Choose timezone
Your profile timezone:
We are pleased to announce a four-day event Fast Machine Learning for Science, which will be hosted by Imperial College London from September 25-28, 2023. The first three days will be workshop-style with invited and contributed talks. The last day will be dedicated to technical demonstrations and satellite meetings. The event will be hybrid with an in-person, on-site venue and the possibility to join virtually. For those attending in-person there will be a social reception during the evening of Monday 25th, and a dinner on Wednesday 28th.
As advances in experimental methods create growing datasets and higher resolution and more complex measurements, machine learning (ML) is rapidly becoming the major tool to analyze complex datasets over many different disciplines. Following the rapid rise of ML through deep learning algorithms, the investigation of processing technologies and strategies to accelerate deep learning and inference is well underway. We envision this will enable a revolution in experimental design and data processing as a part of the scientific method to greatly accelerate discovery. This workshop is aimed at current and emerging methods and scientific applications for deep learning and inference acceleration, including novel methods of efficient ML algorithm design, ultrafast on-detector inference and real-time systems, acceleration as-a-service, hardware platforms, coprocessor technologies, distributed learning, and hyper-parameter optimisation.
Abstract submission deadline: 14th August (extended!)
Registration deadline: 1st September
Organising Committee:
Sunita Aubeeluck
Robert Bainbridge
David Colling
Marvin Pfaff
Wayne Luk
Andrew Rose
Sioni Summers (co-chair)
Alex Tapper (co-chair)
Yoshi Uchida
Scientific Committee:
Thea Aarrestad (ETH Zurich)
Javier Duarte (UCSD)
Phil Harris (MIT)
Burt Holzman (Fermilab)
Scott Hauck (U. Washington)
Shih-Chieh Hsu (U. Washington)
Sergo Jindariani (Fermilab)
Mia Liu (Purdue University)
Allison McCarn Deiana (Southern Methodist University)
Mark Neubauer (U. Illinois Urbana-Champaign)
Jennifer Ngadiuba (Fermilab)
Maurizio Pierini (CERN)
Sioni Summers (CERN)
Alex Tapper (Imperial College)
Nhan Tran (Fermilab)
Biomedical data poses multiple hard challenges that break conventional machine learning assumptions. In this talk, I will highlight the need to transcend our prevalent machine learning paradigm and methods to enable them to become the driving force of new scientific discoveries. I will present machine learning methods that have the ability to bridge heterogeneity of individual biological datasets by transferring knowledge across datasets with a unique ability to discover novel, previously uncharacterized phenomena. I will discuss the findings and impact these methods have for annotating comprehensive single-cell atlas datasets and discovery of novel cell types.
The papers my talk was mostly based on are:
https://www.nature.com/articles/s41592-020-00979-3
https://www.nature.com/articles/s41592-022-01651-8
https://arxiv.org/pdf/2102.03526.pdf
https://www.biorxiv.org/content/10.1101/2023.02.03.526939v1.full.pdf
Timetable adjustment: https://docs.google.com/presentation/d/1NkoRFTu31AAAYCMhkxjL2MKi_hqm0D4HzqvHr8ClRBo/edit#slide=id.g283abf9457a_0_0
As detector technologies improve, the increase in resolution, number of channels and overall size create immense bandwidth challenges for the data acquisition system, long data center compute times and growing data storage costs. Much of the raw data does not contain useful information and can be significantly reduced with veto and compression systems as well as online analysis.
We design integrated systems combining digitizers (ADC/TDC), encoders, communication interfaces and embedded machine learning to analyze and reduce data at the source, near or on the detectors. The goal of these systems is to minimize latency and maximize throughput and minimize power consumption while keeping the accuracy as high as possible.
As the final system requires all these modules to work seamlessly together, we built a DAQ testbench to validate the data flow from the detector to the compute nodes. This testbench is built around an Arbitrary Waveform Generator that emulates the digital or analog signal from the detector. This setup measures the performance of the entire system and find any chokepoints or unstable elements. Among the measured performance metrics are maximum throughput, total latency, average and maximum power and accuracy of the applied algorithms when compared to the expected output.
We are currently testing DAQ systems for two applications :
1 ) The CookieBox, an attosecond angular streaking detector used for X-ray pulse shape recovery generating ~800 GB/s. This system requires microsecond latency to apply a veto on downstream detectors. The complete embedded system includes an ADC, an FIR filter, a peak finder algorithm, an optimized quantizer, a neural network to measure the signal characteristics and an Ethernet interface to the compute node. The neural network was improved over its previous implementation and currently operates at 0.14 µs latency and a theoretical 6.67 million events per second maximum throughput on a Virtex VCU128 board. Final assembly of the entire system for testing detector to compute node is underway.
2 ) The billion pixel X-ray camera for use in synchrotrons, XFEL facilities and pulsed power facilities generating up to 15 TB/s. The goal is to compress the camera image in place with no loss of information. To achieve a high compression ration with very low latency, we train neural networks to emulate the ISTA algorithm, which accelerates the processing time for each patch and uses operation directly compatible with hardware. This encoding is followed by a DEFLATE compression. The network compresses each 6x6 pixel patches in 1.01 µs with a ratio of 87:1 when implemented on a ZYNQ ZCU104 running at 100 MHz frequency. When optimizing using a latency strategy, the network achieves a 101:1 compression in 0.89 µs. Current work is underway to process larger patches using decomposed matrices.
The DAQ testbench will let us both qualify best performance and understand the throughput limitations and the power consumption for these complex systems, and hopefully increase buy in by potential users currently limited by data rates.
Particle flow reconstruction is crucial to analyses performed at general-purpose detectors, such as ATLAS and CMS. Recent developments have shown that a machine-learned particle-flow reconstruction using graph neural networks offer a prospect for computationally efficient event reconstruction [1-2]. Focusing on scalability of machine-learning based models for full event reconstruction, we compare two alternative models for particle flow reconstruction that can process full events consisting of tens of thousands of input elements, while avoiding quadratic memory allocation and computation cost. We test the models on a newly developed granular and detailed dataset based on full GEANT4 detector simulation for particle flow reconstruction studies. Using supercomputing, we carry out extensive hyperparameter optimization to choose a model configuration that significantly outperforms the baseline rule-based implementation on a cluster-based dataset; where the inputs are charged particle tracks and calorimeter clusters. We characterize the physics performance, using event-level quantities such as jet and missing transverse energy response, and computational performance of the model and find that using mixed precision can significantly improve training speed. We further demonstrate that the resulting model architecture and software setup is highly portable across hardware vendors, supporting training on NVidia, AMD, and Habana cards. Finally, we show that the model can be trained, alternatively, on a highly granular dataset consisting of tracks and raw calorimeter hits, resulting in a physics performance that is competitive with baseline particle flow, limited currently by training throughput. We expect that with additional effort in dataset design, model development and high-performance training, it will be possible to improve event reconstruction performance over current baselines. The extensive simulated dataset and model training code are made available under the FAIR principles.
[1] https://arxiv.org/abs/2101.08578
[2] https://arxiv.org/abs/2303.17657
The High-Luminosity LHC (HL-LHC) will provide an order of magnitude increase in integrated luminosity and enhance the discovery reach for new phenomena. The increased pile-up foreseen during the HL-LHC necessitates major upgrades to the ATLAS detector and trigger. The Phase-II trigger will consist of two levels, a hardware-based Level-0 trigger and an Event Filter (EF) with tracking capabilities. Within the Trigger and Data Acquisition group, a heterogeneous computing farm consisting of CPUs and potentially GPUs and/or FPGAs is under study, together with the use of modern machine learning algorithms such as Graph Neural Networks (GNNs).
GNNs are a powerful class of geometric deep learning methods for modeling spatial dependencies via message passing over graphs. They are well-suited for track reconstruction tasks by learning on an expressive structured graph representation of hit data and considerable speedup over CPU-based execution is possible on FPGAs.
The focus of this talk is a study of track reconstruction for the Phase-II EF system using GNNs on FPGAs. We explore each of the steps in a GNN-based EF tracking pipeline: graph construction, edge classification using an interaction network (IN), and track reconstruction. Several methods and hardware platforms are under evaluation, studying optimizations of the GNN approach aimed to minimize FPGA resources utilization and maximize throughput while retaining high track reconstruction efficiency and low fake rates required for the ATLAS Phase-II EF tracking system. These studies include IN model hyperparameter tuning, model pruning and quantization-aware training, and sequential processing of sub-graphs over the detector.
The combinatorics of track seeding has long been a computational bottleneck for triggering and offline computing in High Energy Physics (HEP), and remain so for the HL-LHC. Next-generation pixel sensors will be sufficiently fine-grained to the point of being able to determine angular information of the charged particle passing through. This detector technology immediately improves the situation for offline tracking but any major improvements in physics reach are unrealized since they are dominated by level-one trigger acceptance. We will demonstrate track angle and hit position prediction, including errors, using a mixture density network within a single layer of silicon as well as the progress towards and challenges of implementing the neural network in hardware as an ASIC.
Computing demands for large scientific experiments, such as the CMS experiment at CERN, will increase dramatically in the next decades. To complement the future performance increases of software running on CPUs, explorations of coprocessor usage in data processing hold great potential and interest. We explore the novel approach of Services for Optimized Network Inference on Coprocessors (SONIC) and study the deployment of this as-a-Service approach in large-scale data processing. In this setup, the main CMS Mini-AOD creation workflow is executed on CPUs, while several machine learning (ML) inference tasks are offloaded onto (remote) coprocessors, such as GPUs. With experiments performed at Google Cloud, the Purdue Tier-2 computing center, and combinations of the two, we demonstrate the acceleration of these ML algorithms individually on coprocessors and the corresponding throughput improvement for the entire workflow. We also show that this approach can be easily generalized to different types of coprocessors, and even deployed on local CPUs without performance decrease. We emphasize that SONIC enables high coprocessor usage and brings the portability to run workflows on different types of coprocessors.
