involving personal data at CNAF, we have acquired experience in the security sector, as well as in hardening tools like RKE2+CIS, and infrastructures such as EPIC. Ultimately, our goal is to integrate these workflows into a microservices-based environment within a secure Cloud infrastructure, with the intention of easily reproducing this process for future collaborations in the biomedical field.
Fermilab is transitioning authentication and authorization for grid operations to using bearer tokens based on the WLCG Common JWT (JSON Web Token) Profile. One of the functionalities that Fermilab experimenters rely on is the ability to automate batch job submission, which in turn depends on the ability to securely refresh and distribute the necessary credentials to experiment job submit points. Thus, with the transition to using tokens for grid operations, we needed to create a service that would obtain, refresh, and distribute tokens for experimenters’ use. This service would avoid the need for experimenters to be experts in obtaining their own tokens and would better protect the most sensitive long-lived credentials. Further, the service needed to be widely scalable, as we are currently keeping credentials active for approximately 15 experiments, each with 1-3 different credentials, and distributing those credentials to 2-20 submit points per experiment, with those numbers steadily increasing. To address these issues, we created and deployed a Managed Tokens service. The service is written in Go, taking advantage of that language’s native concurrency primitives to easily be able to scale operations as we onboard experiments. The service uses as its first credentials a set of kerberos keytabs, stored on the same secure machine that the Managed Tokens service runs on. These kerberos credentials allow the service to use htgettoken via condor_vault_storer to store vault tokens in the HTCondor credential managers (credds) that run on the batch system scheduler machines (HTCondor schedds); as well as downloading a local, shorter-lived copy of the vault token. The kerberos credentials are then also used to distribute copies of the locally-stored vault tokens to experiment submit points. When experimenters schedule jobs to be submitted, these distributed vault tokens are used to access a Hashicorp Vault instance (run separately from the Managed Tokens service), and previously-stored refresh tokens there are used to obtain the bearer token that is submitted with the job. We will discuss here the design of the Managed Tokens service, including elaborating on certain choices we made with regards to concurrent operations, configuration, monitoring, and deployment.
The simulation of physics events in the LHCb experiment uses the majority of the distributed computing resources available to the experiment. Notably, around 50% of the overall CPU time in the Geant4-based detailed simulation of physics events is spent in the calorimeter system. This talk presents a solution implemented in the LHCb simulation software framework to accelerate the calorimeter simulation.
During the Geant4 transport, the simulation of particles entering the calorimeter is stopped and the corresponding showers are generated using libraries of pre-simulated energy deposits. The energy deposits subsequently undergo a series of transformations to improve the accuracy of the simulation without increasing the library size. This technique reduces the computation time of the calorimeter to a negligible level.
The use of machine learning techniques in conjunction with the libraries to further enhance the simulation accuracy is also discussed, and a comparison between the outputs of the fast and detailed simulations is shown.
The Adaptive Hough Transform (AHT) is a variant of the Hough transform for particle tracking. Compared to other solutions using Hough Transforms, the benefit of the described algorithm is a shifted balance between memory usage and computation, which could make it more suitable for computational devices with less memory that can be accessed very fast. In addition, the AHT algorithm's flexibility is explored to suppress the number of false positives while maintaining high efficiency.
The algorithm's efficiency has been tested on single muon and pion events as well as high pile-up simulated data consistent with the High Luminosity LHC experiment using the ODD detector available in the ACTS toolkit. The AHT for single muons events yielded an efficiency of over 99% with an average of 9.9 reconstructed particles for a single truth particle. Filtering methods reduced the number of reconstructed particles to 1.8 while maintaining very high tracking efficiency. For pile-up cases, efficiency is above 98%. Additional peak filtering cuts the number of reconstructed tracks over 12 times.
This poster presents an overview and features of a bamboo framework designed for HEP data analysis. The bamboo framework defines a domain-specific language, embedded in python, that allows to concisely express the analysis logic in a functional style. The implementation based on ROOT's RDataFrame and cling C++ JIT compiler approaches the performance of dedicated native code. Bamboo is currently being used for several CMS Run 2 and Run 3 analyses that rely on the NanoAOD data format for which many reusable components are included.
The ePIC Collaboration is actively working on the Technical Design Report (TDR) for its future detector at the Electron Ion Collider to be built at Brookhaven National Laboratory within the next decade. The development of the TDR by an international Collaboration with over 850 members requires a plethora of physics and detector studies that need to be coordinated. An effective set of Collaborative Tools and an open, collaborative environment are instrumental for the success of this effort. This includes the Collaboration Web presence, modern digital repositories (Zenodo), collaborative document development (Google Docs, Overleaf), file sharing (XRootD, Google Drive), communication (Zoom and Mattermost). ePIC is leveraging GitHub for its shared development environment and code version control and validation. Current activities of the ePIC Collaboration in this area are informed in part by the previous successful Data and Analysis Preservation effort of the PHENIX Collaboration at RHIC. This included a complete redesign of the Collaboration’s public website with the goal of simplified long-term maintenance, preservation of its software environment using containerization techniques, and migration of its various research materials to Zenodo. In this presentation we describe the technology choices and progress in the area of the ePIC Collaborative Tools, covering the emerging web presence to replace the existing Wiki, communications and collaborative software development, digital repositories and routes to possible future data migration to new document development workflow systems.
Fully automated conversion from CAD geometries directly into their ROOT geometry equivalents has been a hot topic of conversation at CHEP conferences. Today multiple approaches for CAD to ROOT conversion exist. Many appear not to work well. In this paper, we report on three separate and distinct successful efforts from within the CBM collaboration, namely from our Silicon Tracking System team, from our Transition Radiation Detector team, from our Ring-imaging Cherenkov Detector team and from our Beam-Monitor Assembly team on their experiences. These studies benefit from being semi-independent and were reported upon during our biannual CBM collaboration meetings during 2023 and 2024.
In these eventually successful investigative studies, we discuss conversion from CAD in portable STEP format to meshed solids in STL format. Methods which form these into tessellated shapes are discussed. We reported on tessellation based upon TGeoArbN classes with due regard to computational costs occurred in conversion and in simulation. We conduct computation efficiency tests for transport and reconstruction simulations using different subsystems after converting them to VG shapes through a VecGeom converter command in ROOT. We bench tested different navigators and discuss geometry complexity with computational cost.
The main purpose of this contribution is to assess these investigative studies, in order to fix a plan on whether and how CAD to ROOT methods could and should be used by the CBM experiment. As the experiment is in its final design stage, we need to discuss this topics frankly.
DUNE’s current processing framework (art) was branched from the event processing framework of CMS, a collider-physics experiment. Therefore art is built on event-based concepts as its fundamental processing unit. The “event” concept is not always helpful for neutrino experiments, such as DUNE. DUNE uses trigger records that are much larger than collider events (several GB vs. MB). Therefore, to avoid allocating large chunks of memory, DUNE is developing a framework that is able to break apart trigger records into smaller segments for more granular processing, and then stitch those chunks back together into an event.
In order for such an event-processing framework to work it needs to be integrated with input/output infrastructure that allows for fine-grained storage and I/O. FORM (Fine-grained Object Reading/Writing Model), a DUNE project, which intends to explore fine grained I/O and storage framework to store data in finer containers. Data objects need to be partitioned into segments to serve the fine grained processing, and be stored separately at accessible locations. Thus enabling I/O to read/write segmented data objects individually to avoid excessive memory consumption caused by reading large storage objects. The details of data storage and I/O should be encapsulated by the framework and transparent to client code such as algorithms. The persistence framework, FORM, is designed to write and read data in multiple smaller entries/events resulting in improved concurrency.
Geant4 hadronic physics sub-library includes a wide variety of models for high and low-energy hadronic interactions. We report on recent progress in development of the Geant4 nuclear de-excitation module. This module is used by many Geant4 models for sampling of de-excitation of nuclear recoil produced in nuclear reactions. Hadronic shower shape and energy deposition are sensitive to these processes. We will present comparisons of Geant4 predictions for the thin target experiments and will discuss CPU efficiency of Geant4 de-excitation module.
Choosing the right resource can speedup jobs completion, better utilize the available hardware and visibly reduce costs, especially when renting computers on the cloud. This was demonstrated in earlier studies on HEPCloud. But the benchmarking of the resources proved to be a laborious and time-consuming process. This paper presents GlideinBenchmark, a new Web application leveraging the pilot infrastructure of GlideinWMS to benchmark resources, and shows how to use the data collected and published by GlideinBenchmark to automate the optimal selection of resources.
An experiment can select the benchmark or the set of benchmarks that most closely evaluate the performance of its workflows. With GlideinBenchmark and the help of the GldieinWMS Factory it controls the benchmark execution. Finally, a scheduler like HEPCloud's Decision Engine can use the results to optimize resource provisioning.