Due to the stochastic nature of hadronic interactions, particle showers from hadrons can vary greatly in their size and shape. Recovering all energy deposits from a hadronic shower within a calorimeter into a single cluster can be challenging and requires an algorithm that accommodates the large variation present in such showers. In this study, we demonstrate the potential of a deep learning based algorithm based on a sparse point-voxel convolutional neural networks (SPVCNN) to perform hadronic calorimetry using Compact Muon Solenoid detector on the Large Hadron Collider with the hadron calorimeter and high granularity calorimeter. In particular, we focus on accelerating calorimeter reconstruction at HEP experiment calorimeters by offloading tasks to GPUs. By employing a modified object condensation loss, we train the network to group cell deposits into clusters while filtering out noise. We show that SPVCNN performs comparably to generic topological cluster-based methods in both pileup and no pileup scenarios, with the added advantage of acceleration using GPUs, and further algorithmic development with better datasets. This type of acceleration, as part of heterogeneous computing frameworks, will be crucial for the High-Luminosity Large Hadron Collider (HL-LHC). Our findings indicate that SPVCNN can provide efficient and accurate calorimetry solutions, particularly for high level trigger (HLT) applications with latency on the order of milliseconds.
In 2026 the Phase-II Upgrade will enhance the LHC to become the High Luminosity LHC. Its luminosity will be up to 7 times of the nominal LHC luminosity. This leads to an increase in interesting events which might open the door to detect new physics. However, it also leads to a major increase in proton-proton collisions with mostly low energetic hadronic particles, called pile-up. Up to 200 simultaneous collisions per LHC bunch crossing are expected. This puts higher demands on the ATLAS detector electronics and real-time data processing capabilities. The Liquid Argon calorimeter measures the energy of particles that are produced in LHC collisions. These energies are used by the trigger to decide whether events might be interesting and therefore worth saving for further investigations or not. The computation of the deposited energy is done in real-time on FPGAs, which are chosen due to their capacity to process large amounts of data with a very low latency. At the moment, the energy is calculated by an optimal filtering algorithm. This filter algorithm was adapted for LHC conditions with low pile-up, but studies under High Luminosity LHC conditions showed a significant decrease in performance. Especially a new trigger scheme that will allow trigger accept signals in successive LHC bunch crossings will challenge the energy readout. It could be shown that neither further extensions nor tuning of the optimal filter could improve the performance. That is why more sophisticated algorithms such as artificial neural networks came into focus. Convolutional neural networks have proven to be a promising alternative. However, the computational power that is available on the FPGA is tightly limited. Therefore, these networks need to have a low resource consumption. We developed networks that not only fulfill these requirements but also show performance improvements under various signal conditions. Especially for overlapping signals the convolutional neural networks outperform the legacy filter algorithm. Two types of network architectures will be discussed. The first type uses dilation to enlarge its field of view. This allows the network to get more information from past signal occurrences whereas at the same time keeps the total number of network parameters low. The other architecture uses a so-called tagging layer to first detect signal overlaps and then calculates the energy with the additional information. Their yield with respect to different performance measures will be compared to the legacy system. Furthermore, their semi-automated implementation in firmware will be presented. Calculations on the FPGA use fixed-point precision arithmetic, which is why quantization aware training is applied. Performance enhancements utilize time division multiplexing as well as bit width optimization. We show that the stringent processing requirements on the latency (at the order of 100 ns) can be achieved. Implementation results based on INTEL Agilex FPGAs will be shown, including resource usage and operation frequency.
A novel data collection system, known as Level-1 (L1) Scouting, is being introduced as part of the L1 trigger of the CMS experiment at the CERN LHC. The L1 trigger of CMS, implemented in FPGA-based hardware, selects events at 100 kHz for full read-out, within a short 3 microsecond latency window. The L1 Scouting system collects and stores the reconstructed particle primitives and intermediate information of the L1 trigger processing chain, at the full 40 MHz bunch crossing rate. Demonstrator systems consisting of PCIe-based FPGA stream-processing boards and associated host PCs have been deployed at CMS to capture the intermediate trigger data. An overview of the new system, and results from Run 3 data taking will be shown. In addition, a neural-network based re-calibration and fake identification engine has been developed to improve the quality of the L1 trigger objects for online analysis. We utilise new solutions for creating portable, flexible, and maintainable ML inference implementations that are accessible to those without hardware design knowledge. Tools such as High Level Synthesis languages, soft core libraries, and custom ML inference compilers will be discussed and explored. The results of these strategies as used for the CMS L1 trigger scouting system will be presented.
Decision Forests are fast and effective machine learning models for making real time predictions. In the context of the hardware triggers of the experiments at the Large Hadron Collider, DF inference is deployed on FPGA processors with sub-microsecond latency requirements. The FPGAs may be executing many algorithms, and many DFs, motivating resource-constrained inference. Using a jet tagging classification task representative of the trigger system, we optimise the DF training using Yggdrasil Decision Forests with fast estimation of resource and latency cost from the Conifer package for FPGA deployment. We use hyperparameter optimisation to select the optimal combination of DF architecture, feature augmentation, and FPGA compilation parameters to achieve optimal trade-off between model accuracy and inference cost under realistic LHC hardware constraints. We compare this Hardware/Software Codesign approach to other methods.
We introduce the fwXmachina framework for evaluating boosted decision trees on FPGA for implementation in real-time systems. The software and electrical engineering designs are introduced, with both physics and firmware performance detailed. The test bench setup is described. We present an example problem in which fwXmachina may be used to improve the identification of vector boson fusion Higgs production at the L1 triggers in LHC experiments. Comparisons are made to previous results, including comparisons to neural network approaches. The talk describes work in JINST 16 P08016 (2021), [2104.03408], as well as more recent results.
We present the preparation, deployment, and testing of an autoencoder trained for unbiased detection of new physics signatures in the CMS experiment Global Trigger test crate FPGAs during LHC Run 3. The Global Trigger makes the final decision whether to readout or discard the data from each LHC collision, which occur at a rate of 40 MHz, within a 50 ns latency. The Neural Network makes a prediction for each event within these constraints, which can be used to select anomalous events for further analysis. The implementation occupies a small percentage of the resources of the system Virtex 7 FPGA in order to function in parallel to the existing logic. The GT test crate is a copy of the main GT system, receiving the same input data, but whose output is not used to trigger the readout of CMS, providing a platform for thorough testing of new trigger algorithms on live data, but without interrupting data taking. We describe the methodology to achieve ultra low latency anomaly detection, and present the integration of the DNN into the GT test crate, as well as the monitoring, testing, and validation of the algorithm during proton collisions.
We describe an application of the deep decision trees, described in fwXmachina part 1 and 2 at this conference, in fwXmachina for anomaly detection in FPGA for implementation in real-time systems. A novel method to train the decision-tree-based autoencoder is presented. We give an example in which fwXmachina may be used to detect a variety of different BSM models via anomaly detection at the L1 triggers in LHC experiments. Comparisons are made to previous results, including comparisons to neural network approaches. This work is detailed in [2304.03836]
In the next years the ATLAS experiment will undertake major upgrades to cope with the expected increase of luminosity provided by the Phase II of the LHC accelerator. In particular, in the barrel of the muon spectrometer a new triplet of RPC detector will be added and the trigger logic will be performed on FPGAs. We have implemented a new CNN architecture that is able to identify the muon tracks and to determine some kinematical quantities in about 200 ns up to two muons at a time, with the expected noise conditions of Phase II. Then we have synthetised the algorithm on FPGA with the help of HLS4ML and we have satisfied the experimental requirements thanks to other compression techniques, like the knowledge distillation and the quantization aware training.
This work describes the investigation of neuromorphic computing--based spiking neural network (SNN) models used to filter data from sensor electronics in the CMS experiments experiments conducted at the High Luminosity Large Hadron Collider (HL-LHC). We present our approach for developing a compact neuromorphic model that filters out the sensor data based on the particle's transverse momentum with the goal of reducing the amount of data being sent to the downstream electronics. The incoming charge waveforms are converted to streams of binary-valued events, which are then processed by the SNN. We present our insights on the various system design choices---from data encoding to optimal hyperparameters of the training algorithm---for an accurate and compact SNN optimized for hardware deployment. Our results show that an SNN trained with an evolutionary algorithm and an optimized set of hyperparameters obtains a signal efficiency of about 91%, which is similar to that of a Deep Neural Network, but with nearly half the number of parameters.
The processing of large volumes of high precision data generated by sophisticated detectors in high-rate collisions poses a significant challenge for major high-energy nuclear and particle experiments. To address this challenge and revolutionize real-time data processing pipelines, modern deep neural network techniques and AI-centric hardware innovations are being developed.
The sPHENYX experiment is the new detector designed to collect data at Brookhaven Lab’s Relativistic Heavy Ion Collider. The overall goal of sPHENIX is to study the strong interaction implementing a real-time selection of rare decays of particles containing heavy quarks. The proposal for sPHENIX is to build an intelligent experiment where the control and data acquisition is smart because of AI and ML used in hardware, electronics and algorithm. The goals are:
extraction of critical data via selective streaming from complex data sets through real-time AI and
automated control, anomaly detection and feedback for detector operation through real-time AI.
The Large Hadron Collider will be upgraded to the High Luminosity LHC, delivering many more simultaneous proton-proton collisions, extending the sensitivity to rare processes. The CMS detector will be upgraded with new, highly granular, detectors in order to maintain performance in the busy environment with many overlapping collisions (pileup). For the first time, tracks from charged particles with a transverse momentum above 2 GeV will be reconstructed in the Level-1 Trigger, the first tier of data processing that accepts no more than 2.5% of collision events for further analysis. Charged particle tracks are crucial in separating signal processes from backgrounds, and in suppressing particles originating from the many pileup collisions. We present developments of Machine Learning algorithms in the reconstruction and usage of the tracks, including the removal of fake tracks, identification of the common vertex (point of origin) of the signal process, and in linking tracks to calorimeter deposits to effectively identify electrons down to low momentum. In all cases, we target a high signal efficiency and background rejection, as well as ultrafast and lightweight deployment in FPGAs.
The future LHC High-Luminosity upgrade amplifies the proton collision rate by a factor of about 5-7, posing challenges for physics object reconstruction and identification including tau and b-jet tagging. Detecting both the taus and bottom quarks at the CMS Level-1 (L1) trigger enhances many important physics analyses in the experiment. The challenge of the L1 trigger system requires identification at a throughput of 40 million collisions per second, while only having a latency of 12.5-microsecond window for each event. This study presents the integration of two machine learning algorithms for b-tagging and tau reconstruction into the CMS L1 trigger. Our algorithm utilizes the HLS4ML software to generate the neural network allowing us to achieve the desired latency and throughput within the constrained resources of the system. We present how the particle inputs are prepared, how the synchronization between different jet algorithms is performed, and board-testing of the whole system in Xilinx VU9P FPGAs.
Data storage is a major limitation at the Large Hadron Collider and is currently addressed by discarding a large fraction of data. We present an autoencoder based lossy compression algorithm as a first step towards a solution to mitigate this problem, potentially enabling storage of more events. We deploy an autoencoder model, on Field Programmable Gate Array (FPGA) firmware using the hls4ml library. The model is trained to reconstruct a small jet dataset derived from CMS Open Data, as a proof-of-principle. We show that the model is capable of compressing the dataset to nearly half the initial size with a tolerable loss in data resolution. We also open a discussion for future studies that enable testing data compression algorithms under conditions close to online operation of the LHC.
With machine learning gaining more and more popularity as a physics analysis tool, physics computing centers, such as the Fermilab LHC Physics Center (LPC), are seeing huge increases in their resources being used for such algorithms. These facilities, however, are not generally set up efficiently for machine learning inference as they rely on slower CPU evaluation, which has a noticeable impact on time-to-insight and is detrimental to computational throughput. In this work, we will discuss how we used the NVIDIA Triton Inference Server to re-optimize Fermilab's resource allocation and computing structure to achieve high throughput for scaling out to multiple users parallelizing their machine learning inference at the same time. We will also demonstrate how this service is used in current physics analyses and provide steps for how others can apply this tool to their analysis code.
The upcoming high-luminosity upgrade of the LHC will lead to a factor of five increase in instantaneous luminosity during proton-proton collisions. Consequently, the experiments situated around the collider ring, such as the CMS experiment, will record approximately ten times more data. Furthermore, the luminosity increase will result in significantly higher data complexity, thus making more sophisticated and efficient real-time event selection algorithms an unavoidable necessity in the future of the LHC.
One particular facet of the looming increase in data complexity is the availability of information pertaining to the individual constituents of a jet at the first stage of the event filtering system, known as the level-1 trigger. Therefore, more intricate jet identification algorithms that utilise this additional constituent information can be designed if they meet the strict latency, throughput, and resource requirements. In this work, we construct, deploy, and compare fast machine-learning algorithms, including graph- and set-based models, that exploit jet constituent data on field-programmable gate arrays (FPGAs) to perform jet classification. The latencies and resource consumption of the studied models are reported. Through quantization-aware training and efficient FPGA implementations, we show that O(100) ns inference of complex models like graph neural networks and deep sets is feasible at low resource cost.
The challenging environment of real-time systems at the Large Hadron Collider (LHC) strictly limits the computational complexity of algorithms that can be deployed. For deep learning models, this implies only smaller models that have lower capacity and weaker inductive bias are feasible. To address this issue, we utilize knowledge distillation to leverage both the performance of large models and the speed of small models. In this paper, we present an implementation of knowledge distillation for jet tagging, demonstrating an overall boost in student models' jet tagging performance. Furthermore, by using a teacher model with a strong inductive bias of Lorentz symmetry, we show that we can induce the same bias in the student model which leads to better robustness against arbitrary Lorentz boost.
The exceptional challenges in data acquisition faced by experiments at the LHC demand extremely robust trigger systems. The ATLAS trigger, after a fast hardware data processing step, uses software-based selections referred to as the High-Level-Trigger (HLT). Jets originating from b-quarks (b-jets) are produced in many interesting fundamental interactions, making them a key signature in a broad spectrum of processes, such as Standard Model HH→4b. Trigger selections including b-jets require track reconstruction which is computationally expensive and could overwhelm the HLT farm. To cope with the real-time constraints and enhance the physics reach of the collected data, a fast neural-network-based b-tagger was introduced for the start of Run-3 (https://arxiv.org/abs/2306.09738). This low-precision filter runs after the hardware trigger and before the remaining HLT reconstruction. It relies on the negligible cost of neural-network inference as compared to track reconstruction, and the cost reduction from limiting tracking to specific detector regions. In the case of HH→4b, the filter lowers the input rate to the remaining HLT by a factor of five at the small cost of reducing the overall signal efficiency by roughly 2%. The proposed talk will present this method, which has tremendous potential for application at the HL-LHC, including in the low latency hardware trigger and in use cases beyond heavy flavour tagging.
BDTs are simple yet powerful ML algorithms with performance often at par with cutting-edge NN-based models. The structure of BDTs allows for a highly parallelized, low-latency implementation in FPGAs. I will describe the development and implementation of a BDT-based algorithm for tau lepton identification in the ATLAS Level-1 trigger system as part of the phase-I upgrade, designed to be integrated into existing firmware written in VHDL along with some practical lessons learned along the way.
The High Luminosity upgrade to the LHC will deliver unprecedented luminosity to the experiments, culminating in up to 200 overlapping proton-proton collisions. In order to cope with this challenge several elements of the CMS detector are being completely redesigned and rebuilt. The Level-1 Trigger is one such element; it will have a 12.5 microsecond window in which to process protons colliding at a rate of 40MHz, and reduce this down to 750kHz. The key attibute of a trigger system is to retain the signals which would benefit from further analysis, and thus should be stored on disk. This upgraded trigger, as in the present design, will utilise an all-FPGA solution. Although rules-based algorithms have traditionally been used for this purpose, the emergence of new generation FPGAs and Machine Learning toolsets have enabled neural networks to be proposed as an alternative architecture. We present the design and implementation of a Convolution Neural Network (CNN) on an FPGA to demonstrate the feasibility of such an approach. Results will be presented for a baseline signal model of a pair of Higgs bosons decaying to four b-quarks. The model architecture, resource usage, latency and implementation floorplan will all be presented. Latest results will also be shown of studies to use domain-specific knowledge to enhance the network’s inference capability.
Extracting low-energy signals from LArTPC detectors is useful, for example, for detecting supernova events or calibrating the energy scale with argon-39. However, it is difficult to efficiently extract the signals because of noise. We propose using a 1DCNN to select wire traces that have a signal. This efficiently suppresses the background while still being efficient for the signal. This is then followed by a 1D autoencoder to denoise the wire traces. At that point the signal waveform can be cleanly extracted.
In order to make this processing efficient, we implement the two networks on an FPGA. In particular we use hls4ml to produce HLS from the Keras models for both the 1DCNN and the autoencoder. We deploy them on an AMD/Xilinx Alveo U55C using the Vitis software platform.
Graph structures are a natural representation of data in many fields of research, including particle and nuclear physics experiments, and graph neural networks (GNNs) are a popular approach to extract information from that. Simultaneously, there is often a need for very low-latency evaluation of GNNs on FPGAs. The HLS4ML framework for translating machine learning models from industry-standard Python implementations into optimized HLS code suitable for FPGA applications has been extended to support GNNs constructed using PyTorch Geometric (PyG). To that end, the parsing of general PyTorch models using symbolic tracing using the torch.FX package has been added to HLS4ML. This approach has been extended to enable parsing of PyG models and support for GNN-specific operations has been implemented. To demonstrate the performance of the GNN implementation in HLS4ML, a network for track reconstruction in the sPHENIX experiment is used. Future extensions, such as an interface to quantization-aware training with Brevitas, are discussed.
Within the framework of the L1 trigger's data filtering mechanism, ultra-fast autoencoders are instrumental in capturing new physics anomalies. Given the immense influx of data at the LHC, these networks must operate in real-time, making rapid decisions to sift through vast volumes of data. Meeting this demand for speed without sacrificing accuracy becomes essential, especially when considering the time-sensitive nature of identifying key physics events. With ultra low-latency requirements at the trigger, we can leverage hardware-aware neural architecture search techniques to find optimal models. Our approach leverages supernetworks to explore potential subnetworks through evolutionary search and unstructured neural network pruning, facilitating the discovery of high-performing sparse autoencoders. For efficient search, we train predictor networks for each objective, lowering the sample cost of evolutionary search. Here, we optimize for the post-pruning model. Due to the unique nature of reconstruction-based anomaly detection methods, we explore how neural network pruning and sparsity affect the generalizability on out-of-distribution data in this setting.
Recent years have witnessed the enormous success of the transformer models in various research fields including Natural Language Processing, Computational Vision as well as natural science territory. In the HEP community, models with transformer backbones have shown their power in jet tagging tasks. However, despite the impressive performance, transformer-based models are often large and computational heavily, resulting in low inference speeds. In this talk, I will discuss the preliminary results of our effort in accelerating the transformer models in the context of FastML.
Social event
The European Spallation Source (ESS) is multi-disciplinary research facility based on neutron scattering under construction in Lund. The facility includes a superconducting linear proton accelerator, a rotating tungsten target wheel where neutrons are spalled off by the high energy protons and a suit of instruments for neutron scattering experiments.
ESS is a user facility designed and built for external scientists who will visit ESS after the start of the user program in 2027. Reliability and availability are therefore of major concern, and challenging since accelerator-based research facilities in general are very complex. In addition, the ambition to be the world’s first sustainalbe research facility emphasise the importance of operational efficiency. This has motivated us to initiate a Control System Machine Learning (CSML) project to explore how machine learning methods developed in other fields such as natural language processing, image analysis and robotics, can be applied to the control system. In this talk the outcome of this project will be presented together with examples, lessons learned and a road map into the future for accelerator controls.
Magnetic confinement fusion research is at a threshold where the next generation of experiments are designed to deliver burning fusion plasmas with net energy gain for the first time. ML holds great promise in reducing the costs and risks of fusion reactor development, by enabling efficient workflows for scenario optimization, reactor design, and controller design. This talk reviews various aspects of ML applications in fusion science, ranging from simulation acceleration, controller design, event detection, and realtime diagnostics, punctuated by case studies of physics model ML-surrogates and novel RL-derived controllers.
The exploration of extrasolar planets, which are planets orbiting stars other than our own, holds great potential for unravelling long-standing mysteries surrounding planet formation, habitability, and the emergence of life in our galaxy. By studying the atmospheres of these exoplanets, we gain valuable insights into their climates, chemical compositions, formation processes, and past evolutionary paths. The recent launch of the James Webb Space Telescope (JWST) marks the beginning of a new era of high-quality observations that have already challenged our existing understanding of planetary atmospheres. Over its lifetime, the JWST will observe approximately 50 to 100 planets. Furthermore, in the coming decade, the European Space Agency's Ariel mission will build on this progress by studying in detail the atmospheres of an additional 1000 exoplanets.