Monte Carlo Event Generators contain several free parameters that cannot be inferred from first principles and need to be tuned to better model the data. With increasing precision of perturbative calculations to higher orders and hence decreasing theoretical uncertainties, it becomes crucial to study the systematics of non-perturbative phenomenological models. A recent attempt was made at tuning the combination of the angular-ordered parton shower in Herwig7 and Lund string hadronization model to LEP data with a new approach called Autotunes [1]. However, the results showed worse performance to important observables like LEP event shapes when compared to the previous tunes of the cluster hadronization model. Since the angular ordered parton shower and the string hadronization model perform well independently with Herwig7 and Pythia8, we would naively expect them to perform better together and thus investigate further by tuning the setup with the Professor approach adopted in [2]. I present the results of our tune and compare it with the Herwig7 default, Pythia 8 and Autotunes tunes.
[1] High dimensional parameter tuning for event generators, J.Belm, L.Gellersen, Eur.Phys.J.C 80 (2020) 1, 54
[2] Systematic event generator tuning for the LHC, A.Buckley et al, Eur.Phys.J.C 65 (2010) 331-357
Extensive research has been conducted on deep neural networks (DNNs) for the identification and localization of primary vertices (PVs) in proton-proton collision data from ATLAS/ACTS. Previous studies focused on locating primary vertices in simulated ATLAS data using a hybrid methodology. This approach began with the derivation of kernel density estimators (KDEs) from the ensemble of charged track parameters, employing an analytical probability density estimation technique. These KDEs were subsequently utilized as input for two neural network (NN) architectures, namely UNet and UNet++, alongside the truth PV positions extracted in the form of target histograms from the simulated data. Through these investigations, a proof-of-concept was demonstrated, achieving performance comparable to the ATLAS Adaptive Multi-Vertex Finder (AMVF) algorithm, while also enhancing the vertex position resolution.
The current studies transition from analytical KDE computation to a fully NN-based implementation, presenting an end-to-end primary vertex finder algorithm driven by neural networks. A comprehensive analysis of this approach, including a comparative assessment of its performance against the AMVF algorithm, will be presented.
Precision measurements of fundamental properties of particles serve as stringent tests of the Standard Model and search for new physics. These experiments require robust particle identification and event classification capabilities, often achievable through machine learning techniques. This presentation introduces a Graph Neural Network (GNN) approach tailored for identifying outgoing particles in elastic events where a muon beam interacts with the atomic electrons of thin low-Z targets in a series of tracking stations containing silicon strip modules. The processes include, among others, ionization and pair production (resulting in e⁺e⁻ pairs) caused by muons. We illustrate the application of the developed technique through a case study utilizing simulated data of a reduced geometrical configuration of the MUonE experiment, which aims to precisely measure the leading hadronic contribution to the muon magnetic moment anomaly at CERN.
The implementation of a federated access system for GSI's local Lustre storage using XRootD and HTTP(s) protocols will be presented. It aims at ensuring a secure and efficient data access for the diverse scientific communities at GSI. This prototype system is a key step towards integrating GSI/FAIR into a federated data analysis model. We use Keycloak for authentication, which issues SciTokens through OpenID Connect, while LDAP manages local users. After successful login, a JSON Web Token (JWT) is created with appropriate read and write permissions. This token is passed to XRootD’s multiuser plugin, which performs the requested operations as the specified user. We also developed an easy-to-use web interface to improve the user experience. This federated access model enhances the security, scalability, and usability of GSI's storage systems, making it a strong solution for modern data management needs.
We present an overview of the Monte Carlo event generator for lepton and quark pair production for the high-energy electron-positron annihilation process. We note that it is still the most sophisticated event generator for such processes. Its entire source code is rewritten in the modern C++ language. We checked that it reproduces all features of the older code in Fortran 77. We discuss a number of improvements both in the MC algorithm and in its various interfaces, such as those to parton showers and detector simulation.
Traditional filesystems organize data in directories. The directories are typically a collection of files whose grouping is based on one criteria, i.e., the starting date of the experiment, experiment name, beamline ID, measurement device, or instrument. However, each file in a directory can belong to different logical groups, such as a special event type, experiment condition, or a part of a selected dataset.
The dCache is a storage system developed to store large amounts of scientific data, used by many HEP and Photon Science experiments.
With recent developments in dCache, we have introduced a concept of file tagging, which dynamically groups files with the same label into virtual directories. The file labels can be added, removed, renamed, and deleted through the admin interface or via Rest API. The files in the
virtual directories are exposed through all protocols supported by dCache.
This contribution will describe the details of the implementation for the file tagging in dCache and present our future development plans on automatic metadata extractions, a feature that will significantly simplify data management. Additionally, we are exploring the use of virtual directories as a way to translate scientific data catalogs into filesystem views for direct data analysis
The LHCb experiment requires a wide variety of Monte Carlo simulated samples to support its physics programme. LHCb’s centralised production system operates on the DIRAC backend of the WLCG; users interact with it via the DIRAC web application to request and produce samples.
To simplify this procedure, LbMCSubmit was introduced, automating the generation of request configurations from a basic parameterisation of the desired samples, eliminating the need for defining hundreds of static models as was done in the past. However, this submission process is still clunky, time-consuming, and lacks a conducive platform for discussion.
We present a more streamlined approach to testing and submitting requests via a GitLab repository. This involves creating a simulation request by opening a GitLab merge request, which is then processed via LbMCSubmit to generate the necessary configuration, and then automatically tested using Continuous Integration on a few events. Upon approval, productions are automatically submitted and run on the WLCG via DIRAC, with samples accessible in the bookkeeping.
This approach is faster and simpler for users, ensuring efficient resource utilisation through testing. Using GitLab has the added benefits of collating discussion and reviewing requests, and leveraging GitLab’s powerful approval feature with the custom API to enforce approvals by certain experts in requests where necessary.
Introduced in spring 2023 alongside LbMCSubmit and continually updated since, this system has become the standard procedure for simulation requests within LHCb, processing nearly five hundred requests to date.
The poster presents the first experiments with the time-to-digital converter (TDC) for the Fast Interaction Trigger detector in ALICE experiment at CERN. It is implemented in Field-Programmable Gate Array (FPGA) technology and uses Serializer and Deserializers (ISERDES) with multiple-phase clocks.
The input pulse is a standard differential input signal. The signal is sampled with eight evenly spaced phase-shifted clock pulses generated by Mixed-Mode Clock Manager (MMCM). Before reaching ISERDES units the input signal is first buffered and then divided into two complementary outputs. The two ISERDES units are set up in oversample mode, enabling them to capture 2-phase DDR data. One ISERDES is synchronized with clocks at 0° and 90° angles, whereas the other ISERDES synchronizes with clocks at 45° and 135° angles. Additional four clocks are generated by locally inverting logic within each ISERDES unit. Since the FPGA contains a large number of ISERDES blocks, it will allow us to create multi-channel systems in a single FPGA chip.
Also, we consider another TDC implementation, where the phase shift between ISERDES is performed using the IDELAY blocks. This solution makes it possible to use only two clock signals 0 and 90°. IDELAYs have adjustable delays from 39 ps to 78 ps depending on the clocking frequency and has built-in temperature-dependent compensation.
The Compressed Baryonic Matter (CBM) experiment at FAIR will explore the QCD phase diagram at high net-baryon densities through heavy-ion collisions, using the beams provided by the SIS100 synchrotron in the energy range of 4.5-11 AGeV/c (fully stripped gold ions). This physics program strongly relies on rare probes with complex signatures, for which high interaction rates and a strong selection are needed to achieve the necessary statistics.
These requirements led to the technical decision for a self-triggered and free-streaming data acquisition, followed by an online full reconstruction and selection chain. Such a system can operate reliably and efficiently only with a performant Experiment Control System (ECS) to ensure the synchronization and data quality of all sub-systems.
After looking at existing solutions, the development of a Python based solution focused only on the Experiment Control and on the upper layer of Detector Controls (state and configuration propagation) was instead chosen for CBM. To allow maximal quality checks of the core functions, it will be divided in three levels, from an experiment independent modular core to various user interfaces.
This contribution presents the design choices for this ECS, the technical core package, the CBM ECS core package and the demonstrator GUI packages based on it, as well as the checks and tests done with them.
The National Analysis Facility (NAF) at DESY is a multi-purpose compute cluster available to a broad community of high-energy particle physics, astro particle physics as well as other communities. Being continuously in production for about 15 years now, the NAF evolved through a number of hardware and software revisions. A constant factor however has been the human factor, as the broad set of user experiences and user interactions with compute and storage infrastructures requires a ongoing support endeavor.
While utilizing compute resources, i.e., CPU cycles, has shown to be the more easy part in running an Analysis Facility, setting up and operating storage as well as authentication/authorization infrastructures and models have always caused the most labour intense work loads. As such easing the operational load is paramount to run an AF efficiently. While solutions for monitoring of the different dimensions of an AF exists, i.e., the compute part or the storage systems, and integrated monitoring has been missing and bridging the information silos has been cumbersome. Thus the need for an integrated monitoring like per user and job file and network socket handles on the compute part being mapped to I/O information on the storage instances.
Furthermore, as an AF is an exposed system with regard to security constraints, care has to be taken to set up a sufficient safe service model in the various steps of designs and operations.
The Deep Underground Neutrino Experiment (DUNE), hosted by the U.S. Department of Energy’s Fermilab, is expected to begin operations in the late 2020s. The validation of one far detector module design for DUNE will come from operational experience gained from deploying offline computing infrastructure for the ProtoDUNE (PD) Horizontal Drift (HD) detector. The computing infrastructure of PD HD is developed to achieve the physics goals by storing, globally distributing, cataloging, reconstructing, simulating, and analyzing data. Offline computing activities start with raw data in Hierarchical Data Format (HDF5) collected by DUNE’s data acquisition (DAQ) system. The data is conveyed from the neutrino platform at CERN to the host labs using a data pipeline that includes Rucio for replica management and FTS3 for transport. The database system for PD HD comprises several backend relational databases (run configuration, beam instrumentation, slow controls, and calibration) that are fed into a Master Store database, an unstructured database, containing all of the information collected from the backend databases. A subset of this information, needed by offline users, is then moved into a lighter-weight relational database that users can access via an API or by an art service during the reconstruction and analysis stage. The primary software strategy for event reconstruction has been the adoption of algorithms that are flexible and accessible enough to support creative software solutions and advanced algorithms as HEP computing evolves. The collaboration anticipates making substantial use of HPCs for ProtoDUNE HD algorithms.
We will present the first analysis of the computational speedup achieved through the use of the GPU version of Madgraph, known as MG4GPU. Madgraph is the most widely used event generator in CMS. Our work is the first step toward benchmarking the improvement obtained through the use of its GPU implementation. In this presentation, we will show the timing improvement achieved without affecting physics performance, for a wide range of physics processes that are of general interest in CMS, quantified both by gridpack-generation and event-generation. Preliminary results demonstrate a speedup of a factor of three in matrix element calculation and a factor of 2.5 in full gridpack production for one of the most computationally intensive processes: Drell-Yan with four additional emissions. The workflows have been tested with diverse computational resources, including CUDA-enabled NVIDIA GPUs and modern vectorized CPUs from Intel and AMD, accessible via CERN resources and HPCs.
The increasing computing power and bandwidth of FPGAs opens new possibilities in the field of real-time processing of HEP data. LHCb now uses a cluster-finder FPGA architecture to reconstruct hits in the VELO pixel detector on-the-fly during readout. In addition to its usefulness in accelerating HLT1 reconstruction by providing it with pre-reconstructed data, this system enables further opportunities. Thanks to the triggerless readout architecture of LHCb, these reconstructed hit positions are available for every collision, amounting to a flow of $10^{11}$ hits per second, that can be exploited further.
We have implemented a set of programmable counters, counting the hit rate at many locations in the detector volume simultaneously on the fly. We use this data to measure, and continuously track, both the motion of the interaction region and the relative position of the detector elements, with precisions of $O(\mu m)$ and time granularity $O(ms)$. To this purpose we use a linearized calculation, based on a principal component analysis (PCA) of these low-level counters, that can be executed online with minimal computational effort. This methodology, being based on just the raw hit positions, differs in a substantial way from methodologies commonly in use, that rely on reconstructing of particle trajectories and their origin vertex, and are therefore computationally much more complex and more prone to biases due to internal detector misalignments. We report results obtained with real data in the 2024 run of LHCb.
A growing reliance on the fast Monte Carlo (FastSim) will accompany the high luminosity and detector granularity expected in Phase 2. FastSim is roughly 10 times faster than equivalent GEANT4-based full simulation (FullSim). However, reduced accuracy of the FastSim affects some analysis variables and collections. To improve its accuracy, FastSim is refined using regression-based neural networks trained with ML. The status of FastSim refinement is presented. The results show improved agreement with the FullSim output and an improvement in correlations among output observables and external parameters.
Level-1 Data Scouting (L1DS) is a novel data acquisition subsystem at the CMS Level-1 Trigger (L1T) that exposes the L1T event selection data primitives for online processing at the LHC’s 40 MHz bunch-crossing rate, enabling unbiased and unconventional analyses. An L1DS demonstrator has been operating since Run 3, relying on a ramdisk for ephemeral storage of incoming and intermediate data, accessible by the system's units through NFS. With the HL-LHC and the CMS Phase 2 upgrade projected to enhance trigger resolutions, a high-performance shared memory system is key to retain real-time processing capabilities in Run 4. For this, we leverage the emerging Compute Express Link (CXL) open standard, which provides uniform, cache-coherent memory access from heterogeneous processing units, targeting a streamlined pipeline with minimized data movement over a memory lake shared among CPUs and GPUs. In this contribution, we present the integration of CXL-compliant shared memory into the L1DS demonstrator at CMS, including an overview of our approach's design, benefits, and limitations. Furthermore, we evaluate CXL-based L1DS performance through analyses in heterogeneous contexts, supporting a discussion of the memory lake model and its use cases for the CMS community.
The ALICE Grid processes up to one million computational jobs daily, leveraging approximately 200,000 CPU cores distributed across about 60 computing centers. Enhancing the prediction accuracy for job execution times could significantly optimize job scheduling, leading to better resource allocation and increased throughput of job execution. We present results of applying machine learning techniques to predicting the execution time of ALICE computational jobs. To this end, we focus on the following main challenges in this prediction task:
(1) Feature extraction and selection: extracting the relevant features from the collected data and selecting the ones that are most important for model training and inference
(2) Model selection: identifying an ML model that is accurate and robust for our prediction problem.
(3) Model decay: making sure that the model accuracy does not deteriorate in time as new data arrives, possibly from an evolving data distribution.
(4) Near-real-time processing: predictions need to be made in near-real-time.
Our goal is to develop a solution capable of predicting job execution times for batches of hundreds of elements in less than 100 milliseconds, without compromising accuracy or hindering continuous learning. This requires striking a delicate balance between computational complexity and real-time performance. By addressing these challenges within the ALICE CERN experiment framework, we can enhance job scheduling efficiency and optimize resource allocation, ultimately advancing scientific research in particle physics.
Acknowledgements. This work is co-financed in part supported by the Ministry of Science and Higher Education (Agreement Nr 2023/WK/07) and by the program of the Ministry of Science and Higher Education entitled PMW
The super-resolution (SR) techniques are often used in the up-scaling process to add-in details that are not present in the original low-resolution image. In radiation therapy the SR can be applied to enhance the quality of medical images used in treatment planning. The Dose3D detector measuring spatial dose distribution [1][2], the dedicated set of ML algorithms for SR has been proposed to perform final dose distribution up-scaling. Despite the significant advancements in image processing, the task of three-dimensional (3D) image upscaling remains a formidable challenge and has not gained widespread popularity due to the inherent complexities associated with preserving spatial consistency and accurately interpolating volumetric pixel intensities.
In our project, as the SR technique, the SRCNN [3] architecture has been adjusted. The training and validation data being produced with Geant4 MC simulation with in-house developed application and with two different scoring resolutions. Extra features related to the beam shape have been defined. The input data resolution is the one coming from the measurement (1cc) and the target data resolution is defined at the level of the CT image. Our research's latest breakthroughs and advancements will feature at the conference.
References:
[1] https://dose3d.fis.agh.edu.pl,
[2] M. Kopeć, et al. A reconfigurable detector for measuring the spatial distribution of radiation dose for applications in the preparation of individual patient treatment plans. Nuclear Inst. and Methods in Physics Research, A 1048 (2023) 167937
[3] Dong, C., Loy, C.C., He, K., Tang, X. (2014). Learning a Deep Convolutional Network for Image Super-Resolution. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds) Computer Vision – ECCV 2014. ECCV 2014. Lecture Notes in Computer Science, vol 8692. Springer, Cham. https://doi.org/10.1007/978-3-319-10593-2_13
The LHCb Detector project is home to the detector description of the LHCb experiment. It is used in all data processing applications, from simulation to reconstruction . It is based on the DD4hep package relying on the combination of XML files and C++ code. The need to support different versions of the detector layout in different data taking periods, on top of the DD4hep detector description format, necessitated a suite of recent custom developments.
The detector descriptions are identified by the C++ code and folders containing their description files (in the DD4hep CompactXML format). To support concurrent detectors layout, by convention, the components' description has to be self-contained and individually versioned within their respective component folders. There is no dependency between the components. The description of the overall LHCb detector combines specific versions of the components for the period being described; the versions for a specific data taking period or potential layouts to be simulated are in corresponding folders. When a sub-detector is identical in two LHCb layouts it can be loaded by both, avoiding code duplication and facilitating future upgrade simulation studies. A convention for naming the versions consistent between the components and the whole detector has been set up. Dependency and conventions checks as well as geometry monitoring are enforced by use of GitLab’s CI testing. They include verifications that changes introduced do not affect existing versions.
Simulating the Large Hadron Collider detectors, particularly the Zero Degree Calorimeter (ZDC) of the ALICE experiment, is computationally expensive. This process uses the Monte Carlo approach, which demands significant computational resources, and involves many steps. However, recent advances in generative deep learning architectures present promising methods for speeding up these simulations.
In this work, we apply normalizing flows to the simulation of ZDC neutron detector responses, thus obtaining high-fidelity surrogates of numerical models, and achieving competitive results on the GEANT4 dataset. We also provide and compare post-processing techniques for enhancing the results. Moreover, we check if the reasoning of the networks is physically relevant by employing state-of-the-art explainability techniques. This we see as a vital step in deciding whether our model is ready to replace the current simulation engine.