In this talk, I will outline three fundamental challenges to exoplanet characterisation that lend themselves well to machine-learning approaches. Firstly, we encounter the issue of extracting useful information from data with low signal-to-noise ratios. When the noise from instruments surpasses the signal from exoplanets, we must rely on self-supervised deconvolution techniques to learn accurate instrument models that go beyond our traditional calibration methods. Secondly, in order to interpret these alien worlds, we must employ highly complex models encompassing climate, chemistry, stellar processes, and radiative transfer. However, these models demand significant computational resources, necessitating the use of machine learning surrogate modelling techniques to enhance efficiency. Lastly, the Bayesian inverse problem, which traditionally relies on methods like Markov Chain Monte Carlo (MCMC) and nested sampling, becomes particularly challenging in high-dimensional parameter spaces. In this regard, simulation-based inference techniques offer potential solutions.
It is evident that many of the modelling and data analysis challenges we face in the study of exoplanets are not unique to this field but are actively investigated within the machine learning community. However, interdisciplinary collaboration has often been hindered by jargon and a lack of familiarity with each other's domains. In order to bridge this gap, as part of the ESA Ariel Space mission, we have successfully organized four machine learning challenges hosted at ECML-PKDD and NeurIPS (https://www.ariel-datachallenge.space). These challenges aim to provide novel solutions to long-standing problems and foster closer collaboration between the exoplanet and machine learning communities. I will end this talk with a brief discussion of the lessons learned from running these interdisciplinary data challenges.
The field of Astrodynamics faces a significant challenge due to the increasing number of space objects orbiting Earth, especially from recent satellite constellation deployments. This surge underscores the need for quicker and more efficient algorithms for orbit propagation and determination to mitigate collision risks in both Earth-bound and interplanetary missions on large scales. Often, serial finite-difference-based schemes are the method of choice for solving such initial and boundary value problems. However, as the complexity of the physical model increases, these methods rapidly lose efficiency due to their high number of function calls. While iterative solvers, such as the Modified-Chebyshev-Picard Iteration (MCPI), have shown increased performance for simple propagation problems, this drops for highly nonlinear problems over large time spans, in which large numbers of iterations are required for convergence. This work introduces a mathematical framework for quantifying non-linearity in first-order ODE systems using their Jacobian matrix and presents a new time-parallel iterative method based on the spectral-element approach for solving them. The novelty of this method lies in its mitigation of the nonlinear effects of ODEs through the regularization of the dependent variable with the Frobenius norm of the Jacobian matrix, which results in an optimal time coordinate transformation that minimises the spectral error. To compactly represent this coordinate transformation, a layered, Neural-Network-like architecture is employed using Chebyshev polynomials as activation functions, coined as a “Deep Spectral Network” (DSN). Unlike classical Neural Networks that use an iterative forward and back-propagation process for training, this DSN leverages the orthogonality of Chebyshev polynomials to sequentially construct new layers based on previous coefficient values. The performance of the Deep Spectral Network method is assessed for the Cartesian and modified-equinoctial element formulations of the perturbed two-body problem, against the Runge-Kutta 4(5) and Dormand-Prince 8(7) integrators for orbits of various eccentricities. The DSN achieves a 70x/40x function call speed-up compared to the state-of-the-art serial finite-difference methods. Furthermore, parallel CPU time speed-ups of up to 8 are achieved with multi-threading, for an implementation in the Julia 1.9.1 language.
Gamma-ray bursts (GRBs) have traditionally been categorized based on their durations. However, the emergence of extended emission (EE) GRBs, characterized by durations higher than two seconds and properties similar to short GRBs, challenges conventional classification methods. In this talk, we delve into GRB classification, focusing on a machine-learning technique (t-distributed stochastic neighbor embedding, t-SNE) for classification and the identification of extended emission in GRBs, and its hyper-parameter optimisation.
Furthermore, we introduce an innovative tool, ClassipyGRB, designed for astronomers whose research centers on GRBs. This versatile Python3 module enhances the exploration of GRBs by offering nteractive visualizations of their light curves and highlighting shared attributes. With ClassipyGRB, astronomers can swiftly compare events, identifying resemblances and exploring their high-frequency characteristics. This tool uses the power of proximity analysis, enabling rapid identification of similar GRBs within seconds.
Deep Learning assisted Anomaly detection is quickly becoming a powerful tool allowing for the rapid identification of new phenomena.
We present a method of anomaly detection techniques based on deep recurrent autoencoders to the problem of detecting gravitational wave signals in laser interferometers. This class of algorithm is trained via a semi-supervised strategy, i.e. with a weak distinction between classes at training time. While the semi-supervised nature of the problem comes with a cost in terms of accuracy as compared to supervised techniques, there is a qualitative advantage in generalizing experimental sensitivity beyond pre-computed signal templates.
We construct a low-dimensional embedded space GWAK (Gravitational-Wave Anomalous Knowledge) which captures the physical signatures of distinct signals on each axis of the space.
By introducing alternative signal priors that capture the salient features of gravitational-wave signatures, we allow for the recovery of sensitivity even when an unmodelled anomaly is encountered.
We show that regions of the embedded space can identify binaries, sine-Gaussian-like signals and detector glitches, and also search a variety of hypothesized astrophysical sources that may emit signals in the GW frequency band including core-collapse supernovae and other stochastic sources.
Proved to be efficient, we incorporate the GWAK search pipeline as a part of the ML4GW software stack. We show how the ML4GW stack is quickly becoming an effective toolkit for the fast and effective deployment of Machine Learning based gravitational algorithms.
Deep Learning (DL) applications for gravitational-wave (GW) physics are becoming increasingly common without the infrastructure to be validated at-scale or deployed in real-time. With ever more sensitive GW observing runs beginning in 2023, the tradeoff between speed and data robustness must be bridged in order to create experimental pipelines which take shorter to iterate upon and which produce results that are both more conclusive and more reproducible. We present a set of libraries, ml4gw and hermes, which allow for the development of DL-powered GW physics applications which are faster, more intuitive, and better able to leverage the powerful modeling techniques available in the GW literature. Within these frameworks we present the latest results for aframe, an end-to-end pipeline for Binary Black Hole (BBH) merger detection, showing the power of a robust validation and deployment framework. We further with results for a real-time parameter estimation algorithm for un-modeled burst-type GW signals using likelihoodfree inference with normalizing flows.
The Deep Underground Neutrino Experiment (DUNE) presents promising approaches to better identify and understand supernova (SN) events. Using simulated Liquid Argon Time Projection Chamber (LarTPC) data, we develop an end to end edge-AI pipeline that has the potential to significantly reduce SN pointing time. Using a sequence of machine learning algorithms, we are able to reject radiological background, suppress electronics noise, and identify neutrino electron elastic scattering interactions. We may distinguish such interactions from the more abundant charged current neutrino interactions that carry little to no SN directional information. Such a pipeline enables us to significantly reduce the amount of data required for downstream event analysis, allowing determination of the SN's position within real-time latency constraints. The algorithms in this pipeline also more accurately identify low-energy (LE) signals in low SNR samples. These low energy signals are relevant for detector calibration studies and downstream analysis of particle interactions. We show the potential performance of such a pipeline in a real time setting, and evaluate its potential for identification of critical supernova events, and analysis of downstream LE events.
In the Fermilab accelerator complex, the Main Injector (MI) and the Recycler Ring (RR) share a tunnel. The initial design was made for the needs of the Tevatron, where the RR stored fairly low intensities of anti-protons. Currently, however, both the MI and RR often have high intensity beams at the same time. Beam loss monitors (BLMs) are placed at different points in the tunnel to detect losses. However, it is often difficult to attribute the beam loss to either the MI or the RR, causing the beams to be unnecessarily aborted in both machines. This causes unnecessary downtime that is costly to the running of the experiments at the Intensity Frontier.
In order to decrease the unnecessary downtime, a system has to attribute the loss to a particular machine in real-time (less than 3 ms). To do this, a real-time AI system is used. A “central node” receives all the data from the BLMs and passes them to a U-Net-based AI model running on an Intel Arria10 SoC. This model attributes the likelihood that beam loss at a particular monitor is to a particular machine. This was the first FPGA-based edge AI control system running in the accelerator complex.
In addition to describing the system, a second focus of the presentation will be on using hls4ml to translate the original U-Net model, written in Keras, to High Level Synthesis (HLS) for the Intel HLS compiler. In particular, this model stressed the streaming implementation due to its design with skip connections, requiring some modification to the libraries. We will discuss our experience, and discuss plans for the future.
Superconducting (SC) magnets deployed at any accelerator complex must reach exceptionally high currents to accurately control particle trajectories. During operation, superconducting magnets occasionally experience a spontaneous transition from the superconducting to the normal state while operating at several kiloamps (quenching). Quenches may significantly damage the magnet, preventing SC magnets from conducting their intended maximum operational current. Using data from surrounding sensors, we present a machine learning interface that trains and performs inference for anomaly detection in SC magnet data with the potential for real time quench prediction. The algorithm extracts energy and flux changes from acoustic and quench antenna respectively, while altering the quench prediction inference based on changes in latent space. The result is a model that localizes anomalies in space and time that may be further investigated to understand the physical origin of the quench, and eventually aid in a real time quench prediction system.
The Tokamak magnetic confinement fusion device is one leading concept design for future fusion reactors which require extremely careful control of plasma parameters and magnetic fields to prevent fatal instabilities. Magneto-hydrodynamic (MHD) instabilities occur when plasma confinement becomes unstable as a result of distorted non-axisymmetric magnetic field lines. These ``mode'' instabilities often lead to contact with the chamber wall, confinement loss, and damage to the reactor. Therefore, active control and suppression of these instabilities on microsecond time scales \cite{R1} is required and will be critical to the reliability of future fusion reactors. We address this need by applying deep learning methods to develop a novel real-time FPGA (Field Programmable Gate Array)-accelerated instability tracking feedback control system for the HBT-EP Tokamak.
Enabling active control requires real-time mode tracking capabilities where knowledge of the amplitude and phase of these instabilities affects corrections in magnetic confinement and plasma parameters. In microsecond latency applications such as this, convolutional neural networks (CNNs) deployed to hardware accelerators such as FPGAs provide a robust solution. The emission mechanism produces short plasma discharges resulting in a highly nonlinear system making CNNs an ideal choice for modeling a function which yields the sine and cosine components of the MHD instability. The predicted amplitude and phase are subsequently calculated for comparison with measurements obtained from over two-hundred magnetic sensors which provide a ground truth. Among tested algorithms, the CNN was most accurate at predicting the instability’s sine and cosine components.
Optical input is supplied to the CNN from a Phantom S710 high-speed streaming camera aimed through a viewport aligned tangent to the Tokamak chamber (see figure 1). Typically a dedicated PCIe frame grabber is paired with cameras in high throughput applications such as this to convert raw camera data to pixel values. Using hls4ml, we compile a high-level synthesis representation of the CNN and synthesize to a register-transfer level (RTL) design using the Xilinx development suite \cite{R3}. Our latency requirements mean data transfer to a second PCIe accelerator is not a viable solution. Therefore, we deploy our neural network to the available portion of the frame grabbers FPGA, all but eliminating PCIe and DMA overhead. We write these predictions serially over high-speed RS422 outputs to digital-to-analog converters, and finally, to the Tokamak's magnetic coil control system.
To achieve our target latency within strict resource constraints while meeting timing constraints, we optimize our model by applying the following optimizations: tuning strategy by layer, tuning reuse factor by layer, post-training quantization, pruning, ReLU merging, batching, physical optimization looping, and more. Finally, we benchmark our CNN implementation at <10us empirically by timing the assertions of the CNNs axi-stream interface control signals; with an overall latency including exposure and readout of 20us. We also pipeline computation with readout to achieve >100kfps throughput.
Ultimately, this work aims to enable active control and suppression of MHD instabilities in magnetic confinement fusion devices such as the Tokamak and future fusion reactors.
Figure 1: https://drive.google.com/file/d/12XKTKWd1FGyMMIKngMPXvcCYvVFDB0Ba/view?usp=sharing
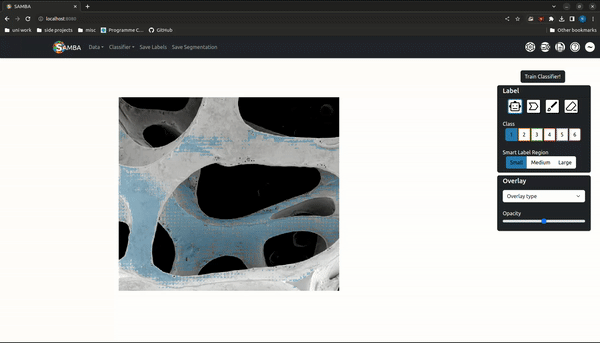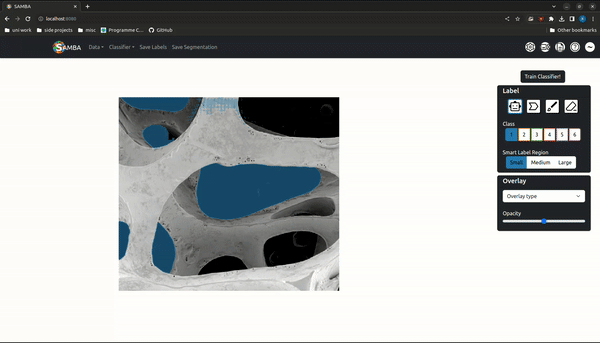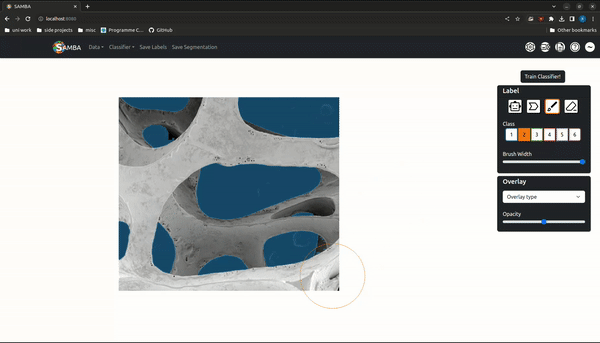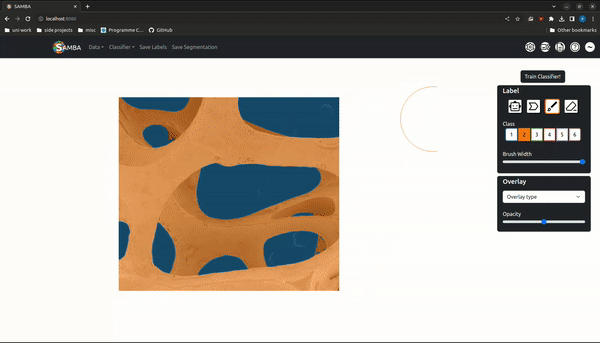
Segmentation is the assigning of a semantic class to every pixel in an image, and is a prerequisite for downstream analysis like phase quantifcation, morphological characterization etc. The wide range of length scales, imaging techniques and materials studied in materials science means any segmentation algorithm must generalise to unseen data and support abstract, user-defined semantic classes.
'Trainable segmentation' is a popular interactive segmentation paradigm where a random forest is trained to map from image features to user drawn labels. Meta's recent Segment Anything Model (SAM) is a promptable, open-source macroscopic object detection model that maps an image embedding - generated by a large transformer-based autoencoder - and prompt (click, bounding-box, mask) to a segmentation via a lightweight decoder network. Decoder inference can be run in real-time in the browser, allowing for object segmentation suggestions as the mouse cursor is moved.
SAMBA (Segment Anything Model Based App) is a trainable segmentation tool that uses the SAM model for fast, high-quality label suggestions and random forests for robust, generalizable segmentations. Image embeddings are generated serverside and supplied to the user where clientside decoder inference can take place. It is accessible in the browser (https://www.sambasegment.com/), without the need to download any external dependencies.
Increased development and utilization of multimodal scanning probe microscopy (SPM) and spectroscopy techniques have led to an orders-of-magnitude increase in the volume, velocity, and variety of collected data. While larger datasets have certain advantages, practical challenges arise from their increased complexity including the extraction and analysis of actionable scientific information. In recent years, there has been an increase in the application of machine and deep learning techniques that use batching and stochastic methods to regularize statistical models to execute functions or aid in scientific discovery and interpretation. While this powerful method has been applied in a variety of imaging systems (e.g., SPM, electron microscopy, etc.), analysis alone takes on the order of weeks to months due to scheduling and IO overhead imposed by GPU and CPU based systems which limits streaming inference rates to speeds above 50ms. This latency precludes the possibility of real-time analysis in SPM techniques such as band-excitation piezoresponse force spectroscopy (BE PFM), where typical measurements of cantilever resonance occur at 64Hz.
One method to accelerate machine learning inference is to bring computational resources as close to the data acquisition source as possible to minimize latencies associated with I/O and scheduling. Therefore, we leverage the National Instruments PXI platform to establish a direct, peer-to-peer channel over PCIe between an analog-to-digital converter and a Xilinx field programmable gate array (FPGA). Through the LabVIEW FPGA design suite, we develop this FPGA-based pipeline using cantilever resonances acquired in BE PFM to conduct real-time prediction of the simple harmonic oscillator (SHO) fit. To accomplish this, we use hls4ml to compile a high-level synthesis (HLS) representation of the neural network. Once this HLS model is synthesized to a register transfer level description (RTL), we implement the design on the FPGAs programmable logic. The parallelizable nature of FPGAs allows for heavily pipelined neural network implementations to achieve latencies on the order of microseconds. We currently benchmark our implementation at 36 us per inference with a fourier transformation accounting for an additional 330 us. At the expense of FPGA resources, we overlap data acquisition with computation to enable continuous acquisition and processing of response data. This work provides a foundation for deploying on-sensor neural networks using specialty hardware for real- time analysis and control of materials imaging systems. To further enhance the performance and capabilities we discuss our progress implementing this system on an RFSoC 4x2 (Radio Frequency System-on-Chip) which integrates both the FPGA and RF data converters on a single chip, effectively combining analog and digital processing capabilities and reducing latencies associated with I/O and scheduling.
Materials have marked human evolution throughout history. The next technological advancement will inevitably be based on a groundbreaking material. Future discovery and application of materials in technology necessitates precise methods capable of creating long-range, non-equilibrium structures with atomic accuracy. To achieve this, we need enhanced analysis tools and swift automated synthesis. Although machine learning is gradually making inroads into materials science, most analysis happens well after the experiment, making the insights less actionable. Furthermore, most models applied are purely data-driven and thus do not necessarily adhere to the principles of physics. In this paper, we delve into our advancements in creating machine learning algorithms, informed and constrained by physics, implemented on FPGAs for detailed materials analysis. Firstly, we explore the use of 4D scanning transmission electron microscopy, where an electron beam produces a 2D image from 2D diffraction patterns with sub-atomic accuracy. We introduce a spatial transforming autoencoder that outperforms existing algorithms in determining crystallographic strain, shear, and orientation. We deploy these models on FPGAs via HLS4ML, achieving latencies less than 29 s, surpassing current imaging rate (~1 kHz). This advancement provides capabilities for triggering systems that permit detection-controlled imaging modes that reduce damage during electron microscopy, preserving the natural state of sensitive materials. Secondly, we discuss real-time analysis of multimodal in situ spectroscopies in pulsed-laser deposition. This process involves a laser ablating a targeting a low-pressure oxidizing atmosphere, forming a plasma plume that is deposited on a heated substrate. We demonstrate how this process can be monitored using direct imaging of the plasma dynamics and reflection high-energy electron diffraction at >500 Hz to observe surface crystallography and diffusion. We show how hard-physics constrained machine learning methods deployed on FPGAs can serve as real-time approximates of processes providing a pathway towards autonomous synthesis.
Accurate and reliable long-term operational forecasting is of paramount importance in numerous domains, including weather prediction, environmental monitoring, early warning of hazards, and decision-making processes. Spatiotemporal forecasting involves generating temporal forecasts for system state variables across spatial regions. Data-driven methods such as Convolutional Long Short-Term Memory (ConvLSTM) are effective in capturing both spatial and temporal correlations, but they suffer from error accumulation and accuracy loss in long-term forecasting due to the nonlinearity and uncertainty in physical processes. To address this issue, we propose to combine data-driven and data assimilation methods for explainable long-term operational forecasting. Data assimilation is used for updating the predictive results by merging measurements into operational modelling. However, it is computationally impossible to conduct online data assimilation and provide real-time reanalysis data for large-scale problems. Recent advancements in neural network techniques have offered new opportunities for improving data assimilation and operational forecasting. Neural networks excel at capturing nonlinear relationships and are computationally efficient at leveraging large-scale datasets, making them particularly well-suited for handling the intricate dynamics of operational forecasting systems.