Data and Metadata Organization, Management and Access
In this presentation, I will outline the upcoming transformations set to take place within CERN's database infrastructure. Among the challenges facing our database team during the Long Shutdown 3 (LS3) will be the upgrade of Oracle databases.
The forthcoming version of Oracle database is introducing a significant internal change as the databases will be converted to a container architecture. This presentation will introduce the concept of a container database and show the challenges and new opportunities it brings.
This major upgrade will also introduce numerous new features. Some of the expected functionalities are vector data types and vector indexes, as well as JSON Relational duality. Additionally, we'll explore the potential benefits of adopting new schema-level privileges and Oracle True Cache technology.
Seamless and efficient transition necessitates close collaboration between the database team and its users. This presentation aims to inform the community of the upcoming changes and the efforts required to ensure a smooth transition.
Remote file access is critical in High Energy Physics (HEP) and is currently facilitated by XRootD and HTTP(S) protocols. With a tenfold increase in data volume expected for Run-4, higher throughput is critical. We compare some client-server implementations on 100GE LANs connected to high-throughput storage devices. A joint project between IT and EP departments aims to evaluate RNTuple as a replacement for ROOT’s TTree format, with a focus on verifying the scalability of EOS storage using a new data format. Based on this project we run a large-scale experiment to stress CERN’s CPU, network and memory by using massively parallel analysis workflows and replicated datasets in EOS physics instances.
The recent commissioning of CERN’s Prevessin Data Centre (PDC) brings the opportunity for multi-datacentre Ceph deployements, bringing advantages for business continuity and disaster recovery. However, the simple extension of a single cluster across data centres is impractical due to the impact of latency on Ceph’s strong consistency requirements. This paper reports on our research towards building a multi datacentre Ceph deployment in production. Due to the nature of different transaction semantics for blocks, objects and files, geo-distributing a ceph cluster needs a different approach for each protocol in use. This paper will detail the challenges with Ceph across data centres, the various solutions we evaluated and a roadmap for the future at CERN.
Erasure-coded storage systems based on Ceph have become a mainstay within UK Grid sites as a means of providing bulk data storage whilst maintaining a good balance between data safety and space efficiency. A favoured deployment, as used at the Lancaster Tier-2 WLCG site, is to use CephFS mounted on frontend XRootD gateways as a means of presenting this storage to grid users.
These storage systems are complex and self-correcting, but despite access to a myriad of metrics the inner workings of the storage tend to be opaque to the storage admin. One of the common problems seen within Ceph based systems are “Slow Ops” - instances of operations that take longer than expected, that are also often blocking in nature, impacting the overall performance and reliability of the system. These could be caused by, for example, intensive client side usage, internal CEPH data movement or hardware and/or network issues. Identifying the causes of a slow operation can provide a means to prevent or reduce the impact of future occurrences, leading to an increase in performance and reliability.
We detail the Lancaster Grid Site’s attempts to understand the causes of and mitigate against these “Slow Ops” and other performance bottlenecks within our storage system, with a focus on deletions as a case study on operations with a potential high-impact for the Ceph backend. We endeavour to bring together a holistic monitoring model, utilising Ceph metrics, detailed XRootD monitoring streams and client-side logging, in order to understand how data-management events impact the health of the storage.
Onedata [1] platform is a high-performance data management system with a distributed, global infrastructure that enables users to access heterogeneous storage resources worldwide. It supports various use cases ranging from personal data management to data-intensive scientific computations. Onedata has a fully distributed architecture that facilitates the creation of a hybrid cloud infrastructure with private and commercial cloud resources. Users can collaborate, share, and publish data, as well as perform high-performance computations on distributed data using different interfaces.
Within the ALICE project, we are designing an architecture that live-streams monitoring data from MonALISA dataand stores it in Onedata, utilising S3 storage. This data is accessible through the POSIX filesystem HPC, cloud infrastructures, and external MLOps systems (via S3 or REST API). When a computational task requires the data, it is seamlessly transferred and cached at the task’s location. Onedata’s distributed and multi-protocol nature facilitates the creation of a hybrid data processing infrastructure, where Onedata functions as the data plane. The platform also includes robust security features to safeguard data and metadata from unauthorised changes, ensuring the integrity of the datasets during the final preparation stages. Additionally, Onedata enables long-term archiving of datasets, preserving crucial information for future reference. Data can be structured hierarchically within Onedata, and datasets are annotated with metadata, simplifying the organisation and retrieval of specific information.
Currently, Onedata is used in European projects: EUreka3D [3], EuroScienceGateway [4], DOME [5], InterTwin [6] where it provides a data transparency layer for managing large, distributed datasets on dynamic hybrid cloud containerised environments.
Acknowledgements: This work is co-financed in part supported by the Ministry of Science and Higher Education (Agreement Nr 2023/WK/07) and by the program of the Ministry of Science and Higher Education entitled "PMW".
References:
[1] Onedata project website. https://onedata.org.
[2] ALICE - A Large Ion Collider Experiment. https://alice-collaboration.web.cern.ch.
[3] EUreka3D: European Union’s REKonstructed in 3D. https://eureka3d.eu.
[4] EuroScienceGateway project: open infrastructure for data-driven research. https://galaxyproject.org/projects/esg/.
[5] DOME: A Distributed Open Marketplace for Europe Cloud and Edge Services. https://dome-marketplace.eu.
[6] InterTwin: Interdisciplinary Digital Twin Engine for Science. https://intertwin.eu.
In order to achieve the higher performance year on year required by the 2030s for future LHC upgrades at a sustainable carbon cost
to the environment, it is essential to start with accurate measurements of the state of play. Whilst there have been a number of studies
of the carbon cost of compute for WLCG workloads published, rather less has been said on the topic of storage, both nearline and archival.
We present a study of the embedded and ongoing carbon costs of storage in multiple configurations, from Tape farms through to SSDs, within the UK Tier-1 and Tier-2s and discuss how this directs future policy.
Online and real-time computing
The ATLAS experiment at CERN is constructing upgraded system
for the "High Luminosity LHC", with collisions due to start in
2029. In order to deliver an order of magnitude more data than
previous LHC runs, 14 TeV protons will collide with an instantaneous
luminosity of up to 7.5 x 10e34 cm^-2s^-1, resulting in much higher pileup and
data rates than the current experiment was designed to handle. While
this is essential to realise the physics programme, it presents a huge
challenge for the detector, trigger, data acquisition and computing.
The detector upgrades themselves also present new requirements and
opportunities for the trigger and data acquisition system.
The design of the TDAQ upgrade comprises: a hardware-based low-latency
real-time Trigger operating at 40 MHz, Data Acquisition which combines
custom readout with commodity hardware and networking to deal with
4.6 TB/s input, and an Event Filter running at 1 MHz which combines
offline-like algorithms on a large commodity compute service
with the potential to be augmented by commercial accelerators .
Commodity servers and networks are used as far as possible, with
custom ATCA boards, high speed links and powerful FPGAs deployed
in the low-latency parts of the system. Offline-style clustering and
jet-finding in FPGAs, and accelerated track reconstruction are
designed to combat pileup in the Trigger and Event Filter
respectively.
This contribution will report recent progress on the design, technology and
construction of the system. The physics motivation and expected
performance will be shown for key physics processes.
The CMS Level-1 Trigger Data Scouting (L1DS) introduces a novel approach within the CMS Level-1 Trigger (L1T), enabling the acquisition and processing of L1T primitives at the 40 MHz LHC bunch-crossing (BX) rate. The target for this system is the CMS Phase-2 Upgrade for the High Luminosity phase of LHC, harnessing the improved Phase-2 L1T design, where tracker and high-granularity calorimeter data will be available for the first time. Currently, a L1DS demonstrator is operating during LHC Run3, collecting data from the CMS L1T system. This contribution focuses on the online processing system of the Run3 scouting demonstrator, introduced for the first time in the beginning of 2024. Its function is to aggregate data fragments from all scouting sources (event building), perform online analysis/selection, and generate datasets for offline analysis. Contrary to the standard CMS data-taking, data fragments and processing are based on the LHC orbit, rather than individual events per BX. This allows the system to work at a constant rate of about 11kHz, while opening the possibility of exploring multi-BX correlations. An overview of the L1DS system will be provided, including its architecture, performance, and first results.
The Next Generation Triggers project (NextGen in short) is a five-year collaboration across ATLAS and CMS (with contributions from LHCb and ALICE) and the Experimental Physics, Theoretical Physics, and Information Technology Departments of CERN to research and develop new ideas and technologies for the experiment trigger systems for HL-LHC and beyond. After more than a year of preparation in 2022-2023, the project started in January 2024 and involves the effort of more than 100 researchers and engineers working on four interacting areas: (1) online data processing, modern computing architectures, novel algorithmic concepts, machine learning and the direct interplay of experimental approaches and theory simulation; (2) enhancing the ATLAS trigger and data acquisition to focus on improved and accelerated filtering and exotic signature detection; (3) rethinking the CMS real-time data processing to design a novel AI-powered real-time processing workflow to analyze every single collision produced in the LHC; and (4) designing novel education and training programmes to support the experiment research plans. Investigations of the use of ML from front-end systems inference to development of workflows for large-scale training on local, cloud and HPC systems are among the objectives of the project. Explorations of novel quantum-inspired methods for event generators, optimization in data structures, compression, processes and pipelines are all areas in scope of the research programme. This presentation describes the overall concepts and objectives of the project and the preliminary results and lessons learned after NextGen’s first 10 months.