Here we propose a hybrid-ConvLSTM and DA model for accurate and efficient long term forecasting. This proposed hybrid ConvLSTM-DA method is demonstrated through hourly/daily PM2.5 forecasting globally and regionally (in China), which is a challenging task due to the complexity of geological and meteorological conditions in the region, the need for high-resolution forecasting over a large study area, and the scarcity of observations. The results show that the ConvLSTM-DA method outperforms conventional methods and can provide satisfactory hourly PM2.5 forecasting in the following 27 days with spatially averaged RMSE below 40 ug/m¬3 and correlation coefficient (R) above 0.7. In addition, the ConvLSTM-DA method shows a substantial reduction in CPU time when compared to the commonly used NAQPMS model, up to three orders of magnitude. Overall, the use of data driven modelling provides efficient prediction and also speeds up data assimilation. This hybrid ConvLSTM-DA is a novel operational forecasting technique for spatiotemporal forecasting and used in real spatiotemporal forecasting for the first time.
Surgical data technologies have not only been successfully integrated inputs from various data sources (e.g., medical devices, trackers, robots and cameras) but have also applied a range of machine learning and deep learning methods (e.g., classification, segmentation or synthesis) to data-driven interventional healthcare. However, the diversity of data, acquisitions and pre-processing methods, data types, as well as training and inference methods has presented a challenging scenario for implementing low-latency applications in surgery. Recently, transformers-based models have emerged as dominant neural networks, owing to their attention mechanisms and parallel capabilities when using multimodal medical data. Despite this progress, state-of-the-art transformers-based models remain heavyweight and challenging to optimise (with 100MB of parameters) for real-time applications. Hence, in this work, we concentrate on a lightweight transformer-based model and employ pruning techniques to achieve a balance in data size for both training and testing workflows, aiming at enhancing real-time performance. We present preliminary results from a machine learning workflow designed for real-time classification of surgical skills assessment. We similarly present a reproducible workflow for data collection using multimodal sensors, including USB video image and Bluetooth-based inertial sensors. This highlights the potential of applying models with small memory and parameter size, enhancing inference speed for surgical applications. Code, data and other resources to reproduce this work are available at https://github.com/mxochicale/rtt4ssa
The use of neural networks for approximating fermionic wave functions has become popular over the past few years as their ability to provide impressively accurate descriptions of molecules, nuclei, and solids has become clear.
Most electronic structure methods rely on uncontrolled approximations, such as the choice of exchange-correlation functional in density functional theory or the form of the parameterized trial wavefunction in conventional quantum Monte Carlo simulations. Neural wave functions, on the other hand, are built from multilayer perceptrons, which are universal approximators. The network weights and biases that define a neural wave function may be optimized efficiently by combining variational Monte Carlo methods with automatic gradients calculated using back propagation. This approach produces results of consistent quality across highly diverse systems. In some cases, the variational optimization is capable of discovering quantum phase transitions unaided.
High-dimensionality is known to be the bottleneck for both nonparametric regression and Delaunay triangulation. To efficiently exploit the geometric information for nonparametric regression without conducting the Delaunay triangulation for the entire feature space, we develop the crystallization search for the neighbour Delaunay simplices of the target point similar to crystal growth. We estimate the conditional expectation function by fitting a local linear model to the data points of the constructed Delaunay simplices. Because the shapes and volumes of Delaunay simplices are adaptive to the density of feature data points, our method selects neighbour data points more uniformly in all directions in comparison with Euclidean distance based methods and thus it is more robust to the local geometric structure of the data. We further develop the stochastic approach to hyperparameter selection and the hierarchical crystallization learning under multimodal feature data densities, where an approximate global Delaunay triangulation is obtained by first triangulating the local centres and then constructing local Delaunay triangulations in parallel.
Given the increasing volume and quality of genomics data, extracting new insights requires efficient and interpretable machine-learning models. This work presents Genomic Interpreter: a novel architecture for genomic assay prediction. This model out-performs the state-of-the-art models for genomic assay prediction tasks. Our model can identify hierarchical dependencies in genomic sites. This is achieved through the integration of 1D-Swin, a novel Transformer-based block designed by us for modelling long-range hierarchical data. Evaluated on a dataset containing 38,171 DNA segments of 17K base pairs, Genomic Interpreter demonstrates superior performance in chromatin accessibility and gene expression prediction and unmasks the underlying ’syntax’ of gene regulation. On the efficiency side, 1D-Swin has time complexity of $O(nd)$, where $n$ is the size of input sequences, $d$, the window size, is a hyperparameter. This makes it feasible to deal with long-range sequences in other domains, such as Natural Language Processing (NLP) and Time Series Data.
While this work has been presented in the ICML 2023 workshop on Computional Biology, we are actively pursuing collaborations to further advance its practical applications. We make our source code for 1D-Swin publicly available at https://github.com/Zehui127/1d-swin.
Wasalu Jaco, professionally known as Lupe Fiasco, is a Chicago-born, Grammy Award-winning American rapper, record producer, entrepreneur, and community advocate. He is a luminary in the world of hip-hop, renowned for his thought-provoking lyrics, innovative storytelling, and unwavering commitment to social and political activism.
Rising to fame in 2006, following the success of his debut album, Food & Liquor, Lupe has released eight acclaimed studio albums; his latest being Drill Music in Zion released in June 2022. His efforts to propagate Conscious Material garnered recognition as a Henry Crown Fellow and he is a recipient of the MLK Visiting Professorship Program at MIT for the 2022/2023 academic year.
Lupe will talk about the use of LLMs in his creative endeavors, including co-writting a new rap song ‘Glass of Water’ with AI.
Book your ticket here: https://www.imperial.ac.uk/events/166036/algorithms-and-flow-lupe-fiascos-creative-use-of-llms/
Beyond the well-known highlights in computer vision and natural language, AI is steadily expanding into new application domains. This Pervasive AI trend requires supporting diverse and fast-moving application requirements, ranging from specialized I/O to fault tolerance and limited resources, all the while retaining high performance and low latency. Adaptive compute architectures such as AMD FPGAs are an excellent fit for such requirements but require co-design of hardware and ML algorithms to reap the full benefits. In this talk, we will cover a breadth of co-design techniques, including their merits and challenges, from streaming dataflow architectures to quantization, from sparsity to full circuit co-design. By combining such techniques, we can enable nanosecond-latency and performance in the hundreds of millions of inferences per second. The proliferation of this technology is enabled via open-source AMD tools such as FINN, Brevitas and LogicNets, as well as the AMD-FastML collaborative project QONNX.
How fast should your machine learning be? ideally, as fast as you can stream data to it.
In this presentation I will discuss the role of computing infrastructure in machine learning, and argue that to face the growing volume of data and support latency constraints, the best place for inference is within the network. I will introduce in-network machine learning, the offloading of machine learning models to run within programmable network devices, and explain the technology and methodologies that enable innovation in the field, as well as existing tools. Finally, I will explore the use of in-network machine learning for a range of applications, ranging from security and finance to edge computing and smart environments.
Large Language Models (LLMs) will completely transform the way we interact with computers, but in order to be successful they need to be fast and highly responsive. This represents a significant challenge due to the extremely high computational requirements of running LLMs. In this talk, we look at the technology behind LLMs, its challenges, and why Groq's AI accelerator chip holds a significant advantage in running LLMs at scale.
Deep learning has shown great potential in improving and accelerating the entire medical imaging workflow, from image acquisition to interpretation. This talk will focus on the recent advances of deep learning in medical imaging, from the reconstruction of accelerated signals to automatic quantification of clinically useful information. The talk will describe how model-based deep learning can be used for reconstruction of accelerated MRI and will discuss its applications to fast dynamic cardiac MRI cine imaging. It will also show the utility of deep learning for fast analysis of medical images, with a particular focus on image registration and motion tracking. Finally, it will briefly discuss about the open challenges and opportunities of AI in medical imaging.
Neural networks achieve state-of-the art performance in image classification, medical analysis, particle physics and many more application areas. With the ever-increasing need for faster computation and lower power consumption, driven by real-time systems and Internet-of-Things (IoT), field-programmable gate arrays (FPGAs) have emerged as suitable accelerators for deep learning applications. Due to the high computational complexity and memory footprint of neural networks, various compression techniques, such as pruning, quantisation and knowledge distillation, have been proposed in literature. Pruning sparsifies a neural network, reducing the number of multiplications and memory. However, unstructured pruning often fails to capture properties of the underlying hardware, bottlenecking improvements and causing load-balance inefficiency on FPGAs.
We propose a hardware-centric formulation of pruning, by formulating it as a knapsack problem with parallelisation-aware tensor structures. The primary emphasis is on real-time inference, with latencies of order 1µs. We evaluate our method on a range of tasks, including jet tagging at CERN’s Large Hadron Collider and fast image classification (SVHN, Fashion MNIST). The proposed method achieves reductions ranging between 55% and 92% in digital signal processing blocks (DSPs) and up to 81% in block memory (BRAM), with inference latencies ranging between 105ns and 205µs.
The proposed algorithms are integrated with hls4ml and open-sourced with an Apache 2.0 licence, enabling an end-to-end tool for hardware-aware pruning and real-time inference. Furthermore, the tools are readily integrated with QKeras, enabling pruning and inference of models trained with quantisation-aware training. Compared to TensorFlow Model Optimization, hls4ml Optimization API offers advanced functionality, including support for structured pruning, gradient-based ranking methods and integration with model reduction libraries, such as Keras Surgeon. Furthermore, by enabling multiple levels of pruning granularity, the software can target a wide range of hardware platforms. Through integration with hls4ml, an open-source, end-to-end system is built, allowing practitioners from a wide range of fields to compress and accelerate neural networks suited for their applications.