The new generation of high-energy physics experiments plans to acquire data in streaming mode. With this approach, it is possible to access the information of the whole detector (organized in time slices) for optimal and lossless triggering of data acquisition. Each front-end channel sends data to the processing node via TCP/IP when an event is detected. The data rate in large detectors is often very high and the network is likely to be a bottleneck for the system. On the other hand, the network devices do not need to know the signal shape but only the hit timing (time-stamp) and the address of the front end that generated it. This is a key point to implement a compression algorithm: it is possible to compress signal samples after the front end and decompress them when data are needed for high-level analysis.
To achieve a high compression ratio and fast inference time on hardware an AI-supported algorithm, an autoencoder, is chosen. Autoencoder is an unsupervised machine learning algorithm composed of two parts: an encoder and a decoder that reduces the size of the input and reconstructs the original input from the encoded representation, respectively.
This contribution describes the compression algorithm and the Streaming Readout DAQ (SRO) system prototype developed to test it. The SRO prototype is designed with three separate nodes connected to the same network. We use a PC as a proxy of the final high-level analysis node and two Raspberry Pi single-board computers as signal generators and data processing units (compressors). The architecture was made such that each node could/will be easily replaced with faster hardware (eg. an FPGA).
Consideration concerning the compression algorithm complexity, loss during compression, and execution time are taken into account to achieve the best tradeoff. Results of autoencoder training and timing of some implemented configurations are reported.
The High-Luminosity LHC upgrade will have a new trigger system that utilizes detailed information from the calorimeter, muon and track finder subsystems at the bunch crossing rate, which enables the final stage of the Level-1 Trigger, the Global Trigger (GT), to use high-precision trigger objects. In addition to cut-based algorithms, novel machine-learning-based algorithms will be employed in the trigger system to achieve higher selection efficiency and detect unexpected signals. The focus of this study is the comparison of different machine learning architecture models, including Boosted Decision Trees, Deep Neural Networks and Auto-Encoders. The trigger system will be implemented in FPGAs, benefiting from the performance of the employed AMD Ultrascale+ parts and an increased latency budget available in the new trigger system the utilization of topological correlations as inputs to these novel algorithms will be explored. Notable topological correlations employed are two-objects ∆R and invariant masses (e.g. di-jets, di-muons, di-electrons). The effective FPGA hardware implementation and its optimization will play a key role in this study.
In this talk we present the HIGH-LOW project, which addresses the need to achieve sustainable computational systems and to develop new Artificial Intelligence (AI) applications that cannot be implemented with the current hardware solutions due to the requirements of high-speed response and power constraints. In particular we are focused on the several computing solutions at the Large Hadron Collider (LHC), where most of the computational systems are based on CPUs, but those solutions are not scalable for the future upgrade at high luminosity HL-LHC. Experiments at Future Colliders (FC) will have to face similar computational challenges and will benefit from our outcomes. The HIGH-LOW project develops the next generation of AI algorithms for high-energy physics, specifically tailored to run in real time and in an energy efficient way. This can also help to provide computational solutions for industrial and real life applications, like autonomous cars, autonomous drones, robotics, wearable medical devices, industrial production, visual inspection of production lines and surveillance.
Our project tackles both the ecological transition to low-power hardware and the shift from serial to highly parallel computing using GPUs, FPGAs, and IPUs. This dual approach enhances the efficiency and sustainability of computational resources in high-energy physics and beyond.
Offline Computing
Graph neural networks and deep geometric learning have been successfully proven in the task of track reconstruction in recent years. The GNN4ITk project employs these techniques in the context of the ATLAS upgrade ITk detector to produce similar physics performance as traditional techniques, while scaling sub-quadratically. However, one current bottleneck in the throughput and physics performance of graph-based tracking is the final processing of classified graph edges into track candidates. This stage typically requires a trade-off between computational and physics performance. In this contribution, we present a variety of algorithms to ameliorate this trade-off, from heuristic approaches that use GPU-accelerated graph operations, to learned approaches such as hierarchical graph neural networks. Based on dedicated timing studies, we show that these graph segmentation algorithms are also well-suited to online track reconstruction.
High quality particle reconstruction is crucial to data acquisition at large CERN experiments. While the classical algorithms have been successful so far, in recent years, the use of pattern recognition has become more and more necessary due to increasing complexity of the modern detectors. Graph Neural Network based approaches have been recently proposed to tackle challenges such as non-uniformity and high level of sparsity. They have been shown to work well not only for calorimetric reconstruction [1] but also for tracking [2]. These GNN based approaches require fast GPU execution of certain operations (such as kNN computation). We present a fast GPU-enabled software library which significantly outperforms existing approaches including those present in large machine learning frameworks (such as TensorFlow and PyTorch). In light of these optimizations, we discuss the performance and computational requirements of GNN based reconstruction algorithms. Finally, we also discuss how the application of these techniques can be extended beyond particle physics.
[1] Qasim, Shah Rukh, et al. "End-to-end multi-particle reconstruction in high occupancy imaging calorimeters with graph neural networks." The European Physical Journal C 82.8 (2022): 1-15.
[2] https://indico.jlab.org/event/459/contributions/11761/
Track reconstruction is an essential element of modern and future collider experiments, including the ATLAS detector. The HL-LHC upgrade of the ATLAS detector brings an unprecedented tracking reconstruction challenge, both in terms of the large number of silicon hit cluster readouts and the throughput required for budget-constrained track reconstruction. Traditional track reconstruction techniques often contain steps that scale combinatorically, which could be ameliorated with deep learning approaches. The GNN4ITk project has been shown to apply geometric deep learning algorithms for tracking to a similar level of physics performance with traditional techniques while scaling sub-quadratically. In this contribution, we compare the computational performance of a variety of pipeline configurations and machine learning inference methods. These include heuristic-and-ML-based graph segmentation techniques, GPU-based module map graph construction, and studies of high throughput graph convolutional kernels. In this contribution, we present benchmarks of latency, throughput, memory usage, and power consumption of each pipeline configuration.
The reconstruction of particle trajectories is a key challenge of particle physics experiments, as it directly impacts particle identification and physics performances while also representing one of the primary CPU consumers of many high-energy physics experiments. As the luminosity of particle colliders increases, this reconstruction will become more challenging and resource-intensive. New algorithms are thus needed to address these challenges efficiently. During track reconstruction, many more tracks are reconstructed than truth particles. This is partially due to fake tracks resulting from an arbitrary combination of detector hits and redundant duplicates of truth particle tracks. Reducing their amount could thus directly improve the speed of our tracking chain.
Those extra tracks are usually removed at the end of the tracking chain in a step called ambiguity resolution. We previously demonstrated (https://indico.jlab.org/event/459/contributions/11453/) that machine learning could speed up this step. Unfortunately, when a track is removed at the end of the tracking chain, all the time spent reconstructing it is lost. Eliminating fake and duplicated tracks before they are reconstructed would thus significantly speed up the reconstruction chain.
Cutting is usually applied to the seeds to mitigate this effect based on seed quality computed by the seeding algorithm. But those algorithms might not always be the most effective, requiring a lot of hand tuning and might not always keep the seed leading to the best possible track.
We propose using a ranking-based machine learning algorithm to select the track seeds before the track finding reconstructs them. The problem is fundamentally the same as with ambiguity resolution but with much less information available on the seeds than the tracks. With a clustering algorithm (such as DBSCAN), we can bundle together nearby seeds that appear to come from the same truth particle. Afterwards, we can apply a Neural Network (NN) using a novel Margin Ranking Loss Function to compare the seeds in each group and only keep one, which should lead to the closest reconstructed track to the truth. In order to fully evaluate this approach’s potential, we implemented it within the A Common Tracking Software (ACTS) framework and tested it on the Open Data Detector (ODD), a realistic virtual detector similar to a future ATLAS one. This evaluation showed an up to ten times speedup of the track finding and an improvement in the quality of the reconstructed tracks at the cost of a slight decrease in efficiency.
Track reconstruction is a crucial task in particle experiments and is traditionally very computationally expensive due to its combinatorial nature. Recently, graph neural networks (GNNs) have emerged as a promising approach that can improve scalability. Most of these GNN-based methods, including the edge classification (EC) and the object condensation (OC) approach, require an input graph that needs to be constructed beforehand. In this work, we consider a one-shot OC approach that reconstructs particle tracks directly from a set of hits (point cloud) by recursively applying graph attention networks with an evolving graph structure. This approach iteratively updates the graphs and can better facilitate the message passing across each graph. Preliminary studies on the TrackML dataset show physics and computing performance comparable to current production algorithms for track reconstruction. We also explore different techniques to reduce constraints on computation memory and computing time.