Today’s deep learning models consume considerable computation and memory resources, leading to significant energy consumption. To address the computation and memory challenges, quantization is often used for storing and computing data as few as possible. However, exploiting efficient quantization for computing a given ML model is challenging, because it affects both the computation accuracy and hardware efficiency. In this work, we propose a fully automated toolflow, named Machine-learning Accelerator System Explorer (MASE), for exploration of efficient arithmetic for quantization and hardware mapping. MASE takes a deep learning model and represents it as a graph representation of both the software model and the hardware accelerator architecture. , This enables both coarse-grained and fine-grained optimization in both software and hardware. MASE implements a collection of arithmetic types, and supports mixed-arithmetic quantization search in mixed precisions. We evaluate our approach on OPT, an open-source version of the GPT model, and show that our approach achieves a 19$\times$ arithmetic density and a 5$\times$ memory density compared to the float32 baseline, surpassing the prior art 8-bit quantisation by 2.5$\times$ in arithmetic density and 1.2$\times$ in memory density.
For many deep learning applications, model size and inference speed at deployment time become a major challenge. To tackle these issues, a promising strategy is quantization.
A straightforward uniform quantization to very low precision often results in considerable accuracy loss. A solution to this predicament is the usage of mixed-precision quantization, founded on the idea that certain sections of the network can accommodate lower precision without compromising performance compared to other sections.
In this work, we present "High Granularity Quantization (HGQ)", an innovative quantization-aware training (QAT) method designed to fine-tune the per-weight and per-activation precision for ultra-low latency neural networks which are to be deployed on FPGAs.
In contrast to what is done in the popular QAT library \texttt{QKeras}, where weights and activations are processed in blocks, HGQ enables each weight and activation to have its unique bitwidth. By optimizing these individual bitwidths alongside the network using gradient descent, the need for training the network multiple times to optimize bitwidths for each block of the network is eliminated. Optimizing at the single-weight level also allows HGQ to find a better trade-off relation between model accuracy and resource consumption.
When multiplication operations in neural networks primarily involve low-bitwidth operands and are implemented with LUTs (in contrast to DSPs), HGQ could demonstrate a significant reduction in on-chip resource consumption by eliminating unnecessary computations without compromising performance. Depending on the specific task, we demonstrate that HGQ has the potential to outperform \texttt{AutoQKeras} by a substantial margin, achieving resource reduction by up to a factor of 10 and latency improvement by a factor of 5 while preserving accuracy. Even in more challenging tasks where the base model is under-fitted, HGQ can still yield considerable enhancements while maintaining the same resource usage.
A functional HGQ framework has been developed using \texttt{tensorflow.keras} has been released, and the Vivado FPGA backend is supported through integrating with \texttt{hl4ml}. The current implementation ensures a bit-to-bit match with the final firmware when there is no numerical overflow, with the added flexibility of adjusting the cover-factor to mitigate such risks.
Event detection in time series data plays a crucial role in various domains, including finance, healthcare, environmental monitoring, cybersecurity, and science. Accurately identifying and understanding events in time series data is vital for making informed decisions, detecting anomalies, and predicting future trends. Extensive research has explored diverse methods for event detection in time series, ranging from traditional threshold-based techniques to advanced deep learning approaches. However, a comprehensive survey of existing methods reveals limitations such as lack of universality, limited robustness, or challenges in ease of use. To address these limitations, we propose a novel framework that leverages a universal method based on sliding windows and a Gaussian optimization process, capable of detecting events in any type of time series data. This universal approach allows the framework to be applied to any domain, making it adaptable to different types of events in various time series datasets. To enhance robustness, our framework incorporates a stacked ensemble learning metamodel that combines deep learning models, including classic feed-forward neural networks (FFNs) and state-of-the-art architectures like Self-Attention. By leveraging the collective strengths of multiple models, this ensemble approach mitigates individual model weaknesses and biases, resulting in more robust predictions. To facilitate practical implementation, we have developed a Python package to accompany our proposed framework. We will present the package and provide a comprehensive guide on its usage, showcasing its effectiveness through real-world datasets from planetary science and financial security domains.
Scientific experiments rely on machine learning at the edge to process extreme volumes of real-time streaming data. Extreme edge computation often requires robustness to faults, e.g., to function correctly in high radiation environments or to reduce the effects of transient errors. As such, the computation must be designed with fault tolerance as a primary objective. FKeras is a tool that assesses the sensitivity of machine learning parameters to faults. FKeras uses a metric based on the Hessian of the neural network loss function to provide a bit-level ranking of neural network parameters with respect to their sensitivity to transient faults. FKeras is a valuable tool for the co-design of robust and fast ML algorithms. It guides and accelerates fault injection campaigns for single and multiple-bit flip error models. It analyzes the resilience of a neural network under single and multiple bit-flip fault models. It helps evaluate the fault tolerance of a network architecture, enabling co-design that considers fault tolerance alongside performance, power, and area. By quickly identifying the sensitive parameters, FKeras can determine how to protect neural network parameters selectively.
There has been a growing trend of Multi-Modal AI models capable of gathering data from multiple sensor modalities (cameras, lidars, radars, etc.) and processing it to give more comprehensive output and predictions. Neural Network models, such as Transformers, Convolutional neural networks (CNNs), etc., exhibit the property to process data from multiple modalities and have enhanced various applications, ranging from consumer devices, medical equipment, and safety-critical systems.
CNNs have shown remarkable performance, especially in vision-based applications, ranging from performing one classification task to more intricate and extensive tasks involving multiple modalities and sub-tasks. They do so by learning the low and high-level features of the images. Most images have common lower-level features, which are learned by the lower layers of the network. As we advance deeper into the network, the layers acquire higher-level or more abstract features.
The proposed methodology harnesses the fundamental capabilities of CNNs to learn patterns and perform multiple un-correlated tasks (radar hand gestures, modified MNIST, SVHN) using a single CNN accelerator. In this way, various tasks can share all the CNN layers (fused model) or some layers (branched model) and maintain, on average more than 90\% accuracy. In the hls4ml-generated accelerator, sharing layers translates to sharing hardware resources. Thus, the suggested approach leads to considerable savings in hardware resources and energy, which would otherwise require separate accelerators for separate tasks. Two architectures are proposed. 1) Fused Model (FM): All the tasks share all the layers, and the task-specific classes get activated in the last layer of the model. 2) Branched Model (BM): It consists of tasks-specific branches and shares only specific layers, and supports sub-tasks classification.
Due to the varying AI requirements and workload, hardware resource utilization and energy budget reach a threshold quickly. The proposed approach is further leveraged to introduce a reconfigurable CNN accelerator that adapts to the application's needs. Three identical instances of an FM/BM accelerator can be configured in a Fault Tolerant mode (high-reliability mode consisting of TMR design), High performance (parallel processing of multiple tasks to deliver maximum performance), and De-Stress (switching off one or more accelerator instances by clock/power-gating to reduce aging and power consumption) mode. This work forms the basis for a fully reconfigurable AI processing system comprising reconfigurable quad-core RISC-V cores, on-chip sensors, reconfigurable AI accelerators, and reconfigurable hardware (i.e., FPGAs).
Field-programmable gate arrays (FPGAs) are widely used to implement deep learning inference. Standard deep neural network inference involves the computation of interleaved linear maps and nonlinear activation functions. Prior work for ultra-low latency implementations has hardcoded the combination of linear maps and nonlinear activations inside FPGA lookup tables (LUTs). Our work is motivated by the idea that the LUTs in an FPGA can be used to implement a much greater variety of functions than this. In this paper, we propose a novel approach to training neural networks for FPGA deployment using multivariate polynomials as the basic building block. Our method takes advantage of the flexibility offered by the soft logic, hiding the polynomial evaluation inside the LUTs with zero overhead.
Our aim is to enable applications that require ultra-low latency real-time processing and highly lightweight on-chip implementations. We show that by using polynomial building blocks, we can achieve the same accuracy using considerably fewer layers of soft-logic than by using linear functions, leading to significant latency and area improvements. We demonstrate the effectiveness of this approach in three different tasks: network intrusion detection, handwritten digit recognition using the MNIST dataset, and jet identification at the CERN Large Hadron Collider. Compared to prior works, for similar accuracies, our method achieves significant latency improvements in these tasks, with reductions of up to $2\times$, $19.38\times$, and $3.57\times$, respectively.
Machine learning has been applied to many areas of clinical medicine, from assisting radiologists with scan interpretation to clinical early warning scoring systems. However, the possibilities of ML-assisted real time data interpretationand the hardware needed to realise it are yet to be fully explored. In this talk, possible applications of fast ML hardware to real-time medical imaging will be discussed, along with the practical considerations needed to deploy algorithms to clinical environments. A new FPGA firmware toolchain will also be presented, which enables very large networks with different use cases to be seamlessly deployed to a variety of FPGAs with low latency. The framework's uses within the basic sciences will be discussed, alongside its medical applications.
Converged compute infrastructure refers to a trend where HPC clusters are set up for both AI and traditional HPC workloads, allowing these workloads to run on the same infrastructure, potentially reducing underutilization. Here, we explore opportunities for converged compute with GroqChip, an AI accelerator optimized for running large-scale inference workloads with high throughput and ultra-low latency. GroqChip features a Tensor Streaming architecture optimized for matrix-oriented operations commonly found in AI, but GroqChip can also efficiently compute other applications such as linear algebra-based HPC workloads.
We consider two opportunities for using the Groq AI accelerator for converged HPC. The first example is a structured grid solver for Computational Fluid Dynamics (CFD). This solver can run in a classical implementation as a direct numerical solver (DNS) using the pressure projection method. In a hybrid AI implementation, the same DNS solver is augmented with CNN-based downscaling and upscaling steps. This enables a reduction of grid size from 2048 to 64, thus significantly reducing the amount of compute necessary while maintaining a similar quality of results after upscaling. A speedup of three orders of magnitude is made possible by the combination of reducing the number of compute steps in the algorithm through introducing AI, and by accelerating both the CNN and DNS stages with GroqChip. The second example is using HydraGNN for materials science and computational chemistry. These problems are typically solved with Density Field Theory algorithms, but recently, Graph Neural Networks (GNNs) have been explored as an alternative. For example, GNNs can be used to predict the total energy, charge density, and magnetic moment for various atom configurations, identifying molecules with desired reactivity. The computation requires many parallel walks of HydraGNN with low batch sizes, and can be solved on GroqChip 30-50x faster than an A100 graphics processor.