Graph neural networks represent a potential solution for the computing challenge posed by the reconstruction of tracks at the High Luminosity LHC [1, 2, 3]. The graph concept is convenient to organize the data and to split up the tracking task itself into the subtasks of identifying the correct hypothetical connections (edges) between the hits, subtasks that are easy to parallelize and process efficiently, for example using GPUs.
We will describe an algorithm that benefits from the graph advantages, but instead of using neural networks, it consists of direct geometric comparisons of neighboring edge pairs, testing the hypothesis of both edges corresponding to the same particle, to build up hit triplets and track candidates. The compatibility of edge pairs is tested based on two observables: the $\eta$ direction, and an estimator of the transverse momentum of the particle hypothetically associated with each edge. Before this step, the tracking algorithm includes graph construction with a modified version of the Module Map method described at [2]. In this Module Map version, the hits are organized in a two dimension map of the modules in the longitudinal detector plane ($r$, $z$), and next the edges are built based on a list of possible connections, in combination with a $\Delta\phi$ cut. At each module, the hits are ordered based on their $\phi$ position, which serves to significantly reduce the combinatorics when applying that $\Delta\phi$ cut.
We will present the track reconstruction performance of this algorithm, estimated using the Open Data Detector [4], as well as its computing efficiency. For this tracking chain executed in a single CPU core, the time required to process an HL-LHC $t\bar{t}$ event with 200 $pp$ interaction pileup per bunch crossing is of the order of a second, which makes it a rather energy efficient tracking algorithm. This is the processing time from the collection of reconstructed hits to the track candidates, targeting primary particles with transverse momentum above 1 GeV. The algorithm is highly parallelizable; executed on a GPU, the processing time is expected to decrease at least by one order of magnitude.
[1] S. Farrell et al., Novel deep learning methods for track reconstruction, 2018, arXiv: 1810.06111 [hep-ex], url: https://arxiv.org/abs/1810.06111.
[2] C. Biscarat et al., Towards a realistic track reconstruction algorithm based on graph neural networks for the HL-LHC, EPJ Web Conf. 251 (2021) 03047, url: https://doi.org/10.1051/epjconf/202125103047.
[3] H. Torres et al. on behalf of the ATLAS Collaboration, Physics Performance of the ATLAS GNN4ITk Track Reconstruction Chain, Proceedings of the CTD 2023, ATL-SOFT-PROC-2023-047, url: http://cds.cern.ch/record/2882507.
[4] https://gitlab.cern.ch/acts/OpenDataDetector.
Distributed Computing
LHAASO experiment is a new generation multi-component experiment designed to study cosmic rays and gamma-ray astronomy. The data volume from LHAASO are currently reaching to ~40PB and ~11PB of new data will be generated every year in the future. Such scale of data needs a big scale of computing resources to process. For LHAASO experiment, there are several types of computing sites to join the LHAASO distributed computing system, that a supercomputing center is one of them. To adding a supercomputing center, several components are developed: 1. a site job agent based on HTCondor is deployed in front of the batch system of the site; 2. two proxy services are respectively responsible to job schedule and data transfer from central side to the site across the firewall of supercomputing center; 3. a service synchronizes the necessary data to a shared filesystem of the site, including the software. 4. job running environment is wrapped inside a container. The services have been deployed in a Chengdu Supercomputing Center and the test results indicate an acceptable performance on job schedule (thousands of jobs) and data transfer (tens of TB).
The Perlmutter HPC system is the 9th generation supercomputer deployed at the National Energy Research Scientific Computing Center (NERSC) It provides both CPU and GPU resources, offering 393216 AMD EPYC Milan cores with 4 GB of memory per core, for CPU-oriented jobs and 7168 NVIDIA A100 GPUs. The machine allows connections from the worker nodes to the outside and already mounts CVMFS for users who need to access software from it. These two options make Perlmutter an ideal candidate for integrating into Grid infrastructures.
Due to the specific highly parallel and massive CPU and memory requirements of the native payloads running on supercomputers, there is always an idle part of the computing capacity. Conversely Grid payloads require few CPU cores for a single task and can take advantage of the idle resources. This ‘backfill’ is advantageous both for the supercomputer operators, increasing the overall use efficiency of the machine and for the Grid users, allowing them to opportunistically use a substantial amount of CPUs. ALICE takes advantage of these conditions, the architecture of the Perlmutter supercomputer, and facilities offered by NERSC by deploying a standard Grid interface to Perlmuter through the NERSC SuperFacility API scheduling tool to submit and monitor normal Grid payloads.. Perlmutter has been integrated into the ALICE Grid, running Monte Carlo simulation, with measurements and tests having been made to also integrate analysis jobs connecting to an EOS instance hosted at LBNL shared with the main Tier 2 site. The resulting HPC-based Grid site has proven to be a reliable resource contributor to the ALICE Grid, providing 8000 cores on average, with its only constraints being the short lifetime of jobs and the current time allocation from NERSC.
This paper describes the path taken to integrate Perlmutter in the ALICE Grid and the usual modifications needed to integrate HPC facilities into the standard Grid infrastructure.
The ALICE Collaboration has begun exploring the use of ARM resources for the execution of Grid payloads. This was prompted by both their recent availability in the WLCG, as well as their increased competitiveness with traditional x86-based hosts in terms of both cost and performance. With the number of OEMs providing ARM offerings aimed towards servers and HPC growing, the presence of these resources in the Grid is anticipated to rise further. Consequently, it becomes a priority to ensure the underlying middleware is capable of running across architectures, ensuring available resources in the Grid are fully utilised.
This contribution outlines a reworked middleware stack, now used in production within ALICE, capable of running jobs across both Amd64 and Aarch64 ISAs, and the initial findings when used to execute Grid jobs compiled for the latter. Furthermore, it will examine how the middleware stack is able to dynamically match packages and binaries depending on the host. In turn, making both the selection process and executing architecture transparent from the end-user. At the same time, an overview is provided on how the middleware remains agnostic to the underlying architecture, allowing it to scale across various other types of CPUs - enabling support for additional architectures beyond ARM if needed, such as RISC-V.
The CernVM File System (CVMFS) is an efficient distributed, read-only file system that streams software and data on demand. Its main focus is to distribute experiment software and conditions data to the world-wide LHC computing infrastructure. In WLCG, more than 5 billion files are distributed via CVMFS and its read-only file system client is installed on more than 100,000 worker nodes. Recent hardware trends have increased the usage of CVMFS in highly parallel environments. Nodes with more than 64 physical cores running concurrent workloads are common. These highly parallel, many-core workloads have exposed specific bugs and limitations of CVMFS in such environments. This contribution reports on the developments that address these issues, and presents new performance benchmarks on machines with 256 (virtual) cores.
The HEPCloud Facility at Fermilab has now been in operation for six years. This facility is used to give a unified provisioning gateway to high performance computing centers, including NERSC, ORLF, and ALCF, other large supercomputers run by the NSF, and commercial clouds. HEPCloud delivers hundreds of millions of core-hours yearly for CMS. HEPCloud also serves other Fermilab experiments including DUNE, Mu2E, Muon g-2, and NOvA. In this paper we present the practical considerations of operating a distributed facility such as HEPCloud. We also mention some of the interesting research and development that HEPCloud has been used for including GPU-based machine learning inference servers, and tests of Quantum Computing.
The amount of data gathered, shared and processed in frontier research is set to increase steeply in the coming decade, leading to unprecedented data processing, simulation and analysis needs.
In particular, the research communities in High Energy Physics and Radio Astronomy are preparing to launch new instruments that require data and compute infrastructures several orders of magnitude larger than what is currently available and entering in the Exascale era.
To meet these requirements, new data-intensive architectures, heterogeneous resource federation models, and IT frameworks will be needed, including large-scale compute and storage capacity to be procured and made accessible at the pan-European level.
Additionally, the emergence of high-end Exascale HPC and Quantum computing systems provides new opportunities for accelerating discoveries and complementing the capabilities of existing research HTC and Cloud facilities.
Addressing key questions around scalability, performance, energy efficiency, portability, interoperability and cybersecurity is crucial to ensuring the successful integration of these heterogeneous systems.
In this context, the SPECTRUM project (https://spectrumproject.eu/) aims to deliver a Strategic Research, Innovation and Deployment Agenda (SRIDA) and a Technical Blueprint for a European compute and data continuum.
With a consortium composed of leading European science organisations in High Energy Physics and Radio Astronomy, and leading e-Infrastructure providers covering HTC, HPC, Cloud and Quantum technologies, the project will work with a Community of Practice composed of external experts.
The ultimate goal is to pave the way towards data-intensive scientific collaborations with access to a federated European Exabyte-scale research data federation and compute continuum.
The contribution is going to show how the project is going to operate, the results already obtained and the roadmap to the end of the project.
Simulation and analysis tools
Gravitational Waves (GW) were first predicted by Einstein in 1918, as a consequence of his theory of General Relativity published in 1915. The first direct GW detection was announced in 2016 by the LIGO and Virgo collaborations. Both experiments consist of a modified Michelson-Morley interferometer that can measure deformations of the interferometer arms of about 1/1,000 the width of a proton. The sensitivity of GW interferometers is limited by noise. Non-Gaussian transient noise artifacts, also known as glitches, are particularly challenging due to their similarity with astrophysical signals in the time and frequency domains. Noise reduction and subtraction is one of the most important and challenging activities in GW research.