Machine Learning has gone through major revolutionary phases over the past decade and neural networks have become state-of-the-art approaches in many applications, from computer vision to natural language processing. However, these advances come at ever-growing computational costs, in contrast, CMOS scaling is hitting fundamental limitations such as power consumption and quantum mechanical effects, thus lags substantially behind these growing demands. To approach this discrepancy, novel computing technologies have come into focus in recent years. In this setting, the field of analog computing is gaining research interest, as it represents a possible solution to the scaling problem.
While analog computing can dramatically increase the energy efficiency of computations and thereby contribute to a continued performance scaling of CMOS, it comes with the emblematic caveats of analog computations like noise, temporal drift, non-linearities, and saturation effects. Even though calibration routines and intelligent circuit design try to compensate for these imperfections, in practice they cannot be fully avoided. Therefore, applications running on these analog accelerators must find solutions to limit their impact.
One implementation of an analog accelerator is the BrainScaleS-2 system from the Kirchhoff Institute at Heidelberg University. It’s a neuromorphic mixed-signal system with an analog chip at its core, that serves as a research platform for spiking neural networks and as an analog matrix multiplication accelerator at the same time. The primary design goals of the system are energy-efficient computing and a scalable chip design, which allows the system to be extended up to wafer-scale processor sizes.
This work is concerned with such analog computations and the implications of calibration in terms of result quality and runtime cost. We conduct several experiments with artificial neural network models on the BrainScaleS-2 system as an accelerator for matrix multiplications and familiarize ourselves with these difficulties. A central approach to overcoming analog imperfections is hardware-in-the-loop training, in which the model is trained on the actual inference hardware. This compensates for remaining calibration offsets and allows the model to tolerate a certain level of noise. Further, we improve the performance of these models by adjusting calibration parameters as well as the mapping strategy of the linear layers to the analog hardware.
Our major contributions to the FastML workshop are a short introduction to the circuit which executes the analog matrix multiplication, related tooling, and calibration parameters. We then show how these parameters affect the multiply-accumulate operation, with the respective impact on hardware imperfections and how they impact the training results of the model itself. We show, that optimizing these parameters involves tradeoffs with respect to remaining imperfections that cannot be further improved, and plan on discussing these to foster an overall understanding of the challenges of analog hardware in the community.
Quantum readout and control is a fundamental aspect of quantum computing that requires accurate measurement of qubit states. Errors emerge in all stages, from initialization to readout, and identifying errors in post-processing necessitates resource-intensive statistical analysis. In our work, we use a lightweight fully-connected neural network (NN) to classify states of a superconducting transmon system. Our NN accelerator yields higher fidelities (92%) than the classical matched filter method (84%). By exploiting the natural parallelism of NNs and their placement near the source of data on field-programmable gate arrays (FPGAs), we can achieve ultra-low latency (~1µs) below decoherence on the Quantum Instrumentation Control Kit (QICK). Integrating machine learning methods on QICK opens several pathways for efficient real-time processing of quantum circuits.
Convolutional Neural Networks (CNNs) have been applied to a wide range of applications in high energy physics including jet tagging and calorimetry. Due to their computational intensity, a large amount of work has been done to accelerate CNNs in hardware, with FPGA devices serving as a high-performance and energy-efficient platform of choice. As opposed to a dense computation where every single multiplication in a convolution is performed, there is a large proportion of zero values in the activation maps due to the ReLU activation layers. Recent work has explored threshold-based sparsification of CNNs by retraining with a parameterized activation function, termed FATReLU which zero-outs all values less than a positive threshold for more sparsity. In this work, we explore the use of ReLU threshold-based sparsification without retraining instead as a time-efficient method and present a sparse accelerator toolchain based on fpgaConvNet.
At a macro level, the accelerator partitions a CNN model and for each partition, it stores all weights in on-chip memory and executes model inference in a layer-wise pipeline. At a micro level, it dynamically skips zero-valued multiplications in hardware via a non-zero check and a crossbar switch to speed-up computation at run-time. We model the performance benefits and measure accuracy loss of ReLU-based sparsification on hardware implementations of ResNet-18 and ResNet-50 on a Xilinx Alveo U250 board. In doing so, we demonstrate the accuracy benefit of latency-aware thresholding, where ReLU thresholds are iteratively increased to boost the sparsity of each partition's slowest node. We measure the performance gains of our method on the baseline-hardware as well as on optimised-hardware, which refers to the new design obtained after performing a design space exploration for the boosted sparsity.
Compared to existing sparse-accelerated designs with the same resources, we observe upto 16% and 29% increase in throughput for the baseline-hardware and optimised-hardware designs, respectively for < 1% loss in Top-1 accuracy on CIFAR-10 image classification without any model retraining. Using latency-aware thresholding, we observe upto 23% and 36% increase in throughput for baseline-hardware and optimised-hardware designs, respectively for the same accuracy. Our work demonstrates that post-training ReLU-based sparsification provides a cheap and useful trade-off between performance and accuracy in sparse CNN inference. A summary of the results can be viewed here: https://drive.google.com/file/d/1nrEoCvD09nku-SVYVPAPlg1OWi_kUsbp/view?usp=sharing
The continued need for improvements in accuracy, throughput, and efficiency of Deep Neural Networks has resulted in a multitude of methods that make the most of custom architectures on FPGAs. These include the creation of hand-crafted networks and the use of quantization and pruning to reduce extraneous network parameters. However, with the potential of static solutions already well exploited, we propose to shift the focus to using the varying difficulty of individual data samples to further improve efficiency and reduce average compute for classification. Input-dependent computation allows for the network to make runtime decisions to finish a task early if the result meets a confidence threshold. Early-Exit network architectures have become an increasingly popular way to implement such behaviour in software.
We create A Toolflow for Hardware Early-Exit Network Automation (ATHEENA), an automated FPGA toolflow that leverages the probability of samples exiting early from such networks to scale the resources allocated to different sections of the network. The toolflow uses the data-flow model of fpgaConvNet, extended to support Early-Exit networks as well as Design Space Exploration to optimize the generated streaming architecture hardware with the goal of increasing throughput/reducing area while maintaining accuracy. Experimental results on three different networks demonstrate a throughput increase of $2.00\times$ to $2.78\times$ compared to an optimized baseline network implementation with no early exits. Additionally, the toolflow can achieve a throughput matching the same baseline with as low as $46\%$ of the resources the baseline requires.
The contribution addresses the topic of time-series recognition, specifically comparing the conventional approach of manual feature extraction with contemporary classification methods that leverage features acquired through the training process. Employing automated feature extraction software, we attained a high-dimensional representation of a time-series, obviating the necessity of designating application-sensitive features. Subsequently, dimensionality reduction techniques, such as Linear Discriminant Analysis (LDA) or Generalized Discriminant Analysis (GDA), were applied to diminish the negative effects of features with low discriminative power among different classes of time-series. Finally, a variety of classification methods (including Bayes classifier, Random Forest or Artificial Neural Networks) were employed both on the complete and reduced feature sets. These results were compared with those of a simple Convolutional Neural Network (CNN) comprising two convolutional layers and trained on the original time-series data. The experimental data used in our work consist of acoustic emission signals originating from two distinct defectoscopy experiments.
Universal approximation theorems are the foundations of classical neural networks,
providing theoretical guarantees that the latter are able to approximate maps of interest.
Recent results have shown that this can also be achieved in a quantum setting,
whereby classical functions can be approximated by parameterised quantum circuits.
We provide here precise error bounds for specific classes of functions
and extend these results to the interesting new setup of randomised quantum circuits,
mimicking classical reservoir neural networks. Our results show in particular that a quantum neural network with $\mathcal{O}(\varepsilon^{-2})$ weights and $\mathcal{O} (\lceil \log_2(\varepsilon^{-1}) \rceil)$ qubits suffices to achieve accuracy $\varepsilon>0$ when approximating functions with integrable Fourier transform.
Deep learning techniques have demonstrated remarkable performance in super resolution (SR) tasks for enhancing image resolution and granularity. These architectures extract image features with a convolutional block and add the extracted features to the upsampled input image transported through a skip connection, which is then converted from a depth to higher resolution space. However, SR can be computationally expensive due to large three-dimensional inputs with outputs many times larger while demanding low latency, making large scale implementation in commercial video streaming applications challenging. To address this issue, we explore the viability of SR deployment on-chip to FPGA and ASIC devices for low latency and low power inference. We train and optimize our model using a range of techniques, including quantization-aware training, batch normalization, heterogeneous quantization, and FIFO depth optimization to achieve an implementation which fits within our resource and accuracy constraints. Using the DIV2K diverse image dataset and supplying input images which are downscaled by a factor of three, we achieve >30 PSNR at >2b quantization. We use this initial FPGA implementation as a proof of concept for future ASIC implementations.
Social event
Zoom link: https://cern.zoom.us/j/63951739685?pwd=VTdITmdvOTc3V1hyK0xPa2t6cjhUdz09
This two-part tutorial presents an update on Intel HLS flow and the Intel FPGA AI Suite. In the first part, we will have a 30-minute update on how the latest oneAPI tool flow for IP authoring works. In the second part we will present Intel FPGA AI Suite and groundbreaking AI Tensor Blocks newly integrated into Intel's latest FPGA device families for deep learning inference. These innovative FPGA components bring real-time, low-latency, and energy-efficient processing to the forefront, supported by the inherent advantages of Intel FPGAs, including I/O flexibility, dynamic reconfiguration, and long-term support. We delve into the Intel FPGA AI Suite, demonstrating its flexibility in achieving scalable performance and seamless integration with industry-leading frameworks like TensorFlow and PyTorch, facilitated by Quartus Prime Software. Moreover, we highlight the game-changing role of AI Tensor Blocks in enhancing deep learning inference performance. This tutorial offers both theoretical insights and practical experiences, equipping participants to leverage these advancements and revolutionize FPGA-based AI applications.
More and more researchers working in fields such as drug discovery, weather forecasting, climate modelling and high-energy particle physics are looking towards AI-based approaches to enhance their applications, both in terms of accuracy and time-to-result. Furthermore, new approaches such as PINNs are revolutionising how neural networks can learn to emulate physical systems governed by well-defined yet complex equations. In this workshop we will take a look at some examples and explore how Graphcore’s IPU technology can accelerate such workflows on the cusp between HPC and AI.