InterTwin is a EU-funded project with the aim of building Digital Twins (DT) for various scientific use cases based on a co-designed blueprint architecture. Within InterTwin, we are developing GlitchFlow, a pipeline for modeling and generating glitches for GW interferometers using deep generative algorithms. In this contribution, we present results of the glitch generation using several Neural Network (NN) architectures, and describe the implementation of the pipeline as execution of DAGs (Directed Acyclic Graph) with an Apache Airflow instance deployed on Kubernetes. We show how the most computing intensive tasks such as model training can be off-loaded to Vega, the EuroHPC, using InterLink, a module developed within the InterTwin framework.
This paper presents the innovative HPCNeuroNet model, a pioneering fusion of Spiking Neural Networks (SNNs), Transformers, and high-performance computing tailored for particle physics, particularly in particle identification from detector responses. Drawing from the intrinsic temporal dynamics of SNNs and the robust attention mechanisms of Transformers, our approach capitalizes on these synergies to achieve heightened performance in discerning intricate particle interactions. At the heart of HPCNeuroNet lies the integration of the sequential dynamism inherent in SNNs with the context-aware attention capabilities of Transformers, enabling the model to precisely decode and interpret complex detector data. HPCNeuroNet is realized through the HLS4ML framework, optimized for deployment on FPGA environments. This architectural choice not only enhances computing speed but also enhances the accuracy and scalability of the models. Benchmarked against traditional particle physics models, HPCNeuroNet showcases superior performance metrics, underlining its transformative potential in high-energy physics. Our findings illuminate the groundbreaking potential of conjoining SNNs, Transformers, and FPGA-based high-performance computing in the domain of particle physics, marking a significant stride forward and establishing a robust foundation for future endeavors in the field.
Hamiltonian moments in Fourier space—expectation values of the unitary evolution operator under a Hamiltonian at various times—provide a robust framework for understanding quantum systems. They offer valuable insights into energy distribution, higher-order dynamics, response functions, correlation information, and physical properties. Additionally, Fourier moments enable the computation of arbitrarily complex polynomial transformations of the Hamiltonian, which have numerous applications, such as estimating ground state energy.
In this talk, we will discuss methods for reliably computing the first moments of a nuclear effective field theory using current quantum processors. We will delve into how echo-verification and noise renormalization techniques can be effectively employed within Hadamard test protocols, utilizing control reversal gates to avoid directly controlling the time evolution. These techniques, combined synergistically with purification and error suppression methods, significantly enhance the capabilities of current quantum processors. Our analysis, conducted using noise models, shows a substantial reduction in noise strength by two orders of magnitude. Additionally, quantum circuits involving up to 266 CNOT gates across five qubits achieve high accuracy with these methodologies when executed on IBM superconducting quantum devices.
Finally, we will see how noise renormalization techniques can be utilized to observe correlation decay across a quantum phase transition in one-dimensional spin chains, in alignment with the predictions of the Kibble-Zurek mechanism.
Based on arXiv:2401.13048
Jets are key observables to measure the hadronic activities at high energy colliders such as the Large Hadron Collider (LHC) and future colliders such as the High Luminosity LHC (HL-LHC) and the Circular Electron Positron Collider (CEPC). Yet jet reconstruction is a computationally expensive task especially when the number of final-state particles is large. Such a clustering task can be regarded as an optimization problem, which can be formulated in terms of an Ising Hamiltonian and searching for its ground state would provide the answer. Quantum-annealing-inspired algorithms provide promising solutions to tackle the problem. This study opens up a new approach to globally reconstruct multijet beyond dijet in one-go, in contrast to the traditional iterative method.
Machine learning, particularly deep neural networks, has been widely used in high-energy physics, demonstrating remarkable results in various applications. Furthermore, the extension of machine learning to quantum computers has given rise to the emerging field of quantum machine learning. In this paper, we propose the Quantum Complete Graph Neural Network (QCGNN), which is a variational quantum algorithm based model designed for learning on complete graphs. QCGNN with deep parametrized operators offers a polynomial speedup over its classical and quantum counterparts, leveraging the property of quantum parallelism. We investigate the application of QCGNN with the challenging task of jet discrimination, where the jets are represented as complete graphs. Additionally, we conduct a comparative analysis with classical models to establish a performance benchmark.
Built on algorithmic differentiation (AD) techniques, differentiable programming allows to evaluate derivatives of computer programs. Such derivatives are useful across domains for gradient-based design optimization and parameter fitting, among other applications. In high-energy physics, AD is frequently used in machine learning model training and in statistical inference tasks such as maximum likelihood estimation. Recently, AD has begun to be explored for the end-to-end optimization of particle detectors, with potential applications ranging from HEP to medical physics to astrophysics. To that end, the ability to estimate derivatives of the Geant4 simulator for the passage of particles through matter would be a huge step forward.
The complexity of Geant4, its programmatic control flow, and its underlying stochastic sampling processes, introduce challenges that cannot all be addressed by current AD tools. As such, the application of current AD tools to Geant4-like simulations can provide invaluable insights into the accuracy and errors of the AD gradient estimates and into how to address remaining challenges.
In this spirit, we have applied the operator-overloading AD tool CoDiPack to the compact G4HepEm/HepEmShow package for the simulation of electromagnetic showers in a simple sampling calorimeter. Our AD-enabled simulator allows to estimate derivatives of energy depositions with respect to properties of the geometry and the incoming particles. The derivative estimator comes with a small bias, which however proved unproblematic in a simple optimization study. In this talk, we will report on our methodology and encouraging results, and demonstrate how a next-generation AD tool, Derivgrind, can be used to bring these results to the scale of Geant4.
Computing Infrastructure
The Square Kilometre Array (SKA) is set to revolutionise radio astronomy and will utilise a distributed network of compute and storage resources, known as SRCNet, to store, process and analyse the data at the exoscale. The United Kingdom plays a pivotal role in this initiative, contributing a significant portion of the SRCNet infrastructure. SRCNet v0.1, scheduled for early 2025, will prototype the movement and management of data, demonstrating both ingestion and dissemination processes (using Rucio and related tools from HEP). It will also demonstrate access to data through science platforms and interactive analysis tools, building on synergies with discussions in the HEP community with Analysis Facilities.
Azimuth, a self-service portal optimised for high-performance computing in scientific applications, will be integral to this effort. It simplifies the complex management of cloud resources, making it an ideal tool for the heterogeneous compute environments provided by UK HPC sites. Federating access to UK and SKA members across these resources, and ensuring efficient use of network and storage placement will be critical for science exploitation by enhancing the experience and productivity of researchers. This work outlines the UK's architectural vision and roadmap, detailing implementation strategies for SRCNet v0.1 and beyond.
In the High-Performance Computing (HPC) field, fast and reliable interconnects remain pivotal in delivering efficient data access and analytics.
In recent years, several interconnect implementations have been proposed, targeting optimization, reprogrammability and other critical aspects. Custom Network Interface Cards (NIC) have emerged as viable alternatives to commercially available products, which often come with high price tags and limited or no customization options.
In this field, the APEnet project has been and continues to be engaged in developing custom FPGA-based NICs tailored for toroidal interconnection systems dedicated to scientific computing and simulations: leveraging a custom network protocol and being easily portable and reconfigurable, it ensures adaptability across various scientific domains spanning from High Energy Physics to Brain Simulation; it implements a 3D direct torus interconnect, which nested in a multi-tier topology, enables high path diversity, short cabling at low dimension and high efficiency.
In this work, we present the latest advancements for the APEnet NIC, APEnetX, which integrates cutting-edge Xilinx Ultrascale+ technologies with custom hardware and software components to enable Remote Direct Memory Access (RDMA) functionalities targeting both the remote hosts and accelerators such as GPUs. A custom network protocol is used, accompanied by Quality-of-Service (QoS) functionalities, to ensure efficient data transfers between nodes even in the event of critical congestion states. Finally, we developed the necessary libraries to replicate APEnetX in a simulated environment (Omnet++): the emulation of the network at large scale enables us to tailor the architecture for specific scientific applications.
The Worldwide Large Hadron Collider Computing Grid (WLCG) community’s deployment of dual-stack IPv6/IPv4 on its worldwide storage infrastructure is very successful and has been presented by us at earlier CHEP conferences. Dual-stack is not, however, a viable long-term solution; the HEPiX IPv6 Working Group has focused on studying where and why IPv4 is still being used, and how to flip such traffic to IPv6. The agreed end goal is to turn IPv4 off and run IPv6-only over the wide area network, to simplify both operations and security management.
This paper reports our work since the CHEP2023 conference. Firstly, we present our campaign to encourage the deployment of IPv6 on CPU services and Worker Nodes, with a deadline of end of June 2024. Then, the WLCG Data Challenge (DC24) performed during two weeks of February 2024 was an excellent opportunity to observe the percentage of data transfers which were carried by IPv6. We present our observation of the predominance of IPv6 in data transfers during DC24 and the opportunity we had to understand yet more reasons for the use of IPv4 and to get them removed.
The paper ends with the working group’s proposed plans and timescale for moving WLCG to “IPv6-only”. We have continued to test IPv6-only clusters as a way of confirming the readiness of the LHC experiments for an IPv6-only environment. Another aspect of the plan is the possible use of IPv6-only clients configured with a customer-side translator, or CLAT, together with a deployment of 464XLAT using what is often known as “IPv6-mostly” as in IETF RFCs 6877/8925. This will enable IPv6-only sites to continue to connect to non-WLCG IPv4-only services.
The Large Hadron Collider (LHC) experiments rely on a diverse network of National Research and Education Networks (NRENs) to distribute their data efficiently. These networks are treated as "best-effort" resources by the experiment data management systems. Following the High Luminosity upgrade, the Compact Muon Solenoid (CMS) experiment is projected to generate approximately 0.5 exabytes of data annually. The seamless operation of NRENs is crucial for the success of CMS and other LHC experiments. However, challenges arise during data
movement as NRENs lack awareness of data transfer priorities, importance, or quality of service requirements and NRENs operators can not ensure predictable data flow rates across multi-domain networks.
Our work focuses on SENSE, The Software-defined network for End-to-end Networked Science at Exascale, and Rucio, data management software used by multiple experiments, to allocate and prioritize specific data transfers across the wide area network. In this paper, we will showcase our advancements since the last publication, sharing insights gained and detailing the enhancements made to the software stack. These improvements enable science experiments to treat networks as first-class citizens and effectively utilize, prioritize, and manage wide area networks to sites.
The Network Optimised Experimental Data Transfer (NOTED) has undergone successful testing at several international conferences, including the International Conference for High Performance Computing, Networking, Storage and Analysis (also known as SuperComputing). It has also been tested at scale during the WLCG Data Challenge 2024, in which NREN's and WLCG sites conducted testing at 25% of the rates foreseen for the HL-LHC. During these events, NOTED has demonstrated its ability to detect network congestion and dynamically reconfigure the network by executing actions, thereby enhancing network capacity. Recently, the integration of NOTED with the CERN’s Network Monitoring System has increased its ability to detect and respond to congestion in the LHCOPN (Tier 0 to Tier 1’s links) and LHCONE (Tier 1’s to Tier 2’s links) networks. We report here on NOTED’s enhanced ability to identify congested WLCG sites and DC24 experiences with network reconfiguration to alleviate the detected congestion. Previous work has demonstrated the feasibility of improving NOTED’s ability to predict network traffic using machine learning with LSTM (Long Short-Term Memory) networks, given its capacity to learn from historical data. We present here new findings on the beneficial impact of various machine learning approaches, including encoders, transformers, and other algorithms, on the NOTED’s performance in relation to traffic forecasting.
Analysis facilities and interactive computing
The ROOT software package provides the data format used in High Energy Physics by the LHC experiments. It offers a data analysis interface called RDataFrame, which has proven to adapt well to the requirements of modern physics analyses. However, with increasing data collected by the LHC experiments, the challenge to perform an efficient analysis expands. One of the solutions to ease this challenge, is the leverage of modern high performing distributed computing environments for which RDataFrame provides an easy-to-use interface layer - the distributed RDataFrame.
In this talk, we show that the Distributed RDataFrame is out of the experimental testing phase, and it is now ready for production thanks to a stabilized user interface. We delve into recent improvements of the distributed RDataFrame, including Pythonizations of the interface that allow running the workflows seamlessly (for example, with the XGBoost library). As the variety and geographical locations of distributed environments are available, we show the reproducibility and compare the performance across several of them.
The ATLAS experiment is currently developing columnar analysis frameworks which leverage the Python data science ecosystem. We describe the construction and operation of the infrastructure necessary to support demonstrations of these frameworks, with a focus on those from IRIS-HEP. One such demonstrator aims to process the compact ATLAS data format PHYSLITE at rates exceeding 200 Gbps. Various access configurations and setups on different sites are explored, including direct access to a dCache storage system via Xrootd, the use of ServiceX, and the use of multiple XCache servers equipped with NVMe storage devices. Integral to this study was the analysis of network traffic and bottlenecks, worker node scheduling and disk configurations, and the performance of an S3 object store. The system's overall performance was measured as the number of processing cores scaled to over 2,000 and the volume of data accessed in an interactive session approached 200 TB. The presentation will delve into the operational details and findings related to the physical infrastructure that underpins these demonstrators.
As a part of the IRIS-HEP “Analysis Grand Challenge” activities, the Coffea-casa AF team executed a “200 Gbps Challenge”. One of the goals of this challenge was to provide a setup for execution of a test notebook-style analysis on the facility that could process a 200 TB CMS NanoAOD dataset in 20 minutes.
We describe the solutions we deployed at the facility to execute the challenge tasks. The facility was configured to provide 2000+ cores for quick turn-around, low-latency analysis. To reach the highest event processing rates we tested different scaling backends, both scaling over HTCondor and Kubernetes resources and using Dask and Taskvine schedulers. This configuration also allowed us to compare two different services for managing Dask clusters, Dask labextention, and Dask Gateway server, under extreme conditions.
A robust set of XCache servers with a redirector were deployed in Kubernetes to cache the dataset to minimize wide-area network traffic. The XCache servers were backed with solid-state NVME drives deployed within the Kubernetes cluster nodes. All data access was authenticated using scitokens and was transparent to the user.
To ensure we could track and measure data throughput precisely, we used our existing Prometheus monitoring stack to monitor the XCache pod throughput on the Kubernetes network layer. Using the rate query across all of the 8 XCache pods we were able to view a stacked cumulative graph of the total throughput for each XCache. This monitoring setup allowed us to ensure uniform data rates across all nodes while verifying we had reached the 200 Gbps benchmark.
In the data analysis pipeline for LHC experiments, a key aspect is the step in which small groups of researchers—typically graduate students and postdocs—reduce the smallest, common-denominator data format down to a small set of specific histograms suitable for statistical interpretation. Here, we will refer to this step as “analysis” with the recognition that in other contexts, “analysis” might include other pieces, such as the actual computation required to extract statistical interoperation from the histograms. Analysis is a very important part of the pipeline as it is the step where individual researchers exercise their creativity in trying new ideas in the pursuit of discovery. Therefore, a critical metric for the analysis step is turnaround time because it determines how rapidly researchers can explore their space of ideas. We demonstrate our experience reshaping late-stage analysis applications on thousands of nodes with the goal of minimizing turnaround time. It is not enough merely to increase scale: it is necessary to make changes throughout the stack, including storage systems, data management, task scheduling, and application design. We demonstrate these changes when applied to CMS analysis applications built using the Coffea framework, leveraging Dask and TaskVine to scale out to distributed resources. We evaluate the performance of the applications on opportunistic campus clusters, showing effective scaling up to 7200 cores, thus producing significant improvement in turnaround time.
China’s High-Energy Photon Source (HEPS), the first national high-energy synchrotron radiation light source, is under design and construction. HEPS computing center is the principal provider of high-performance computing and data resources and services for science experiments of HEPS. The mission of HEPS scientific computing platform is to accelerate the scientific discovery for the characteristics of light source experiments through high-performance computing and data analysis. In order to meet the diverse analysis needs of data analysis in light source disciplines, we have built a scientific computing platform that can provide desktop analysis, interactive analysis, batch analysis and other types of computing services, and support scientists to access the computing environment through the web anytime and anywhere, quickly analyze experimental data. In this article, a scientific computing platform for HEPS's diverse analysis requirements is designed. First, the diverse analysis requirements of HEPS is introduced. Second, the challenges faced by the HEPS scientific computing system. Third, the architecture and service process of the scientific computing platform are described from the perspective of user, and some key technical implementations will be introduced in detail. Finally, the application effect of computing platforms will be demonstrated.
We have created a Snakemake computational analysis workflow corresponding to the IRIS-HEP Analysis Grand Challenge (AGC) example studying ttbar production channels in the CMS open data. We describe the extensions to the AGC pipeline that allowed porting of the notebook-based analysis to Snakemake. We discuss the applicability of the Snakemake multi-cascading paradigm for running massively-parallel RECAST-compatible physics analysis workflows where the analysis process may run over numerous independent data samples with large number of independent individual data files in a fully concurrent manner. The created Snakemake workflow example was run on the REANA reproducible analysis platform. We describe the improvements brought to the REANA job scheduling, tracking and termination processes for massively-parallel Snakemake workflows. We present results of several numerical experiments running the same workflow on the Kubernetes cluster with increasing number of identical nodes. We infer on the feasibility of REANA to schedule numerous concurrent jobs from the same Snakemake workflow rule, study the importance of cluster node size from the point of view of the job memory requirements, as well as estimate the overhead of dispatching workload to many cluster nodes. The results demonstrate the applicability of Snakemake for even massively-parallel RECAST-compatible physics analysis workflows.
Meeting point: in front of the venue, the Auditorium Maximum of Jagiellonian University - Krupnicza 33 Street.
Panel dyskusyjny z udziałem naukowców z ośrodków krakowskich.
